【愚公系列】2021年12月 Python教学课程 04-字符串

一、字符串类型 str
1 字符串类型的定义
字符串是 Python 中最常用的数据类型之一,使用单引号或双引号来创建字符串,使用
三引号创建多行字符串。
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
字符串是不可变的序列数据类型,不能直接修改字符串本身,和数字类型一样!
虽然字符串本身不可变,但可以通过方括号加下标的方式,访问或者获取它的子串,当
然也包括切片操作。这一切都不会修改字符串本身,当然也符合字符串不可变的原则。
>>> s = "hello world!"
>>> s[4]
'o'
>>> s[2:6]
'llo '
>>> s
'hello world!'
Python3 全面支持 Unicode 编码,所有的字符串都是 Unicode 字符串,可以放心大胆的
使用中文。
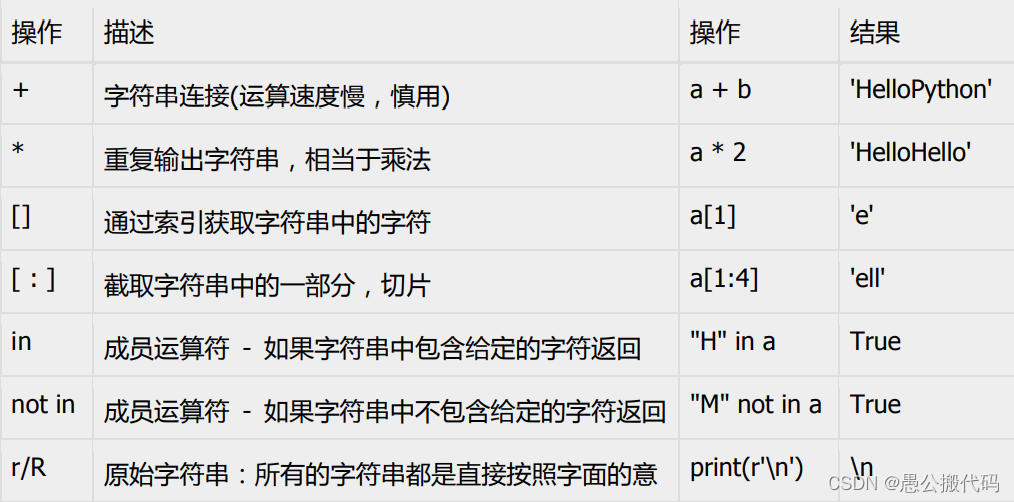
2 字符串的运算:
下表实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
3 Python 转义字符:
编程语言里,有很多特殊字符,它们起着各种各样的作用。有些特殊字符没有办法用普
通字符表示,需要进行转义。python 用反斜杠()转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \ (在行尾时) | 续行符 |
| \ \ | 反斜杠符号 |
| \’ | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy 代表的字符,例如:\o12 代表换行 |
| \xyy | 十六进制数,yy 代表的字符,例如:\x0a 代表换行 |
| \033 | 颜色控制 |
4 “多行字符串”
在字符串中,可以使用三引号(三单或三双引号都可以)编写跨行字符串,在其中可以
包含换行符、制表符以及其他特殊字符。例如:
cursor.execute('''
CREATE TABLE users (
login VARCHAR(8),
uid INTEGER,
prid INTEGER)
''')
上面的 cursor.execute 执行了一个创建 users 表的 SQL 语句。多行字符串本质上和普通
字符串没有区别,但是将我们从引号和特殊字符串的泥潭里面解脱出来了,在编写、排
版、查看、维护上更人性化。
5 字符串内置方法
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| bytes.decode(encoding=‘UTF-8’, errors=‘strict’) | Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象 |
| string.encode(encoding=‘UTF-8’, errors=‘strict’) | 以 encoding 指定的编码格式编码 string,编码的结果是一个bytes对象。如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果 beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟 find()方法一样,只不过如果 str 不在 string 中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以string作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab]) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元组 (string_pre_str,str,string_post_str),如果 string 中不包含 str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string)) | 类似于 find()函数,不过是从右边开始查找. |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是从右边开始. |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找. |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str="", num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num 个子字符串 |
| string.splitlines([keepends]) | 按照行(’\r’,’\r\n’,\n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果 beg 和 end 指定值,则在指定范围内检查. |
| string.strip([obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del="") | 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充 0 |
