曲鸟全栈UI自动化教学(八):框架代码讲解和进一步优化

一、前言
上一章《曲鸟全栈UI自动化教学(七):使用Pytest来搭建自动化测试框架》 的教学中,我们搭建了一个自动化测试框架的雏形,做到了数据和代码的分离。这篇会为对框架代码进行讲解。
二、代码框架讲解
1. 项目目录
项目目录文件就下面五个,核心的主要在test_case.py和comDef.py这两个文件中
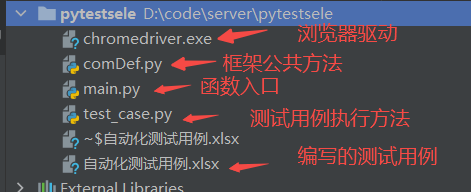
程序运行的入口文件为main.py,当我们运行main.py文件时,会执行pytest.main方法进行测试用例的注册:
import pytest
# 执行测试用例
pytest.main(['test_case.py'])
2. 核心代码讲解
上面的代码等于将test_case.py这个文件中的pytest的测试用例进行执行,test_case.py文件代码如下 (注释是对该行代码的解释说明):
import pytest
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from comDef import parse_case
# 初始化driver
driver = webdriver.Chrome() # 初始化webdriver,启动谷歌浏览器
driver.implicitly_wait(2) # 设置元素的全局等待时间为2秒,当操作元素时,元素2秒内未出现就抛出异常
driver.maximize_window() # 最大化浏览器窗口
# 调用parse_case方法,对文件名为:“自动化测试用例.xlsx”里的数据进行解析,解析为[{},{}]列表的形式,这样pytest才能够识别
@pytest.mark.parametrize("data", parse_case('自动化测试用例.xlsx'))
# data为excel中的每行记录(步骤)转换成的pytest能识别的代码:{'action': 'send_keys', 'location_method': 'XPATH', 'path': '//*[@id="account"]', 'value': 'admin'}
def test_run_case(data):
path, location_method = data.get('path'), data.get('location_method') # 获取元素地址、定位方法
action, value = data.get('action'), data.get('value') # 获取要执行的操作、和操作的值(例如;send_keys的value)
if path:
if location_method:
_driver = driver.find_element(getattr(By, location_method), path) # 寻找元素对象
# 下面为封装的具体操作,根据excel表获取的不同则执行不同的操作
if action == 'click': # 如果要执行的操作等于click则执行点击事件
_driver.click()
elif action == 'send_keys' and value:
_driver.send_keys(value)
elif value: # 没有元素路径则代表执行的操作不需要元素路径,所以下面封装的操作都是不需要元素路径的
if action == 'sleep': # 强制等待
time.sleep(float(value))
elif action == 'get':
driver.get(value)
else:
return False
上面的代码本身也有缺陷,首先我们封装的操作比较少,只有click、send_keys、get等这几个简单的操作,但如果我们封装的操作多了,按现在这样的代码写法,代码量会成倍的增加 (下面是增加了四个操作后,操作功能部分代码):
if action == 'click': # 如果要执行的操作等于click则执行点击事件
getattr(_driver, action)()
_driver.click()
elif action=='clear':
_driver.clear()
_driver.is_displayed()
elif action == 'send_keys' and value:
_driver.send_keys(value)
if action == 'sleep': # 强制等待
time.sleep(float(value))
elif action == 'get':
driver.get(value)
elif action == 'refresh':
driver.refresh()
elif action == 'quit':
driver.quit()
elif action == 'close':
driver.close()
可以看到代码量越来越多,当我们框架越来越完善的时候,增加的操作更多的时候,就会越来越难以维护,所以我们需要换一种更精简的写法来简化代码。
三、代码优化
我们还是可以通过反射来处理这些操作代码:
未使用反射时的执行操作的代码(而且随着操作增多代码量也会增加):
if action == 'click': # 如果要执行的操作等于click则执行点击事件
getattr(_driver, action)()
_driver.click()
elif action=='clear':
_driver.clear()
_driver.is_displayed()
elif action == 'send_keys' and value:
_driver.send_keys(value)
if action == 'sleep': # 强制等待
time.sleep(float(value))
elif action == 'get':
driver.get(value)
elif action == 'refresh':
driver.refresh()
elif action == 'quit':
driver.quit()
elif action == 'close':
driver.close()
使用反射时的执行操作的代码:
getattr(_driver, action)(value) if value else getattr(_driver, action)()
if action == 'sleep': # 强制等待
time.sleep(float(value))
else:
getattr(driver, action)(value) if value else getattr(driver, action)()
可以看到,代码减少了很多!而且再增加操作也不会增加我们的代码量!
