PySpark 教程 - 使用 Python 学习 Apache Spark

在数据以如此惊人的速度生成的世界中,在正确的时间正确分析该数据非常有用。Apache Spark 是实时处理大数据和执行分析的最令人惊奇的框架之一。 总之,Python for Spark或 PySpark 是最受欢迎的认证课程之一,让 Scala for Spark 物超所值。所以在这个PySpark 教程博客中,我将讨论以下主题:
PySpark 教程:什么是 PySpark?
Apache Spark 是一个快速的集群计算框架,用于处理、查询和分析大数据。基于内存计算,它比其他几个大数据框架有优势。

开源社区最初用 Scala 编程语言编写,开发了一个了不起的工具来支持 Python for Apache Spark。PySpark 通过其库Py4j帮助数据科学家与 Apache Spark 和 Python 中的RDD 交互。 有许多特性使 PySpark 成为比其他框架更好的框架:
- 速度: 比传统的大规模数据处理框架快 100 倍
- 强大的缓存: 简单的编程层提供强大的缓存和磁盘持久化能力
- 部署: 可以通过 Mesos、Hadoop 通过 Yarn 或 Spark 自己的集群管理器进行部署
- 实时: 由于内存计算,实时计算和低延迟
- Polyglot: 支持 Scala、Java、Python 和 R 编程
让我们继续我们的 PySpark 教程博客,看看 Spark 在行业中的哪些应用。
行业中的 PySpark
每个行业都围绕大数据展开,哪里有大数据,哪里就有分析。那么让我们来看看使用 Apache Spark 的各个行业。

媒体是向在线流媒体发展的最大行业之一。 Netflix使用 Apache Spark 进行实时流处理,为其客户提供个性化的在线推荐。它每天处理4500 亿个流向服务器端应用程序的事件。

金融是 Apache Spark 的实时处理发挥重要作用的另一个领域。银行正在使用 Spark 访问和分析社交媒体资料,以获取洞察力,从而帮助他们为信用风险评估、有针对性的广告和客户细分做出正确的业务决策。使用 Spark 也减少了客户流失。 欺诈检测是 Spark 涉及的机器学习中使用最广泛的领域之一。

医疗保健提供者正在使用 Apache Spark分析患者记录以及过去的临床数据,以确定哪些患者在出院后可能面临健康问题。Apache Spark 用于基因组测序以减少处理基因组数据所需的时间。

零售和电子商务是一个如果不使用分析和定向广告就无法想象的行业。作为当今最大的电子商务平台之一,阿里巴巴运行着一些世界上最大的 Spark Jobs,以分析 PB 级数据。阿里巴巴在图像数据中进行特征提取。eBay 使用 Apache Spark 提供Targeted Offers,增强客户体验并优化整体性能。
Travel Industries 也使用 Apache Spark。 TripAdvisor是帮助用户规划完美旅行的领先旅游网站,它正在使用 Apache Spark 加速其个性化客户推荐。TripAdvisor 使用 apache spark 通过比较数百个网站为客户找到最优惠的酒店价格,为数百万旅客提供建议。.
本 PySpark 教程的一个重要方面是了解我们为什么需要使用 Python?为什么不是 Java、Scala 或 R?
为什么选择 Python?
易学:对于程序员来说,Python 相对容易学习,因为它的语法和标准库。此外,它是一种动态类型语言,这意味着 RDD 可以保存多种类型的对象。

