Flink第一课!使用批处理,流处理,Socket的方式实现经典词频统计

【摘要】 Flink是什么Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。 Flink的特点支持事件时间(event-time)和处理时间(processing-time)语义精确一次(exactly-once)的状态一致性保证低延迟,每秒处理数百万个事件,毫秒级延迟与众多常用存储系统的连接高可用,动态扩展,实现7*24小时全天候运行 Flink的全球热度 F...
Flink是什么
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
Flink的特点
- 支持事件时间(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 低延迟,每秒处理数百万个事件,毫秒级延迟
- 与众多常用存储系统的连接
- 高可用,动态扩展,实现7*24小时全天候运行
Flink的全球热度

Flink可以实现的目标
-
低延迟 来一次处理一次
-
高吞吐
-
结果的准确性和良好的容错性
基于流的世界观
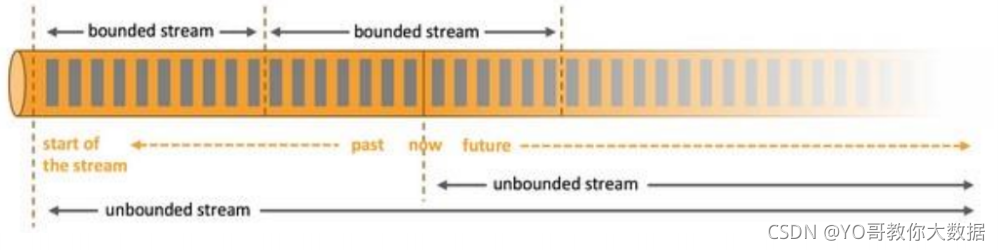
- 在Flink的世界观中,一切皆有流组成,就如python中的一切皆对象的概念。对应离线的数据,则规划为有界流;对于实时的数据怎规划为没有界限的流。也就是Flink中的有界流于无界流
- 有开始也有结束的确定在一定时间范围内的流称为有界流。一旦确定就不会再改变,一般 批处理 用来处理有界数据。
- 无界流就是持续产生的数据流,数据是无限的,有开始,无结束,一般 流处理 用来处理无界数据

