用 Python 构建内容聚合器

目录
在这个基于项目的教程中,您将使用 Python 和流行的框架Django从头开始构建一个内容聚合器。
由于每天都有大量内容在线发布,因此访问多个站点和来源以获取有关您最喜欢的主题的信息可能会非常耗时。这就是内容聚合器如此受欢迎和强大的原因,因为您可以使用它们在一个地方查看所有最新新闻和内容。
无论您是在寻找投资组合项目,还是在寻找将未来项目扩展到简单CRUD功能之外的方法,本教程都会为您提供帮助。
在本教程中,您将学习:
- 如何使用RSS 提要
- 如何创建Django自定义管理命令
- 如何按计划自动运行自定义命令
- 如何使用单元测试来测试 Django 应用程序的功能
单击下面的链接下载此项目的代码,并按照以下步骤构建自己的内容聚合器:
演示:您将构建的内容
您将在名为pyCasts 的Python 中构建您自己的播客内容聚合器!从头到尾遵循本教程。
该应用程序将是一个网页,显示来自The Real Python Podcast和Talk Python to Me Podcast的最新 Python Podcast 剧集。完成本教程后,您可以通过向应用程序添加更多播客提要来练习所学。
这是一个快速演示视频,展示了它的实际效果:
项目概况
为了能够向最终用户显示内容,您需要遵循以下几个步骤:
在本教程的过程中,您将逐步了解其中的每一个。现在,您将了解将在上述步骤中使用哪些技术和框架。
为了将播客 RSS 提要提取到您的应用程序中并对其进行解析,您将学习如何使用feedparser库。您将使用该库仅从提要中提取最新的剧集数据,您将把这些数据编组到Episode模型中并使用 Django ORM 保存到数据库中。
您可以将此代码添加到脚本中并定期手动运行它,但这会破坏使用聚合器来节省时间的意义。相反,您将学习如何使用称为自定义管理命令的内置 Django 工具。要解析和保存数据,您将在 Django 内部运行您的代码。
在django-apscheduler库的帮助下,您将为您的函数调用设置时间表,也称为作业。然后,您可以使用 Django 管理面板查看运行的作业和时间。这将确保在不需要管理员干预的情况下自动获取和解析您的提要。
然后,您将使用Django 模板引擎向用户显示查询的上下文 — 换句话说,最新的剧集。
先决条件
为了充分利用本教程,您应该熟悉以下概念和技术:
您可能还会发现有一些Bootstrap 4 的经验会很有帮助。
如果您在开始本教程之前没有掌握所有必备知识,那也没关系!事实上,您可以通过继续前进和刚刚开始来了解更多信息。如果遇到困难,您可以随时停下来查看上面链接的资源。
第 1 步:设置您的项目
在这一步结束时,您将设置环境、安装依赖项并完成 Django 的启动和运行。
首先创建您的项目目录,然后将目录更改为:
$ mkdir pycasts
$ cd pycasts
现在您位于项目目录中,您应该创建虚拟环境并激活它。使用任何让您最高兴的工具来执行此操作。此示例使用venv:
$ python3 -m venv .venv
$ source .venv/bin/activate
(.venv) $ python -m pip install --upgrade pip
现在您的环境已激活并pip升级,您需要安装所需的依赖项以完成项目。您可以requirements.txt在本教程的可下载源代码中找到一个文件:
打开source_code_setup/文件夹并安装固定的依赖项。请务必将 替换为<path_to_requirements.txt>下载文件的实际路径:
(.venv) $ python -m pip install -r <path_to_requirements.txt>
您现在应该已经安装了 Django、feedparser、django-apscheduler和它们的子依赖项。
现在您拥有启动和运行所需的所有工具,您可以设置 Django 并开始构建。要完成构建的这一步,您需要做以下四件事:
- 在当前工作目录中创建您的 Django 项目,
/pycasts - 创建一个
podcastsDjango 应用 - 运行初始迁移
- 创建超级用户
由于您已经熟悉 Django,因此您不会详细探索这些步骤中的每一个。您可以继续运行以下命令:
(.venv) $ django-admin startproject content_aggregator .
(.venv) $ python manage.py startapp podcasts
(.venv) $ python manage.py makemigrations && python manage.py migrate
(.venv) $ python manage.py createsuperuser
如果事实证明您确实需要更深入地了解这些终端命令中的任何一个,您可以查看Django 第 1 部分入门。
按照 Django 的提示完成创建超级用户帐户后,在测试应用程序是否正常工作之前,您还需要进行一项更改。尽管应用程序在没有它的情况下也能运行,但不要忘记将您的新podcasts应用程序添加到settings.py文件中:
# content_aggregator/settings.py
# ...
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
# My Apps
"podcasts.apps.PodcastsConfig",
]
您将您的新应用INSTALLED_APPS列为"podcasts.apps.PodcastsConfig".
