Spark 教程:实时集群计算框架

Apache Spark 是一个用于实时处理的开源集群计算框架。它是 Apache 软件基金会中最成功的项目之一。Spark 显然已经发展成为大数据处理的市场领导者。今天,Spark 正被亚马逊、eBay 和 Yahoo! 等主要参与者采用。许多组织在具有数千个节点的集群上运行 Spark,这是您职业生涯中成为Spark 认证专家的巨大机会。 我们很高兴通过这个Spark 教程 博客开始这段激动人心的旅程。该博客是即将发布的 Apache Spark 博客系列中的第一篇博客,其中将包括 Spark Streaming、Spark 面试问题、Spark MLlib 等。
在实时数据分析方面,Spark 是所有其他解决方案的首选工具。通过这篇博客,我将向您介绍 Apache Spark 这个令人兴奋的新领域,我们将通过一个完整的用例, 使用 Spark 进行地震检测。
以下是此 Spark 教程博客中涵盖的主题:
- Real Time Analytics
- Why Spark when Hadoop is already there?
- What is Apache Spark?
- Spark Features
- Getting Started with Spark
- Using Spark with Hadoop
- Spark Components
- Use Case: Earthquake Detection using Spark
Spark 教程:实时分析
在开始之前,让我们看看社交媒体领导者每分钟生成的数据量。
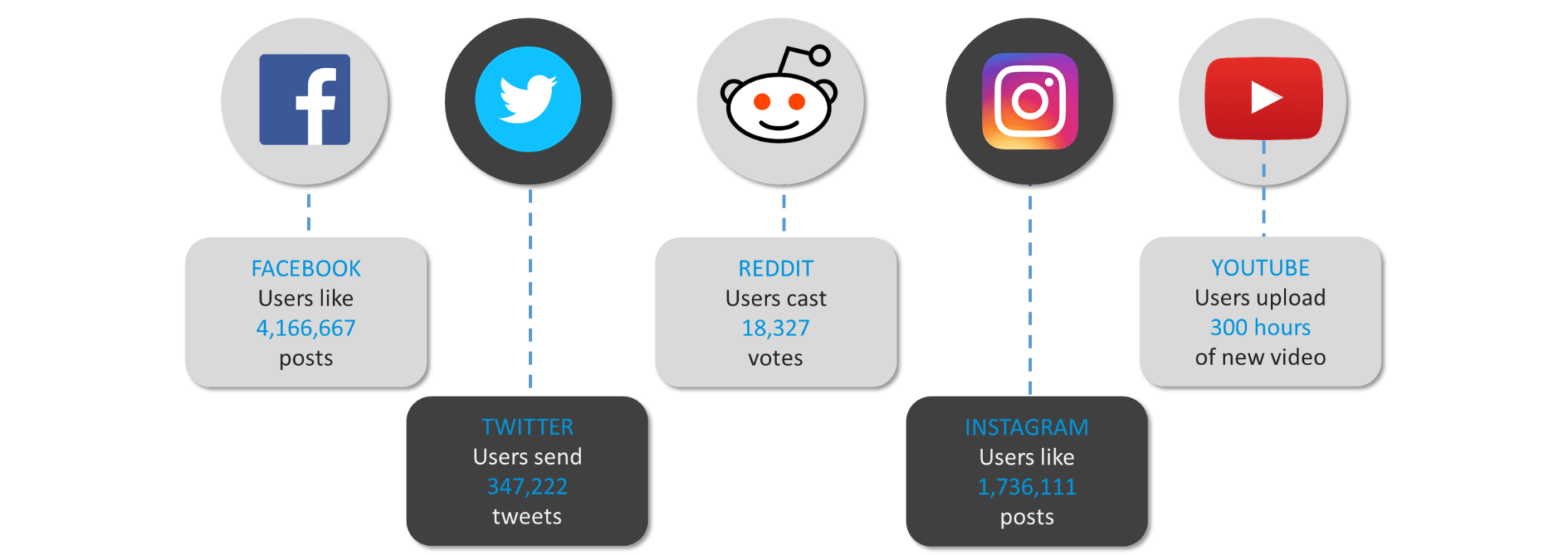
图: 每分钟产生的数据量
正如我们所见,互联网世界需要在几秒钟内处理大量数据。我们将经历在企业中处理大数据的所有阶段,并发现对名为Apache Spark 的实时处理框架的需求。
首先,让我向您介绍当今世界中使用实时分析的几个领域。

图: Spark 教程 - 实时分析示例
我们可以看到大数据的实时处理在我们生活的方方面面都根深蒂固。从银行的欺诈检测到政府的实时监控系统、医疗保健中的自动化机器到股票市场的实时预测系统,我们周围的一切都围绕着近乎实时地处理大数据。
让我们看看实时分析的一些用例:
- 医疗保健:医疗保健领域使用实时分析来持续检查危重患者的医疗状况。寻找血液和器官移植的医院需要在紧急情况下保持实时联系。按时就医是关乎患者生死的大事。
- 政府:政府机构主要在国家安全领域进行实时分析。各国需要持续跟踪所有军事和警察机构,以获取有关安全威胁的最新信息。
- 电信:以电话、视频聊天和流媒体形式提供服务的公司使用实时分析来减少客户流失并在竞争中保持领先地位。他们还提取移动网络中的抖动和延迟测量值,以改善客户体验。
- 银行业务:银行业务涉及世界上几乎所有的货币。确保整个系统的容错事务变得非常重要。通过银行业的实时分析,欺诈检测成为可能。
- 股票市场:股票经纪人使用实时分析来预测股票投资组合的变动。公司在使用实时分析来分析其品牌的市场需求后重新思考他们的商业模式。
Spark 教程:当 Hadoop 已经存在时为什么要使用 Spark?
