Atlas集成大数据组件

Atlas集成外部组件
安装好Atlas只是第一步,接下来我们得采集相关大数据组件的元数据,所以得跟大数据组组件做集成。如果是手工安装的Apache版本的Atlas,我们还需要单独做Atlas跟其他组件的集成配置才能管理他们的元数据,比如HBase、Hive、Storm、kafka等。我们所要做的就是采集元数据和使用即可。
1、集成Hive
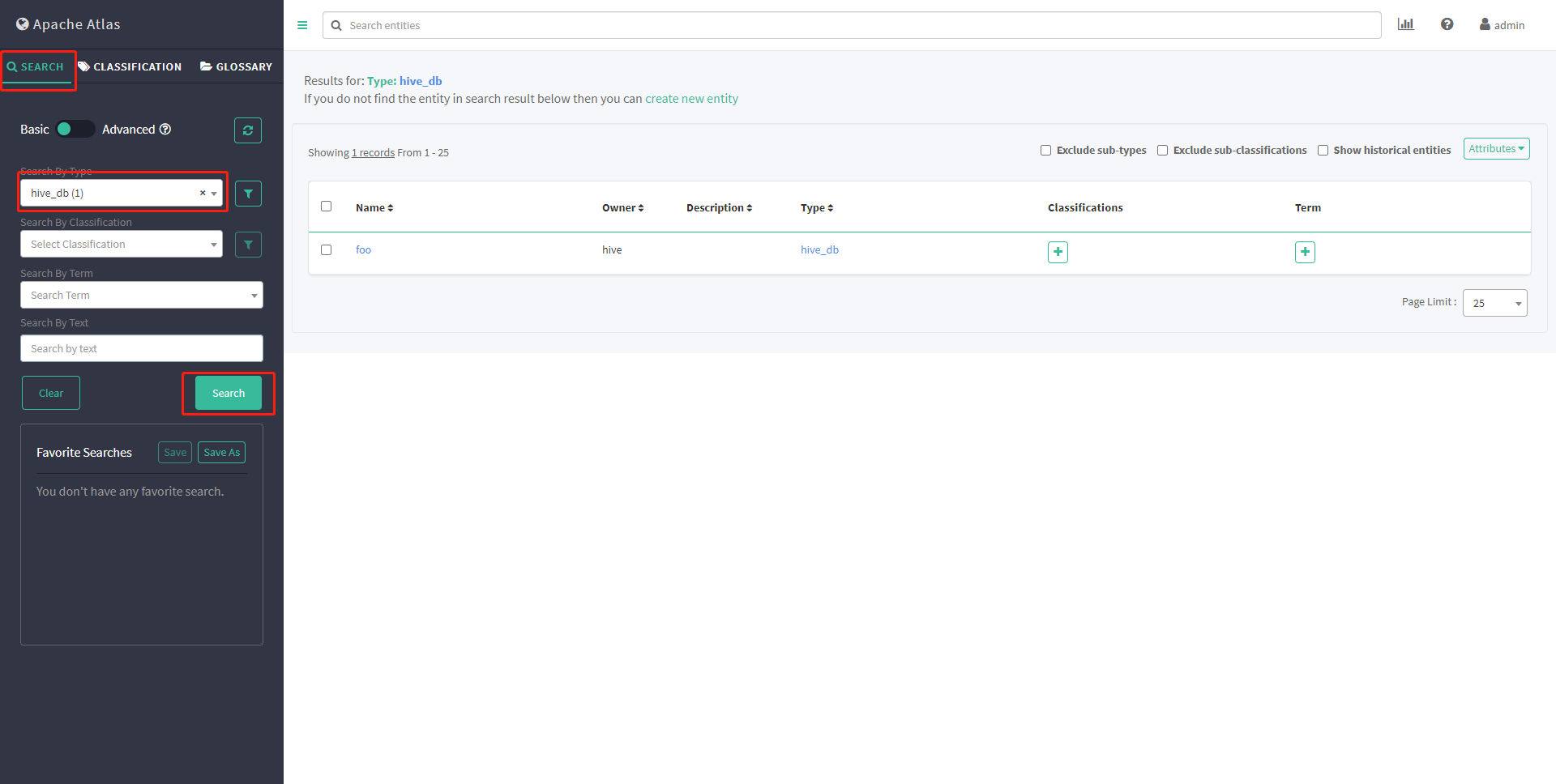
没有任何表,第一次你会没有看见database,后续操作后再次查看出现foo
# 切换到hive用户
su - hive
# 进入hive
hive
# 查看hive数据库
show databases;
# 创建databases
create database if not exists foo
# 再次查看
show databases;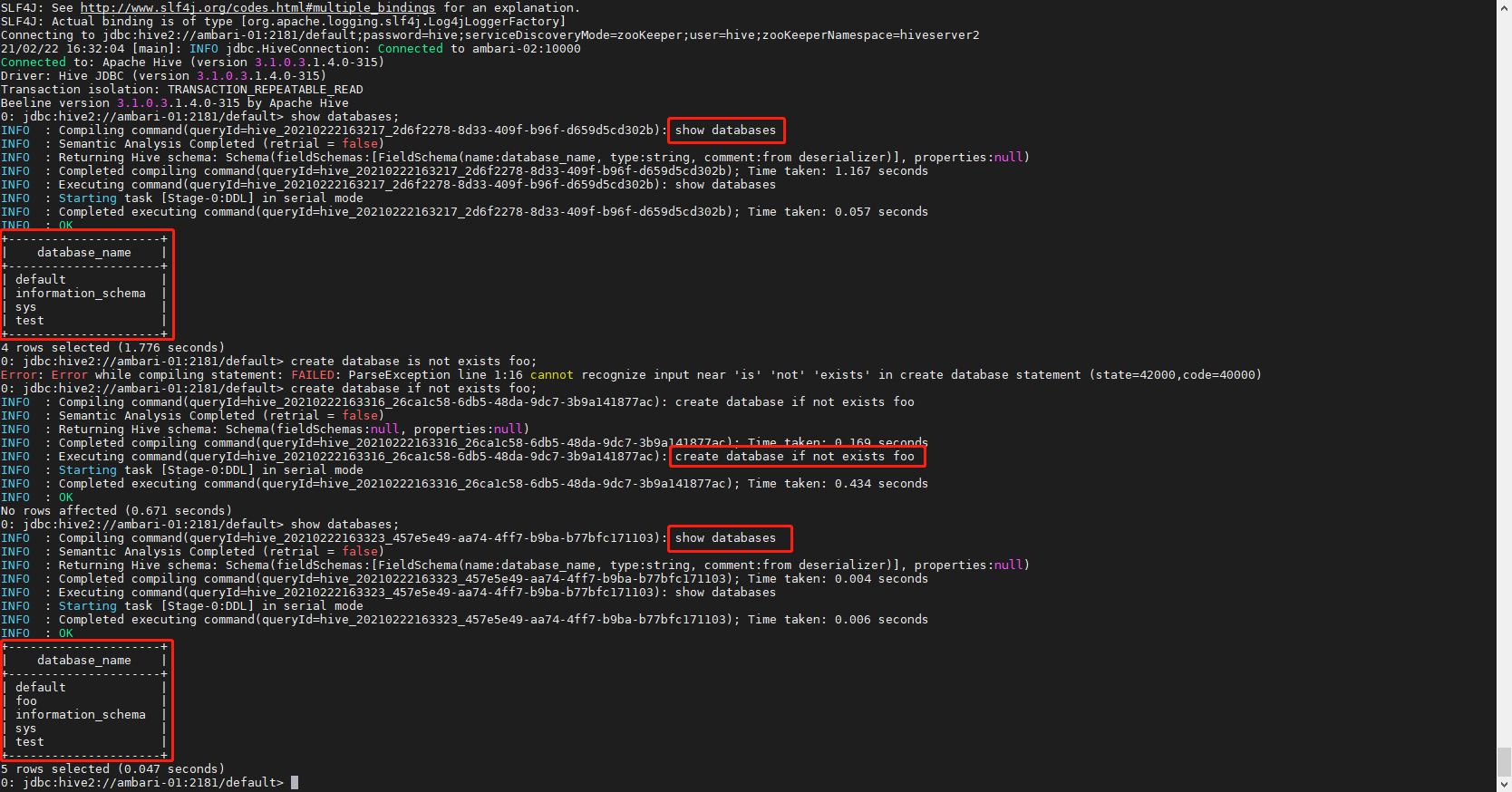