Flink第一课,三种方式实现词频统计
创建Flink工程
创建一个普通的maven工程,导入相关依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
导入成功之后有一点要注意,就是java_2.12中的2.12指的是scala的版本,导入依赖成功之后即在对应目录创建包与对应类开始项目的编写。
批处理实现词频统计
package com.yo.wc;
/**
* created by YO
*/
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.util.Collector;
// 批处理word count
public class WordCount {
public static void main(String[] args) throws Exception{
// 创建执行环境,类似与spark的创建上下文
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据 这里可以随意指定路径,txt文件写入空格隔开的随意单词即可
String inputPath = "D:\\hello.txt";
//read读取数据,可以指定读取的文件类型,整套批处理的api在flink里面就叫做dataset
//dataset是flink针对离线数据的处理模型
DataSet<String> inputDataSet = env.readTextFile(inputPath);
// 对数据集进行处理,按空格分词展开,转换成(word, 1)二元组进行统计
DataSet<Tuple2<String, Integer>> result = inputDataSet.flatMap(new MyFlatMapper())
.groupBy(0) // 按照第一个位置的word分组
.sum(1); // 将第二个位置上的数据求和
result.print();
}
// 自定义类,实现FlatMapFunction接口 输出是String 输出是元组Tuple2<String, Integer>>是flink提供的元组类型
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
//value是输入,out就是输出的数据
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 按空格分词
String[] words = value.split(" ");
// 遍历所有word,包成二元组输出
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
输出: 文本内的单词不同输出也不同
(scala,1)
(flink,1)
(world,1)
(hello,4)
流处理api实现词频统计
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.net.URL;
public class StreamWordCount {
public static void main(String[] args) throws Exception{
// 创建流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// // 从文件中读取数据
String inputPath = "D:\\hello.txt";
DataStream<String> inputDataStream = env.readTextFile(inputPath);
// 基于数据流进行转换计算
DataStream<Tuple2<String, Integer>> resultStream = inputDataStream.flatMap(new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
resultStream.print();
// 执行任务
env.execute();
}
}
输出:
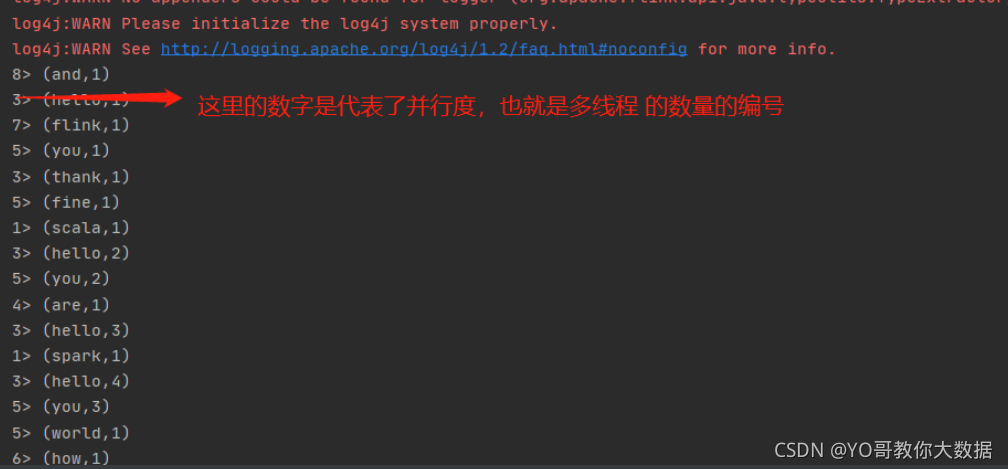
使用socket的方式
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.net.URL;
public class StreamWordCount {
public static void main(String[] args) throws Exception{
// 创建流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 用parameter tool工具从程序启动参数中提取配置项 ,这里就是从main方法中获取参数了args,可以在集群运行,这里再IDEA传参模拟
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
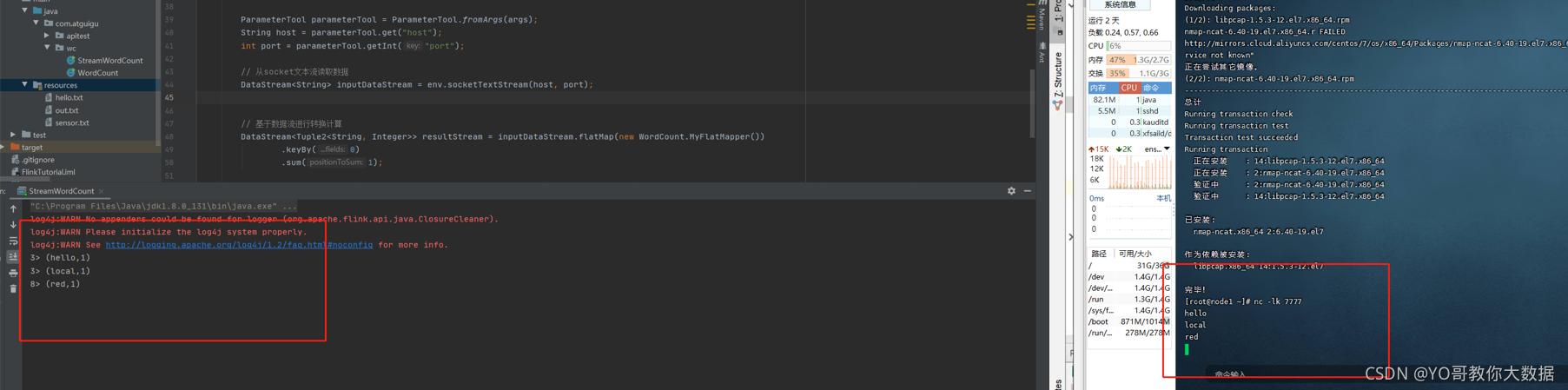
// 从socket文本流读取数据
DataStream<String> inputDataStream = env.socketTextStream(host, port);
// 基于数据流进行转换计算
DataStream<Tuple2<String, Integer>> resultStream = inputDataStream.flatMap(new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
resultStream.print();
// 执行任务
env.execute();
}
}
Flink的第一课入门到这里就完成了,同学们有遇到问题可直接私信,博主会尽力解答!

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)