注意:如果您对为什么使用 verbosepodcasts.apps.PodcastsConfig而不是感到好奇podcasts,那么您可以在官方 Django 文档中阅读有关配置应用程序的更多信息。
TLDR;版本是,虽然使用的应用程序名称,podcasts,应该工作的优良这个小应用程序,它被认为使用完整的最佳实践AppConfig的名称。
是时候尝试一下您的新 Django 项目了。启动 Django 服务器:
(.venv) $ python manage.py runserver
localhost:8000在浏览器中导航到,您应该会看到 Django 的默认成功页面:
现在您已经设置了您的项目并且您有 Django 工作,请继续下一步。
第 2 步:构建您的播客模型
此时,您应该已经设置了环境,安装了依赖项,并且 Django 已成功运行。在此步骤结束时,您将定义和测试播客剧集的模型并将模型迁移到数据库。
您的Episode模型不应仅反映您希望作为开发人员捕获的信息。它还应该反映用户希望看到的信息。跳入代码并立即开始编写模型很诱人,但这可能是一个错误。如果这样做,您可能很快就会忘记用户的观点。毕竟,应用程序是为用户设计的——甚至是像您或其他开发人员这样的用户。
在这一点上拿出笔和纸可能会很有用,但你应该做任何对你有用的事情。问问自己,“作为用户,我想做什么?” 并一遍又一遍地回答这个问题,直到你穷尽所有的想法。然后,您可以通过思考作为开发人员的愿望,问问自己缺少什么。
在编写数据库模型时,这可能是一个很好的策略,它可以避免您以后需要添加额外的字段和运行不必要的迁移。
注意:您的列表可能与下面的列表不同,这没关系。作为本教程的作者,我将分享我的想法,这就是您将在本项目的其余部分中使用的内容。
但是,如果您觉得缺少某个字段或属性,请随时扩展应用程序以在本教程末尾添加它。毕竟这是你的项目。让它成为你自己的!
从用户和开发人员的角度列出您的项目需求:
As a user, I would like to:
- Know the title of an episode
- Read a description of the episode
- Know when an episode was published
- Have a clickable URL so I can listen to the episode
- See an image of the podcast so I can scroll to look
for my favorite podcasts
- See the podcast name
As a developer, I would like to:
- Have a uniquely identifiable attribute for each episode
so I can avoid duplicating episodes in the database
您将在本教程的第 4 步中看到更多关于最后一点的内容。
根据您列出的要求Episode,您podcasts应用中的模型应如下所示:
# podcasts/models.py
from django.db import models
class Episode(models.Model):
title = models.CharField(max_length=200)
description = models.TextField()
pub_date = models.DateTimeField()
link = models.URLField()
image = models.URLField()
podcast_name = models.CharField(max_length=100)
guid = models.CharField(max_length=50)
def __str__(self) -> str:
return f"{self.podcast_name}: {self.title}"
Django 最强大的部分之一是内置的管理区域。将剧集存储在数据库中是一回事,但您还希望能够在管理区域与它们进行交互。您可以通过替换podcasts/admin.py文件中的代码来告诉 Django 管理员您想要显示您的剧集数据来做到这一点:
# podcasts/admin.py
from django.contrib import admin
from .models import Episode
@admin.register(Episode)
class EpisodeAdmin(admin.ModelAdmin):
list_display = ("podcast_name", "title", "pub_date")
在将模型迁移到数据库之前,您还需要做一件事。在 Django 3.2 中,您现在可以自定义自动创建的主键的类型。新的默认值与以前版本的 Django 中BigAutoField的Integer默认值相反。如果你现在运行迁移,你会看到这个错误:
(models.W042) Auto-created primary key used when not defining
a primary key type, by default 'django.db.models.AutoField'.
HINT: Configure the DEFAULT_AUTO_FIELD setting or the
PodcastsConfig.default_auto_field attribute to point to a subclass
of AutoField, e.g. 'django.db.models.BigAutoField'.
您可以通过向文件中的PodcastsConfig类添加额外的行来确保不会看到此错误app.py:
# podcasts/app.py
from django.apps import AppConfig
class PodcastsConfig(AppConfig):
default_auto_field = "django.db.models.AutoField"
name = "podcasts"
现在您的应用程序已配置为自动向所有模型添加主键。您还拥有数据应该是什么样子的图片,并将其表示在模型中。您现在可以运行Django 迁移以将您的Episode表包含在数据库中:
(.venv) $ python manage.py makemigrations
(.venv) $ python manage.py migrate
现在您已经迁移了更改,是时候测试它了!
本教程已经涵盖了很多内容,因此为简单起见,您将使用 Django 的内置测试框架进行单元测试。完成本教程中的项目后,如果您愿意,可以随意使用pytest或其他测试框架重写单元测试。
在您的podcasts/tests.py文件中,您可以添加:
# podcasts/tests.py
from django.test import TestCase
from django.utils import timezone
from .models import Episode
class PodCastsTests(TestCase):
def setUp(self):
self.episode = Episode.objects.create(
title="My Awesome Podcast Episode",
description="Look mom, I made it!",
pub_date=timezone.now(),
link="https://myawesomeshow.com",
image="https://image.myawesomeshow.com",
podcast_name="My Python Podcast",
guid="de194720-7b4c-49e2-a05f-432436d3fetr",
)
def test_episode_content(self):
self.assertEqual(self.episode.description, "Look mom, I made it!")
