Spark SQL 教程 - 通过示例了解 Spark SQL

Apache Spark 是一个闪电般的集群计算框架,专为快速计算而设计。随着大数据生态系统中实时处理框架的出现,公司在其解决方案中严格使用 Apache Spark。Spark SQL 是 Spark 中的一个新模块,它将关系处理与 Spark 的函数式编程 API 集成在一起。它支持通过 SQL 或 Hive 查询语言查询数据。通过这篇博客,我将向您介绍 Spark SQL 这个令人兴奋的新领域。
以下提供了博客的故事情节:
- 什么是 Spark SQL?
- 为什么使用 Spark SQL?
- Spark SQL 是如何工作的?
- Spark SQL 库
- Spark SQL 的特点
- 使用 Spark SQL 查询
- 将模式添加到 RDD
- 作为关系的 RDD
- 在内存中缓存表
什么是 Spark SQL?
Spark SQL 将关系处理与 Spark 的函数式编程相结合。它提供对各种数据源的支持,并使可以将 SQL 查询与代码转换编织在一起,从而产生一个非常强大的工具。
为什么使用 Spark SQL?
Spark SQL 起源于 Apache Hive,运行在 Spark 之上,现在与 Spark 堆栈集成。Apache Hive 有如下所述的某些限制。Spark SQL 旨在克服这些缺点并取代 Apache Hive。
Spark SQL 比 Hive 更快吗?
在处理速度方面,Spark SQL 比 Hive 更快。下面我列出了 Hive 对 Spark SQL 的一些限制。
Hive 的限制:
- Hive 在内部启动 MapReduce 作业以执行即席查询。 在分析中型数据集(10 到 200 GB)时,MapReduce 的性能滞后。
- Hive 没有恢复功能。这意味着,如果处理在工作流程中间终止,您将无法从卡住的地方恢复。
- 当垃圾被启用并导致执行错误时,Hive 无法级联删除加密的数据库。为了克服这个问题,用户必须使用清除选项来跳过垃圾而不是丢弃。
这些缺点让位于 Spark SQL 的诞生。但仍然存在于我们大多数人脑海中的问题是,
Spark SQL 是数据库吗?
Spark SQL 不是一个数据库,而是一个用于结构化数据处理的模块。它主要适用于作为编程抽象的 DataFrames,通常充当分布式 SQL 查询引擎。
Spark SQL 是如何工作的?
让我们探索一下 Spark SQL 必须提供的功能。Spark SQL 模糊了 RDD 和关系表之间的界限。它通过与 Spark 代码集成的声明性 DataFrame API,在关系处理和过程处理之间提供了更紧密的集成。它还提供了更高的优化。DataFrame API 和 Datasets API 是与 Spark SQL 交互的方式。
借助 Spark SQL,更多用户可以访问 Apache Spark,并改进了对当前用户的优化。 Spark SQL 提供了 DataFrame API,可以对外部数据源和 Spark 的内置分布式集合执行关系操作。它引入了一个名为 Catalyst 的可扩展优化器,因为它有助于支持大数据中的各种数据源和算法。
Spark 可以在 Windows 和类 UNIX 系统(例如 Linux、Microsoft、Mac OS)上运行。在一台机器上本地运行很容易——你只需要在你的系统PATH上安装java ,或者指向 Java 安装的JAVA_HOME环境变量。
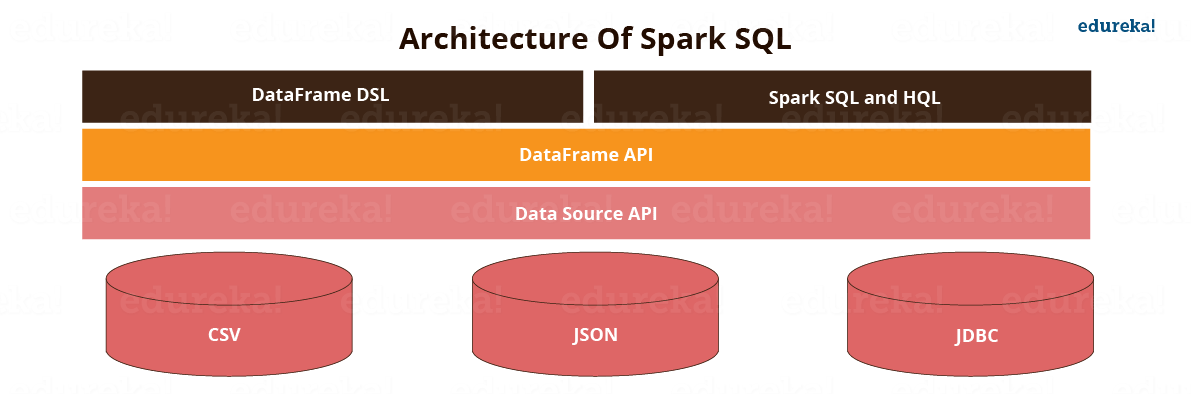
图: Spark SQL 的架构。
Spark SQL 库
Spark SQL 有以下四个库,用于与关系和过程处理交互:
1.数据源API(应用程序接口):
这是一个用于加载和存储结构化数据的通用 API。
- 它内置了对 Hive、Avro、JSON、JDBC、Parquet 等的支持。
- 支持通过 Spark 包进行第三方集成
- 支持智能来源。
- 它是一种适用于结构化和半结构化数据的数据抽象和领域特定语言 (DSL)。
- DataFrame API 是以命名的列和行的形式分布的数据集合。
- 它像 Apache Spark Transformations 一样被惰性评估,并且可以通过 SQL Context 和 Hive Context 访问。
- 它在单节点集群到多节点集群上处理千字节到拍字节大小的数据。
- 支持不同的数据格式(Avro、CSV、Elastic Search和 Cassandra)和存储系统(HDFS、HIVE Tables、MySQL等)。
- 可以通过 Spark-Core 与所有大数据工具和框架轻松集成。
- 为Python、Java、Scala和R 编程提供 API 。
2.数据帧API:
DataFrame 是组织成命名列的分布式数据集合。 它 相当于 SQL 中的关系表, 用于将数据存储到表中。
3. SQL 解释器和优化器:
