Spark MLlib – Apache Spark 的机器学习库

Spark MLlib是 Apache Spark 的机器学习组件。 Spark 的主要吸引力之一是能够大规模扩展计算,而这正是机器学习算法所需要的。但局限性是所有机器学习算法都无法有效并行化。每个算法都有自己的并行化挑战,无论是任务并行还是数据并行。
话虽如此,Spark 正在成为构建机器学习算法和应用程序的事实上的平台。 好吧,在继续阅读博客之前,您可以查看由行业专家策划的Spark 课程。 在 Spark MLlib 上工作的开发人员正在 Spark 框架中以可扩展和简洁的方式实现越来越多的机器算法。通过这个博客,我们将学习机器学习的概念、Spark MLlib、它的实用程序、算法和电影推荐系统的完整用例。
本博客将涵盖以下主题:
什么是机器学习?
从人工智能中的模式识别和计算学习理论的研究发展而来,机器学习探索了可以从数据中学习和预测的算法的研究和构建——这些算法通过做出数据驱动的预测或决策来克服严格遵循静态程序指令的问题,通过从样本输入构建模型。
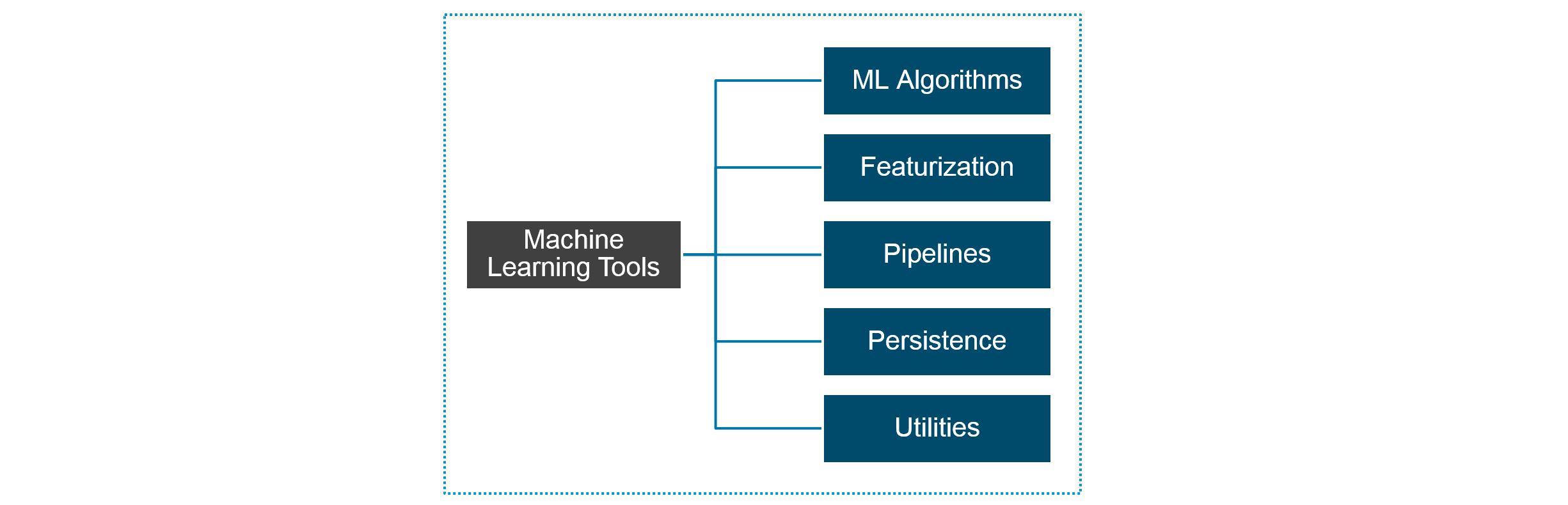
图: 机器学习工具
机器学习与计算统计学密切相关,计算统计学也侧重于通过使用计算机进行预测。它与数学优化有着密切的联系,数学优化为该领域提供了方法、理论和应用领域。在数据分析领域,机器学习是一种用于设计复杂模型和算法的方法,这些模型和算法适用于商业用途中称为预测分析的预测。
机器学习任务分为三类:
- 监督学习:监督学习是指您有输入变量 (x) 和输出变量 (Y),并使用算法来学习从输入到输出的映射函数。