self.assertEqual(self.episode.link, "https://myawesomeshow.com")
self.assertEqual(
self.episode.guid, "de194720-7b4c-49e2-a05f-432436d3fetr"
)
def test_episode_str_representation(self):
self.assertEqual(
str(self.episode), "My Python Podcast: My Awesome Podcast Episode"
)
在上面的代码中,您使用.setUp()来定义一个示例Episode对象。
您现在可以测试一些Episode属性以确认模型按预期工作。从您的模型中测试字符串表示总是一个好主意,您在Episode.__str__(). 字符串表示是您在调试代码时将看到的内容,如果它准确地显示您希望看到的信息,将使调试更容易。
现在您可以运行您的测试:
(.venv) $ python manage.py test
如果您的测试成功运行,恭喜!您现在为内容聚合器打下了良好的基础,并且拥有了定义良好的数据模型。是时候进行第 3 步了。
第 3 步:创建您的主页视图
到现在为止,您应该有一个可运行的 Django 应用程序,其中包含您的Episode模型并通过了单元测试。在此步骤中,您将为主页构建 HTML 模板,添加所需的CSS 和资产,将主页添加到您的views.py文件中,并测试主页是否正确呈现。
注意:编写 HTML 和 CSS 超出了本教程的范围,因此您不会涉及这些的原因和方法。但是,如果您对 HTML 或 CSS 有任何不理解或有疑问,可以在评论中联系Real Python社区寻求见解。
在source_code_setup/您之前下载的文件夹中,您将找到一个名为static的文件夹和一个名为 的文件夹templates。您应该将这些文件夹复制到您的项目根文件夹pycasts/. 请务必将 替换为<source_code_setup_path>您在本地计算机上保存的实际路径,并且不要忘记将点 ( .) 复制到当前工作目录中:
(.venv) $ cp -r <source_code_setup_path>/static .
(.venv) $ cp -r <source_code_setup_path>/templates .
现在您的项目根目录中有 HTML 模板和静态文件的文件夹,是时候将所有内容连接起来,以便 Django 知道它们存在。
转到settings.py主content_aggregator应用程序中的文件。向下滚动直到到达该TEMPLATES部分,然后将templates/您之前创建的目录添加到DIRS列表中。本教程使用 Django 3,它pathlib用于文件路径:
# content_aggregator/settings.py
# ...
TEMPLATES = [
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
"DIRS": [
BASE_DIR / "templates",
],
"APP_DIRS": True,
"OPTIONS": {
"context_processors": [
"django.template.context_processors.debug",
"django.template.context_processors.request",
"django.contrib.auth.context_processors.auth",
"django.contrib.messages.context_processors.messages",
],
},
},
]
您还需要将该static/文件夹添加到您的设置中。您可以通过向下滚动到文件STATIC部分settings.py并包含新创建static/文件夹的路径来执行此操作:
# content_aggregator/settings.py
# ...
STATIC_URL = "/static/"
STATICFILES_DIRS = [
BASE_DIR / "static",
]
Django 现在知道您的静态资产和模板存在,但您还没有完成。为了完成到目前为止您已经完成的工作,您还有一些任务需要在列表中打勾:
- 创建一个主页视图中
views.py - 创建 URL路径
- 添加更多单元测试
您创建 URL 路径和主页视图的顺序并不重要。两者都需要完成才能使应用程序正常工作,但您可以从列表的顶部开始并首先创建您的视图类。
在您的podcasts应用程序中,打开您的views.py文件并将内容替换为以下代码:
1# podcasts/views.py
2
3from django.views.generic import ListView
4
5from .models import Episode
6
7class HomePageView(ListView):
8 template_name = "homepage.html"
9 model = Episode
10
11 def get_context_data(self, **kwargs):
12 context = super().get_context_data(**kwargs)
13 context["episodes"] = Episode.objects.filter().order_by("-pub_date")[:10]
14 return context
您可能熟悉 Django 中基于函数的视图,但 Django 也有内置的基于类的视图。这些非常方便,可以减少您需要编写的代码量。
在上面的代码片段中,您使用基于类的视图将播客剧集发送到主页:
- 第 7 行:您从
ListView类继承,以便您可以迭代剧集。默认情况下,它将迭代model = Episode第 9 行定义的所有剧集。 - 第 11 到 14 行:您覆盖
context数据并按最新的十集进行过滤,由发布日期确定pub_date。您想在此处进行过滤,因为否则可能会有数百(如果不是数千)剧集传递到主页。
现在是时候为您的主页提供一个 URL。您首先需要urls.py在您的podcasts应用程序中创建一个文件:
(.venv) $ touch podcasts/urls.py
现在您可以为HomePageView类添加路径:
# podcasts/urls.py
from django.urls import path
from .views import HomePageView
urlpatterns = [
path("", HomePageView.as_view(), name="homepage"),
]
在当前状态下,应用程序仍然不会显示您的主页,因为主content_aggregator应用程序不知道podcasts/urls.py. 两行代码应该可以解决这个问题。在您的content_aggregator/urls.py文件中,添加突出显示的代码以将两者连接在一起:
# podcasts/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path("", include("podcasts.urls")),
]
走到这一步做得很好!您现在应该能够启动您的应用程序并查看主页。和以前一样,启动您的应用程序python manage.py runserver并前往localhost:8000:

您可以看到主页有效,但没有内容。即使没有它,您仍然可以使用单元测试来测试内容是否能正确显示。
在步骤 2 中,您为模型创建了单元测试。您还创建了.setUp(),它创建了一个Episode要测试的对象。您可以使用相同的测试集数据来测试您的主页模板是否按预期工作。
除了测试主页是否正确呈现剧集之外,最好同时测试是否使用了正确的模板以及导航到其 URL 是否返回了有效的 HTTP 状态代码。
对于这样的单页应用程序,它可能看起来有点矫枉过正——而且可能确实如此。但是,随着任何应用程序的增长,您希望确保未来的更改不会破坏您的工作代码。此外,如果您将此项目用作作品集,那么您应该表明您了解最佳实践。
下面突出显示的代码是要添加到podcasts/tests.py文件中的新测试代码:
# podcasts/tests.py
from django.test import TestCase
from django.utils import timezone
from django.urls.base import reverse
from datetime import datetime
from .models import Episode
class PodCastsTests(TestCase):
def setUp(self):
self.episode = Episode.objects.create(
title="My Awesome Podcast Episode",
description="Look mom, I made it!",
pub_date=timezone.now(),
link="https://myawesomeshow.com",
image="https://image.myawesomeshow.com",
podcast_name="My Python Podcast",
guid="de194720-7b4c-49e2-a05f-432436d3fetr",
)
def test_episode_content(self):
self.assertEqual(self.episode.description, "Look mom, I made it!")
