【精通Spark系列】万事开头难?本篇文章让你轻松入门Spark

🚀 作者 :“大数据小禅”
🚀 **文章简介 **:本篇文章属于Spark系列文章,将会记录从spark基础到进阶的内容,,内容涉及到Spark的入门集群搭建,核心组件,RDD,算子的使用,底层原理,SparkCore,SparkSQL,SparkStreaming等。
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬
1.Spark是什么?
Apache Spark是专门为大规模数据处理而设计出来的计算引擎,相对于Hadoop MapReduce将结果保存在磁盘中,Spark使用了内存保存中间结果,能在数据尚未写入磁盘时在内存中进行运算。Spark只是一个计算框架,不像Hadoop一样包含了分布式文件系统和完备的调度系统,如果需要使用Spark,需要搭载其他文件系统例如用HDFS和更成熟的调度系统进行配合更好的进行计算工作。
2.Spark的历史
- 2009年由加州大学伯克利分校AMPLab开创
- 2010年通过BSD许可协议开源发布
- 2013年捐赠给Apache软件基金会并切换开源协议到Apache2.0
- 2014年2月,Spark成为Apache的顶级项目
- 2014年11月,Spark的母公司Databricks团队使用Spark刷新数据排序世界记录
3.Spark入门之集群搭建
在进行Spark搭建之前,应该尽可能先搭建好Hadoop集群,在生产环境中,HDFS的使用也是极其广泛,与Spark进行配合可以达到更高的工作效率,Hadoop的搭建过程可以看我之前写的文章,Hadoop集群搭建,过程比较详细,步骤附带了较多截图帮助小伙伴们进行搭建。
下面进入到Spark集群的搭建部分,首先我们需要将安装包上传到我们的集群,集群共三台机器分别是node1,node2,node3,使用hadoop用户进行操作,用户添加的方法,IP映射与免密在Hadoop集群搭建的部分有详细写到。将安装包上传之后使用tar命令进行解压,使用mv命令进行重命名方便后续的操作。如下图

修改配置文件
spark的配置文件修改较为简单,先进入到spark目录下的conf目录,因为配置文件默认是以模板的方式存在,所以我们需要先cp一份进行修改,如下图

打开了spark-env.sh文件之后,需要想下面三个配置添加到配置文件的最后几行。第一行指定主机的JAVA路径,第二行指定的是MASTER_HOST的主机地址,最后是MASTER的端口号。如下图