历史元数据处理
在上线Atlas之前Hive可能运行很久了,所以历史上的元数据无法触发hook,因此需要一个工具来做初始化导入。Apache Atlas提供了一个命令行脚本 import-hive.sh ,用于将Apache Hive数据库和表的元数据导入Apache Atlas。该脚本可用于使用Apache Hive中的数据库/表初始化Apache Atlas。此脚本支持导入特定表的元数据,特定数据库中的表或所有数据库和表。
# 切换到 atlas 用户
su - atlas
# 执行导入脚本
/usr/hdp/current/atlas-client/hook-bin/import-hive.sh
# 账户密码 admin admin123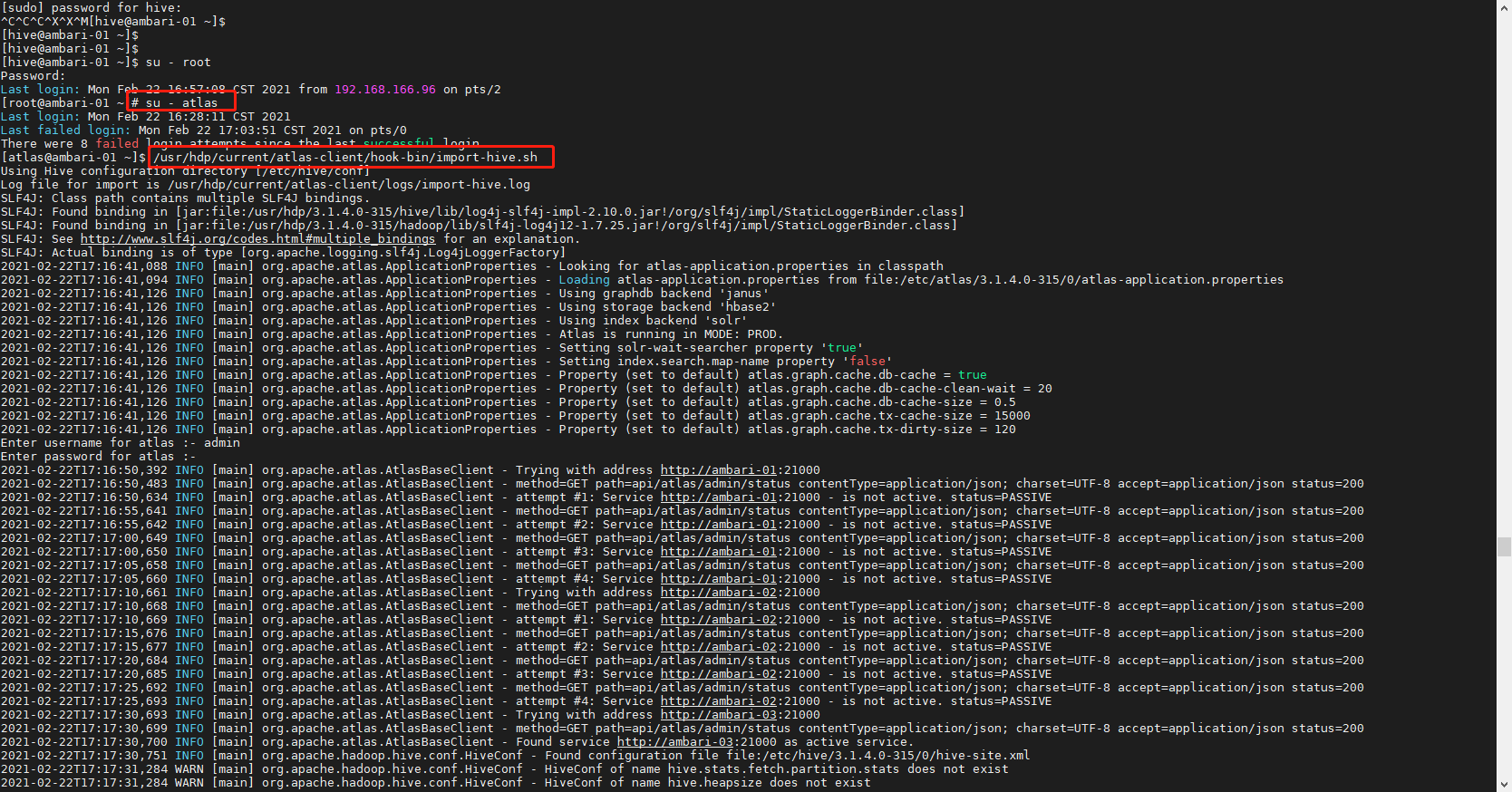
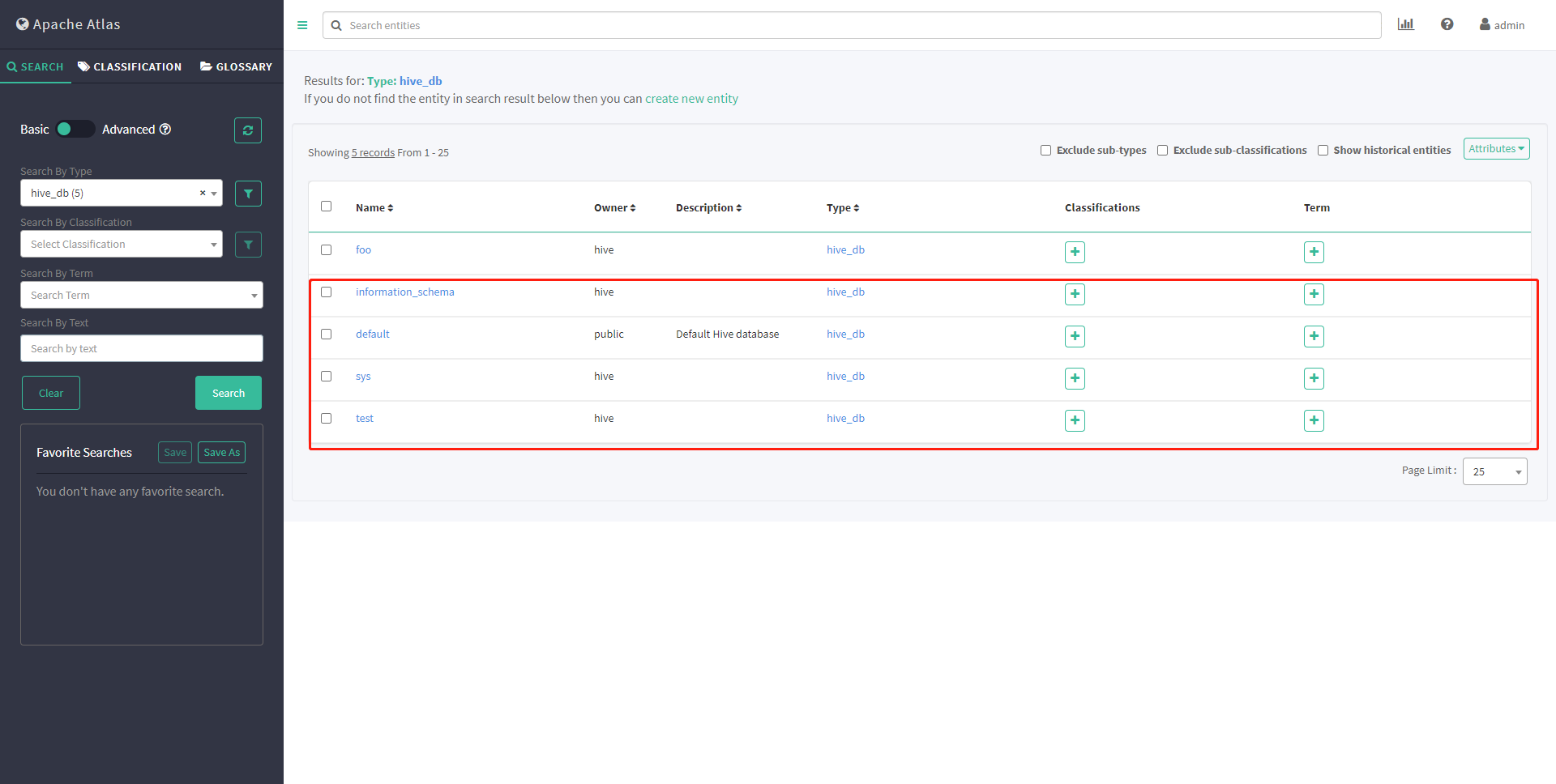
看到新导入的database 则证明历史元数据导入成功