字符串是 Python 中和列表、字典同样重要的数据类型,对它的操作特别多,因此内置
了很多方法。
几个重要的方法
- encode() # 编码成 bytes 类型
- find() # 查找子串
- index() # 获取下标
- replace() # 替换子串
- len(string) # 返回字符串长度,Python 内置方法,非字符串方法。
- lower() # 小写字符
- upper() # 大写字符
- split() # 分割字符串
- strip() # 去除两端的指定符号
- startswith() # 字符串是否以 xxx 开头
- endswith() # 字符串是否以 xxx 结尾
6 格式化方法
我们经常会输出类似’亲爱的 xxx 你好!你 xx 月的话费是 xx,余额是 xx’之类的字符串,
而 xxx 的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
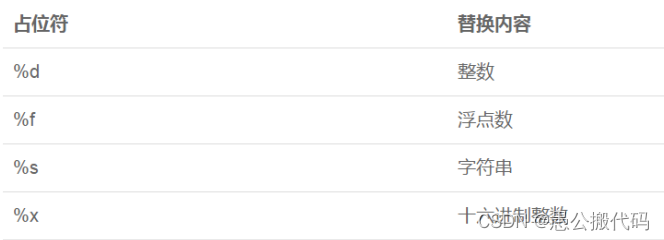
6.1 占位符
在 Python 中,用%实现格式化,举例如下:
>>> 'Hello, %s' % 'world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
%s 表示用字符串替换,%d 表示用整数替换,有几个%?占位符,后面就跟几个变量或
者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
其中,格式化整数和浮点数还可以指定是否补 0 和整数与小数的位数,例如:
print('%2d-%02d' % (3, 1))
print('%.2f' % 3.1415926)
如果你不太确定应该用什么,%s 永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表
示一个%:
>>> 'growth rate: %d %%' % 7
6.2 format()方法
fromat()方法是字符串的内置方法,其基本语法如下:
参数列表:[[fill][align][sign][#][0][width][,][.precision][type]]
简单的 format 格式化方法基本有两类:
1.{0}、{1}、{2}:这一类是位置参数,引用必须按顺序,不能随意调整,否则就乱了。
例如:
tpl = “i am {0}, age {1}, really {0}”.format(“seven”, 18)
2.{name}、{age}、{gender}:这一类是关键字参数,引用时必须以键值对的方式,可
以随意调整顺序。例如:
tpl = “i am {name}, age {age}, really {name}”.format(name=“seven”, age=18)
7 字符串颜色控制
有时候我们需要对有用的信息设置不同颜色来达到强调、突出、美观的效果,在命令行
或 linux 终端中,颜色是用转义序列控制的,转义序列是以 ESC 开头,在代码中用\033
表示(ESC 的 ASCII 码用十进制表示就是 27,等于用八进制表示的 33,\0 表示八进制)。
注意:颜色控制只在终端界面中有效。
格式:\033[显示方式;前景色;背景色 m 正文\033[0m
| 前景色 | 背景色 | 颜色 |
|---|---|---|
| 前景色 | 背景色 颜 | 色 |
| 30 | 40 | 黑色 |
| 31 | 41 | 红色 |
| 32 | 42 | 绿色 |
| 33 | 43 | 黃色 |
| 34 | 44 | 蓝色 |
| 35 | 45 | 紫红色 |
| 36 | 46 | 青蓝色 |
| 37 | 47 | 白色 |
显示方式:
| 显示方式 | 意义 |
|---|---|
| 0 | 终端默认设置 |
| 1 | 高亮显示 |
| 4 | 使用下划线 |
| 5 | 闪烁 |
| 7 | 反白显示 |
| 8 | 不可见 |
例子:
\033[1;31;40m 1-高亮显示 31-前景色红色 40-背景色黑色
\033[0m 采用终端默认设置,也就是取消颜色设置
8 字符编码
计算机只能处理数字 01,如果要处理文本,就必须先把文本转换为数字 01,这种转换
方式就称为字符编码。
对于我们而言,你只需要简单记住下面几种编码就好:
ASCII 编码:早期专门为英语语系编码,只有 255 个字符,每个字符需要 8 位也就是 1
个字节。不兼容汉字。
Unicode 编码:又称万国码,国际组织制定的可以容纳世界上所有文字和符号的字符编
码方案。用 2 个字节来表示汉字。
UTF-8 编码:为了节省字节数,在 Unicode 的基础上进行优化的编码。用 1 个字节表示
英文字符,3 个字符表示汉字。天生兼容 ASCII 编码,所以最为流行。
GB2312:我国早期自己制定的中文编码,世界范围内不通用。
GBK: 全称《汉字内码扩展规范》,向下与 GB2312 兼容,向上支持 ISO10646.1 国际
标准,是前者向后者过渡过程中的一个承上启下的产物。windows 中文版的汉字编码用
的就是 GBK。也非世界范围通用的编码
其它编码:非以上类型者的统称。属于能不用就不要碰的编码。
最后再强调一次,Python3 在运行时全部使用 Unicode 编码

- 点赞
- 收藏
- 关注作者
评论(0)