self.assertEqual(self.episode.link, "https://myawesomeshow.com")
self.assertEqual(
self.episode.guid, "de194720-7b4c-49e2-a05f-432436d3fetr"
)
def test_episode_str_representation(self):
self.assertEqual(
str(self.episode), "My Python Podcast: My Awesome Podcast Episode"
)
def test_home_page_status_code(self):
response = self.client.get("/")
self.assertEqual(response.status_code, 200)
def test_home_page_uses_correct_template(self):
response = self.client.get(reverse("homepage"))
self.assertTemplateUsed(response, "homepage.html")
def test_homepage_list_contents(self):
response = self.client.get(reverse("homepage"))
self.assertContains(response, "My Awesome Podcast Episode")
和以前一样,您可以使用python manage.py test. 如果此时您的所有测试都通过了,那么恭喜!
在这一步中,您成功创建了 HTML 模板和资产,构建了视图类,并连接了所有 URL 路由。您还编写了更多通过的单元测试。现在您已准备好进入下一步。
第 4 步:解析 Podcast RSS 提要
此时,您的应用程序应该看起来不错!您拥有开始添加内容所需的一切。到这一步结束时,您应该可以轻松地使用 feedparser 库来解析 RSS 提要并提取所需的数据。
在深入解析之前,RSS 提要究竟是什么?为什么要使用它来获取播客数据?
首先,所有播客都有一个RSS 提要。这是播客应用程序获取并向您显示播客数据和剧集的基本方式。您通常可以在播客网站上找到提要 URL 链接。
此外,播客 RSS 提要需要看起来都一样。这意味着当播客创建者将他们的提要提交到Apple Podcasts或Google Podcasts 等平台时,提要必须遵守RSS 2.0 规范。
此要求有两个方面的好处:
- 所有提要将具有相同的属性,因此您可以重复使用代码为任何给定的播客提取相同的数据,使您的代码更易于维护和更干。
- 每个剧集都必须有一个
guid分配给它,这使得该提要中的每个剧集都是独一无二的。
您要解析的第一个提要是The Real Python Podcast提要。在浏览器中导航到https://realpython.com/podcasts/rpp/feed以查看提要的外观。如果您觉得难以阅读,可以安装几个浏览器插件之一来美化它。一个示例 Chrome 插件是XML Tree,但还有许多其他插件可用。
要使用 feedparser 解析提要,您可以使用parse():
>>> import feedparser
>>> feed = feedparser.parse("https://realpython.com/podcasts/rpp/feed")
parse()获取提要并将其自动解析为可用的 Python 对象。然后,您可以使用标准点表示法访问提要标签,例如播客标题:
>>> podcast_title = feed.channel.title
>>> podcast_title
'The Real Python Podcast'
您还可以使用括号表示法访问标签内的属性:
>>> podcast_image = feed.channel.image["href"]
>>> podcast_image
'https://files.realpython.com/media/real-python-logo-square.28474fda9228.png'
在使用 feedparser 解析的提要中,您还可以访问称为.entries. 这允许迭代<item>提要中的每个元素。在您用播客剧集填充数据库后,您将能够使用.entries来检查guid提要上每个播客剧集的 ,并检查它是否存在于您的数据库中。
注意:暂时不要实现以下代码片段。只需阅读它。当您创建 Django 自定义命令并将其用于您的项目时,您将在下一步中编写类似的代码。现在,只需浏览一下这段代码,就可以了解如何使用 feedparser。
值得注意的是,您需要将来自 RSS 提要的发布日期转换为一个datetime对象,以便将其保存到数据库中。您将使用该dateutil库来执行此操作:
# Example
import feedparser
from dateutil import parser
from podcasts.models import Episode
feed = feedparser.parse("https://realpython.com/podcasts/rpp/feed")
podcast_title = feed.channel.title
podcast_image = feed.channel.image["href"]
for item in feed.entries:
if not Episode.objects.filter(guid=item.guid).exists():
episode = Episode(
title=item.title,
description=item.description,
pub_date=parser.parse(item.published),
link=item.link,
image=podcast_image,
podcast_name=podcast_title,
guid=item.guid,
)
episode.save()
您尚未将此代码放入文件的原因是您没有在 Django 中运行它的好方法。既然您已经掌握了如何使用 feedparser,那么您将探索如何使用自定义命令来运行您的解析函数。