2、集成HBase
Atlas HBase hook与HBase master注册为协处理器。在检测到对HBase名称空间/表/列族的更改时,Atlas Hook过Kafka通知更新Atlas中的元数据。按照以下说明在HBase中设置Atlas Hook:
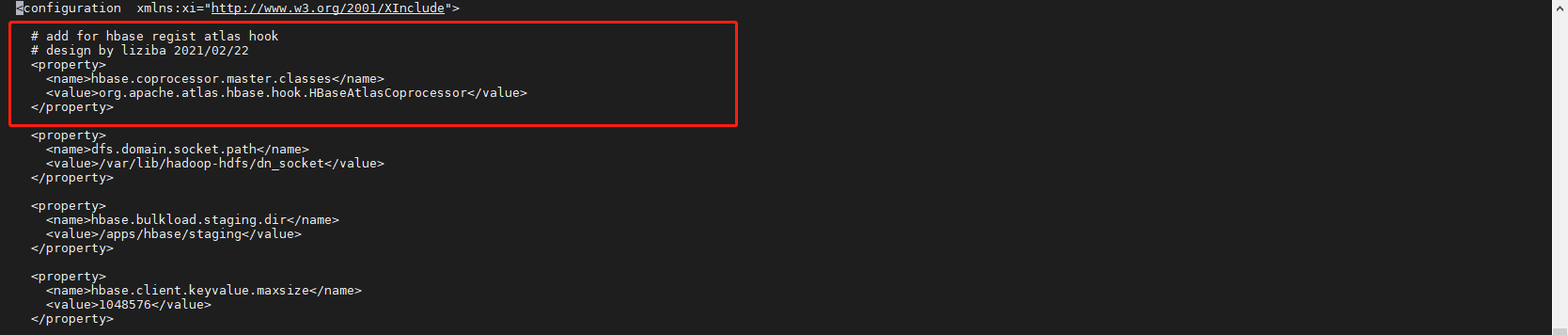
# 编辑 hbase-site.xml
cd /etc/hbase/conf
vi hbase-site.xml
# add for hbase regist atlas hook
# design by liziba 2021/02/22
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.atlas.hbase.hook.HBaseAtlasCoprocessor</value>
</property>
查看元数据
