数据中心网络架构 — 超融合数据中心网络

目录
数据中心
GSMA 数据显示,预计到 2025 年,全球 5G 渗透率将达到 24%;而 IDC 预测,到 2025 年全球物联网市场规模将达到 1.1 万亿美元。
随着 5G、大数据、物联网、AI 等新技术融入人类社会的方方面面,可以预见,在未来二三十年间人类将迈入基于数字世界的万物感知、万物互联、万物智能的智能社会。
数据中心作为构建数字化社会的信息基石,成为了新的生产力,承担着各类应用的数据存储、数据分析与数据计算的重任。在万物智联时代,数据就是生产要素,算力就是生产力。
因此数据中心聚焦于对数据的高效处理,这种处理能力通常称之为 “算力”。数据中心量纲也从原有的资源规模向算力规模转变,算力中心的概念被业界广泛接受。
现代数据中心主要包括以下核心部件:
- 计算系统:包括用于部署业务的通用计算模块和提供超强算力的高性能计算模块等。
- 存储系统:包括海量存储模块、数据管理引擎、存储专用网络等。
- 数据中心网络:负责联接数据中心内部通用计算、高性能计算和存储模块,它们之间的所有数据交互都要通过数据中心网络实现。
- 能源系统:包括供电模块、温控模块、IT管理模块等。
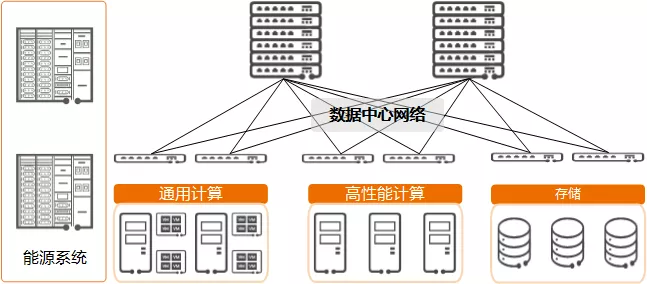
算力中心
根据 ODCC(Open Data Center Committee,开放数据中心委员会)的定义,数据中心的算力要素包含 4 大核心要素,即:
- 通用计算能力
- 高性能计算能力
- 存储能力
- 网络能力
相对的,数据中心内存在三大资源区:
- 通用计算区:与数据中心外部的用户对接,提供指定的应用服务。这个区域中的服务器大量使用虚拟化、容器等技术,形成灵活的资源池来承载应用。
- 高性能计算(HPC)区:配备了专用的高性能单元(e.g. CPU、GPU)的服务器,完成指定的高性能计算任务或 AI 训练。这个区域中的服务器一般很少使用虚拟技术。