- 无监督学习:无监督学习是一种机器学习算法,用于从由没有标记响应的输入数据组成的数据集中得出推论。
- 强化学习:计算机程序与动态环境交互,在该环境中它必须执行某个目标(例如驾驶车辆或与对手玩游戏)。该程序在导航其问题空间时会获得奖励和惩罚方面的反馈。这个概念被称为强化学习。
Spark MLlib 概述
Spark MLlib 用于在 Apache Spark 中执行机器学习。MLlib 包含流行的算法和实用程序。
MLlib 概述:
- spark.mllib 包含构建在RDD 之上的原始 API。它目前处于维护模式。
- spark.ml提供了构建在 DataFrames 之上的更高级别的 API,用于构建机器学习管道。spark.ml 是目前 Spark 的主要机器学习 API。
Spark MLlib 工具
Spark MLlib 提供以下工具:
- ML 算法: ML 算法构成了 MLlib 的核心。其中包括常见的学习算法,例如分类、回归、聚类和协同过滤。
- 特征化:特征化包括特征提取、变换、降维和选择。
- 管道: 管道提供用于构建、评估和调整 ML 管道的工具。
- 持久性: 持久性有助于保存和加载算法、模型和流水线。
- 公用事业: 公用事业用于线性代数、统计和数据处理。
MLlib 算法
Spark MLlib 中流行的算法和实用程序是:
- Basic Statistics
- Regression
- Classification
- Recommendation System
- Clustering
- Dimensionality Reduction
- Feature Extraction
- Optimization
让我们详细看看其中的一些。