# 切换到hadoop
su - hadoop
# 创建hbase table
hbase shell
create 't1', 'cf1'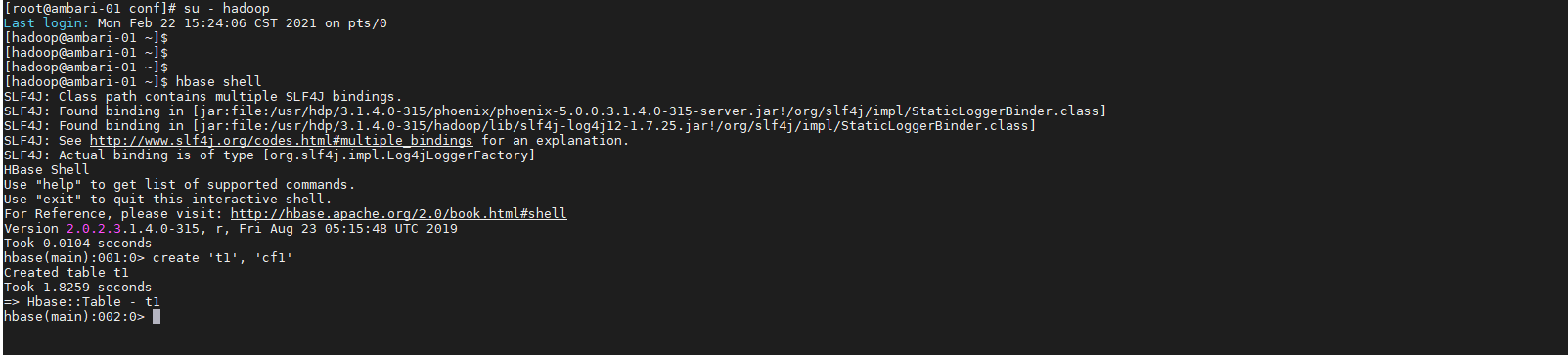
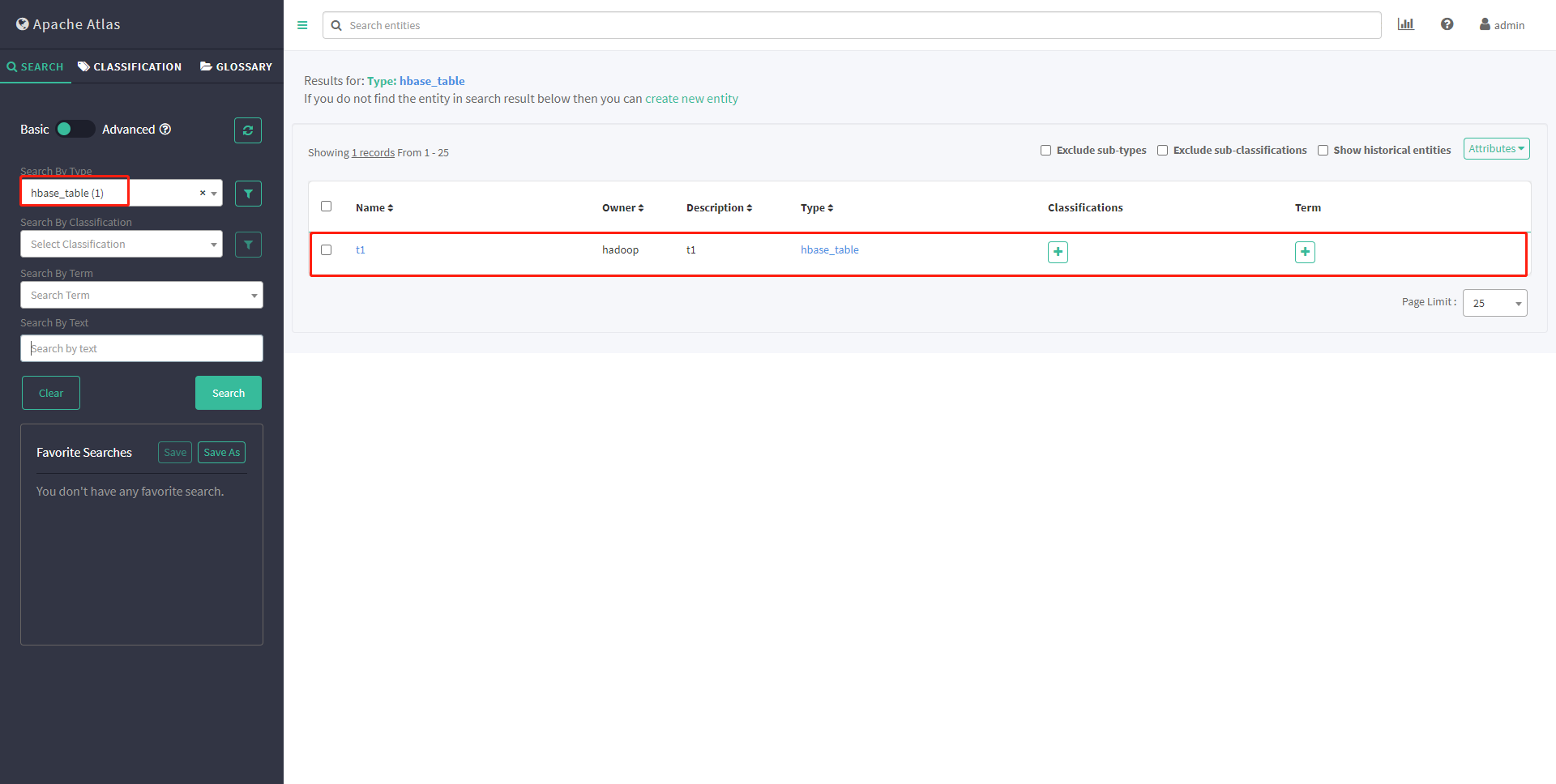
再次查看元数据
历史元数据导入
同样,HBase也会在Atlas上线之前早就上线了,所以需要同步历史上的元数据。
注意:一定要进入atlas用户,因为Atlas的Linux管理账户是atlas,其他账户下可能会报没有权限的错误。
sudo su - atlas
/usr/hdp/current/atlas-client/hook-bin/import-hbase.sh
# 密码 admin admin123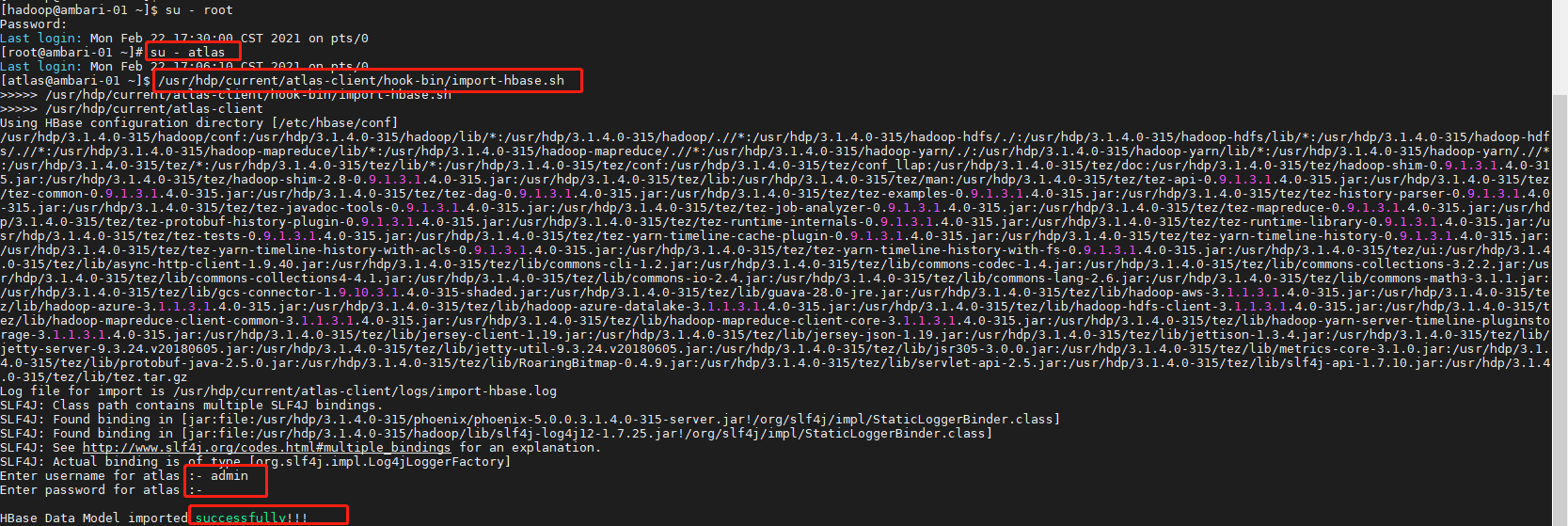
再次查看元数据
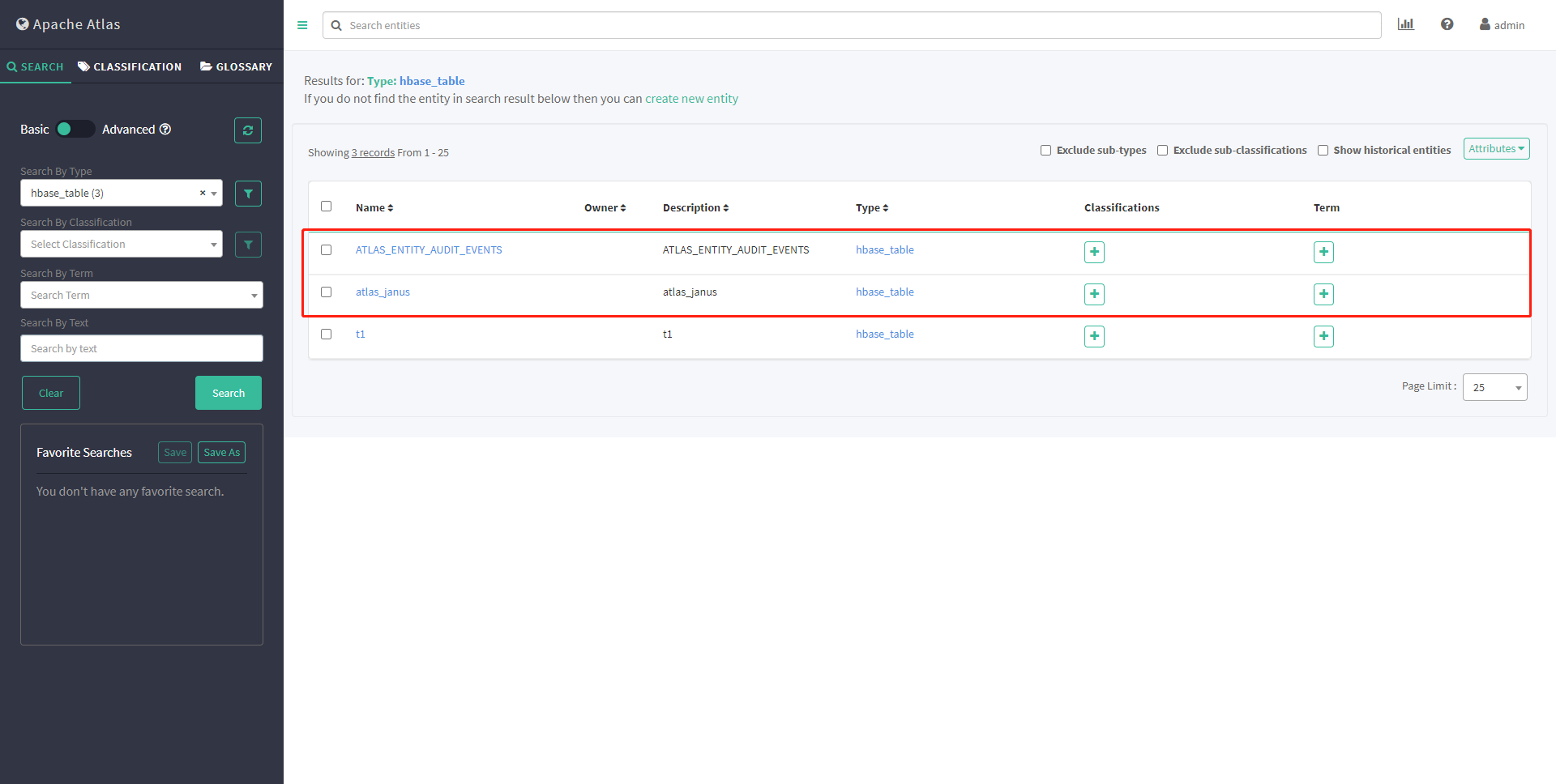