SQL 解释器和优化器基于在 Scala 中构建的函数式编程。
- 它是 SparkSQL 中最新、技术最先进的组件。
- 它提供了转换树的通用框架,用于执行分析/评估、优化、规划和运行时代码生成。
- 这支持基于成本的优化(运行时间和资源利用率称为成本)和基于规则的优化,使查询运行速度比其 RDD(弹性分布式数据集)对应物快得多。
例如,Catalyst 是一个模块化库,它是一个基于规则的系统。框架中的每条规则都侧重于不同的优化。
4、SQL服务:
SQL 服务是在 Spark 中处理结构化数据的入口点。它允许创建DataFrame对象以及执行 SQL 查询。
Spark SQL 的特点
以下是 Spark SQL 的特点:
-
与 Spark 集成
Spark SQL 查询与 Spark 程序集成。Spark SQL 允许我们使用 SQL 或可在 Java、Scala、Python 和 R 中使用的 DataFrame API 查询 Spark 程序中的结构化数据。要运行流式计算,开发人员只需针对 DataFrame / Dataset API 编写批处理计算, Spark 会自动增加计算量,以流式方式运行它。这种强大的设计意味着开发人员不必手动管理状态、故障或保持应用程序与批处理作业同步。相反,流式作业总是在相同数据上给出与批处理作业相同的答案。
-
统一数据访问
DataFrames 和 SQL 支持访问各种数据源的通用方法,如 Hive、Avro、Parquet、ORC、JSON 和 JDBC。这将连接这些来源的数据。这对于将所有现有用户容纳到 Spark SQL 中非常有帮助。
-
蜂巢兼容性
Spark SQL 对当前数据运行未经修改的 Hive 查询。它重写了 Hive 前端和元存储,允许与当前的 Hive 数据、查询和 UDF 完全兼容。
-
标准连接
连接是通过 JDBC 或 ODBC 进行的。JDBC和 ODBC 是商业智能工具连接的行业规范。
-
性能和可扩展性
Spark SQL 结合了基于成本的优化器、代码生成和列式存储,在使用 Spark 引擎计算数千个节点的同时使查询变得敏捷,提供完整的中间查询容错。Spark SQL 提供的接口为 Spark 提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL 使用这些额外信息来执行额外优化。Spark SQL 可以直接从多个来源(文件、HDFS、JSON/Parquet 文件、现有 RDD、Hive 等)读取。它确保现有 Hive 查询的快速执行。
下图描述了 Spark SQL 与 Hadoop 相比的性能。Spark SQL 的执行速度比 Hadoop 快 100 倍。

图:Spark SQL 与 Hadoop 的运行时。Spark SQL 更快
用户定义函数Spark SQL 具有语言集成的用户定义函数 (UDF)。UDF 是 Spark SQL 的一个特性,用于定义新的基于列的函数,这些函数扩展了 Spark SQL 的 DSL 词汇表,用于转换数据集。UDF 在执行过程中是黑匣子。
下面的示例定义了一个 UDF,用于将给定的文本转换为大写。
代码说明:
1. 创建数据集“hello world”
2. 定义一个将字符串转换为大写的函数“upper”。
3. 我们现在将 'udf' 包导入 Spark。
4. 定义我们的 UDF,'upperUDF' 并导入我们的函数 'upper'。
5. 在新的“upper”列中显示我们的用户定义函数的结果。
val dataset = Seq((0, "hello"),(1, "world")).toDF("id","text")
val upper: String => String =_.toUpperCase
import org.apache.spark.sql.functions.udf
val upperUDF = udf(upper)
dataset.withColumn("upper", upperUDF('text)).show
图: 用户定义函数的演示,upperUDF
代码说明:
1. 我们现在将我们的函数注册为“myUpper”
2. 在其他函数中编目我们的 UDF。
spark.udf.register("myUpper", (input:String) => input.toUpperCase)
spark.catalog.listFunctions.filter('name like "%upper%").show(false)
图: 用户定义函数的结果,upperUDF
使用 Spark SQL 查询
我们现在将开始使用 Spark SQL 进行查询。请注意,实际的 SQL 查询类似于流行的 SQL 客户端中使用的查询。
启动 Spark Shell。进入 Spark 目录,在终端执行 ./bin/spark-shell 成为 Spark Shell。