- 存储区:采用专用的存储服务器,对各类数据进行存储、读写和备份。
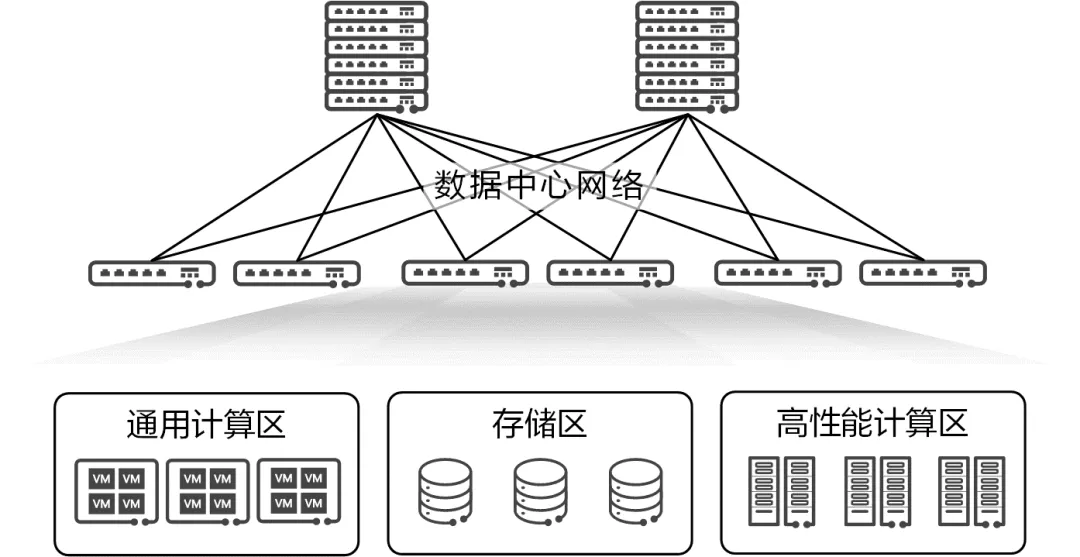
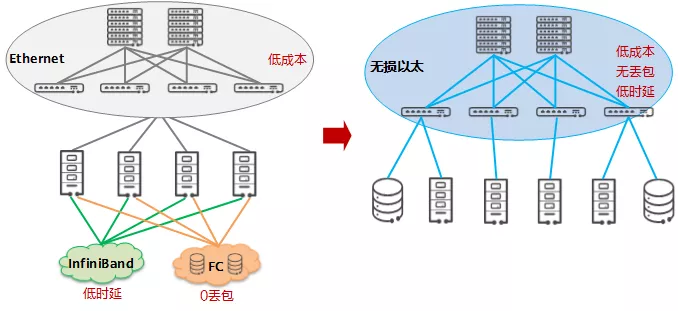
超融合数据中心网络
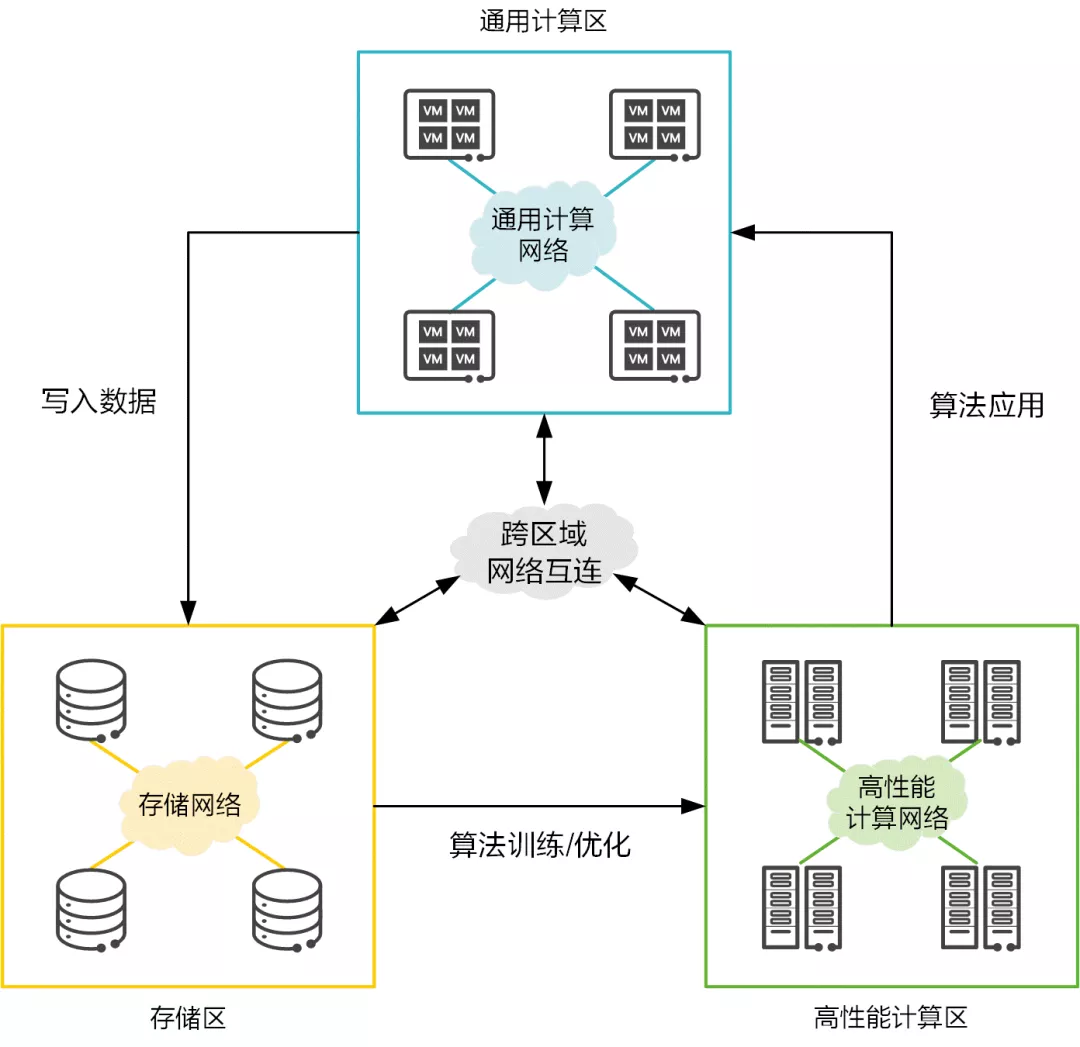
算力持续稳定的输出,离不开三大资源区的相互配合。作为联接数据中心各类资源的大动脉,数据中心网络承载着保障数据高效流通的职责。
数据中心向算力中心演进,网络是数据中心大算力的重要组成部分,提升网络性能,可显著改进数据中心算力能效比。
- 通用计算区:本区域中的网络被称为应用网络、业务网络或前端网络,通用计算业务规模大,扩展性强,要求网络低成本、易扩展。传统部署的是以太网。
- 高性能计算(HPC)区:本区域中的网络被称为高性能计算互联网络,HPC 业务的多节点进程间通信,对于时延要求非常高。传统部署的是 IB(InfiniBand)网络。
- 存储区:本区域中的网络被称为存储网络,存储业务对可靠性诉求非常高,要求网络 0 丢包。传统部署的是 FC(Fibre Channel)网络。
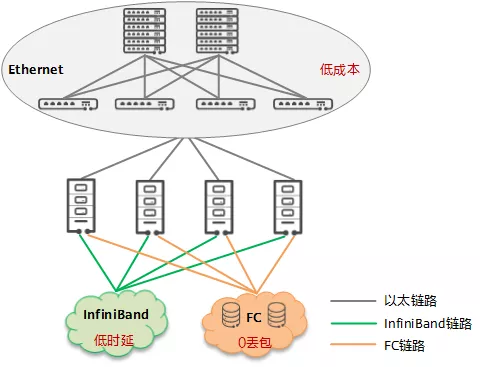
事实证明,在服务器规模不变的情况下,提升网络能力可显著改善数据中心单位能耗下的算力水平。数据中心里这三张网络的融合,成为算力提升的必然要求。
以太网是实现超融合数据中心网络的关键
但是,当前通用计算区部署的传统以太网、高性能计算区部署的 IB 网、存储区部署的 FC 网,是 3 张异构网络,他们协议各异、生态封闭、架构割裂,演进缓慢,带来了运维困难的同时成本也高。根据 IDC 数据显示,近年来 FC 和 IB 市场都在逐步萎缩,已无法匹配云化的发展诉求。