3、集成Kafka
3.1Bug规避
HDP3.1有一个Bug,安装Atlas时不会自动安装atlas-kafka-hook。
3.1.1 发现bug
# 进入hook-bin目录
cd /usr/hdp/current/atlas-client/hook-bin
可以看到并没有Kafka的import脚本。
然后再登录HDP yum源所在节点(安装Ambari时使用的Httpd)
cd /var/www/html/HDP/centos7/3.1.4.0-315/atlas
ls -l
上图中我们可以看到atlas-kafka插件包是提供了的,接下来可以看看该插件在Kakfa节点上是否安装。
登录任意Kafka节点:
yum list atlas-metadata_3_1_4_0_315-kafka-plugin并未安装atlas-metadata_3_1_4_0_315-kafka-plugin

结论 HDP-3.1.4.0中,Ambari安装Atlas时没有自动安装atlas-metadata_3_1_4_0_315-kafka-plugin,这是一个bug
3.1.2 规避bug
在 Kafka的任意Clien节点安装atlas-metadata_3_1_4_0_315-kafka-plugin: ambari-02 167
sudo yum install -y atlas-metadata_3_1_4_0_315-kafka-plugin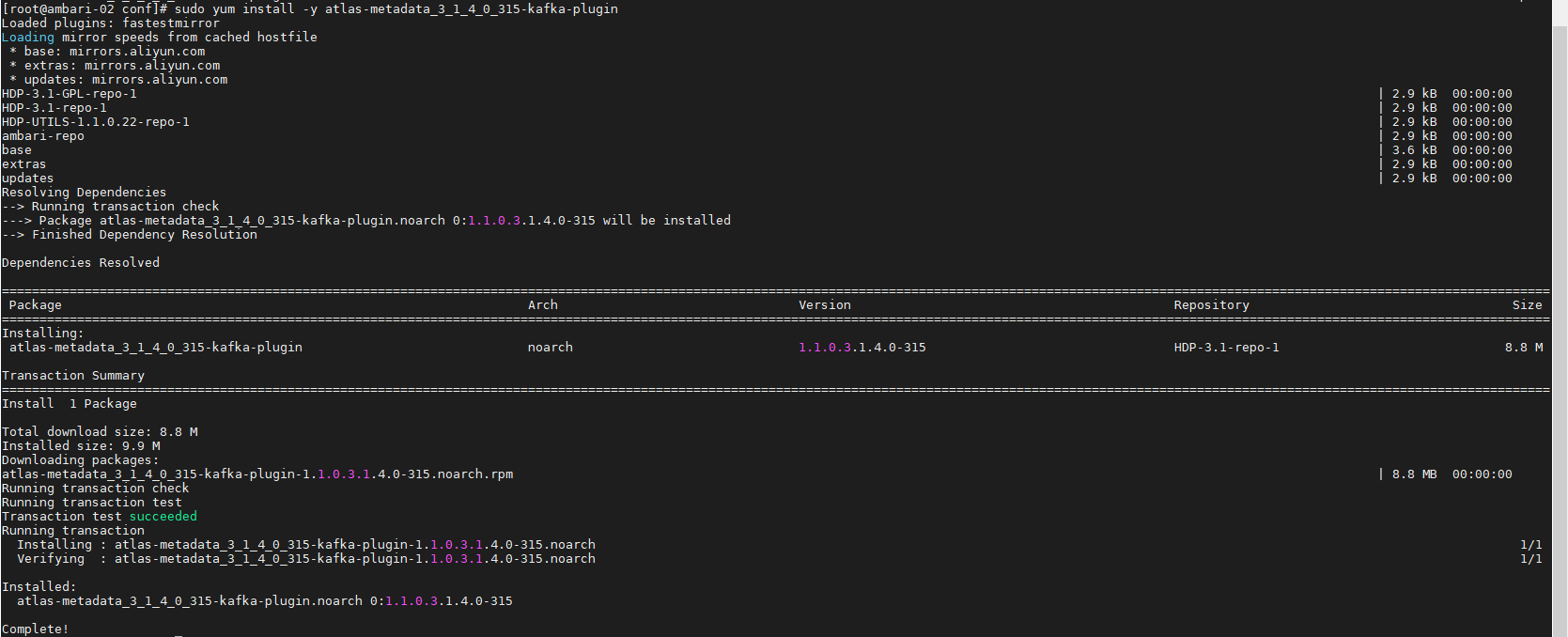
安装完修改下执行权限
sudo chown atlas:hadoop /usr/hdp/current/atlas-client/hook-bin/import-kafka.sh
sudo chown atlas:hadoop /usr/hdp/current/atlas-client/logs/3.1.2 集成原理与局限性