基本统计
基本统计包括最基本的机器学习技术。这些包括:
- 汇总统计:示例包括均值、方差、计数、最大值、最小值和 numNonZeros。
- 相关性:Spearman 和 Pearson 是找到相关性的一些方法。
- 分层抽样:包括 sampleBykey 和 sampleByKeyExact。
- 假设检验:Pearson 的卡方检验是假设检验的一个例子。
- 随机数据生成:RandomRDDs、Normal 和 Poisson 用于生成随机数据。
回归
回归分析是估计变量之间关系的统计过程。当重点是因变量与一个或多个自变量之间的关系时,它包括许多建模和分析多个变量的技术。更具体地说,回归分析有助于理解当任何一个自变量发生变化而其他自变量保持固定时,因变量的典型值如何变化。
回归分析广泛用于预测和预测,其使用与机器学习领域有很大的重叠。回归分析还用于了解自变量中哪些与因变量相关,并探索这些关系的形式。在有限的情况下,回归分析可用于推断自变量和因变量之间的因果关系。
分类
分类 是根据包含类别成员已知的观察(或实例)的训练数据集来识别新观察属于一组类别(子种群)中的哪一个的问题。这是模式识别的一个例子。
在这里,一个例子是将给定的电子邮件分配到“垃圾邮件”或“非垃圾邮件”类别中,或者根据观察到的患者特征(性别、血压、是否存在某些症状、等等。)。
推荐系统
一个推荐系统 是信息过滤系统,试图预测的“评级”或“偏爱”,用户将给予项目的一个子类。近年来,推荐系统变得越来越流行,并被广泛应用于电影、音乐、新闻、书籍、研究文章、搜索查询、社交标签和一般产品等各个领域。
推荐系统通常以两种方式之一生成推荐列表——通过协作和基于内容的过滤或基于个性的方法。