在谈到 Spark 时,每个人都会问的许多问题中的第一个是:“既然我们已经有了 Hadoop,为什么还要使用 Spark ?”。
要回答这个问题,我们必须看看批处理和实时处理的概念。Hadoop基于批处理的概念,其中处理已经存储了一段时间的数据块。当时,Hadoop在2005年凭借革命性的MapReduce框架打破了所有人的预期。Hadoop MapReduce是最好的批量处理数据的框架。
这种情况一直持续到 2014 年,直到 Spark 超过了 Hadoop。Spark 的 USP 是它可以实时处理数据,并且在批量处理大数据集方面比 Hadoop MapReduce 快 100 倍左右。
下图详细解释了 Spark 和 Hadoop 中处理的区别。
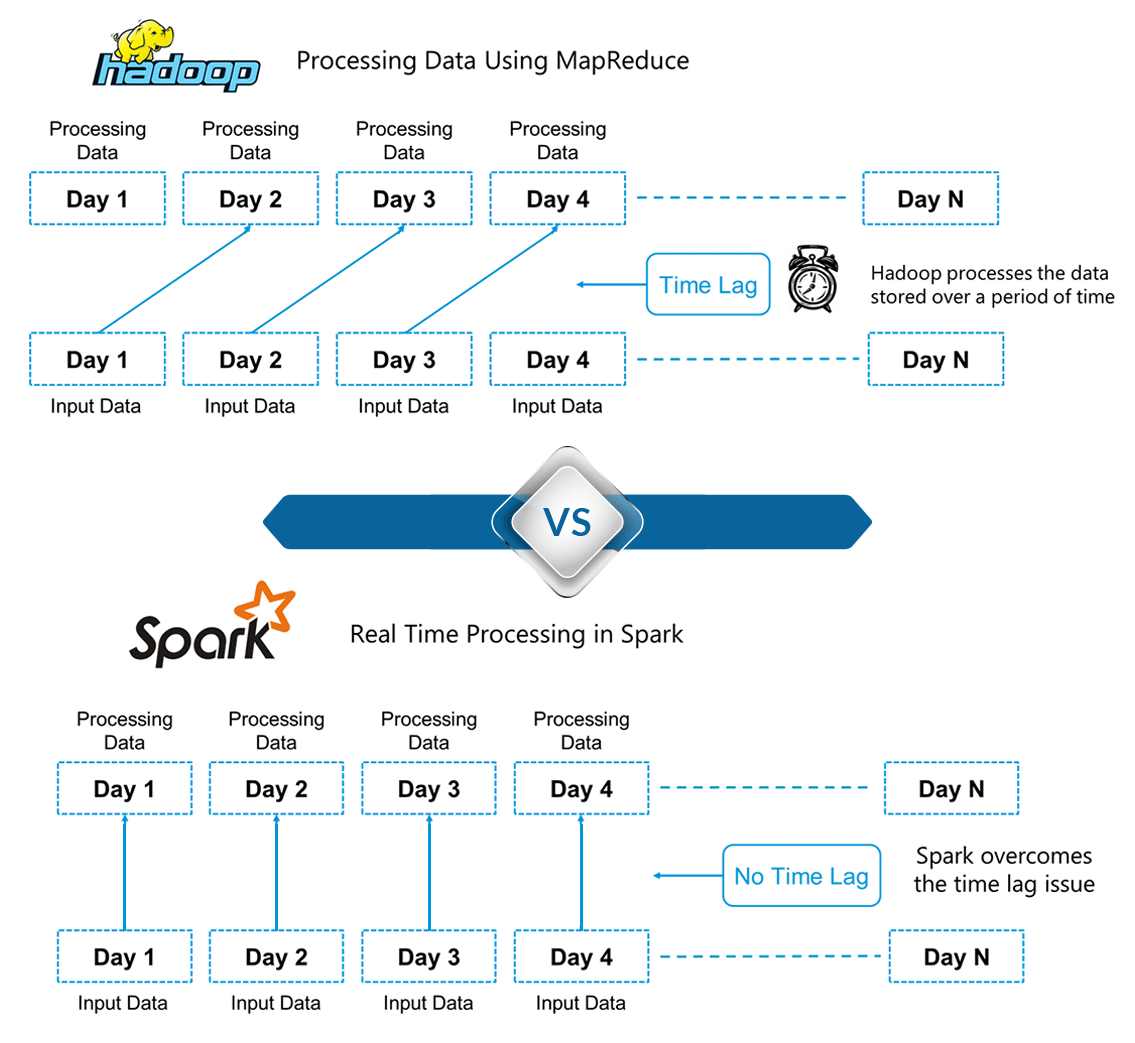
图:Spark 教程——Hadoop 和 Spark 的区别
在这里,我们可以找出 Hadoop 和 Spark 之间的主要区别之一。Hadoop基于大数据的批处理。这意味着数据会存储一段时间,然后使用 Hadoop 进行处理。 而在 Spark 中,处理可以实时进行。Spark 中的这种实时处理能力帮助我们解决了我们在上一节中看到的实时分析用例。除此之外,Spark 的批处理速度也比 Hadoop MapReduce(Apache Hadoop 中的处理框架)快 100 倍。因此,Apache Spark是业界大数据处理的首选工具。
Spark 教程:什么是 Apache Spark?