Atlas只提供一个批量导入元数据到Atlas的工具,原理是通过kafka.utils.ZkUtils获取Topic的元数据信息并写入Atlas。
Atlas没有提供Kafka Hook,所以不能实时采集Kafka的元数据,需要定期调度批量导入元数据的脚本。
3.1.3 历史元数据导入
Kafka可能在Atlas上线之前早就上线了,所以需要同步历史上的元数据
查看kakfa_topic 元数据 初始无元数据
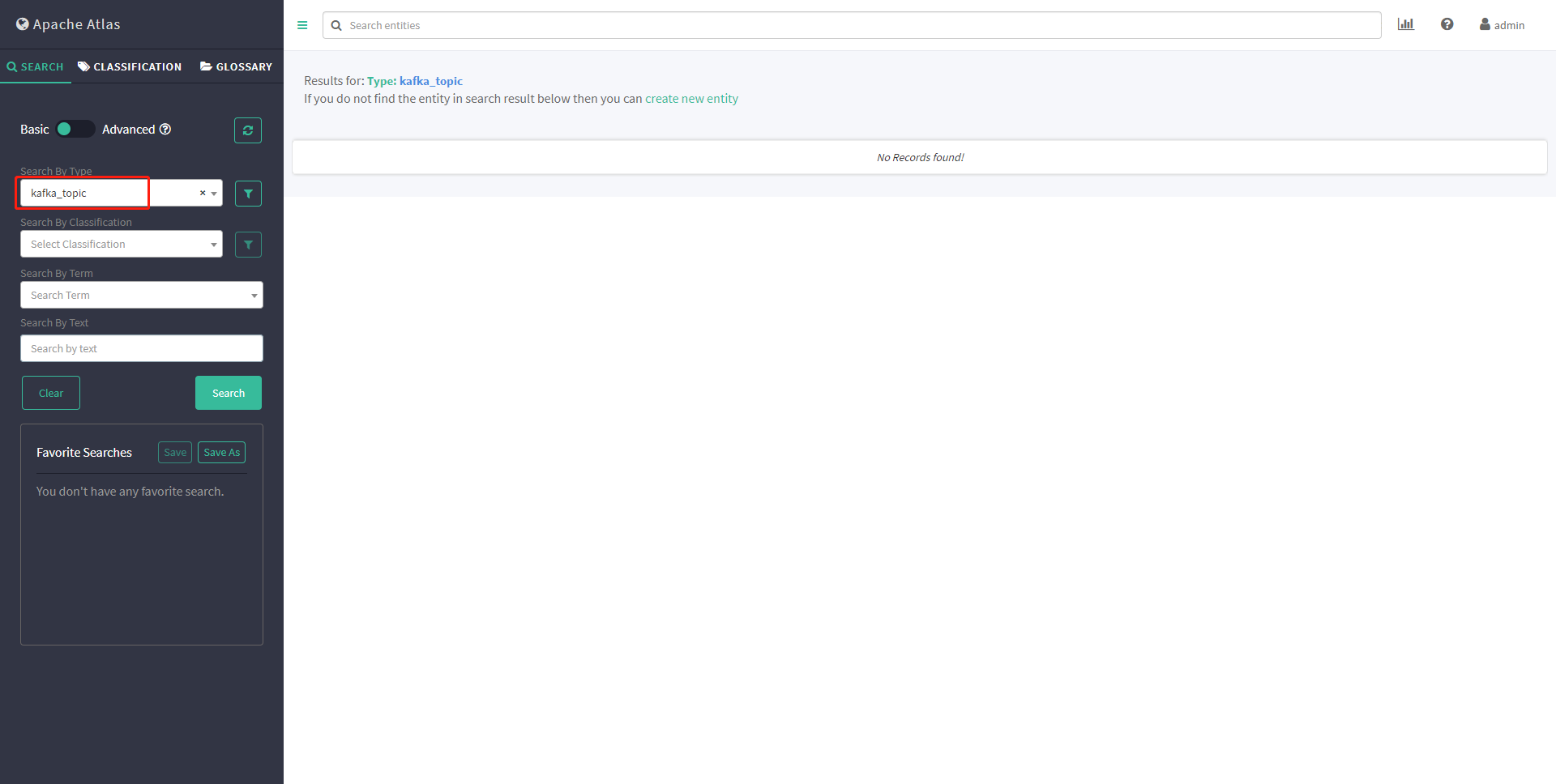
# 在安装kafka插件服务器执行初始化脚本
su - atlas
/usr/hdp/current/atlas-client/hook-bin/import-kafka.sh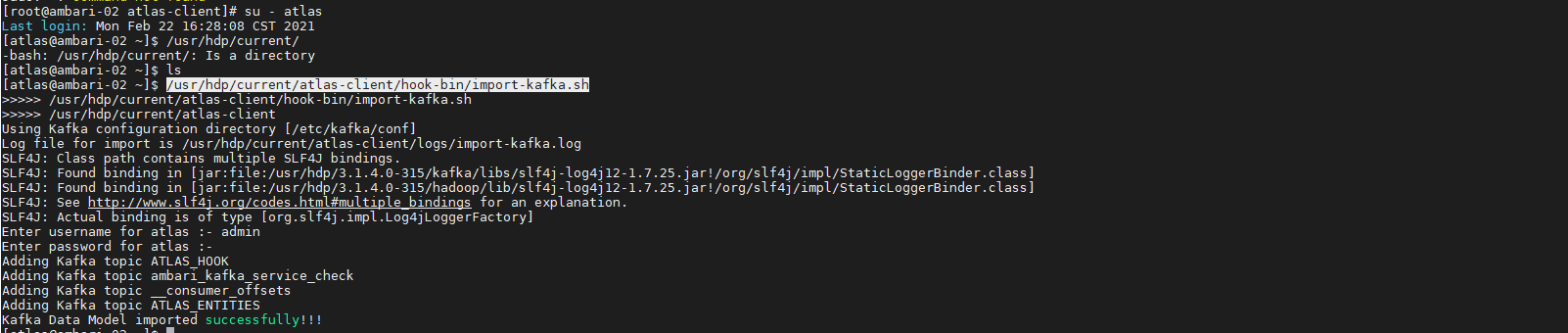
再次查看元数据
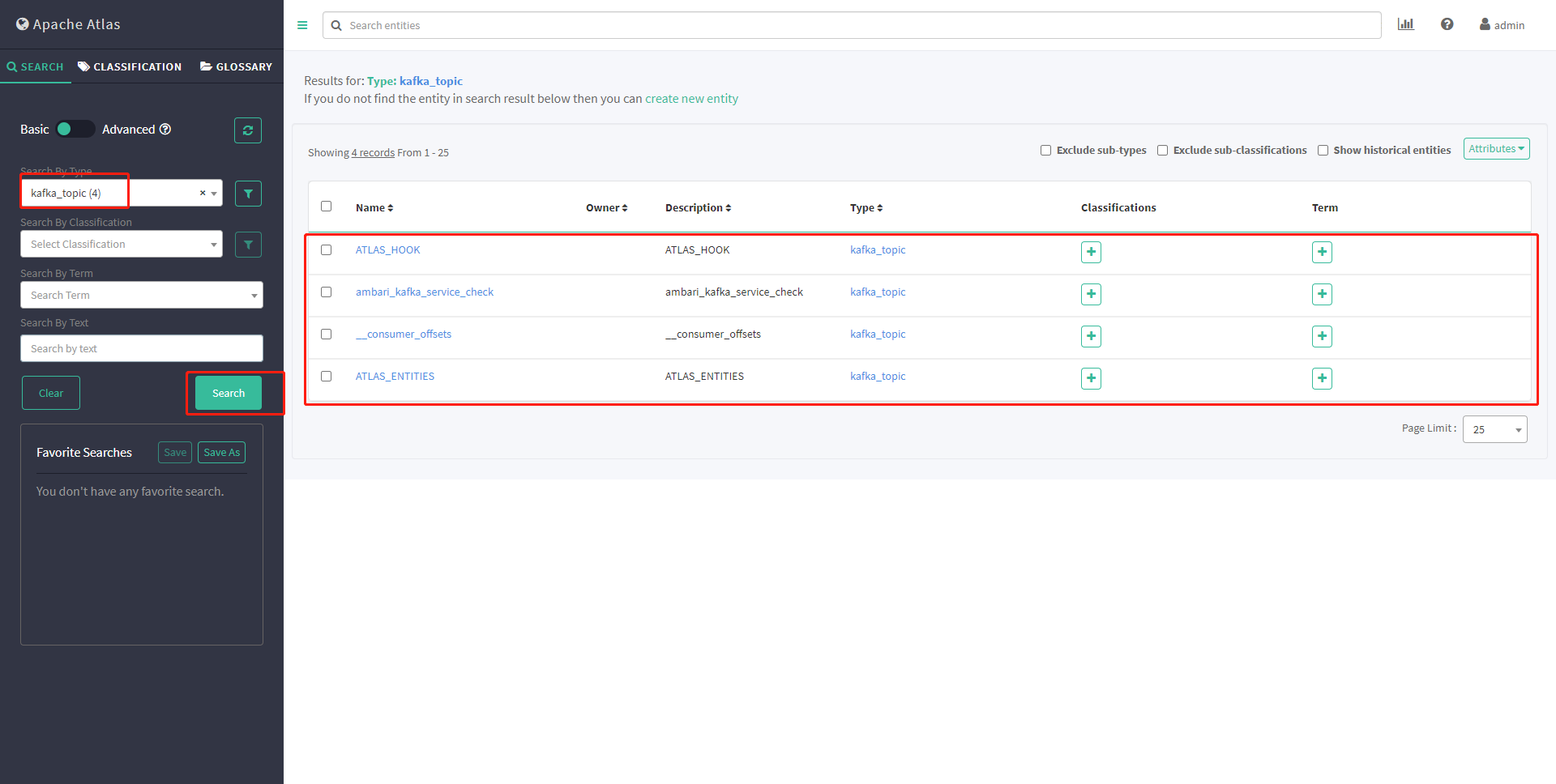
手动创建topic