相对的,数据中心的云化趋势助长了对以太网的需求,以太网是当前以及未来主要的数据中心内部网络互联技术,已经成为云化分布式场景中的事实网络标准:
- 以太网已具有很高的开放性,可以与各种云融合部署、可被云灵活调用管理。
- 以太网具有很好的扩展性、互通性、弹性、敏捷性和多租户安全能力。
- 以太网可以满足新业务超大带宽的需求。
- 以太网从业人员多,用户基础好。
基于以太网的 RoCE/RDMA 计算优化
随着计算集群的规模不断扩大,对集群之间互联的网络性能要求也越来越高,这使得计算和网络深度融合成为必然。
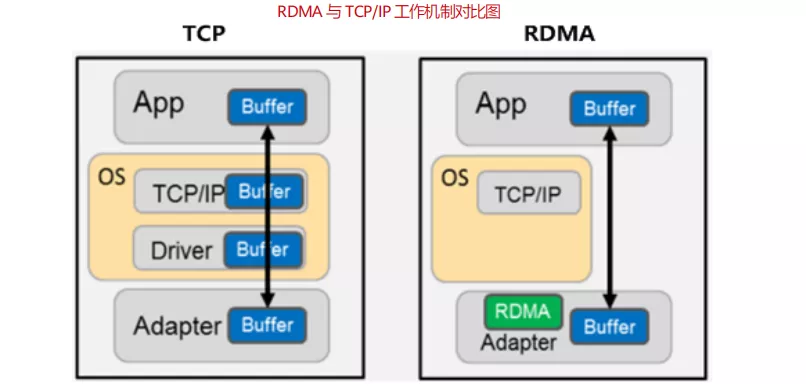
但是,传统的数据中心通常采用以太网技术组成多跳对称的网络架构,使用 TCP/IP 网络协议栈进行传输。但 TCP/IP 网络通信逐渐不适应高性能计算业务诉求,其主要限制有以下两点:
-
TCP/IP 协议栈处理带来数十微秒的时延:如下图所示,在服务器内部,传统的 TCP 协议栈在接收/发送报文,以及对报文进行内部处理时,会产生数十微秒的固定时延,这使得在 AI 数据运算这类微秒级系统中,TCP 协议栈时延成为最明显的瓶颈。
-
TCP 协议栈处理导致服务器 CPU 负载居高不下:随着网络规模的扩大和带宽的提高,宝贵的 CPU 资源越来越地多被用于传输数据。TCP/IP 网络需要主机 CPU 多次参与协议栈内存拷贝。网络规模越大,网络带宽越高,CPU 在收发数据时的调度负担越大,导致 CPU持续高负载。按照业界测算数据:每传输 1bit 数据需要耗费 1Hz 的 CPU,那么当网络带宽达到 25G 以上(满载),对于绝大多数服务器来说,至少 1 半的 CPU能力将不得不用来传输数据。
-
传统的 PCIe 的总线标准由于单通道传输带宽有限,且通道扩展数量也有限:已经无法满足目前大吞吐高性能计算场景的要求。