Apache Spark 是一个用于实时处理的开源集群计算框架。 它有一个蓬勃发展的开源社区,是目前最活跃的 Apache 项目。Spark 提供了一个接口,用于对具有隐式数据并行性和容错性的整个集群进行编程。

它建立在 Hadoop MapReduce 之上,并且 它扩展了 MapReduce 模型以有效地使用更多类型的计算。
Spark 教程:Apache Spark 的特性
Spark具有以下特点:
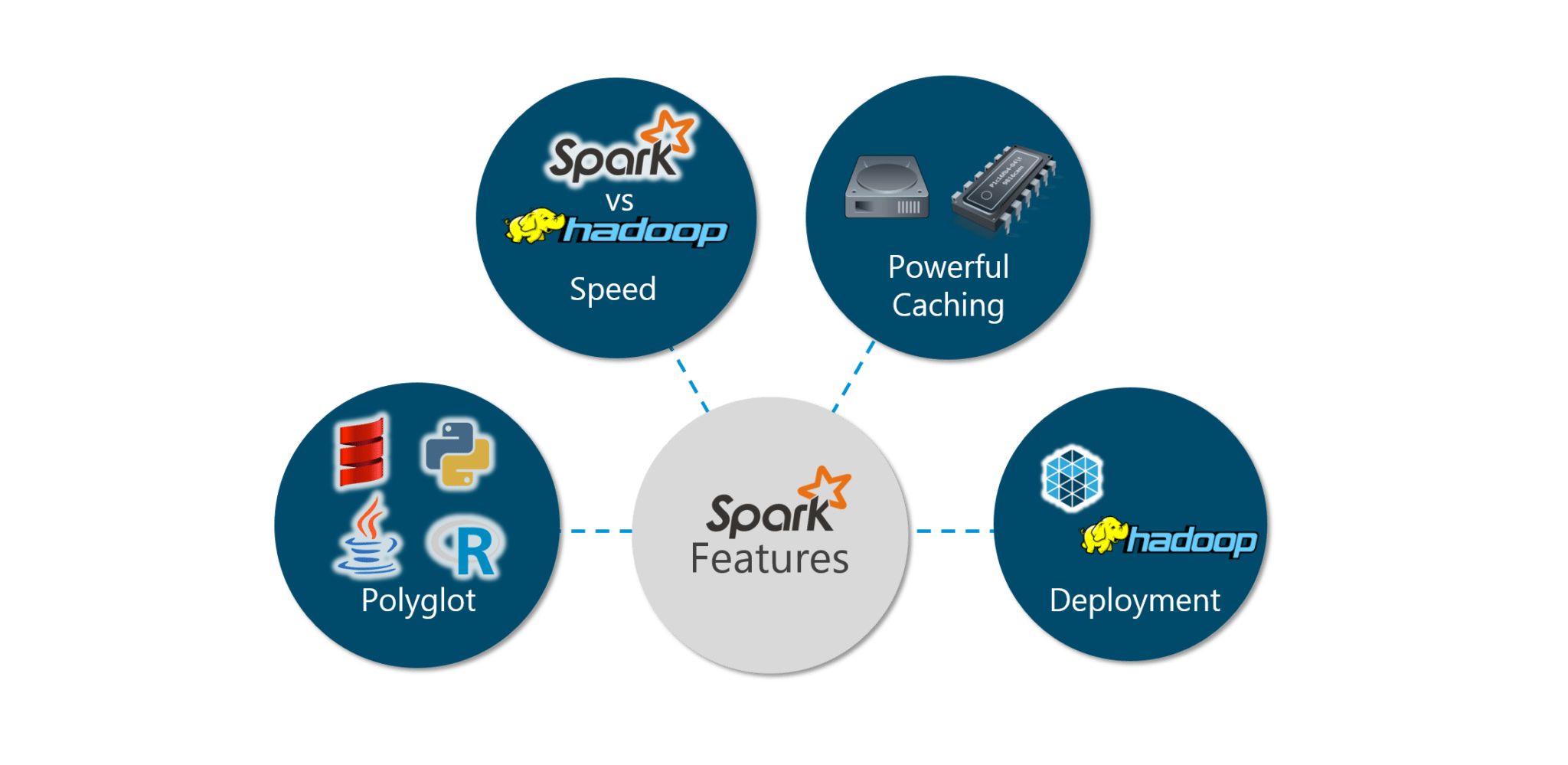
图: Spark 教程——Spark 特性
让我们详细看一下这些功能:
多语种:
Spark 提供 Java、Scala、Python 和 R 语言的高级 API。Spark 代码可以用这四种语言中的任何一种编写。它在 Scala 和 Python 中提供了一个 shell。Scala shell 可以通过./bin/spark-shell访问,Python shell 可以通过./bin/pyspark从安装目录访问。
速度:
对于大规模数据处理,Spark 的运行速度比 Hadoop MapReduce 快 100 倍。Spark 能够通过受控分区来达到这个速度。它使用分区管理数据,这些分区有助于以最少的网络流量并行化分布式数据处理。
| 多种格式: 除了文本文件、CSV 和 RDBMS 表等常用格式外,Spark 还支持 Parquet、JSON、Hive 和 Cassandra 等多种数据源。Data Source API 提供了一种通过 Spark SQL 访问结构化数据的可插拔机制。数据源不仅仅是转换数据并将其拉入 Spark 的简单管道。 |
实时计算:
Spark 的计算是实时的,并且由于其内存计算而具有低延迟。Spark 专为大规模可扩展性而设计,Spark 团队记录了运行具有数千个节点的生产集群的系统的用户,并支持多种计算模型。
Hadoop 集成:
Apache Spark 提供与 Hadoop 的平滑兼容性。这 对所有以 Hadoop 开始职业生涯的大数据工程师来说都是一个福音。Spark 是 Hadoop 的 MapReduce 功能的潜在替代品,而 Spark 能够在现有的 Hadoop 集群之上运行,使用 YARN 进行资源调度。
机器学习:
Spark 的 MLlib 是机器学习组件,在大数据处理方面非常方便。它消除了使用多种工具的需要,一种用于处理,一种用于机器学习。Spark 为数据工程师和数据科学家提供了一个强大、统一的引擎,既快速又易于使用。
