Spark 与 Python 简介 – PySpark 初学者

在处理和使用大数据方面, Apache Spark是使用最广泛的框架之一,而Python是用于数据分析、机器学习等的最广泛使用的编程语言之一。那么,为什么不一起使用它们呢?这就是Spark with Python也称为PySpark出现的地方。
Apache Spark 简介
Apache Spark 是由 Apache 软件基金会开发的用于实时处理的开源集群计算框架。Spark 提供了一个接口,用于对具有隐式数据并行性和容错性的整个集群进行编程。
以下是 Apache Spark 的一些特性,这些特性使其比其他框架更具优势:
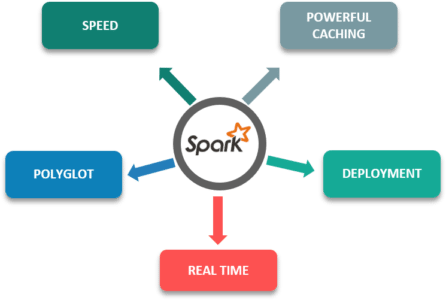
- 速度:比传统的大规模数据处理框架快 100 倍。
- 强大的缓存:简单的编程层提供了强大的缓存和磁盘持久化能力。
- 部署: 可以通过 Mesos、Hadoop 通过 Yarn 或 Spark 自己的集群管理器进行部署。
- 实时: 由于内存计算,实时计算和低延迟。
- Polyglot:这是该框架最重要的特性之一,因为它可以用 Scala、Java、Python 和 R 进行编程。
为什么选择 Python?
虽然 Spark 是用 Scala 设计的,这使它比 Python 快了近 10 倍,但 Scala 只有在使用的内核数量较少时才能更快。由于现在大部分的分析和处理都需要大量的内核,所以Scala的性能优势并没有那么大。

对于程序员来说,Python相对容易 学习,因为它的语法和标准库。此外,它是一种动态类型语言,这意味着 RDD 可以保存多种类型的对象。

尽管 Scala 有SparkMLlib,但它没有足够的库和工具用于机器学习和 NLP目的。此外,Scala 缺乏数据可视化。
使用 Python (PySpark) 设置 Spark
我希望你们知道如何下载火花并安装它。所以,一旦你解压了 spark 文件,安装了它并将它的路径添加到.bashrc文件中,你需要输入source .bashrc
export SPARK_HOME = /usr/lib/hadoop/spark-2.1.0-bin-hadoop2.7
export PATH = $PATH:/usr/lib/hadoop/spark-2.1.0-bin-hadoop2.7/bin
要打开 pyspark shell,您需要输入命令 ./bin/pyspark
Spark in Industry
Apache Spark 由于其惊人的功能,如内存处理、多语言和快速处理,正被全球许多公司用于各种行业的各种目的:

雅虎使用 Apache Spark 的机器学习功能来个性化其新闻、网页以及目标广告。他们使用 Spark 和 python 来找出什么样的新闻——用户有兴趣阅读和分类新闻故事,以找出什么样的用户有兴趣阅读每一类新闻。
TripAdvisor使用 apache spark 通过比较数百个网站来为客户找到最优惠的酒店价格,从而为数百万旅客提供建议。以可读格式阅读和处理酒店评论所需的时间是在 Apache Spark 的帮助下完成的。
作为全球最大的电子商务平台之一,阿里巴巴 运行着一些世界上最大的 Apache Spark 作业,以分析其电子商务平台上数百 PB 的数据。
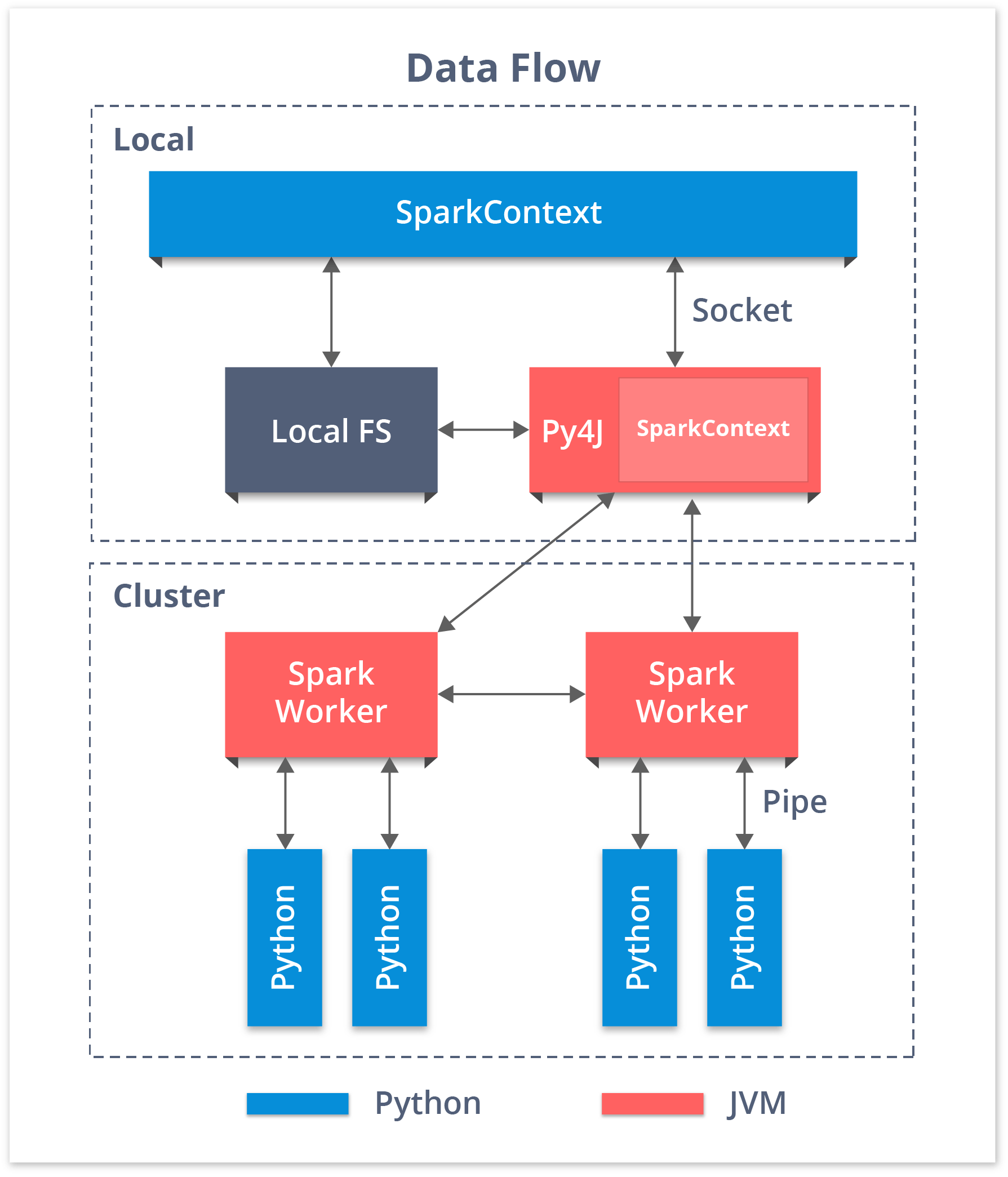
PySpark SparkContext 和数据流
用 Python 谈论 Spark,使用 RDD 是由库 Py4j 实现的。PySpark Shell 将 Python API 链接到 Spark 核心并初始化 Spark 上下文。Spark Context是任何Spark 应用程序的核心。
- Spark 上下文设置内部服务并建立与 Spark 执行环境的连接。
- 驱动程序中的 sparkcontext 对象协调所有分布式进程并允许资源分配。
- Cluster Managers 提供Executors,它是带有逻辑的JVM 进程。
- SparkContext 对象将应用程序发送给执行程序。
- SparkContext 在每个执行器中执行任务。
PySpark KDD 用例