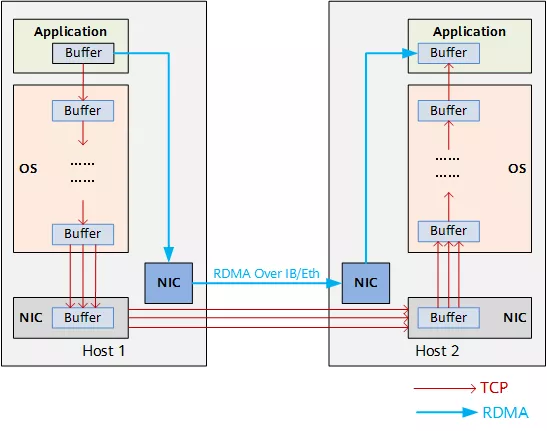
为了降低网络时延和 CPU 占用率,诞生了 RDMA(Remote Direct Memory Access)技术。RDMA 是一种直接内存访问技术,允许应用与网卡之间的直接数据读写,将服务器内的数据传输时延降低到接近 1μs。同时,RDMA 允许接收端直接从发送端的内存读取数据,极大地减少了 CPU 的负担。
RDMA 是相对于 TCP 而言的,可实现计算和网络的深度融合。将数据直接从一台计算机的内存传输到另一台计算机,数据从一个系统快速移动到远程系统存储器中,无需双方操作系统的介入,不需要经过处理器耗时的处理,最终达到高带宽、低时延和低资源占用率的效果。
举例来说,40Gbps 的 TCP/IP 流能耗尽主流服务器的所有 CPU 资源;而在使用 RDMA 的 40Gbps 场景下,CPU 占用率从 100%下降到 5%,网络时延从ms 级降低到 10μs 以下。
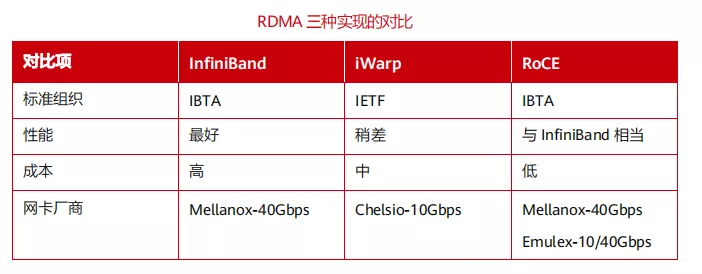
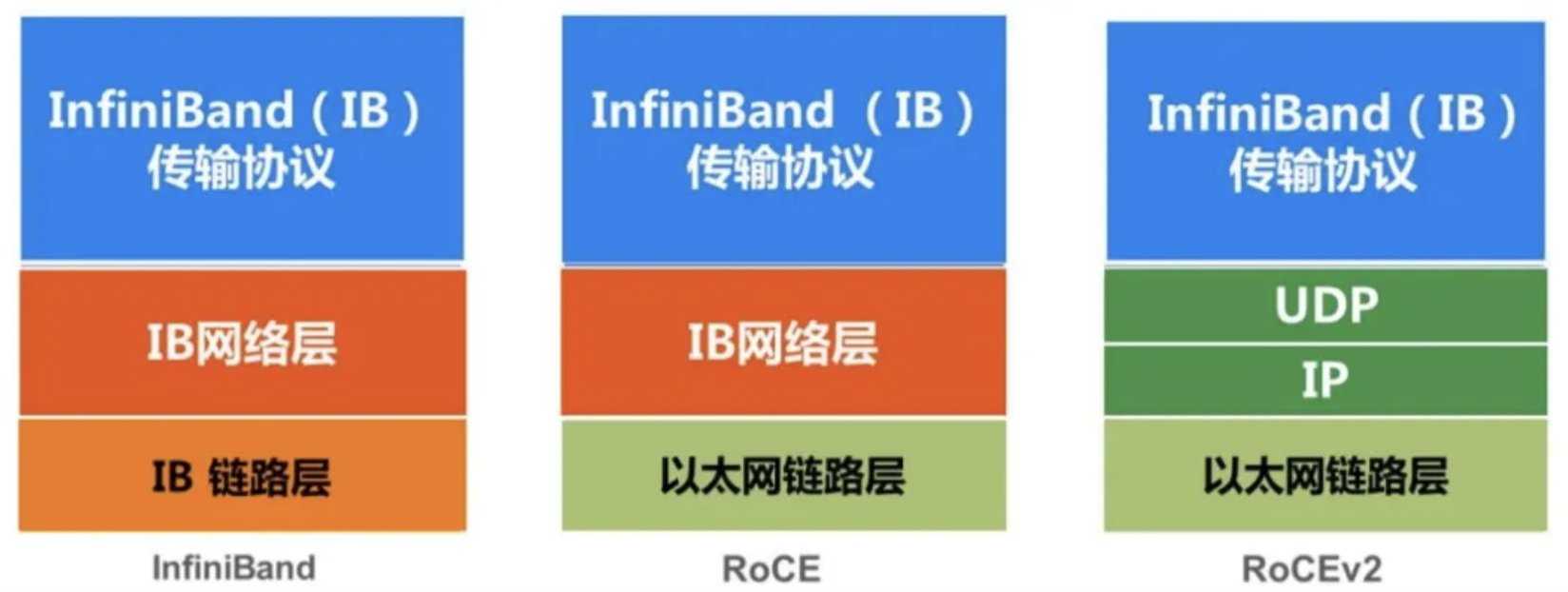
目前,RDMA 替换 TCP 已成为大势所趋。当前业界的主流是在计算处理器内集成 RoCE(Remote Direct Memory Access over Converged Ethernet,基于融合以太的远程内存直接访问协议)以太端口,从而让数据通过标准以太网在传输速度和可扩展性上获得了巨大的提升。
由于 RDMA 对于丢包是非常敏感的。TCP 协议丢包重传是大家都熟悉的机制,TCP 丢包重传是精确重传,发生重传时会去除接收端已接收到的报文,减少不必要的重传,做到丢哪个报文重传哪个。