Spark 教程:Spark 入门
开始使用 Spark 的第一步是安装。让我们在 Linux 系统上安装 Apache Spark 2.1.0(我使用的是 Ubuntu)。
安装:
- 安装 Spark 的先决条件是安装了 Java 和 Scala。
- 如果 未使用以下命令安装Java,请下载 Java 。
sudo apt-get install python-software-properties
sudo apt-add-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer从Scala Lang 官方 页面下载最新的 Scala 版本。 安装后,在文件中设置 scala 路径,~/.bashrc 如下所示。
export SCALA_HOME=Path_Where_Scala_File_Is_Located
export PATH=$SCALA_HOME/bin:PATH- 从Apache Spark 下载页面下载 Spark 2.1.0 。您也可以选择下载以前的版本。
- 使用以下命令提取 Spark tar。
tar -xvf spark-2.1.0-bin-hadoop2.7.tgz在~/.bashrc 文件中设置 Spark_Path 。
export SPARK_HOME=Path_Where_Spark_Is_Installed
export PATH=$PATH:$SPARK_HOME/bin在继续之前,让我们在我们的系统上启动 Apache Spark 并熟悉 Spark 的主要概念,如 Spark 会话、数据源、RDD、数据帧和其他库。
Spark Shell:
Spark 的 shell 提供了一种学习 API 的简单方法,以及一种交互式分析数据的强大工具。
Spark Session:
在早期版本的 Spark 中,Spark Context 是 Spark 的入口点。对于其他所有 API,我们需要使用不同的上下文。对于流式传输,我们需要 StreamingContext、SQL sqlContext 和 hive HiveContext。为了解决这个问题,SparkSession 出现了。它 本质上是 SQLContext、HiveContext 和未来 StreamingContext 的组合。
数据源:
Data Source API 提供了一种通过 Spark SQL 访问结构化数据的可插拔机制。Data Source API 用于将结构化和半结构化数据读取并存储到 Spark SQL 中。数据源不仅仅是转换数据并将其拉入 Spark 的简单管道。