大量库: Scala 没有足够的数据科学工具和库,例如 Python 用于机器学习和自然语言处理。此外,Scala 缺乏良好的可视化和本地数据转换。

巨大的社区支持: Python 拥有一个全球社区,拥有数百万开发人员,他们在数以千计的虚拟和物理位置进行在线和离线交互。

本 PySpark 教程中最重要的主题之一是 RDD 的使用。让我们了解什么是 RDD
Spark RDD
当谈到迭代分布式计算,即在计算中处理多个作业的数据时,我们需要在多个作业之间重用或共享数据。Hadoop 等早期框架在处理多个操作/作业时遇到问题,例如
- 将数据存储在中间存储中,例如 HDFS
- 多个 I/O 作业使计算变慢
- 复制和序列化反过来使过程更慢
RDD 试图通过启用容错分布式内存计算来解决所有问题。RDD 是弹性分布式数据集的缩写 。 RDD 是一种分布式内存抽象,它允许程序员以容错方式在大型集群上执行内存计算。它们是跨一组机器分区的对象的只读集合,如果分区丢失,可以重建这些对象。在 RDD 上执行了几种操作:
- 转换: 转换从现有数据集创建一个新数据集。懒惰评估
- 动作: Spark 仅在 RDD 上调用动作时才强制执行计算
让我们了解一些转换、动作和函数
读取文件并显示前 n 个元素:
rdd = sc.textFile("file:///home/edureka/Desktop/Sample")
rdd.take(n)输出:
[u'森林砍伐正在成为主要的环境和社会问题,现在已经不仅仅是一个强大的恶魔。',
u'我们必须了解因森林砍伐而出现的问题的原因、影响和解决方法。',
u'我们提供了许多关于森林砍伐的长篇和短文,以帮助您的孩子和孩子了解这个问题,并参与学校或校外的论文写作比赛。',
你可以根据班级标准选择下面给出的任何毁林论文。',
u'森林砍伐正在成为社会和环境面临的主要全球问题。']转换为小写和拆分:(降低和拆分)
def Func(lines):
lines = lines.lower()
lines = lines.split()
return lines
rdd1 = rdd.map(Func)
rdd1.take(5)输出:
[[你'砍伐森林',
你是,
你起床了,
你是,
你那个',
你主要,
你'环保',
你和',
你'社会',
你'问题',
你'哪个',
你有,
你现在,
你被带走了,
.....
.
.
.
]删除停用词:(过滤器)
stop_words = ['a','all','the','as','is','am','an','and','be','been','from','had','I','I’d','why','with']
rdd2 = rdd1.filter(lambda z: z not in stop_words)
rdd2.take(10)输出:
[你'森林砍伐',
你起床了,
你主要,
你'环保',
你'社会',
你'问题',
你'哪个',
你有,
你现在,
你被带走了]从 1 到 500 的数字总和:(减少)
sum_rdd = sc.parallelize(range(1,500))
sum_rdd.reduce(lambda x,y: x+y)124750使用 PySpark 进行机器学习
继续我们的 PySpark 教程博客,让我们分析一些篮球数据并做一些未来预测。所以,这里我们将使用自1980 年 [三分球引进年]以来 NBA 的所有球员的篮球数据。