对于博客中显示的查询示例,我们将使用两个文件,“employee.txt”和“employee.json”。下面的图片显示了这两个文件的内容。这两个文件都存储在包含 Spark 安装 (~/Downloads/spark-2.0.2-bin-hadoop2 .7)。因此,所有正在执行查询的人,请将它们放在此目录中或在下面的代码行中设置文件的路径。

图: employee.txt 的内容
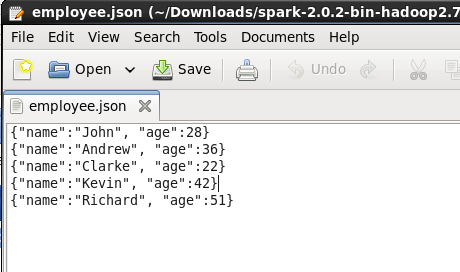
图: employee.json 的内容
代码说明:
1、我们先导入一个Spark Session到Apache Spark中。
2. 使用 'builder()' 函数创建 Spark 会话 'spark'。
3. 将 Implicts 类导入到我们的“spark”会话中。
4. 我们现在创建一个 DataFrame 'df' 并从 'employee.json' 文件导入数据。
5. 显示数据帧“df”。结果是我们的“employee.json”文件中包含 5 行年龄和姓名的表格。
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").getOrCreate()
import spark.implicits._
val df = spark.read.json("examples/src/main/resources/employee.json")
df.show()
图: 启动Spark Session并显示employee.json的DataFrame
代码说明:
1. 将 Implicts 类导入到我们的“spark”会话中。
2. 打印我们的 'df' DataFrame 的架构。
3. 显示来自“df”DataFrame 的所有记录的名称。
import spark.implicits._
df.printSchema()
df.select("name").show()
图: DataFrame 的架构
代码说明:
1. 显示每个人的年龄增加两年后的DataFrame。
2. 我们筛选出所有 30 岁以上的员工并显示结果。
df.select($"name", $"age" + 2).show()
df.filter($"age" > 30).show()
图: employee.json 上的基本 SQL 操作
代码说明:
1. 统计年龄相同的人数。我们同样使用“groupBy”函数。
2. 创建我们的 'df' DataFrame 的临时视图 'employee'。
3. 在我们的'employee' 视图上执行'select' 操作以将表显示为'sqlDF'。
4.显示'sqlDF'的结果。
df.groupBy("age").count().show()
df.createOrReplaceTempView("employee")
val sqlDF = spark.sql("SELECT * FROM employee")
sqlDF.show()
图: employee.json 上的 SQL 操作
创建数据集
在了解了 DataFrames 之后,让我们现在转到 Dataset API。下面的代码在 SparkSQL 中创建了一个 Dataset 类。
代码说明:
1. 创建一个“Employee”类来存储员工的姓名和年龄。
2. 分配一个数据集“caseClassDS”来存储安德鲁的记录。
3. 显示数据集“caseClassDS”。
4. 创建一个原始数据集来演示数据帧到数据集的映射。
5. 将上述序列赋值给一个数组。
case class Employee(name: String, age: Long)
val caseClassDS = Seq(Employee("Andrew", 55)).toDS()
caseClassDS.show()
val primitiveDS = Seq(1, 2, 3).toDS
()primitiveDS.map(_ + 1).collect()
图: 创建数据集
代码说明:
1.设置我们的JSON文件'employee.json'的路径。
2. 从文件创建数据集。
3. 显示'employeeDS' Dataset 的内容。
val path = "examples/src/main/resources/employee.json"
val employeeDS = spark.read.json(path).as[Employee]
employeeDS.show()
图: 从 JSON 文件创建数据集
将模式添加到 RDD
Spark 引入了 RDD(弹性分布式数据集)的概念,这是一个不可变的容错分布式对象集合,可以并行操作。RDD 可以包含任何类型的对象,它是通过加载外部数据集或从驱动程序分发集合来创建的。
Schema RDD 是一个可以运行 SQL 的 RDD。它不仅仅是 SQL。它是结构化数据的统一接口。