完整test_case.py代码如下:
import pytest
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from comDef import parse_case
# 初始化driver
driver = webdriver.Chrome() # 初始化webdriver,启动谷歌浏览器
driver.implicitly_wait(2) # 设置元素的全局等待时间为2秒,当操作元素时,元素2秒内未出现就抛出异常
driver.maximize_window() # 最大化浏览器窗口
# 调用parse_case方法,对文件名为:“自动化测试用例.xlsx”里的数据进行解析,解析为[{},{}]列表的形式,这样pytest才能够识别
@pytest.mark.parametrize("data", parse_case('自动化测试用例.xlsx'))
# data为excel中的每行记录(步骤)转换成的pytest能识别的代码:{'action': 'send_keys', 'location_method': 'XPATH', 'path': '//*[@id="account"]', 'value': 'admin'}
def test_run_case(data):
path, location_method = data.get('path'), data.get('location_method') # 获取元素地址、定位方法
action, value = data.get('action'), data.get('value') # 获取要执行的操作、和操作的值(例如;send_keys的value)
if path:
if location_method:
_driver = driver.find_element(getattr(By, location_method), path) # 寻找元素对象
# 通过反射封装操作,根据excel表获取的不同则执行不同的操作
getattr(_driver, action)(value) if value else getattr(_driver, action)()
elif value: # 没有元素路径则代表执行的操作不需要元素路径,所以下面封装的操作都是不需要元素路径的
if action == 'sleep': # 强制等待
time.sleep(float(value))
else:
# 通过反射封装操作,根据excel表获取的不同则执行不同的操作
getattr(driver, action)(value) if value else getattr(driver, action)()
else:
return False
四、测试用例填写优化
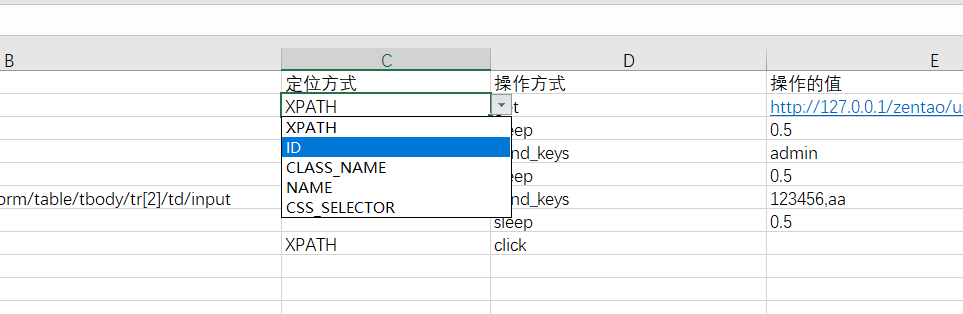
我们之前测试用例在excel中编写的,指定操作步骤和定位方法都是输入进去,其实我们可以做一个下来菜单来选择:
下拉选择定位方式:
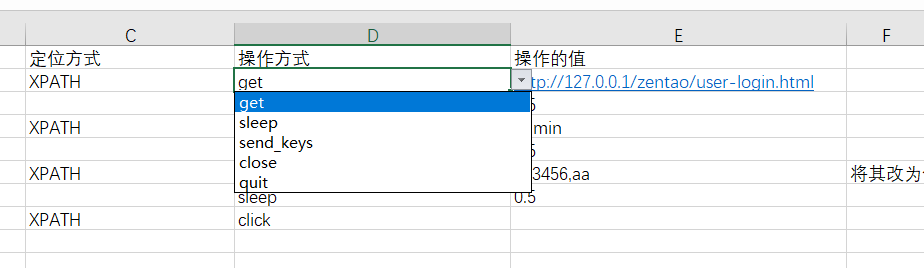
下拉选择操作方式:
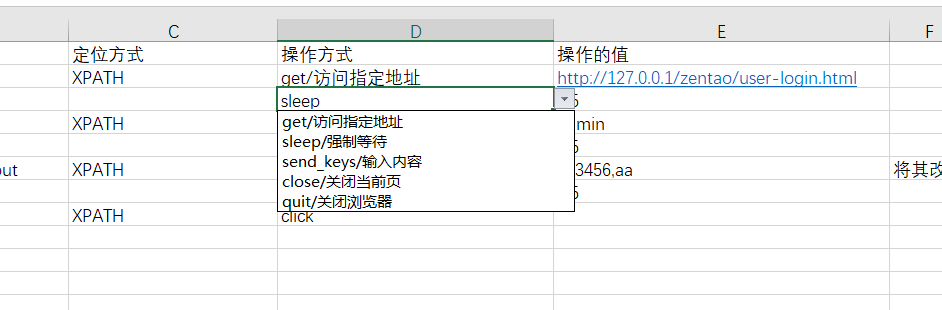
甚至我们还可以改成中文 (相应的解析代码需要做修改(根据/分割,取最前)):
这样写起来就方便一些了,能够提升一些我们的编写效率。
五、总结
其实我们常说的自动化测试平台,最直观的也就是将编写编写用例这部分操作放在了平台上进行 (下图是我们自建的自动化测试平台编辑用例的截图):