RDD:
弹性分布式数据集(RDD)是 Spark 的基本数据结构。它是一个不可变的分布式对象集合。RDD 中的每个数据集都被划分为逻辑分区,这些分区可以在集群的不同节点上进行计算。RDD 可以包含任何类型的 Python、Java 或 Scala 对象,包括用户定义的类。
数据集:
数据集是数据的分布式集合。数据集可以从 JVM 对象构建,然后使用函数转换(map、flatMap、filter 等)进行操作。数据集 API 在 Scala 和 Java 中可用。
数据帧:
DataFrame 是组织成命名列的数据集。它在概念上等同于关系数据库中的表或 R/Python 中的数据框,但在幕后进行了更丰富的优化。DataFrames 可以从多种来源构建,例如:结构化数据文件、Hive 中的表、外部数据库或现有的 RDD。
Spark 教程:将 Spark 与 Hadoop 结合使用
Spark 最好的部分是它与 Hadoop 的兼容性。因此,这形成了非常强大的技术组合。在这里,我们将研究 Spark 如何从 Hadoop 的最佳优势中受益。
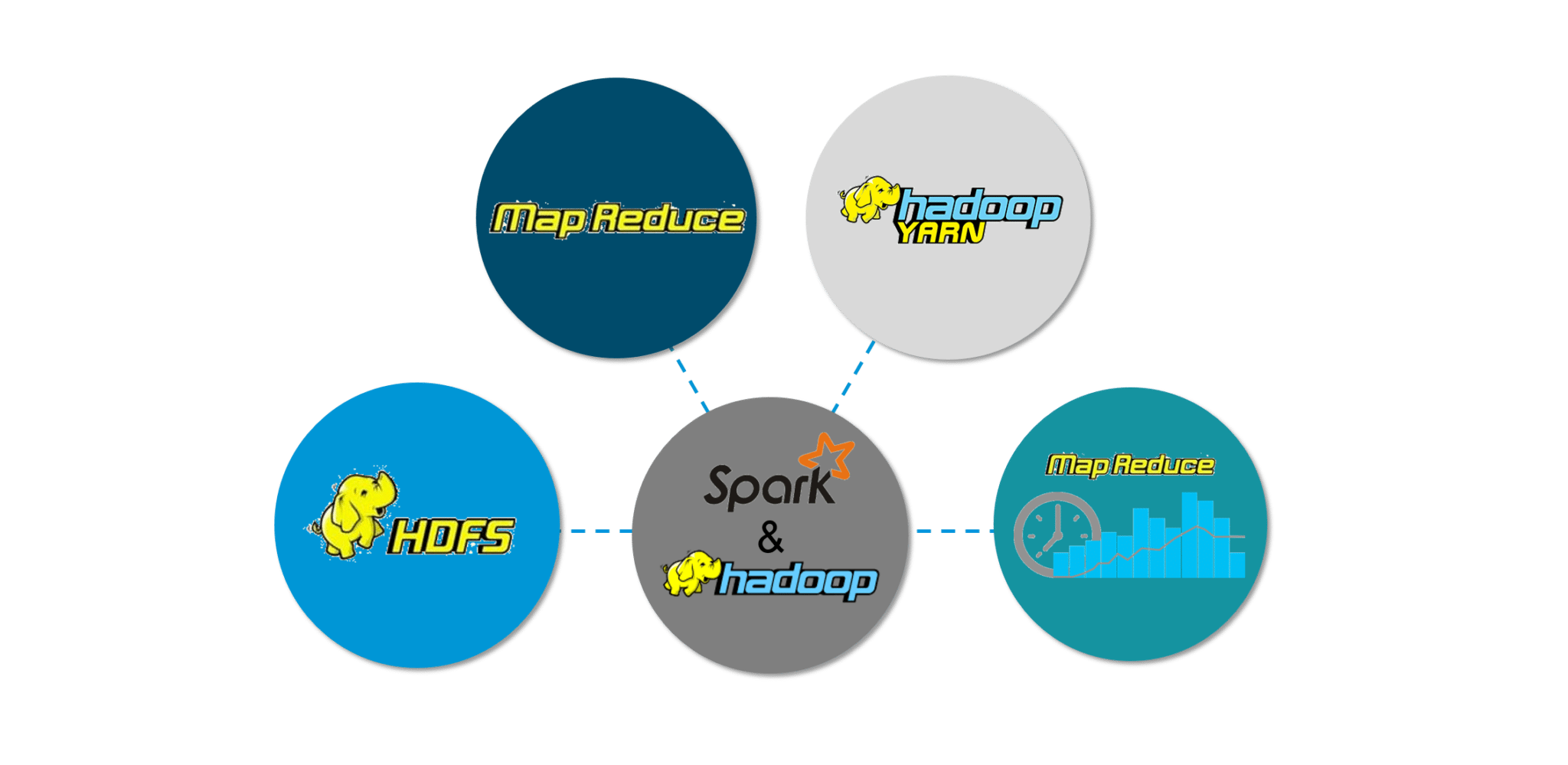
图:Spark 教程——Spark 特性
Hadoop 组件可以通过以下方式与 Spark 一起使用:
- HDFS: Spark 可以在 HDFS 之上运行以利用分布式复制存储。
- MapReduce: Spark 可以与 MapReduce 一起使用在同一个 Hadoop 集群中,也可以单独作为处理框架使用。
- YARN: Spark 应用程序可以在 YARN (Hadoop NextGen) 上运行。
- 批处理和实时处理: MapReduce 和 Spark 一起使用,其中 MapReduce 用于批处理,Spark 用于实时处理。
Spark 教程:Spark 组件
Spark 组件使 Apache Spark 快速可靠。许多这些 Spark 组件都是为了解决使用 Hadoop MapReduce 时出现的问题而构建的。Apache Spark 具有以下组件:
- Spark Core
- Spark Streaming
- Spark SQL
- GraphX
- MLlib (Machine Learning)
Spark Core
Spark Core是大规模并行和分布式数据处理的基础引擎。核心是分布式执行引擎,Java、Scala 和 Python API 为分布式 ETL 应用程序开发提供了一个平台。此外,构建在核心之上的附加库允许用于流、SQL 和机器学习的不同工作负载。 它负责:
- 内存管理和故障恢复
- 在集群上调度、分发和监控作业
- 与存储系统交互
Spark Streaming
Spark Streaming是Spark的组件,用于处理实时流数据。因此,它是对核心 Spark API 的有用补充。它支持实时数据流的高吞吐量和容错流处理。基本的流单元是 DStream,它基本上是一系列 RDD(弹性分布式数据集)来处理实时数据。
Spark SQL
Spark SQL 是Spark中的一个新模块,它将关系处理与 Spark 的函数式编程 API 集成在一起。它支持通过 SQL 或 Hive 查询语言查询数据。对于熟悉 RDBMS 的人来说,Spark SQL 将是您早期工具的轻松过渡,您可以在其中扩展传统关系数据处理的边界。
Spark SQL 将关系处理与 Spark 的函数式编程相结合。此外,它为各种数据源提供支持,并可以将 SQL 查询与代码转换编织在一起,从而成为一个非常强大的工具。
以下是 Spark SQL 的四个库。
- Data Source API
- DataFrame API
- Interpreter & Optimizer
- SQL Service
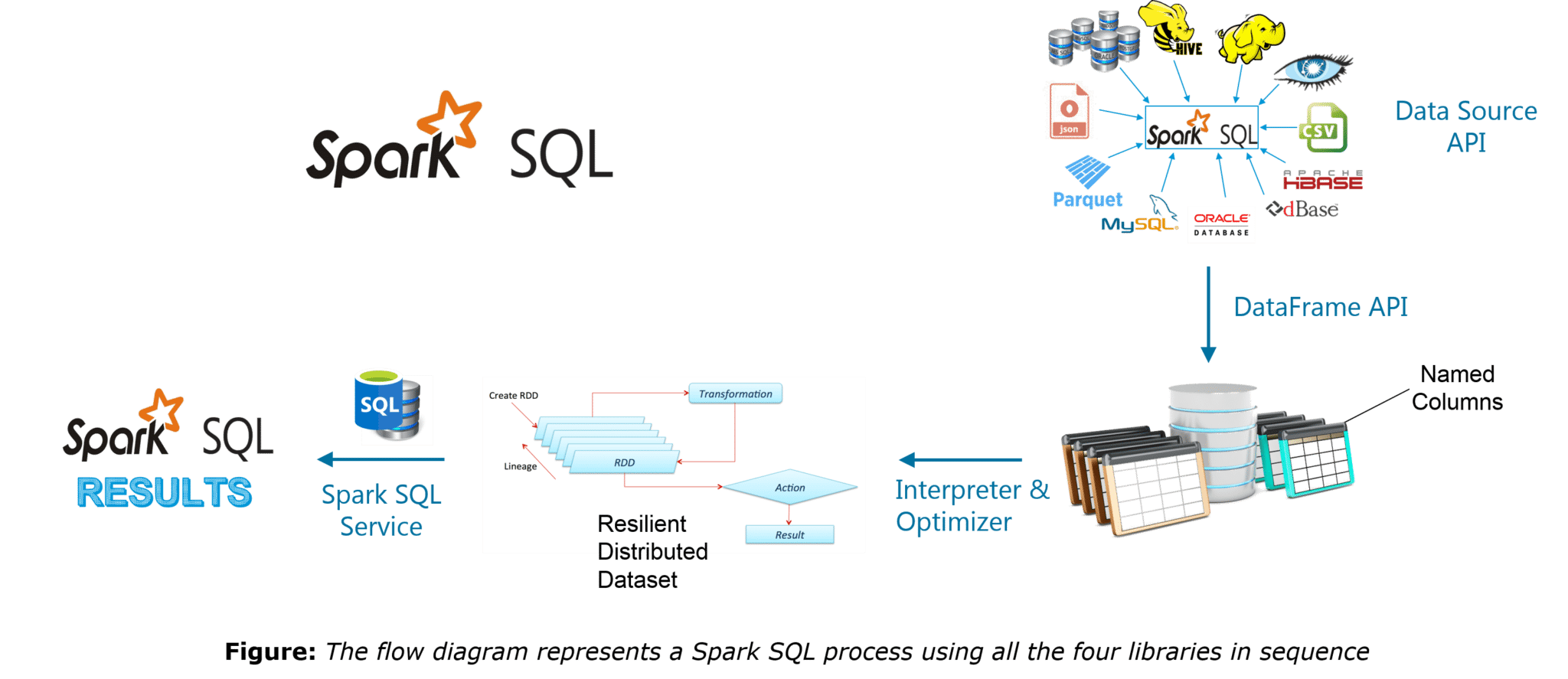
可以在给定的博客中找到有关 Spark SQL 的完整教程:Spark SQL 教程博客
GraphX
GraphX是用于图形和图形并行计算的 Spark API。因此,它使用弹性分布式属性图扩展了 Spark RDD。
属性图是一个有向多重图,可以有多个平行边。每条边和顶点都有与之关联的用户定义属性。在这里,平行边允许相同顶点之间存在多种关系。在高层次上,GraphX 通过引入弹性分布式属性图扩展了 Spark RDD 抽象:一个有向多重图,其属性附加到每个顶点和边。
为了支持图计算,GraphX 公开了一组基本运算符(例如,子图、joinVertices 和 mapReduceTriplets)以及 Pregel API 的优化变体。此外,GraphX 包含越来越多的图算法和构建器,以简化图分析任务。
MlLib(机器学习)
MLlib代表机器学习库。Spark MLlib 用于在 Apache Spark 中执行机器学习。
用例:使用 Spark 进行地震检测
现在我们已经了解了 Spark 的核心概念,让我们使用 Apache Spark 解决一个实际问题。这将有助于让我们有信心在未来开展任何 Spark 项目。