现在让我们来看看KDD'99 Cup(国际知识发现和数据挖掘工具大赛)的一个用例。这里我们取一小部分数据集,因为原始数据集太大了
import urllib
f = urllib.urlretrieve ("<a href="http://kdd.ics.uci.edu/databases/kddcup99/kddcup.data_10_percent.gz">http://kdd.ics.uci.edu/databases/kddcup99/kddcup.data_10_percent.gz</a>", "kddcup.data_10_percent.gz")创建 RDD:
现在我们可以使用这个文件来创建我们的 RDD。
data_file = "./kddcup.data_10_percent.gz"
raw_data = sc.textFile(data_file)过滤:
假设我们要计算有多少正常。我们在数据集中的交互。我们可以按如下方式过滤我们的 raw_data RDD。
normal_raw_data = raw_data.filter(lambda x: 'normal.' in x)数数:
现在我们可以计算新 RDD 中有多少元素。
from time import time
t0 = time()
normal_count = normal_raw_data.count()
tt = time() - t0
print "There are {} 'normal' interactions".format(normal_count)
print "Count completed in {} seconds".format(round(tt,3))输出:
有 97278 次“正常”交互
计数在 5.951 秒内完成映射:
在这种情况下,我们希望将数据文件读取为 CSV 格式的文件。我们可以通过将 lambda 函数应用于 RDD 中的每个元素来做到这一点,如下所示。这里我们将使用map() 和 take() 转换。
from pprint import pprint
csv_data = raw_data.map(lambda x: x.split(","))
t0 = time()
head_rows = csv_data.take(5)
tt = time() - t0
print "Parse completed in {} seconds".format(round(tt,3))
pprint(head_rows[0])输出:
解析在 1.715 秒内完成
[u'0',
u'tcp',
u'http',
u'SF',
u'181',
u'5450',
u'0',
u'0',
.
.
你很正常。”]拆分:
现在我们希望 RDD 中的每个元素都作为一个键值对,其中键是标签(例如 normal),值是代表 CSV 格式文件中行的整个元素列表。我们可以进行如下操作。这里我们使用line.split() 和 map()。
def parse_interaction(line):
elems = line.split(",")
tag = elems[41]
return (tag, elems)
key_csv_data = raw_data.map(parse_interaction)
head_rows = key_csv_data.take(5)
pprint(head_rows[0])输出:
(u'normal.',
[u'0',
u'tcp',
u'http',
u'SF',
u'181',
u'5450',
u'0',
u'0',
u'0.00' ,
u'1.00' ,
。
。
。
。
u'normal。'])
收集行动:
在这里,我们将使用 collect() 操作。它将把 RDD 的所有元素都放入内存中。因此,在处理大型 RDD 时必须小心使用。
t0 = time()
all_raw_data = raw_data.collect()
tt = time() - t0
print "Data collected in {} seconds".format(round(tt,3))输出:
当然,这比我们之前使用的任何其他操作花费的时间更长。每个拥有 RDD 片段的 Spark 工作节点都必须进行协调,以便检索其部分,然后将所有内容减少到一起。
作为结合前面所有内容的最后一个示例,我们希望将所有normal 交互收集 为键值对。
# get data from file
data_file = "./kddcup.data_10_percent.gz"
raw_data = sc.textFile(data_file)
# parse into key-value pairs
key_csv_data = raw_data.map(parse_interaction)
# filter normal key interactions
normal_key_interactions = key_csv_data.filter(lambda x: x[0] == "normal.")
# collect all
t0 = time()
all_normal = normal_key_interactions.collect()
tt = time() - t0
normal_count = len(all_normal)
print "Data collected in {} seconds".format(round(tt,3))
print "There are {} 'normal' interactions".format(normal_count)输出:
12.485秒采集数据
正常互动97278次就是这样,伙计们!
我希望你喜欢这个 Spark with Python 博客。如果您正在阅读本文,恭喜您!您不再是 PySpark 的新手。现在就在您的系统上试试这个简单的例子。

- 点赞
- 收藏
- 关注作者
评论(0)