代码说明:
1. 为RDDs导入Expression Encoder。RDD 类似于数据集,但使用编码器进行序列化。
2. 将Encoder 库导入shell。
3. 将 Implicts 类导入到我们的“spark”会话中。
4. 从“employee.txt”创建一个“employeeDF”DataFrame,并将基于分隔符逗号“,”的列映射到临时视图“employee”中。
5. 创建临时视图“员工”。
6. 定义一个DataFrame 'youngstersDF',它将包含所有年龄在18 到30 岁之间的员工。
7. 将RDD 中的姓名映射到'youngstersDF' 以显示年轻人的姓名。
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder
import org.apache.spark.sql.Encoder
import spark.implicits._
val employeeDF = spark.sparkContext.textFile("examples/src/main/resources/employee.txt").map(_.split(",")).map(attributes => Employee(attributes(0), attributes(1).trim.toInt)).toDF()
employeeDF.createOrReplaceTempView("employee")
val youngstersDF = spark.sql("SELECT name, age FROM employee WHERE age BETWEEN 18 AND 30")
youngstersDF.map(youngster => "Name: " + youngster(0)).show()
图: 为转换创建 DataFrame
代码说明:
1. 将映射名称转换为字符串进行转换。
2. 使用 Implicits 类中的 mapEncoder 将名称映射到年龄。
3. 将名称映射到我们的 'youngstersDF' DataFrame 的年龄。结果是一个名称映射到各自年龄的数组。
youngstersDF.map(youngster => "Name: " + youngster.getAs[String]("name")).show()
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
youngstersDF.map(youngster => youngster.getValuesMap[Any](List("name", "age"))).collect()
图: 使用 DataFrame 进行映射
RDD 支持两种类型的操作:
- 转换:这些是在 RDD 上执行的操作(例如 map、filter、join、union 等),这些操作会产生一个包含结果的新 RDD。
- 动作:这些是在 RDD 上运行计算后返回值的操作(例如reduce、count、first 等)。
Spark 中的转换是“惰性的”,这意味着它们不会立即计算结果。相反,它们只是“记住”要执行的操作和要对其执行操作的数据集(例如,文件)。转换仅在调用操作并将结果返回到驱动程序并存储为有向无环图 (DAG) 时计算。这种设计使 Spark 能够更高效地运行。例如,如果一个大文件以各种方式转换并传递给 first action,Spark 只会处理并返回第一行的结果,而不是对整个文件进行处理。

图: Spark SQL中Schema RDD的生态
默认情况下,每个每次在其上运行操作时,可能会重新计算转换后的 RDD。但是,您也可以使用 persist 或 cache 方法将 RDD 保存在内存中,在这种情况下,Spark 会将元素保留在集群上,以便在您下次查询时更快地访问。
作为关系的 RDD
弹性分布式数据集 (RDD) 是分布式内存抽象,它允许程序员以容错方式在大型集群上执行内存计算。RDD 可以从任何数据源创建。例如:Scala 集合、本地文件系统、Hadoop、Amazon S3、HBase 表等。
指定架构
代码说明:
1. 将'types'类导入Spark Shell。
2. 将 'Row' 类导入 Spark Shell。Row 用于映射 RDD Schema。
3.从文本文件'employee.txt'创建一个RDD'employeeRDD'。
4. 将模式定义为“名称年龄”。这用于映射 RDD 的列。
5. 定义'fields' RDD,它是将'employeeRDD' 映射到模式'schemaString' 后的输出。
6.获取'fields'RDD的类型到'schema'中。
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