第 5 步:创建 Django 自定义命令
在最后一步中,您学习了如何使用 feedparser,但没有以合理的方式运行与 Django ORM 交互的代码。在这一步中,您将介绍如何使用自定义命令在您的项目中执行脚本,以便您可以在 Django 服务器或生产服务器也在运行时与其进行交互。
自定义命令利用该manage.py文件来运行您的代码。当您运行 时manage.py,Django 将management/commands/目录中的任何模块注册为可用命令。
注意:如果您想深入研究,请前往官方 Django 文档以获取有关自定义管理命令的更多信息。
首先创建适当的目录和文件来存储您的命令:
(.venv) $ mkdir -p podcasts/management/commands
(.venv) $ touch podcasts/management/commands/startjobs.py
您几乎可以为该文件命名任何您喜欢的名称,但请注意,如果它以下划线开头,manage.py则不会注册它。稍后在步骤 7 中,您将使用 django-apscheduler将作业添加到此文件中,这就是您将文件命名为startjobs.py.
为了测试您的设置,您将创建一个打印"It works!"到终端的基本命令。
每个命令都应该有一个Command类。该类需要一个.handle()方法,您可以将其视为类的主要方法。该.handle()方法包含您要执行的代码:
# podcasts/management/commands/startjobs.py
from django.core.management.base import BaseCommand
class Command(BaseCommand):
def handle(self, *args, **options):
print("It works!")
现在从终端运行你的新命令:
(.venv) $ python manage.py startjobs
如果您看到It works!打印到终端,恭喜!您创建了第一个自定义命令。
现在是时候包含上一步中的 RSS 解析代码,看看是否可以向数据库中添加一些项目。继续并更新您的startjobs.py代码:
# podcasts/management/commands/startjobs.py
from django.core.management.base import BaseCommand
import feedparser
from dateutil import parser
from podcasts.models import Episode
class Command(BaseCommand):
def handle(self, *args, **options):
feed = feedparser.parse("https://realpython.com/podcasts/rpp/feed")
podcast_title = feed.channel.title
podcast_image = feed.channel.image["href"]
for item in feed.entries:
if not Episode.objects.filter(guid=item.guid).exists():
episode = Episode(
title=item.title,
description=item.description,
pub_date=parser.parse(item.published),
link=item.link,
image=podcast_image,
podcast_name=podcast_title,
guid=item.guid,
)
episode.save()
这一次,当您运行自定义命令时,屏幕上不会打印任何内容,但您现在应该在主页上显示来自 The Real Python Podcast 的 Podcast 剧集。继续尝试。
你得到了什么?如果你还没有导航到那里,现在去你的主页:

你有没有得到类似这张图片的东西?如果是这样,恭喜。有效。
既然您已经探索了如何使用自定义命令并设置并运行了第一个提要,您将在下一步中学习如何添加其他提要。
第 6 步:向 Python 内容聚合器添加其他提要
此时,您应该有一个可以工作的自定义命令来解析 The Real Python Podcast feed。在此步骤结束时,您将了解如何向自定义命令添加更多提要。
既然您有一个使用自定义命令成功解析的播客提要,您可能会想为每个提要一遍又一遍地重复相同的代码。但是,这不是好的编码习惯。您需要无需维护的 DRY 代码。
您可能认为您可以遍历一个提要 URL 列表并在每个项目上使用解析代码,通常,这可以工作。然而,由于 django-apscheduler 的工作方式,这不是一个可行的解决方案。下一步将详细介绍这一点。
相反,您需要重构您的代码,以便为您需要解析的每个提要提供一个解析函数和一个单独的函数。现在,您将分别调用这些方法。
注意:如本教程开头所述,您目前只关注两个提要。完成本教程并知道如何添加更多内容后,您可以通过选择更多要添加的 RSS 提要来深入研究并自行练习。
与此同时,来自Talk Python to Me播客的Michael Kennedy非常友好地授予在本教程中使用他的播客提要的许可。谢谢你,迈克尔!
现在,您将开始探索代码中的内容:
1# podcasts/management/commands/startjobs.py
2
3from django.core.management.base import BaseCommand
4
5import feedparser
6from dateutil import parser
7
8from podcasts.models import Episode
9
10def save_new_episodes(feed):
11 """Saves new episodes to the database.
12
13 Checks the episode GUID against the episodes currently stored in the
14 database. If not found, then a new `Episode` is added to the database.