数据加载:
df = spark.read.option('header','true')
.option('inferSchema','true')
.csv("file:///home/edureka/Downloads/season_totals.csv")印刷栏目:
print(df.columns)输出:
['_c0','玩家','pos','年龄','team_id','g','gs','mp','fg','fga','fg_pct','fg3',' fg3a','fg3_pct','fg2','fg2a','fg2_pct','efg_pct','ft','fta','ft_pct','orb','drb','trb','ast' , 'stl', 'blk', 'tov', 'pf', 'pts', 'yr']排序玩家(OrderBy)和 toPandas:
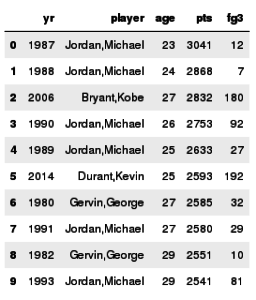
在这里,我们根据一个赛季的得分对球员进行排序。
df.orderBy('pts',ascending = False).limit(10).toPandas()[['yr','player','age','pts','fg3']]
输出:
使用 DSL 和 matplotlib:
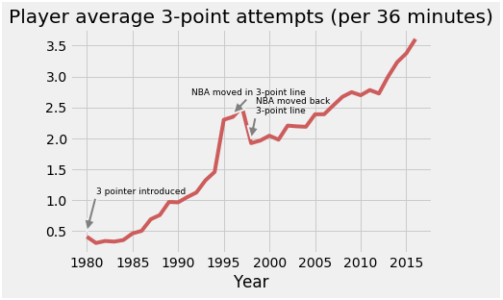
在这里,我们正在分析每个赛季在36 分钟的时间限制内平均出手3 分的次数[这个时间间隔对应于一个近似完整的 NBA 比赛并有足够的休息]。我们使用三分球出手次数 (fg3a) 和上场时间 (mp) 计算此指标,然后使用matlplotlib绘制结果。
from pyspark.sql.functions import col
fga_py = df.groupBy('yr')
.agg({'mp' : 'sum', 'fg3a' : 'sum'})
.select(col('yr'), (36*col('sum(fg3a)')/col('sum(mp)')).alias('fg3a_p36m'))
.orderBy('yr')
from matplotlib import pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
_df = fga_py.toPandas()
plt.plot(_df.yr,_df.fg3a_p36m, color = '#CD5C5C')
plt.xlabel('Year')
_=plt.title('Player average 3-point attempts (per 36 minutes)')
plt.annotate('3 pointer introduced', xy=(1980, .5), xytext=(1981, 1.1), fontsize = 9,
arrowprops=dict(facecolor='grey', shrink=0, linewidth = 2))
plt.annotate('NBA moved in 3-point line', xy=(1996, 2.4), xytext=(1991.5, 2.7), fontsize = 9,
arrowprops=dict(facecolor='grey', shrink=0, linewidth = 2))
plt.annotate('NBA moved back
3-point line', xy=(1998, 2.), xytext=(1998.5, 2.4), fontsize = 9, arrowprops=dict(facecolor='grey', shrink=0, linewidth = 2))输出:
线性回归和 VectorAssembler:
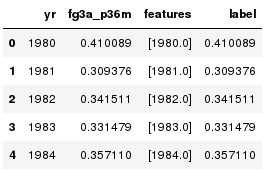
我们可以将线性回归模型拟合到这条曲线上,以模拟未来 5 年的投篮次数。我们必须使用 VectorAssembler 函数将数据转换为单列。这是一个必要条件为在MLlib线性回归API。
from pyspark.ml.feature import VectorAssembler
t = VectorAssembler(inputCols=['yr'], outputCol = 'features')
training = t.transform(fga_py)
.withColumn('yr',fga_py.yr)
.withColumn('label',fga_py.fg3a_p36m)
training.toPandas().head()输出:
建筑模型:
然后我们使用转换后的数据构建我们的线性回归模型对象。
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(maxIter=10)
model = lr.fit(training)将训练好的模型应用于数据集:
我们将经过训练的模型对象模型与 5 年的未来数据一起应用于我们的原始训练集
from pyspark.sql.types import Row
# apply model for the 1979-80 season thru 2020-21 season
training_yrs = training.select('yr').rdd.map(lambda x: x[0]).collect()
training_y = training.select('fg3a_p36m').rdd.map(lambda x: x[0]).collect()
prediction_yrs = [2017, 2018, 2019, 2020, 2021]
all_yrs = training_yrs + prediction_yrs
# built testing DataFrame
test_rdd = sc.parallelize(all_yrs)
row = Row('yr')&lt
all_years_features = t.transform(test_rdd.map(row).toDF())
# apply linear regression model
df_results = model.transform(all_years_features).toPandas()绘制最终预测:
然后我们可以绘制我们的结果并将图表保存在指定的位置。
plt.plot(df_results.yr,df_results.prediction, linewidth = 2, linestyle = '--',color = '#224df7', label = 'L2 Fit')
plt.plot(training_yrs, training_y, color = '#f08080', label = None)
plt.xlabel('Year')
plt.ylabel('Number of attempts')
plt.legend(loc = 4)
_=plt.title('Player average 3-point attempts (per 36 minutes)')
plt.tight_layout()
plt.savefig("/home/edureka/Downloads/Images/REGRESSION.png")输出:
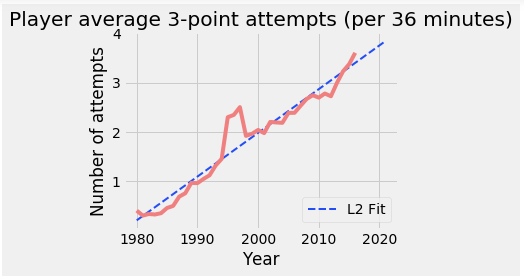
有了这张图,我们就结束了这个 PySpark 教程博客。
所以就是这样,伙计们!
我希望你们对 PySpark 是什么、为什么 Python 最适合 Spark、RDD 以及在此 PySpark 教程博客中使用 Pyspark 进行机器学习的一瞥有所了解。恭喜,您不再是 PySpark 的新手。如果您想了解有关 PySpark 的更多信息并了解不同的行业用例,请查看我们的Spark 与 Python博客。

- 点赞
- 收藏
- 关注作者
评论(0)