之后编辑当前目录的slaves文件,在里面添加从节点的地址
node2
node2
配置好之后就可以进行集群的分发与启动,集群分发命令如下,这里要注意的是,其他机器的环境应该跟主节点环境一样。
//进入到安装包目录
scp -r spark node2:/app
scp -r spark node3:/app
启动集群
//进入spark的sbin目录运行下面的命令
./start-all.sh
正常启动应该可以看下如下的进程存在
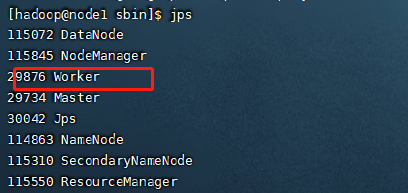
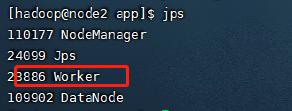
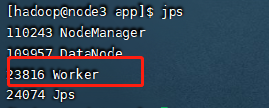
4.集群访问测试
集群搭建完毕之后可以在本地浏览器进行测试是否可以访问,访问前需要先关闭防火墙,具体操作见Hadoop集群的搭建部分。在本地浏览器通过IP地址加上8080端口即可进行访问,如下图
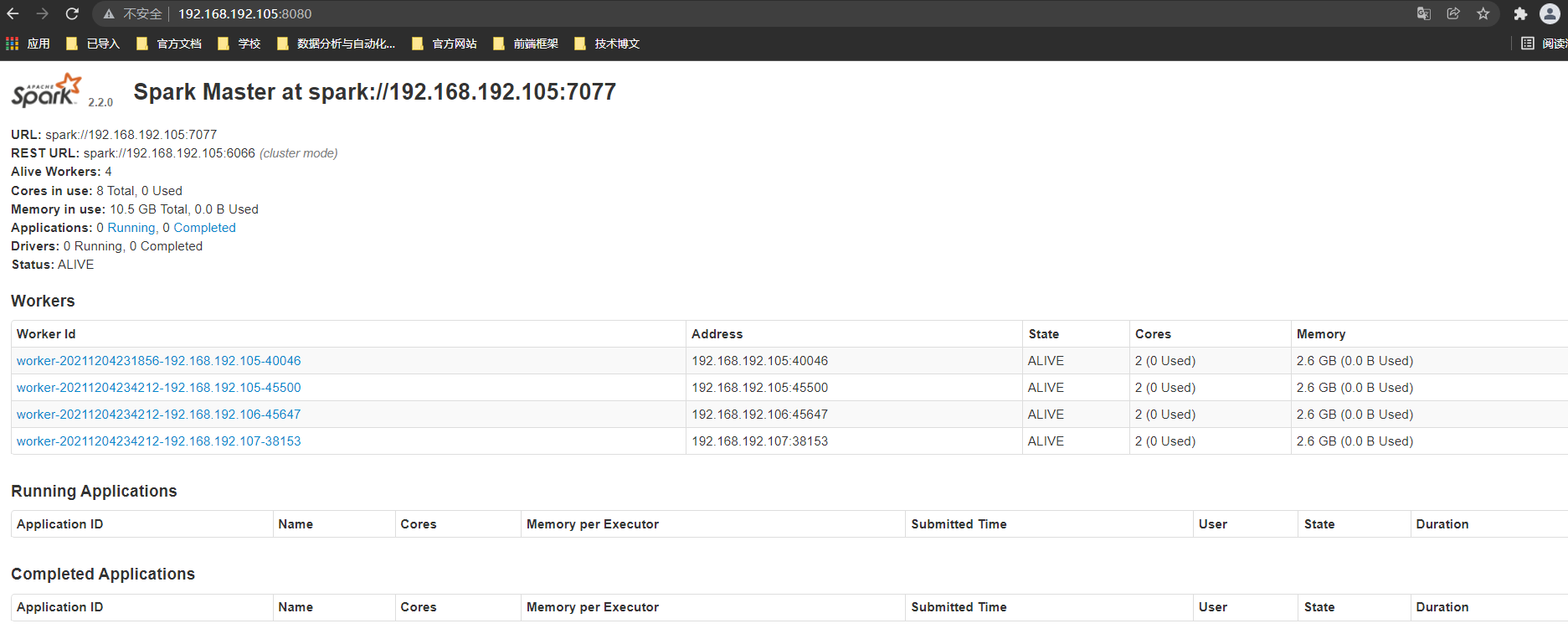
5.集群验证
做完上面的步骤之后,为了验证集群是否可以正常工作,我们需要运行一个spark任务进行测试,在spark安装包中有提供给我们测试的jar包,试着运行,成功则说明我们的集群已经可以正常使用了。运行命令如下,这里要注意的是jar包的位置需要根据你机器spark存放的路径进行修改
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node1:7077,node2:7077,node3:7077 --executor-memory 1G --total-executor-cores 2 /app/spark-2.2.0/examples/jars/spark-examples_2.11-2.2.0.jar 100
在spark的bin目录下运行之后,应该可以看到如下的输出