val employeeRDD = spark.sparkContext.textFile("examples/src/main/resources/employee.txt")
val schemaString = "name age"
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)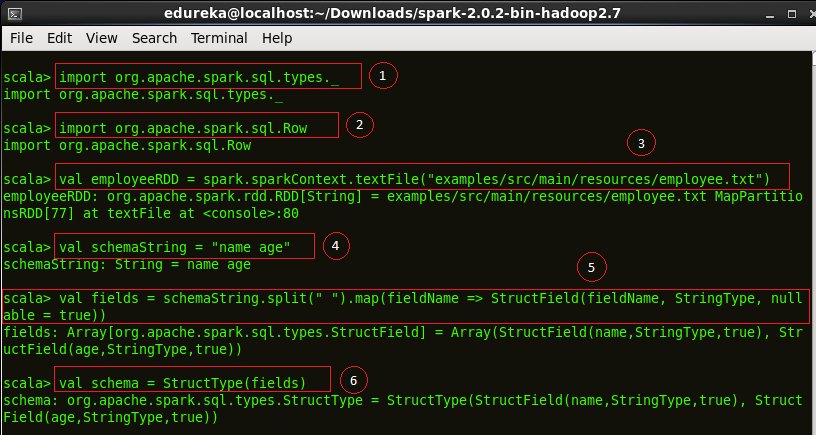
图: 为 RDD 转换指定 Schema
代码说明:
1. 我们现在创建一个名为'rowRDD'的RDD,并使用'map'函数将'employeeRDD'转换为'rowRDD'。
2. 我们定义一个 DataFrame 'employeeDF' 并将 RDD 模式存储到其中。
3. 将'employeeDF' 的临时视图创建为'employee'。
4.对'employee'执行SQL操作,显示employee的内容。
5. 在“员工”视图中显示上一个操作的名称。
val rowRDD = employeeRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim))
val employeeDF = spark.createDataFrame(rowRDD, schema)
employeeDF.createOrReplaceTempView("employee")
val results = spark.sql("SELECT name FROM employee")
results.map(attributes => "Name: " + attributes(0)).show()
图: RDD转换结果
即使定义了 RDD, 它们不包含任何数据。 在 RDD 中创建数据的计算仅在数据被引用时完成。例如缓存结果或写出 RDD。
在内存中缓存表
Spark SQL 使用内存中的列格式缓存表:
- 仅扫描必需的列
- 更少的分配对象
- 自动选择最佳比较
以编程方式加载数据
下面的代码将读取employee.json 文件并创建一个DataFrame。然后我们将使用它来创建 Parquet 文件。
代码说明:
1. 将 Implicits 类导入 shell。
2. 从我们的 'employee.json' 文件创建一个 'employeeDF' DataFrame。
import spark.implicits._
val employeeDF = spark.read.json("examples/src/main/resources/employee.json")

图: 将 JSON 文件加载到 DataFrame
代码说明:
1. 创建我们 DataFrame 的“parquetFile”临时视图。
2. 从我们的 Parquet 文件中选择年龄在 18 到 30 岁之间的人的姓名。
3. 显示 Spark SQL 操作的结果。
employeeDF.write.parquet("employee.parquet")
val parquetFileDF = spark.read.parquet("employee.parquet")
parquetFileDF.createOrReplaceTempView("parquetFile")
val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 18 AND 30")
namesDF.map(attributes => "Name: " + attributes(0)).show()
图: 显示 Parquet DataFrame 的结果
JSON 数据集
我们现在将处理 JSON 数据。由于 Spark SQL 支持 JSON 数据集,我们创建了一个 employee.json 的 DataFrame。这个 DataFrame 的架构可以在下面看到。然后我们定义一个 Youngster DataFrame 并添加所有年龄在 18 到 30 岁之间的员工。
代码说明:
1. 设置为我们的'employee.json' 文件的路径。
2. 从我们的 JSON 文件创建一个 DataFrame 'employeeDF'。
3.打印'employeeDF'的模式。
4. 在“员工”中创建 DataFrame 的临时视图。
5. 定义一个 DataFrame 'youngsterNamesDF',它存储了 'employee' 中所有年龄在 18 到 30 岁之间的员工的姓名。
6. 显示我们的 DataFrame 的内容。
val path = "examples/src/main/resources/employee.json"
val employeeDF = spark.read.json(path)
employeeDF.printSchema()
employeeDF.createOrReplaceTempView("employee")