15
16 Args:
17 feed: requires a feedparser object
18 """
19 podcast_title = feed.channel.title
20 podcast_image = feed.channel.image["href"]
21
22 for item in feed.entries:
23 if not Episode.objects.filter(guid=item.guid).exists():
24 episode = Episode(
25 title=item.title,
26 description=item.description,
27 pub_date=parser.parse(item.published),
28 link=item.link,
29 image=podcast_image,
30 podcast_name=podcast_title,
31 guid=item.guid,
32 )
33 episode.save()
34
35def fetch_realpython_episodes():
36 """Fetches new episodes from RSS for The Real Python Podcast."""
37 _feed = feedparser.parse("https://realpython.com/podcasts/rpp/feed")
38 save_new_episodes(_feed)
39
40def fetch_talkpython_episodes():
41 """Fetches new episodes from RSS for the Talk Python to Me Podcast."""
42 _feed = feedparser.parse("https://talkpython.fm/episodes/rss")
43 save_new_episodes(_feed)
44
45class Command(BaseCommand):
46 def handle(self, *args, **options):
47 fetch_realpython_episodes()
48 fetch_talkpython_episodes()
正如刚才所讨论的,您将解析代码与各个提要分开以使其可重用。对于您添加的每个额外提要,您需要添加一个新的顶级函数。在此示例中,您已分别使用fetch_realpython_episodes()和对 The Real Python Podcast 和 Talk Python to Me Podcast 完成此操作fetch_talkpython_episodes()。
现在您知道如何向应用程序添加额外的提要,您可以继续下一步,在那里您将了解如何自动运行自定义命令并定义运行它的计划。
第 7 步:调度任务 django-apscheduler
此时,您应该有两个或多个 RSS 提要排成一排,并准备好在每次运行新的自定义命令时进行解析。
在这最后一步中,您将:
- 设置django-apscheduler
- 为自定义命令添加时间表
- 将任务日志添加到您的应用程序
- 有机会在 Django 管理员中查看您的预定作业
django-apscheduler 包是 APScheduler 库的 Django 实现。
注意:有关 APScheduler 和您可以使用的所有可能设置的详细信息,请查看官方 APScheduler 文档。您还可以在项目的GitHub存储库上阅读有关 django-apscheduler 的更多信息。
您已经在虚拟环境中安装了 django-apscheduler。要将其安装到您的应用程序中,您还需要将其添加到INSTALLED_APPS您的settings.py文件中:
# content_aggregator/settings.py
# ...
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
# My Apps
"podcasts.apps.PodcastsConfig",
# Third Party Apps
"django_apscheduler",
]
要创建 django-apscheduler 模型,您需要运行数据库迁移命令:
(.venv) $ python manage.py migrate
此命令应用 django-apscheduler 正常工作所需的数据库迁移。
注意:不需要先运行makemigrations,因为 django-apscheduler 包包含它自己的迁移文件。
现在 django-apscheduler 已安装到您的应用程序中,您将简要了解它的工作原理。更详细的解释请查看官方文档。
您要在自定义命令中运行的每个任务都称为作业。您的应用程序中共有三个作业:一个用于您希望解析的每个播客提要,第三个用于从数据库中删除旧作业。
django-apscheduler 包将您的作业存储在数据库中,它还将存储所有成功和不成功的作业运行。拥有此历史记录对您作为开发人员或站点管理员来说非常有用,因为您可以监控任何任务是否失败。但是如果不定期从数据库中清除这些,您的数据库将很快填满,因此从数据库中清除旧历史记录是一种很好的做法。这也将按计划进行。
即使作业历史记录将存储在数据库中,如果发生任何错误,最好将它们记录下来以进行调试。您可以通过将此代码添加到您的应用程序来添加一些基本的日志记录设置settings.py:
# content_aggregator/settings.py
# ...
LOGGING = {
"version": 1,
"disable_existing_loggers": False,
"handlers": {
"console": {
"class": "logging.StreamHandler",
},
},
"root": {
"handlers": ["console"],
"level": "INFO",
},
}
现在您已经添加了日志记录设置,您需要在startjobs.py文件中实例化它。您现在将包含一些导入startjobs.py,稍后您将详细介绍这些导入。添加调度程序所需的日志记录和其他一些导入语句:
1# podcasts/management/commands/startjobs.py
2
3# Standard Library
4import logging
5
6# Django
7from django.conf import settings
8from django.core.management.base import BaseCommand
9
10# Third Party
11import feedparser
12from dateutil import parser
13from apscheduler.schedulers.blocking import BlockingScheduler
14from apscheduler.triggers.cron import CronTrigger
15from django_apscheduler.jobstores import DjangoJobStore
16from django_apscheduler.models import DjangoJobExecution
17
18# Models
19from podcasts.models import Episode
20
21logger = logging.getLogger(__name__)
这可能是一次添加的大量导入语句,所以让我们挑选出需要一些解释的类:
- 第 13 行:
BlockingScheduler是将运行您的作业的调度程序。它是阻塞的,所以它将是进程上唯一运行的东西。 - 第 14 行:
CronTrigger是您将用于调度的触发器类型。 - 第15行:
DjangoJobStore将决定如何将作业存储。在这种情况下,您希望它们在数据库中。 - 第 16 行:您将用于
DjangoJobExecution运行刚才提到的清理函数。
接下来,您需要使用所有导入语句并设置调度程序、触发器和作业存储。
您已经编写了三个工作职能中的两个,所以现在是添加第三个的时候了。在您的Command班级上方,添加您的工作职能:
# podcasts/management/commands/startjobs.py
# ...
def delete_old_job_executions(max_age=604_800):
"""Deletes all apscheduler job execution logs older than `max_age`."""