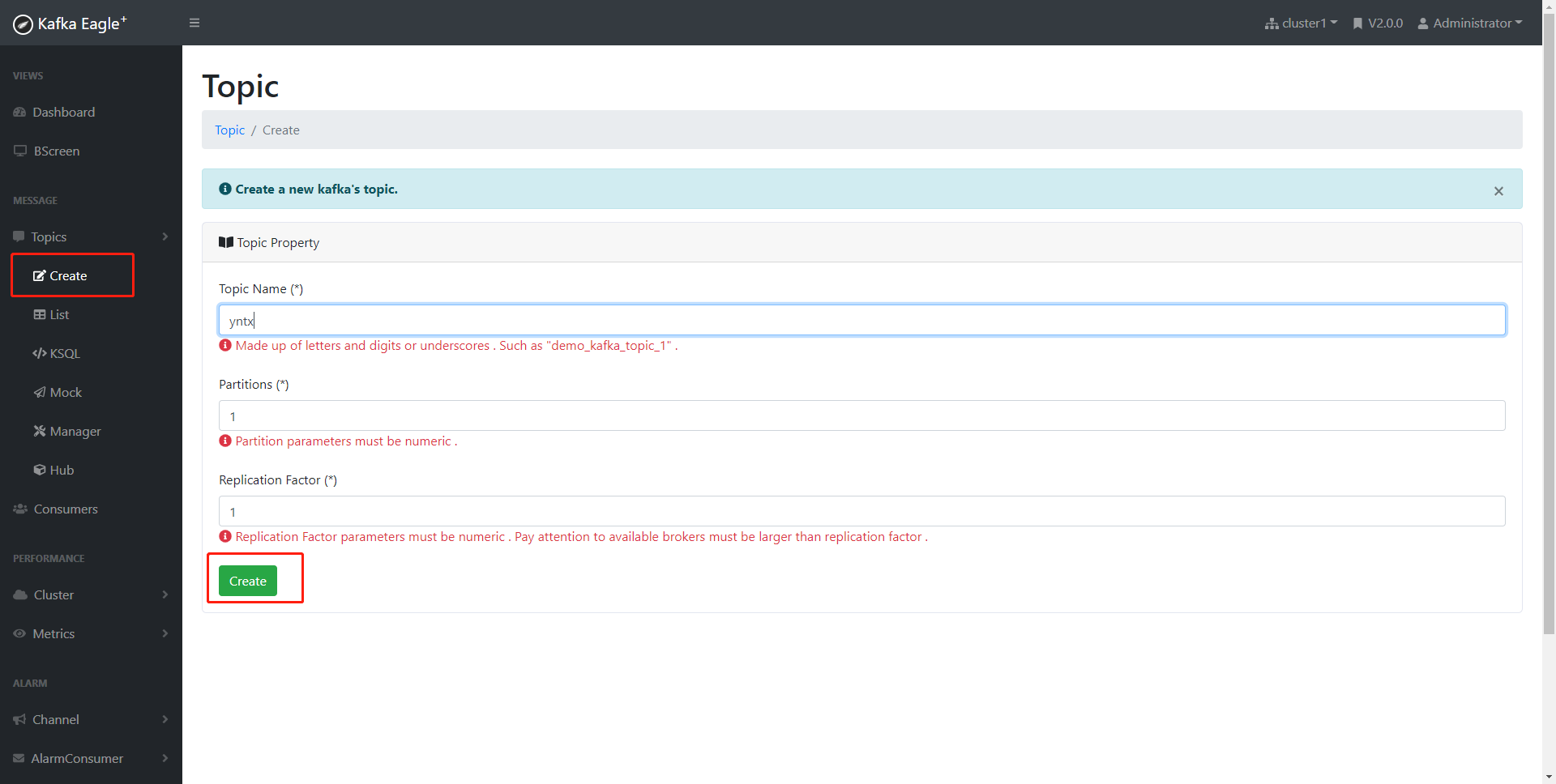
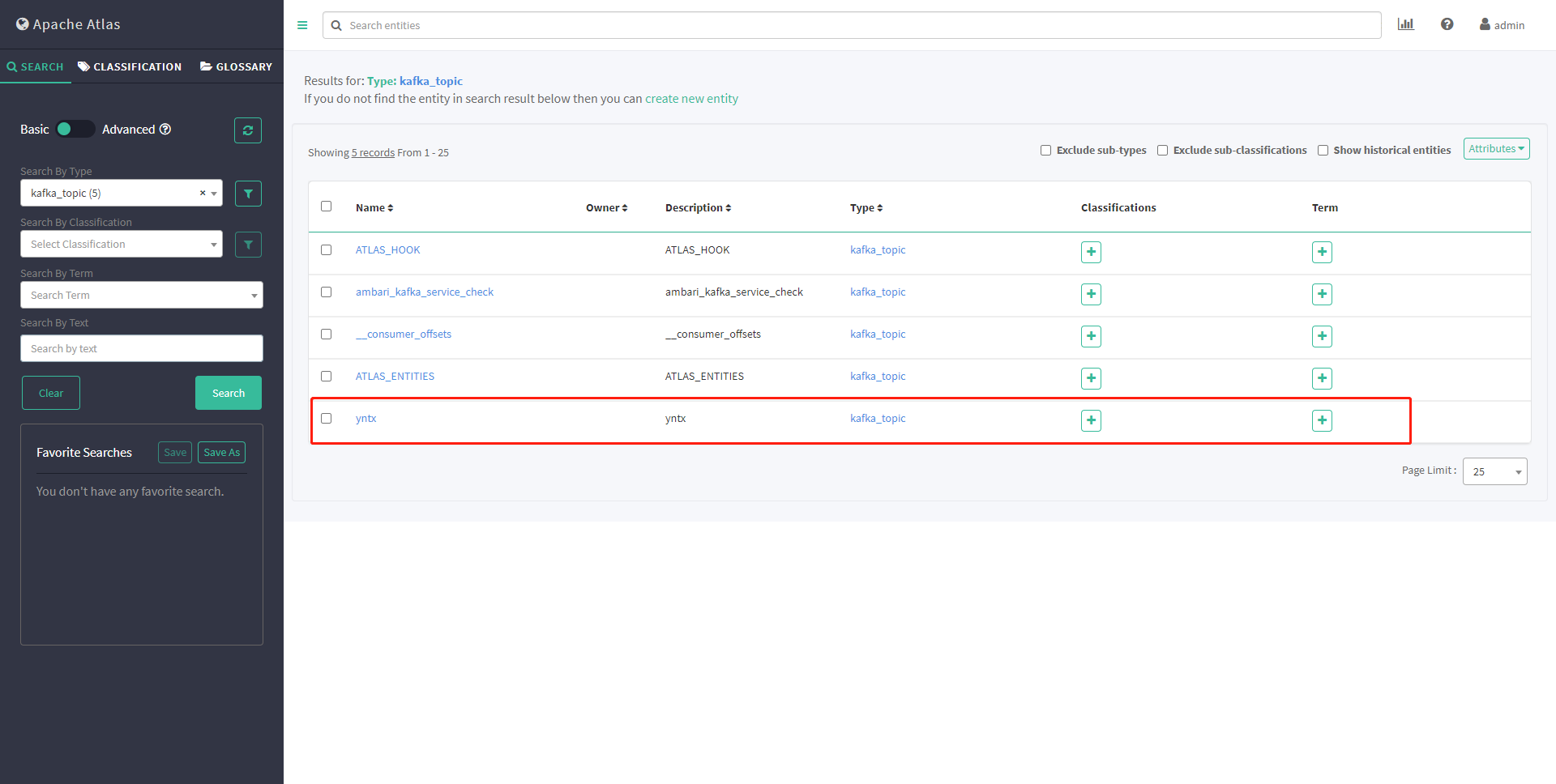
再次查看元数据,并未出现yntx topic
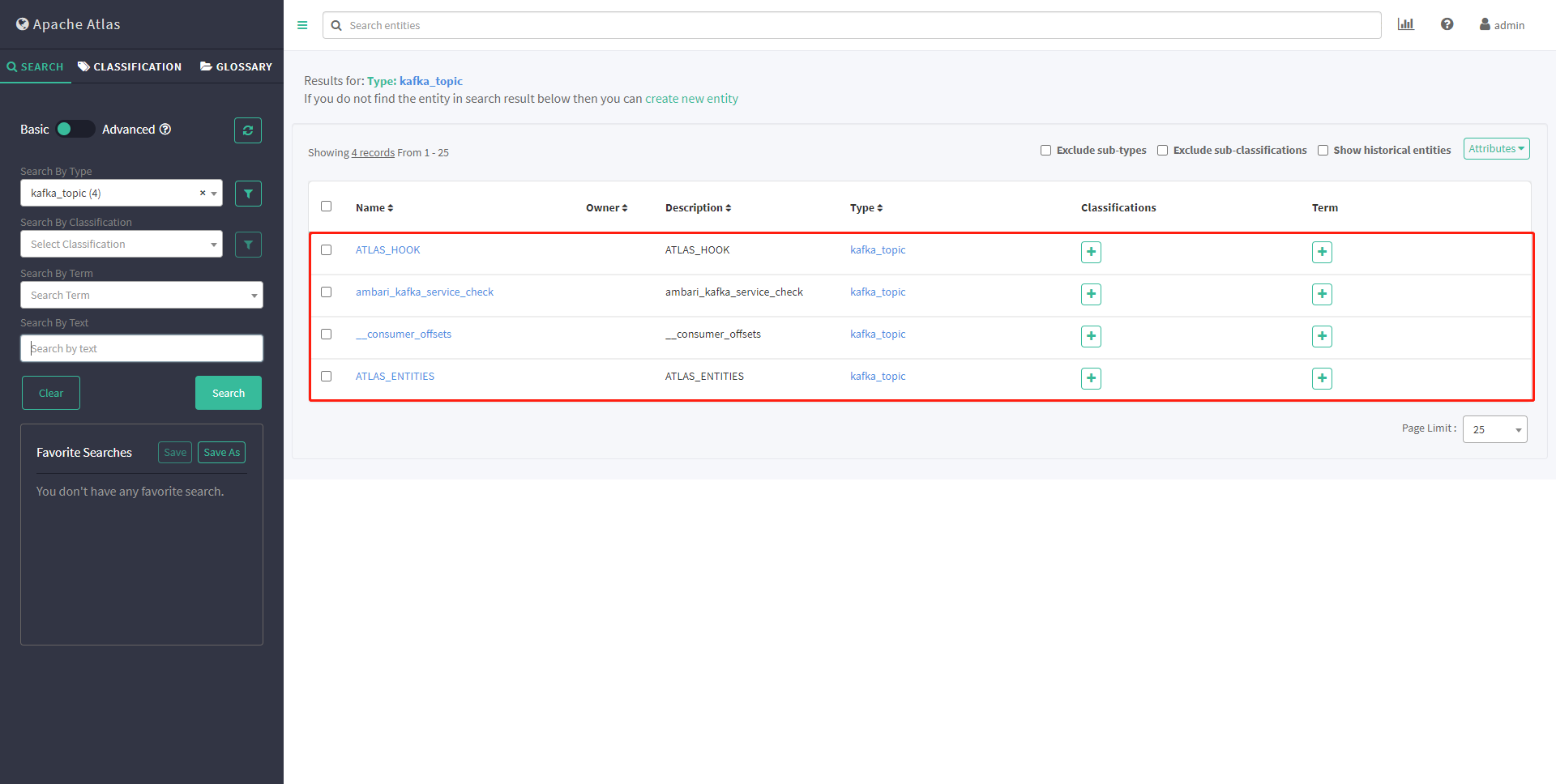
重新执行脚本 /usr/hdp/current/atlas-client/hook-bin/import-kafka.sh
查看元数据 出现了yntx topic
3.1.4 准时导入kafka元数据
通过《3.1.3 历史导入元数据》发现Atlas并不能实时获取Kafka元数据,但是只要Kafka的Topic出现变化,可以再次调用导入脚本即可,因此建议:
可以配置在DS配置一个定时任务专门按照一定周期执行/usr/hdp/current/atlas-client/hook-bin/import-kafka.sh即可。
👇🏻 关注公众号 获取更多资料👇🏻


- 点赞
- 收藏
- 关注作者
评论(0)