问题陈述: 设计一个实时地震检测模型来发送救生警报,这应该改进其机器学习以提供近乎实时的计算结果。
用例 - 要求:
- 实时处理数据
- 处理来自多个来源的输入
- 易于使用的系统
- 批量传输警报
我们将使用 Apache Spark,它是满足我们要求的完美工具。
用例 – 数据集:

图: 用例——地震数据集
在继续之前,我们必须了解一个概念,我们将在我们的地震检测系统中使用它,它称为接收器操作特性 (ROC)。ROC 曲线是一个图形图,它说明了二元分类器系统在其鉴别阈值变化时的性能。我们将使用数据集在 Apache Spark 中使用机器学习获取 ROC 值。
用例 - 流程图:
下图清楚地解释了我们地震检测系统中涉及的所有步骤。
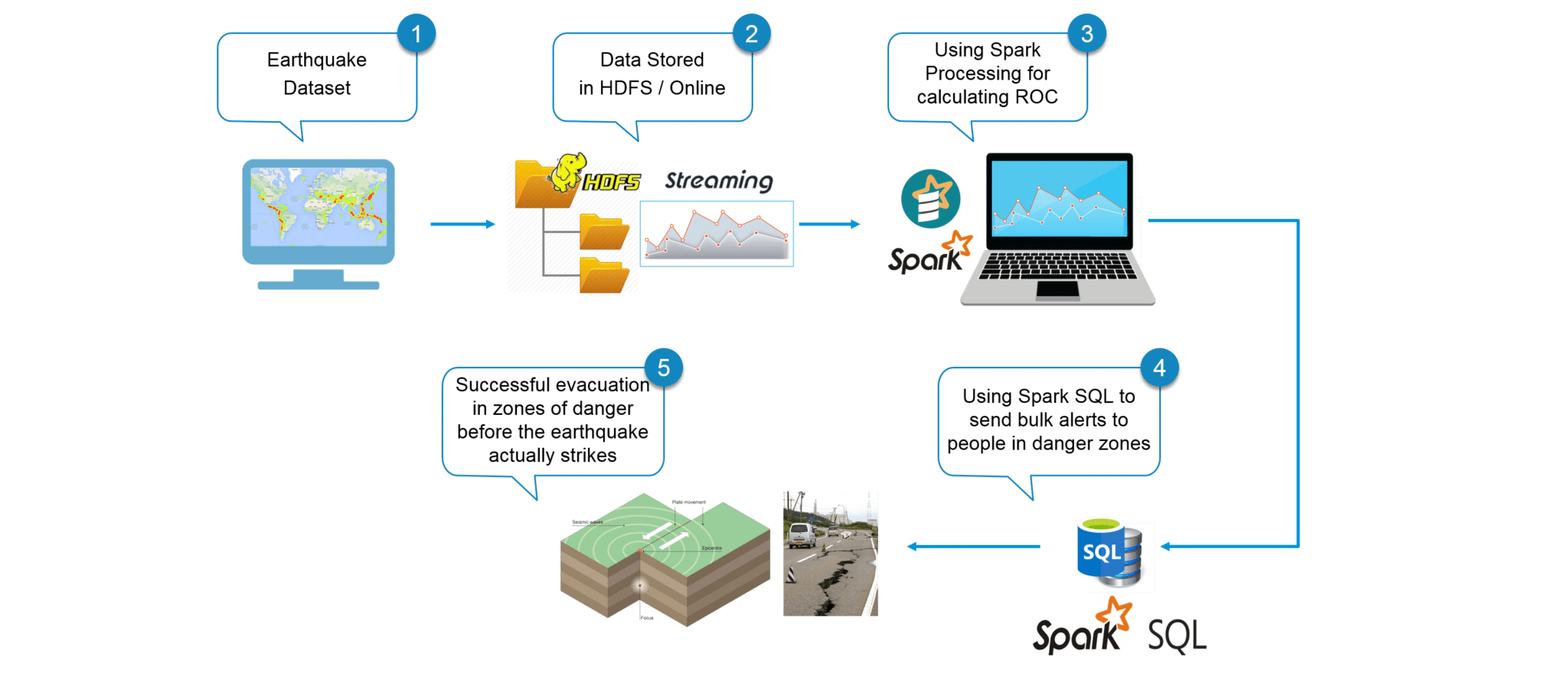
图: 用例 - 使用 Apache Spark 进行地震检测的流程图
用例 – Spark 实现:
继续前进,现在让我们使用 Eclipse IDE for Spark 实现我们的项目。
找到下面的伪代码:
//Importing the necessary classes
import org.apache.spark._
...
//Creating an Object earthquake
object earthquake {
def main(args: Array[String]) {
//Creating a Spark Configuration and Spark Context
val sparkConf = new SparkConf().setAppName("earthquake").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
//Loading the Earthquake ROC Dataset file as a LibSVM file
val data = MLUtils.loadLibSVMFile(sc, *Path to the Earthquake File* )
//Training the data for Machine Learning
val splits = data.randomSplit( *Splitting 60% to 40%* , seed = 11L)
val training = splits(0).cache()
val test = splits(1)
//Creating a model of the trained data