DjangoJobExecution.objects.delete_old_job_executions(max_age)
该max_age参数是表示为整数的秒数。请注意,604,800 秒等于 1 周。
下一步是在自定义命令的.handle()函数中创建您的作业存储和调度程序实例。您还可以在第一份工作中添加:
1# podcasts/management/commands/startjobs.py
2
3# ...
4
5def handle(self, *args, **options):
6 scheduler = BlockingScheduler(timezone=settings.TIME_ZONE)
7 scheduler.add_jobstore(DjangoJobStore(), "default")
8
9 scheduler.add_job(
10 fetch_realpython_episodes,
11 trigger="interval",
12 minutes=2,
13 id="The Real Python Podcast",
14 max_instances=1,
15 replace_existing=True,
16 )
17 logger.info("Added job: The Real Python Podcast.")
您将在上面看到您已成功创建scheduler实例并添加了作业存储。然后,您创建了您的第一份工作 — The Real Python Podcast。
该.add_job()方法需要一些参数才能成功创建作业:
- 第 10 行:第一个参数需要一个函数,因此您将
fetch_realpython_episodes之前创建的函数对象传递给它。请注意它在传递时如何没有调用括号。 - 第 11 和 12 行:您必须设置触发器。在本教程中,您将执行之间的间隔设置为两分钟。这只是为了让您可以测试并查看它是否适合自己。但是,绝对不应该在生产环境中频繁使用它。您还可以传递
seconds和hours作为参数,因此如果您在实时环境中托管此应用程序,您可以设置更现实的更新间隔。 - 第 13 行:所有作业都必须有一个 ID。Django 管理员也将使用该 ID,因此请选择一个可读且有意义的名称。
- 第15行:将
replace_existing现有的工作和防止重复,当你重新启动应用程序关键字参数内容替换。
您可以查看官方 APScheduler 文档以获取所有可接受参数的完整列表.add_job()。
现在,你有你的第一份工作计划,你可以继续前进,最后两个职位增加.handle(),并在电话中添加scheduler.start()和scheduler.shutdown()。哦,让我们也加入一些日志记录。
您的自定义命令类现在应如下所示:
# podcasts/management/commands/startjobs.py
# ...
class Command(BaseCommand):
help = "Runs apscheduler."
def handle(self, *args, **options):
scheduler = BlockingScheduler(timezone=settings.TIME_ZONE)
scheduler.add_jobstore(DjangoJobStore(), "default")
scheduler.add_job(
fetch_realpython_episodes,
trigger="interval",
minutes=2,
id="The Real Python Podcast",
max_instances=1,
replace_existing=True,
)
logger.info("Added job: The Real Python Podcast.")
scheduler.add_job(
fetch_talkpython_episodes,
trigger="interval",
minutes=2,
id="Talk Python Feed",
max_instances=1,
replace_existing=True,
)
logger.info("Added job: Talk Python Feed.")
scheduler.add_job(
delete_old_job_executions,
trigger=CronTrigger(
day_of_week="mon", hour="00", minute="00"
), # Midnight on Monday, before start of the next work week.
id="Delete Old Job Executions",
max_instances=1,
replace_existing=True,
)
logger.info("Added weekly job: Delete Old Job Executions.")
try:
logger.info("Starting scheduler...")
scheduler.start()
except KeyboardInterrupt:
logger.info("Stopping scheduler...")
scheduler.shutdown()
logger.info("Scheduler shut down successfully!")