- 协作过滤方法根据用户过去的行为(之前购买或选择的项目和/或对这些项目的数字评级)以及其他用户做出的类似决定来构建模型。然后使用该模型来预测用户可能感兴趣的项目(或项目的评分)。
- 基于内容的过滤方法利用项目的一系列离散特征来推荐具有相似属性的其他项目。
此外,这些方法通常组合为混合推荐系统。
聚类
聚类是将一组对象以这样的方式分组的任务,即同一组(称为集群)中的对象彼此之间比其他组(集群)中的对象更相似(在某种意义上或另一种意义上)。因此,它是探索性数据挖掘的主要任务,也是统计数据分析的常用技术,用于许多领域,包括机器学习、模式识别、图像分析、信息检索、生物信息学、数据压缩和计算机图形学。
降维
降维 是通过获得一组主要变量来减少所考虑的随机变量数量的过程。可分为特征选择和特征提取。
- 特征选择:特征选择找到原始变量(也称为特征或属性)的子集。
- 特征提取:将高维空间中的数据转换为维数较少的空间。数据变换可能是线性的,如主成分分析 (PCA),但也存在许多非线性降维技术。
特征提取
特征提取从一组初始测量数据开始,并构建旨在提供信息和非冗余的派生值(特征),促进后续的学习和泛化步骤,并在某些情况下导致更好的人类解释。这与降维有关。
优化
优化 是 从一组可用的备选方案中选择最佳元素(关于某些标准)。
在最简单的情况下,优化问题包括通过系统地从允许的集合中选择输入值并计算函数值来最大化或最小化实际函数。优化理论和技术对其他公式的推广包含了大量的应用数学领域。更一般地说,优化包括在给定定义的域(或输入)的情况下找到某些目标函数的“最佳可用”值, 包括各种不同类型的目标函数和不同类型的域。
用例 - 电影推荐系统