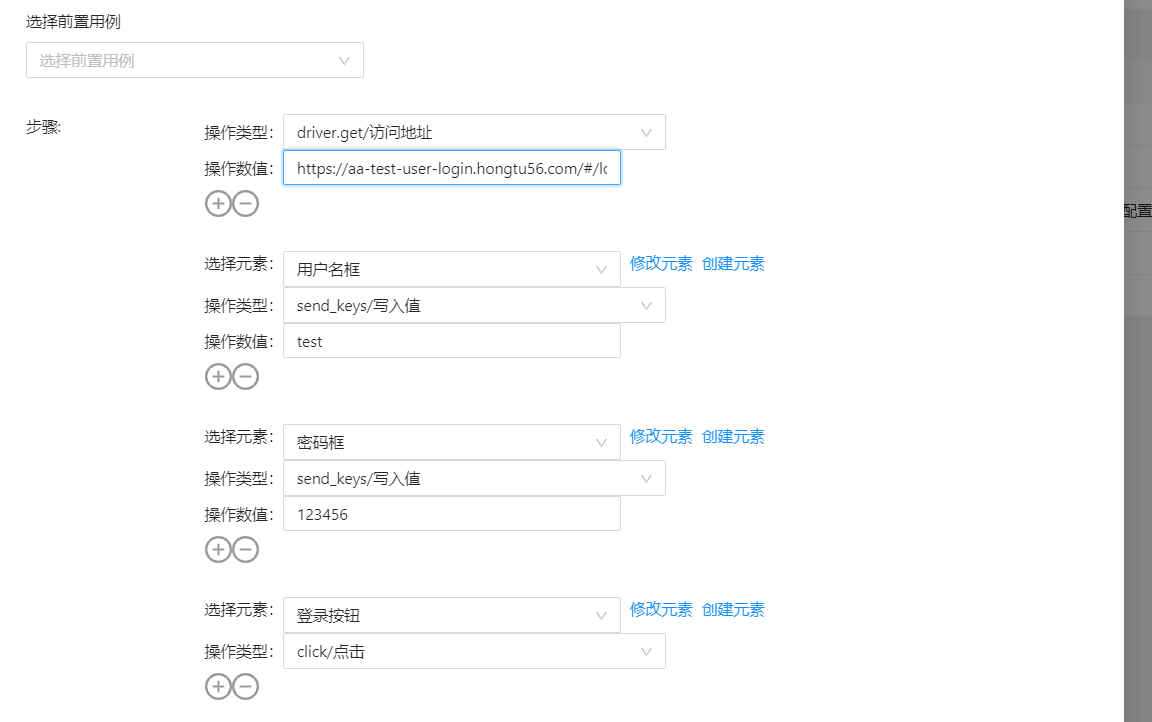
将各个操作元素、类型以及填写的值都都通过图形化操作的方法进行编辑,而用例、页面元素都通过平台进行管理:
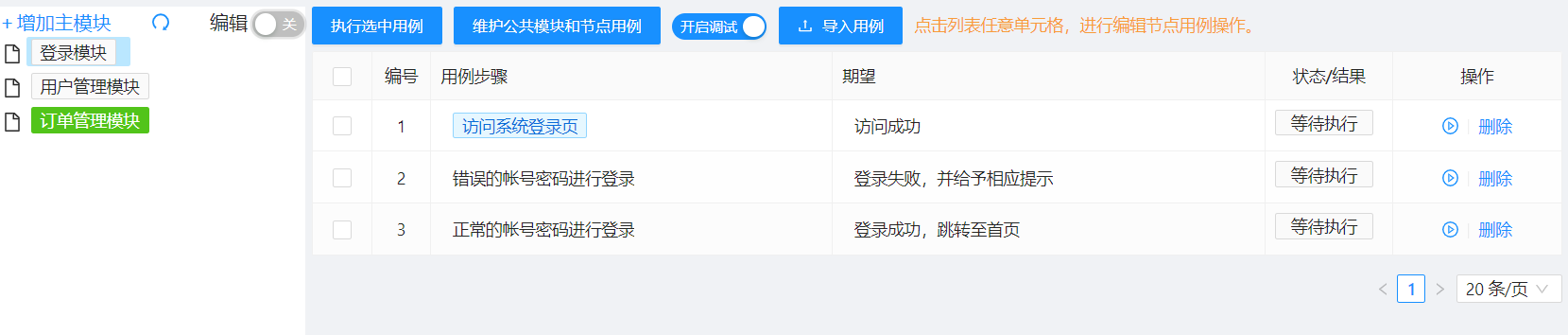
执行操作和结果验证、生成测试报告、定时执行、元素维护等,甚至是失败重跑、重试这些机制都交由后台服务处理。
让编写自动化用例的过程更纯粹,只需要通过“点点点”的方式就能够实现,以至于让完全不懂代码的用户也能够编写自动化测试用例。但构建自动化测试平台的成本是极高的! 所以是选择构建自动化测试平台、还是excel驱动或者其他方式的自动化测试需要根据公司对自动化这一块投入的占比来选择。
另外,无论是我们说的关键字驱动、数据代码分离,还是本教程所建立的框架,都是为了让自动化测试变得简单高效,但在个人接触中发现,有些同行业的小伙伴,花了不少精力去使用各种各样的框架,感觉很高端、很厉害、但当编写用例的时候维护成本反而越来越高。甚至为了能够上手编写自动化用例,还需要花一周、两周去熟悉框架、代码。本来是化繁为简的过程反而弄的越来越复杂,这是得不偿失的!
自动化测试本就是一个回报与投入比较低的事情,而为了这个事情维护了一套框架,不能够提高自动化用例的编写效率,这也是非常讽刺的一件事情。
这里我想表达的主要意思就是:学习自动化可能不同的企业、不同的小伙伴选择的技术架构、框架都不一样,实际不需要去纠结该如何作选择。无论是pytest、allure、robotframework、selenium、airtest都是辅助你进行自动化的工具。最重要的是自己一定要去思考、自己建立的自动化是不是简单高效,易于维护和上手,以及你的企业需要怎样的自动化、什么样的自动化才适合你们的企业才是关键的。

- 点赞
- 收藏
- 关注作者
评论(0)