您可能还记得之前的内容,该调度程序使用BlockingScheduler. 在一个终端中,您可以像以前一样使用python manage.py startjobs. 在单独的终端进程中,启动 Django 服务器。当您查看管理仪表板时,您现在会看到您的作业已注册,并且您可以查看历史记录:
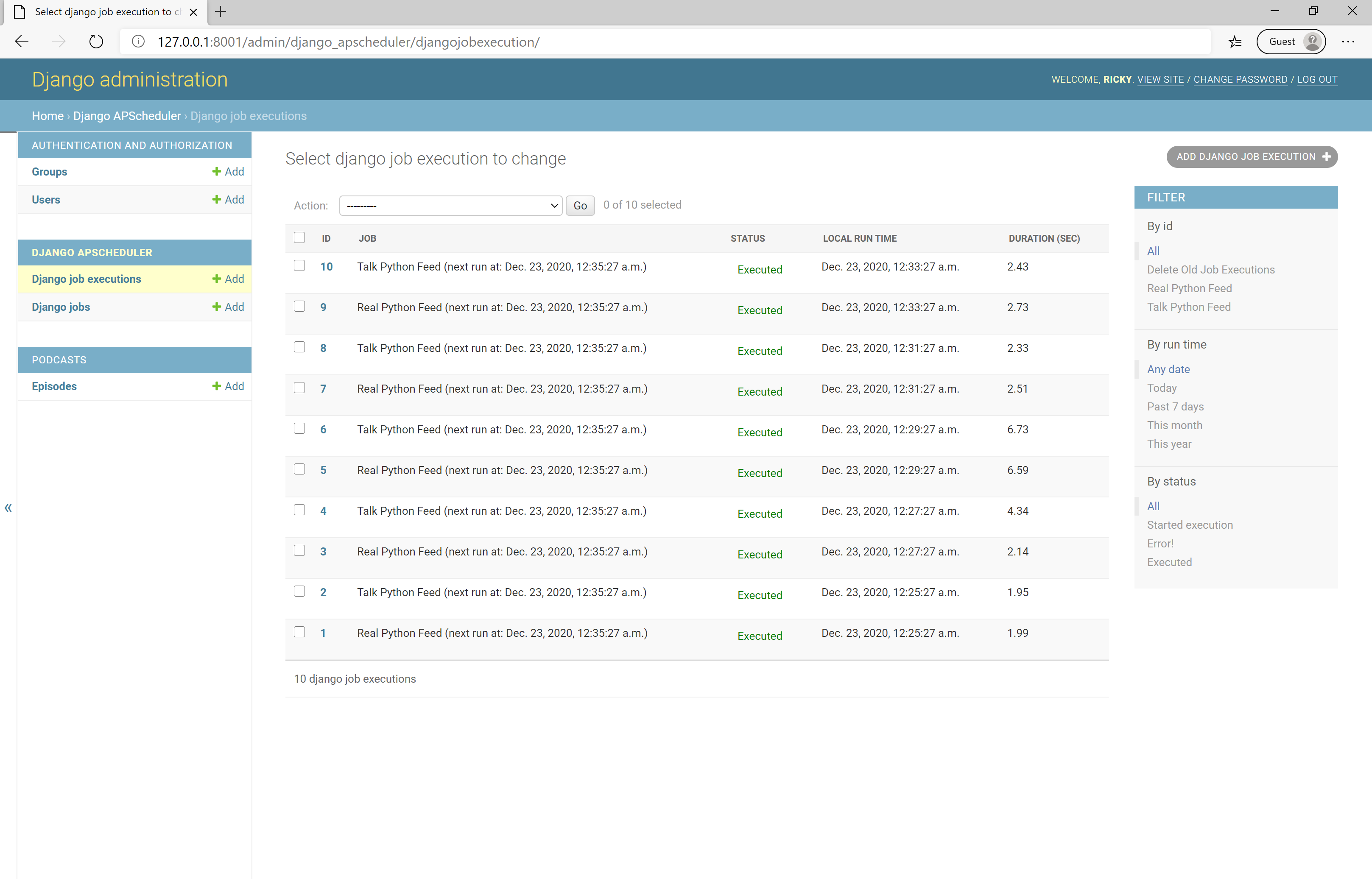
在这最后一步中发生了很多事情,但您已经完成了一个功能正常的应用程序!您已经成功地了解了如何使用 django-apscheduler 按照定义的时间表自动运行您的自定义命令。不小的壮举。做得好!
从头开始构建诸如内容聚合器之类的项目从来都不是一项快速或简单的任务,您应该为自己成功地做到这一点而感到自豪。做一些新的和推动你一点的事情只会帮助你成长为一名开发人员,无论你的资历有多高。
结论
您在这个基于项目的教程中涵盖了很多内容。很好!
在本教程中,您学习了:
- 如何使用 feedparser处理 RSS 提要
- 如何创建和使用自定义管理命令
- 如何使用 django-apscheduler 根据个性化计划自动执行自定义命令
- 如何向Django 应用程序添加基本单元测试
如果您还没有这样做,请单击下面的链接下载本教程的代码,以便您可以使用 Python 构建自己的内容聚合器:
下一步
您可以通过多种方式自定义和更改此应用程序,以表达自己作为开发人员的身份,尤其是当您计划将其用作作品集时。将这个项目提升到一个新的水平将帮助你在未来的工作申请中脱颖而出。
这里有一些想法可以将您的项目提升到一个新的水平:
- 添加更多提要!对数据科学感兴趣?查看数据科学播客的终极列表。
- 更改内容类型。如果播客不是你的东西,也许足球新闻是?或者,您可能更喜欢听金融播客?无论您有什么兴趣,都可以使用这个项目作为垫脚石,为您的激情之一创建聚合器。
- 添加用户帐户,以便用户可以订阅他们感兴趣的提要。然后在一天结束时,向他们发送一封电子邮件,其中包含他们订阅的新内容。查看有关Django 视图授权的教程以获得这方面的帮助。
is_published向Episode模型添加布尔标志,以便管理员可以手动策划和确认主页上显示的剧集。featured向Episode模型添加一个字段,以便您可以在主页上突出显示选定的播客。- 重新设计应用程序以使其成为您自己的应用程序。自定义 CSS 或删除 Bootstrap 4 以支持Tailwind CSS。世界是你的牡蛎。
- 将应用程序部署到生产环境——例如,通过在 Heroku 上托管您的 Django 应用程序。
- 自定义 Django 管理员并增强您的 Django 管理员体验。

- 点赞
- 收藏
- 关注作者
评论(0)