问题陈述: 构建一个电影推荐系统,使用Apache Spark根据用户的喜好推荐电影。
我们的要求:
因此,让我们评估构建电影推荐系统的要求:
- 处理海量数据
- 来自多个来源的输入
- 使用方便
- 快速处理
由于我们可以评估我们的需求,因此我们需要最好的大数据工具来在短时间内处理大数据。因此,Apache Spark是实现我们的电影推荐系统的完美工具。
现在让我们看看我们系统的流程图。

如我们所见,以下使用来自 Spark Streaming 的 Streaming。我们可以实时流式传输或从 Hadoop HDFS 读取数据。
获取数据集:
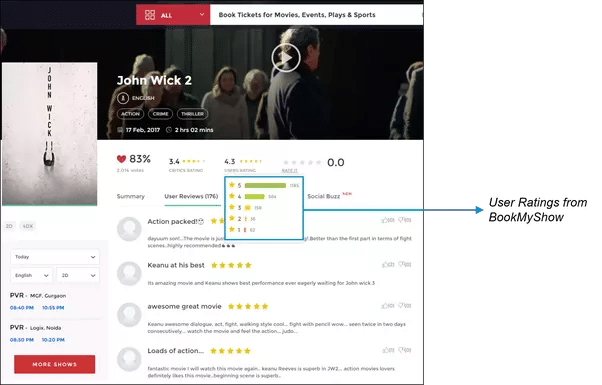
对于我们的电影推荐系统,我们可以从 IMDB、Rotten Tomatoes 和 Times Movie Ratings 等许多流行网站获取用户评分。该数据集有多种格式,例如 CSV 文件、文本文件和数据库。我们可以从网站实时流式传输数据,也可以下载并将它们存储在我们的本地文件系统或 HDFS 中。

数据集:
下图显示了我们如何从流行网站收集数据集。
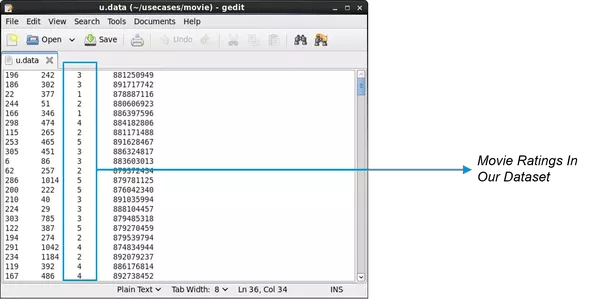
一旦我们将数据流式传输到 Spark 中,它看起来有点像这样。
机器学习:
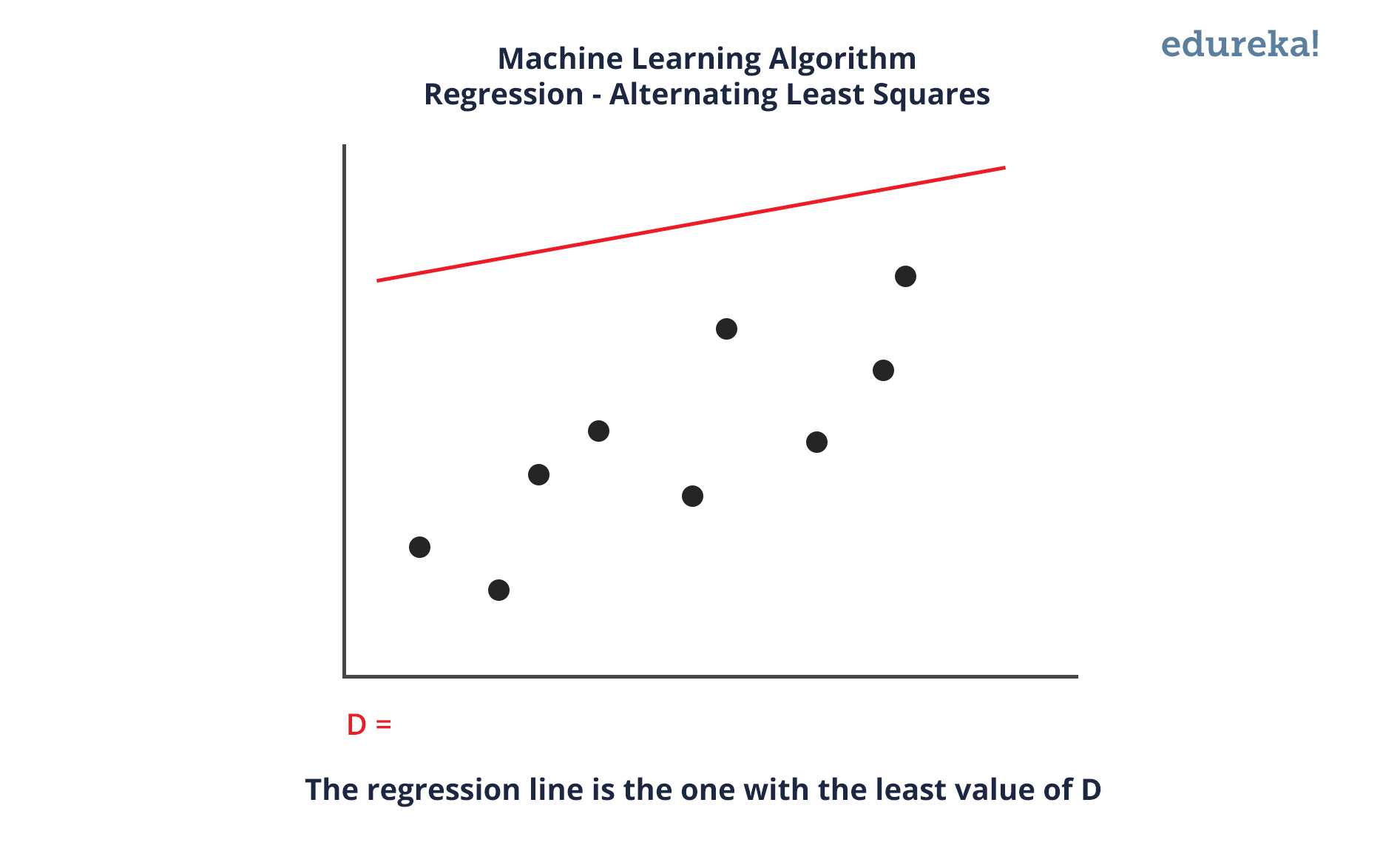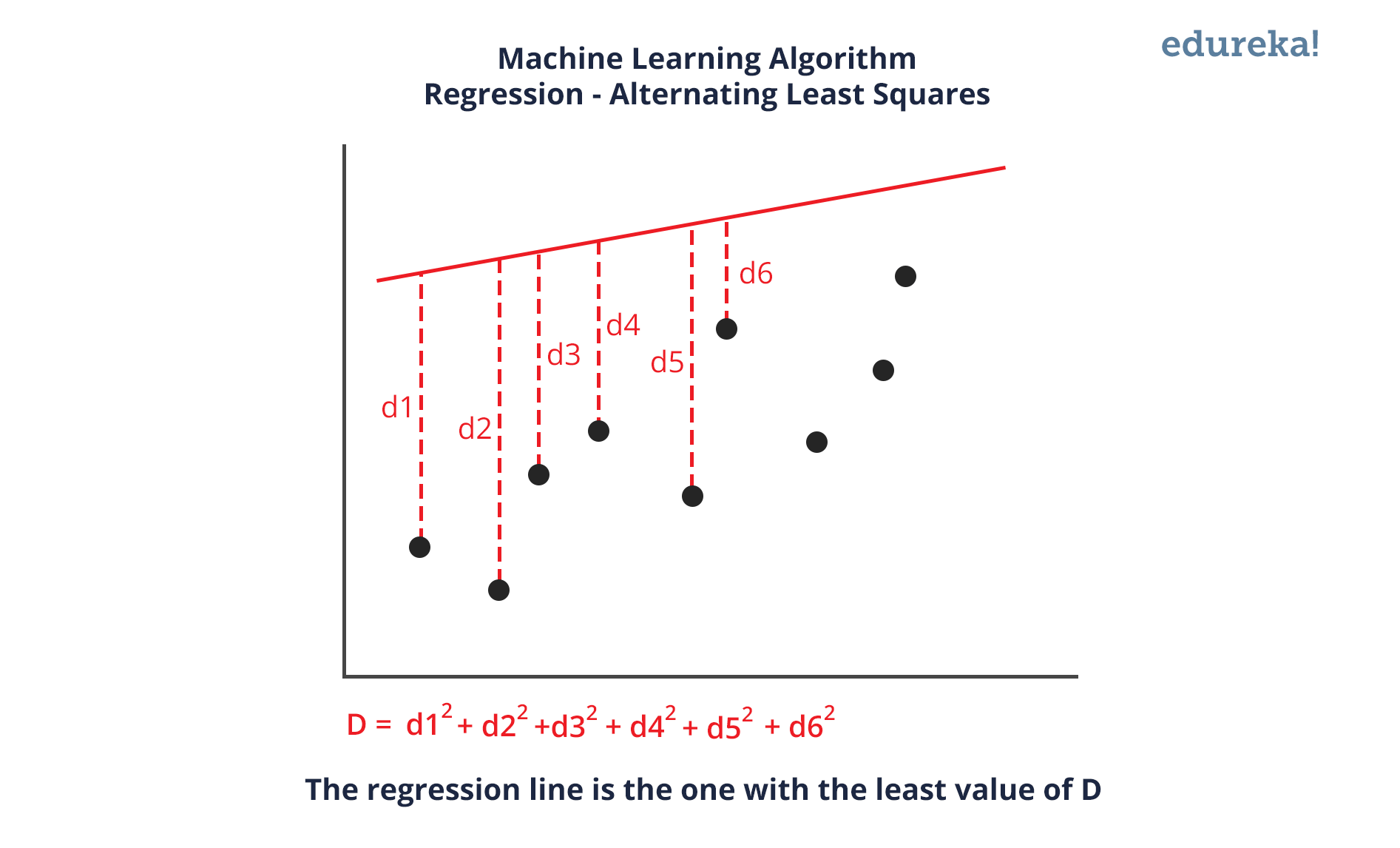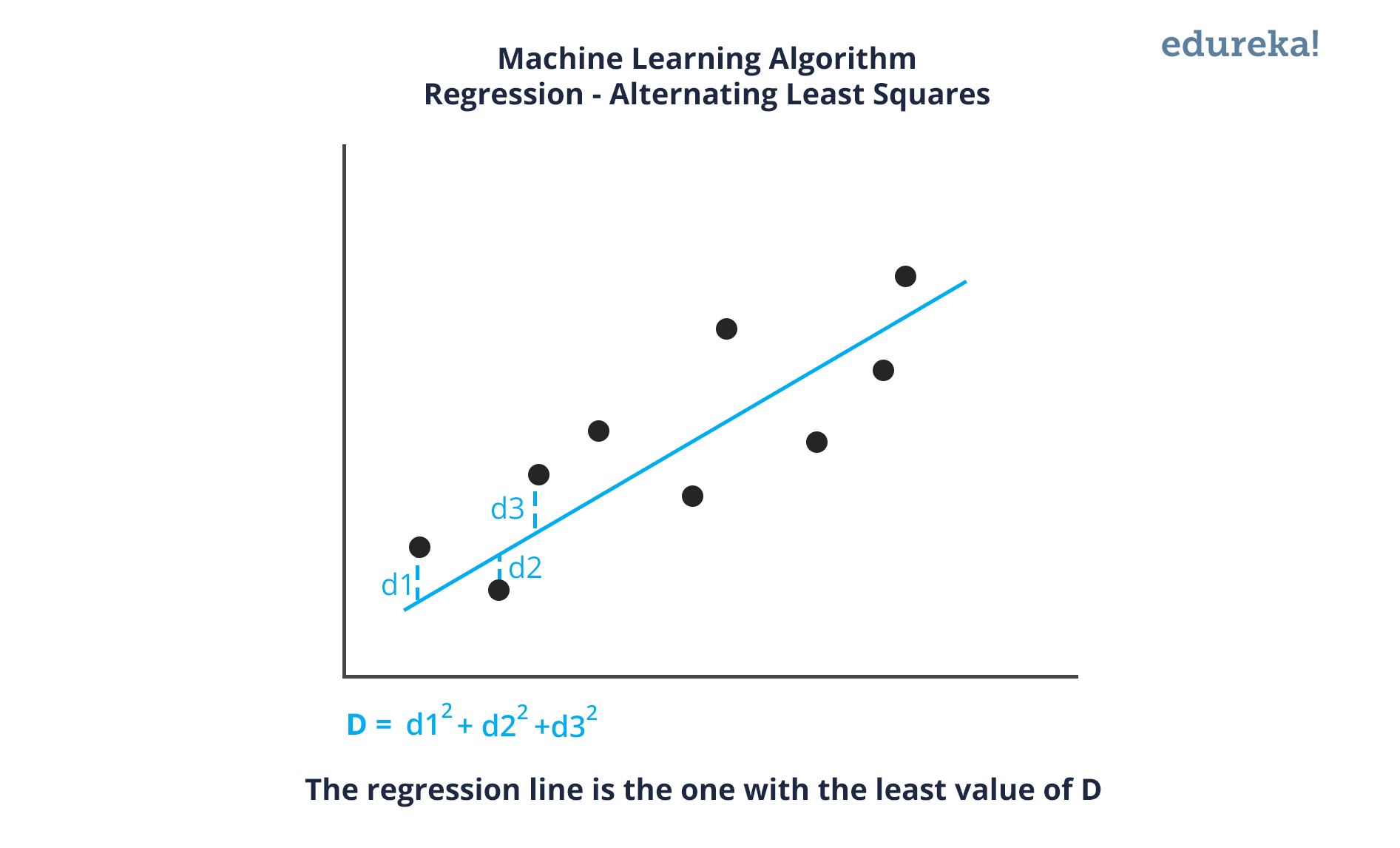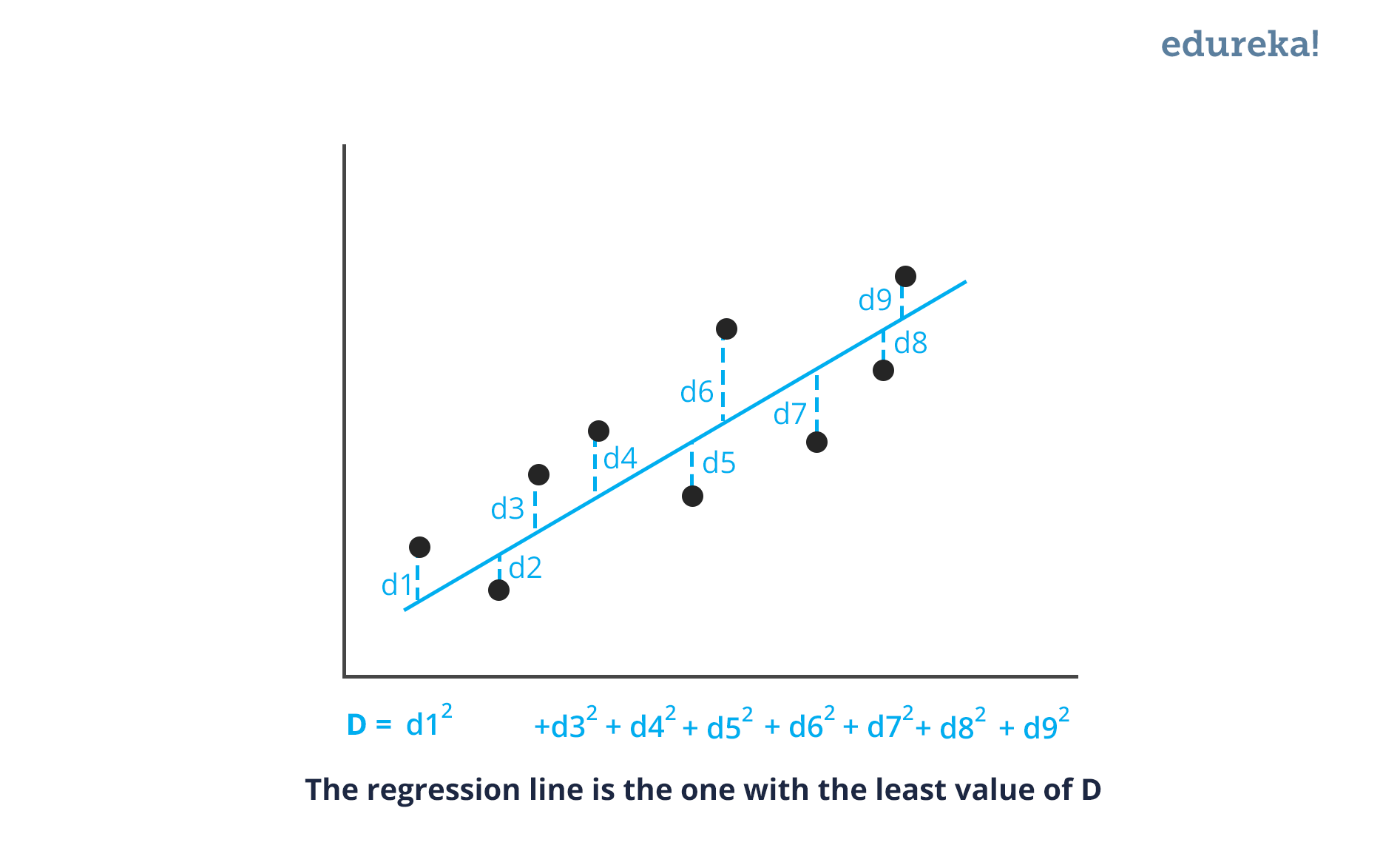