val numIterations = 100
val model = *Creating SVM Model with SGD* ( *Training Data* , *Number of Iterations* )
//Using map transformation of model RDD
val scoreAndLabels = *Map the model to predict features*
//Using Binary Classification Metrics on scoreAndLabels
val metrics = * Use Binary Classification Metrics on scoreAndLabels *(scoreAndLabels)
val auROC = metrics. *Get the area under the ROC Curve*()
//Displaying the area under Receiver Operating Characteristic
println("Area under ROC = " + auROC)
}
}从我们的 Spark 程序中,我们获得的 ROC 值为 0.088137。我们将转换这个值以获得 ROC 曲线下的面积。
用例 - 可视化结果:
我们将绘制 ROC 曲线并将其与特定地震点进行比较。只要地震点超过 ROC 曲线,这些点就被视为大地震。根据我们计算 ROC 曲线下面积的算法,我们可以假设这些大地震在里氏震级以上 6.0 级。

图: 地震ROC曲线
上图以橙色显示地震线。蓝色区域是我们从 Spark 程序中获得的 ROC 曲线。让我们放大曲线以获得更好的图片。

图: 可视化地震点
我们已经根据 ROC 曲线绘制了地震曲线。在橙色曲线高于蓝色区域的点上,我们预测地震为大地震,即震级大于 6.0。因此,有了这些知识,我们就可以使用 Spark SQL 并查询现有的 Hive 表来检索电子邮件地址并向人们发送个性化的警告电子邮件。因此,我们再次使用技术来拯救人类的生命,让每个人的生活更美好。
现在,Apache Spark 博客到此结束。我希望你喜欢阅读它并发现它内容丰富。到目前为止,您一定已经对什么是 Apache Spark 有了充分的了解。实践示例将使您有必要的信心来处理您在 Apache Spark 中遇到的任何未来项目。实践是掌握任何主题的关键,我希望这篇博客能引起您对 Apache Spark 进一步学习的兴趣。

- 点赞
- 收藏
- 关注作者
评论(0)