然而 RDMA 协议中,每次出现丢包,都会导致整个 message 的所有报文都重传。另外,RoCEv2 是基于无连接协议的 UDP 协议,相比面向连接的 TCP 协议,UDP 协议更加快速、占用 CPU 资源更少,但其不像 TCP 协议那样有滑动窗口、确认应答等机制来实现可靠传输,一旦出现丢包,RoCEv2 需要依靠上层应用检查到了再做重传,会大大降低 RDMA 的传输效率。
因此 RDMA 在无损状态下可以满速率传输,而一旦发生丢包重传,性能会急剧下降。大于 0.001 的丢包率,将导致网络有效吞吐急剧下降。0.01 的丢包率即使得 RDMA 的吞吐率下降为 0,要使得 RDMA 吞吐不受影响,丢包率必须保证在 1e-05(十万分之一)以下,最好为零丢包。
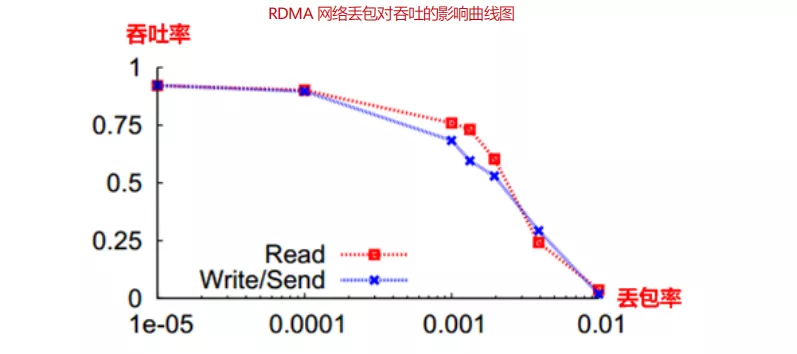
RoCEv2 是将 RDMA 运行在传统以太网上,传统以太网是尽力而为的传输模式,无法做到零丢包,所以为了保证 RDMA 网络的高吞吐低时延,需要交换机支持无损以太网技术。
基于以太网的 NVMe 存储优化
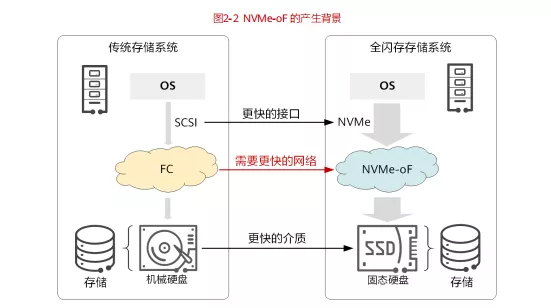
新业务对海量数据的存储和读写需求,催生了存储介质的革新,由 HDD(Hard Disk Drive,机械硬盘)快速向 SSD(Solid-State Drive,固态硬盘)切换,这带来了存储性能近 100 倍的提升。
但是,原来承载存储业务的 FC 网络,无论从带宽还是时延上,均已经成为当前存储网络的瓶颈。完成革新后的全新存储系统,需要一个更快、更高质量的网络。
为此,存储与网络从架构和协议层进行了深度重构。在此过程中,出现了 NVMe(Non-Volatile Memory express,非易失性内存主机控制器接口规范)存储协议,NVMe 极大提升了存储系统内部的存储吞吐性能,降低了传输时延。