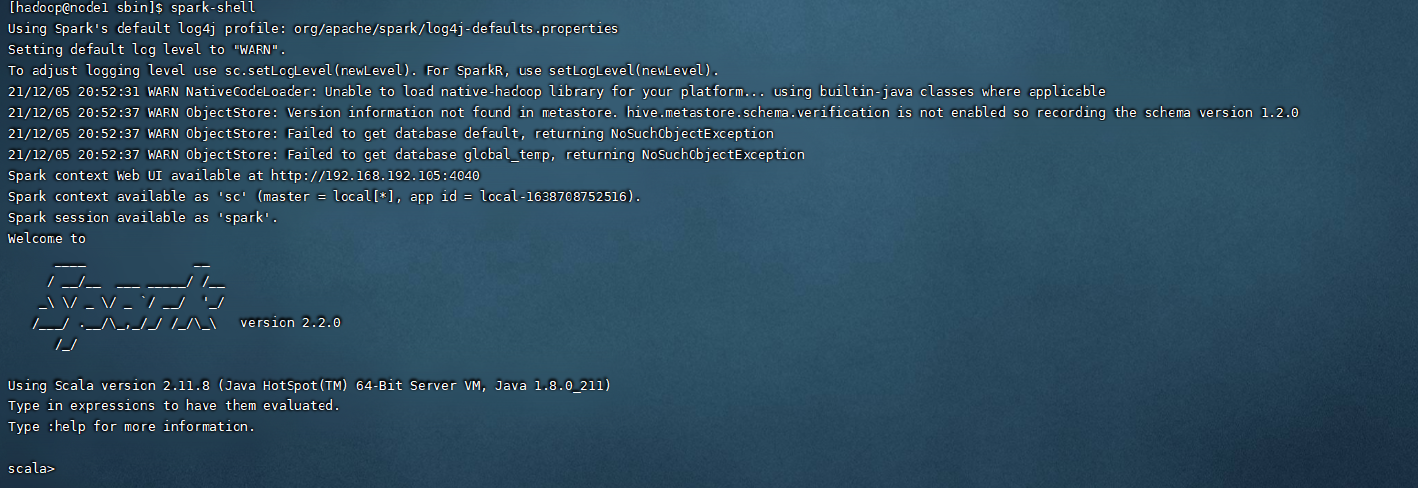
集群搭建成功之后,参照hadoop集群搭建文件进行spark的环境配置,就可以在任意目录使用spark命令了,我们尝试运行一下spark提供的命令行,spark-shell,可以看到在这里也可以进行相关命令的输入。
5.编写你的第一个Spark应用
相信了解过大数据相关框架的同学会很熟悉一个词,叫做词频统计,意思就是根据你提供文本中的单词,进行一个相关的统计,并得到每个关键词的总数,这个可以说是入门spark的时候都会进行编写的小应用,在这个专栏我们将使用scala语言进行编写,scala的语法较为简介,可以提高我们的编码效率。下面我们就是用spark编写第一个应用词频统计。
6.环境搭建
在本地运行spark项目之前,我们需要进行本地环境的搭建,这里我们使用的工具是IDEA,通过创建Maven工程的方式倒入spark的依赖与环境,Maven工程没有别的要求,创建个空的maven工程即可,工程的pop.xml依赖如下,供搭建参考,这里可以根据每个人电脑对应安装包的版本进行修改,正常来说版本不要差距太大,防止打包到集群运行时出问题。
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.7.5</hadoop.version>
<scala.version>2.12.11</scala.version>
</properties>
<!--Hadoop-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--Scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--Spark-->
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.0</version>
</dependency>
</dependencies>
7.代码编写
上面的工作准备完成之后,就可以进入代码的编写部分了,首先需要建立对应的scala项目,词频统计代码参考如下,小伙伴们可以先对照着进行编写,其中涉及到的算子以及相关内容后续都会一一介绍介绍实战。
txt文件内容
xiaochan xiaochan xiaochan
hadoop sqoop
spark hello
workcount代码
package cn.itcast.spark.xiaochan
import org.apache.spark.{SparkConf, SparkContext}
object wordcount_blog1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("workcount_blog")
val sc = new SparkContext(conf)
val work = sc.textFile("wordcount.txt路径地址")
val count = work.flatMap(word => word.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).collect()
count.foreach(println(_))
}
}
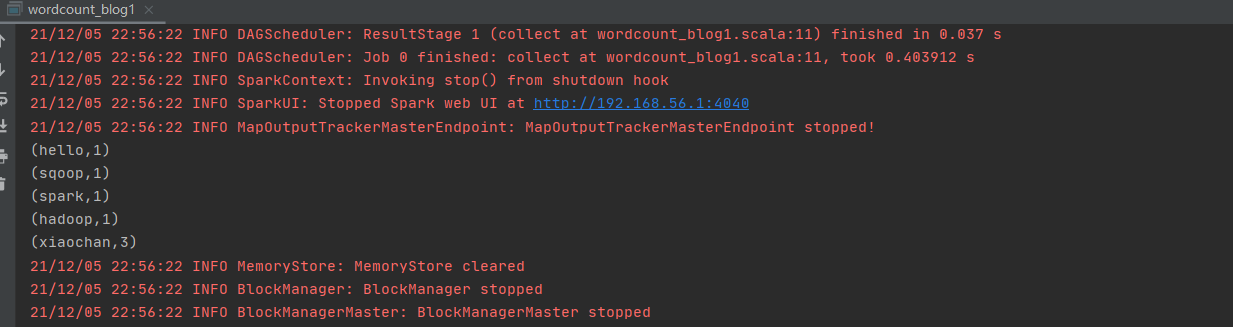
输出结果如下图,可以看到对应的词会被拆分统计。
8.总结
到这里我们就完成了集群的搭建与第一个小案例的运行,如果操作过程中遇到问题可以私信我,博主会尽力帮你解答💪。其次就是由于第一个案例的编写中涉及到了spark算子的时候,小伙伴们对着敲的时候可能会有点蒙,这个不用担心,先敲进去运行出来结果,接下来的文章将会详细对代码出现的算子以及使用方式进行说明。

- 点赞
- 收藏
- 关注作者
评论(0)