整个推荐系统基于机器学习算法交替最小二乘法。在这里,ALS 是一种回归分析,其中回归用于在数据点之间画一条线,以使与每个数据点的距离的平方和最小化。因此,这条线随后用于预测函数在满足自变量值的情况下的值。
图中的蓝线是最佳拟合回归线。对于这条线,维度 D 的值是最小的。所有其他红线将始终远离整个数据集。
Spark MLlib 实现:
- 我们将使用协同过滤 (CF) 根据用户对其他电影的评分来预测用户对特定电影的评分。
- 然后我们将其与其他用户对该特定电影的评分进行协作。
- 为了从我们的机器学习中获得以下结果,我们需要使用 Spark SQL 的 DataFrame、Dataset 和 SQL Service。
这是我们程序的伪代码:
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.Rating
import org.apache.spark.SparkConf
//Import other necessary packages
object Movie {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Movie").setMaster("local[2]")
val sc = new SparkContext(conf)
val rawData = sc.textFile(" *Read Data from Movie CSV file* ")
//rawData.first()
val rawRatings = rawData.map( *Split rawData on tab delimiter* )
val ratings = rawRatings.map { *Map case array of User, Movie and Rating* }
//Training the data
val model = ALS.train(ratings, 50, 5, 0.01)
model.userFeatures
model.userFeatures.count
model.productFeatures.count
val predictedRating = *Predict for User 789 for movie 123*
val userId = *User 789*
val K = 10
val topKRecs = model.recommendProducts( *Recommend for User for the particular value of K* )
println(topKRecs.mkString("
"))
val movies = sc.textFile(" *Read Movie List Data* ")
val titles = movies.map(line => line.split("|").take(2)).map(array => (array(0).toInt,array(1))).collectAsMap()
val titlesRDD = movies.map(line => line.split("|").take(2)).map(array => (array(0).toInt,array(1))).cache()
titles(123)
val moviesForUser = ratings.*Search for User 789*