val youngsterNamesDF = spark.sql("SELECT name FROM employee WHERE age BETWEEN 18 AND 30")
youngsterNamesDF.show()
图: 对 JSON 数据集的操作
代码说明:
1. 创建一个RDD 'otherEmployeeRDD',它将存储来自新德里,德里的雇员George 的内容。
2. 将'otherEmployeeRDD'的内容赋值给'otherEmployee'。
3. 显示“otherEmployee”的内容。
val otherEmployeeRDD = spark.sparkContext.makeRDD("""{"name":"George","address":{"city":"New Delhi","state":"Delhi"}}""" :: Nil)
val otherEmployee = spark.read.json(otherEmployeeRDD)
otherEmployee.show()
图: JSON 数据集上的 RDD 转换
Hive Tables
我们使用 Hive 表执行 Spark 示例。
代码说明:
1. 将'Row'类导入Spark Shell。Row 用于映射 RDD Schema。
2. 将 Spark Session 导入 shell。
3. 创建一个具有 Int 和 String 属性的类“Record”。
4.将'warehouseLocation'的位置设置为Spark仓库。
5. 我们现在构建一个 Spark Session 'spark' 来演示 Spark SQL 中的 Hive 示例。
6. 将 Implicits 类导入 shell。
7. 将 SQL 库导入 Spark Shell。
8. 创建一个带有列的表“src”来存储键和值。
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
case class Record(key: Int, value: String)
val warehouseLocation = "spark-warehouse"
val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate()
import spark.implicits._
import spark.sql
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")图: 为 Hive 构建会话
代码说明:
1. 我们现在将 Spark 目录中示例中的数据加载到我们的表 'src' 中。
2. 'src' 的内容如下所示。
sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
sql("SELECT * FROM src").show()
图: 使用 Hive 表进行选择
代码说明:
1. 我们执行'count'操作来选择'src'表中的键数。
2.我们现在选择'key'值小于10的所有记录并将其存储在'sqlDF'DataFrame中。
3. 从“sqlDF”创建数据集“stringDS”。
4.显示'stringDS'数据集的内容。
sql("SELECT COUNT(*) FROM src").show()
val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key") val stringsDS = sqlDF.map {case Row(key: Int, value: String) => s"Key: $key, Value: $value"}
stringsDS.show()
图: 从 Hive 表创建数据帧
代码说明:
1. 我们创建一个DataFrame 'recordsDF' 并存储所有key 值为1 到100 的记录。
2. 创建一个'recordsDF' DataFrame 的临时视图'records'。
3.显示以'key'为主键的'records'和'src'表的join内容。
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records")
sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
图: 记录Hive操作的结果
所以我们的博客到此结束。我希望你喜欢阅读这个博客并发现它内容丰富。到现在为止,您一定已经对 Spark SQL 是什么有了充分的了解。实践示例将使您有必要的信心来处理您在 Spark SQL 中遇到的任何未来项目。实践是掌握任何主题的关键,我希望这篇博客能引起您足够的兴趣,以进一步探索 Spark SQL 的学习。

- 点赞
- 收藏
- 关注作者
评论(0)