同时,新一代存储网络技术 NVMe over Fabric(简称 NVMe-oF)也应运而生。NVMe-oF 将 NVMe 协议应用到服务器主机前端,作为存储阵列与前端主机连接的通道,可端到端取代 SAN 网络中的 SCSI(Small Computer System Interface,小型计算机系统接口)协议。
通过 RoCE 来作为 NVMe over 的 Fabric,即:NVMe over RoCE,是基于融合以太网的 RDMA 技术来承载 NVMe,比 FC 性能更高(更高的带宽、更低的时延),同时兼具 TCP 的优势(全以太化、全 IP 化),因此 NVMe over RoCE 作为新一代存储网络已经脱颖而出,成为业界 NVMe-oF 的主流技术。
超融合数据中心网络的指标
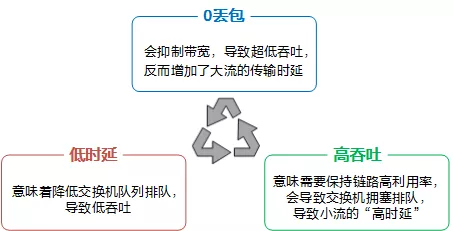
为了满足 AI 时代的数据高效处理诉求、应对分布式架构挑战,对下一代数据中心网络提出了 3 个核心指标:
- 0 丢包
- 低时延
- 高吞吐
这 3 个核心指标互相影响,同时达到最优有很大的挑战。
同时满足 0 丢包、低时延、高吞吐,背后的核心技术是拥塞控制算法。通用的无损网络的拥塞控制算法 DCQCN(Data Center Quantized Congestion Notification),需要网卡和网络进行协作,每个节点需要配置数十个参数,全网的参数组合达到几十万;相反的,为了简化配置,只能采用通用的配置,导致针对不同的流量模型,常常无法同时满足这三个核心指标。
文章来源: is-cloud.blog.csdn.net,作者:范桂飓,版权归原作者所有,如需转载,请联系作者。
原文链接:is-cloud.blog.csdn.net/article/details/121650559

- 点赞
- 收藏
- 关注作者
评论(0)