val sqlContext= *Create SQL Context*
val moviesRecommended = sqlContext.*Make a DataFrame of recommended movies*
moviesRecommended.registerTempTable("moviesRecommendedTable")
sqlContext.sql("Select count(*) from moviesRecommendedTable").foreach(println)
moviesForUser. *Sort the ratings for User 789* .map( *Map the rating to movie title* ). *Print the rating*
val results = moviesForUser.sortBy(-_.rating).take(30).map(rating => (titles(rating.product), rating.rating))
}
}生成预测后,我们可以使用 Spark SQL 将结果存储到 RDBMS 系统中。此外,这可以显示在 Web 应用程序上。
结果:
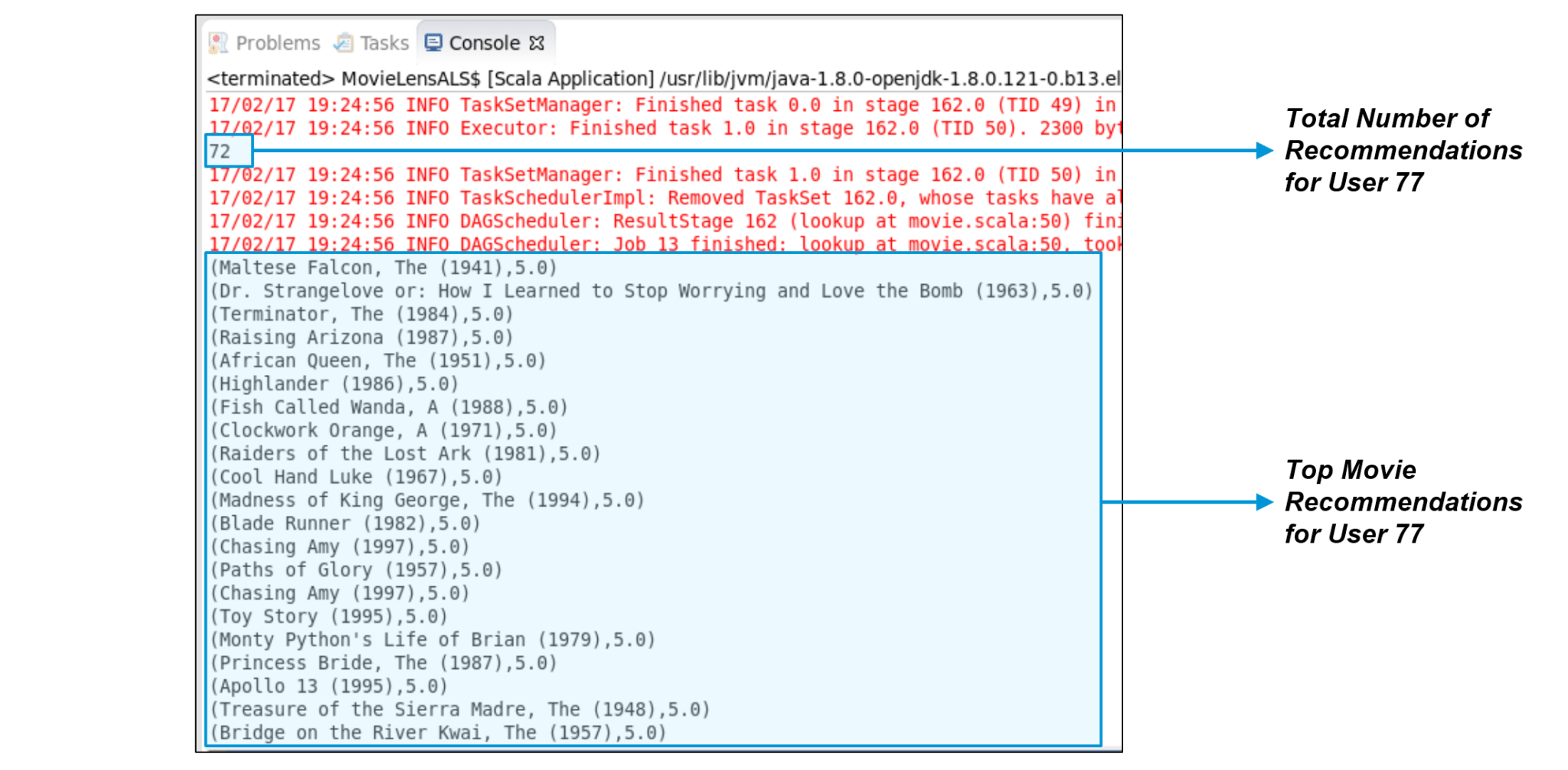
图: 推荐给用户77的电影
欢呼!因此,我们使用 Apache Spark 成功创建了一个电影推荐系统。有了这个,我们只介绍了 Spark MLlib 必须提供的众多流行算法之一。我们将在即将发布的关于数据科学算法的博客中了解有关机器学习的更多信息。

- 点赞
- 收藏
- 关注作者
评论(0)