如何使用 Python 统计分析 access 日志?

一、前言
性能场景中的业务模型建立是性能测试工作中非常重要的一部分。而在我们真实的项目中,业务模型跟线上的业务模型不一样的情况实在是太多了。原因可能多种多样,这些原因大大降低了性能测试的价值。
今天的文章中,我想写的是最简单的逻辑。那就是从基于网关 access 日志统计分析转化到具体的场景中的通用业务模型。详细的介绍请参考《性能测试实战30讲》 中的 【14丨性能测试场景:如何理解业务模型?】
通用业务场景模型。就是将这一天的所有业务数加在一起,再将各业务整天的交易量加在一起,计算各业务量的比例。
二、前置工作
首先我们从高峰日取出一天的网关 access 日志,这里示例大概有 1400+ 万的记录
[root@k8s-worker-4 ~]# wc -l access.log
14106419 access.log
至于网关 access 日志如何配置,可以参看之前的文章 [SpringCloud 日志在压测中的二三事]
(https://zuozewei.blog.csdn.net/article/details/113973798)
我们得到的 access 日志内容一般如下:
10.100.79.126 - - [23/Feb/2021:13:52:14 +0800] "POST /mall-order/order/generateOrder HTTP/1.1" 500 133 8201 52 ms
对应的字段如下:
address, user, zonedDateTime, method, uri, protocol, status, contentLength, port, duration.
那么,我们的需求来了,如何通过分析 access 日志,获取每个接口网关处理时间最大值、最小值、平均值及访问量。
这里我扩展了获取每个接口网关处理时间的统计分析,方便我们接口的性能评估。
三、编写 Python 脚本完成数据分析
我们知道在数据分析、机器学习领域一般推荐使用到 Python,因为这是 Python 所擅长的。而在 Python 数据分析工作中,Pandas 的使用频率是很高的,如果我们日常的数据处理工作不是很复杂的话,你通常用几句 Pandas 代码就可以对数据进行规整。
那么这里我们只需要将日志中 duration 字段存放到 pandas 的基础数据结构 DataFrame 中,然后通过分组、数据统计功能就可以实现。
整个工程一共包括 4 个部分:
- 第一个部分为数据加载,首先我们通过 open 文件读数据加载到内存中。注意日志文件比较大的情况下读取不要用readlines()、readline(),会将日志全部读到内存,导致内存占满。因此在此使用
for line in fo迭代的方式,基本不占内存; - 第二步为数据预处理。读取日志文件,可以使用
pd.read_table(log_file, sep=’ ‘, iterator=True),但是此处我们设置的 sep 无法正常匹配分割,因此先将日志用 split 分割,然后再存入 pandas; - 第三步为数据分析,Pandas 提供了 IO 工具可以将大文件分块读取,使用不同分块大小来读取再调用
pandas.concat连接DataFrame,然后使用 Pandas 常用的统计函数分析; - 最后一步为数据装载,把统计分析结果保存到 Excel 文件中。
下载依赖库:
#pip3 install 包名 -i 源的url 临时换源
#清华大学源:https://pypi.tuna.tsinghua.edu.cn/simple/
# 强大的数据结构库,用于数据分析,时间序列和统计等
pip3 install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 处理 URL 的包
pip3 install urllib -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 安装生成execl表格的相关模块
pip3 install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple/
具体的代码如下:
#统计每个接口的处理时间
#请提前创建 log 并设置 logdir
import sys
import os
import pandas as pd
from urllib.parse import urlparse
import re
'''
全局参数
'''
mulu=os.path.dirname(__file__)
#日志文件存放路径
logdir="D:\log"
#存放统计所需的日志相关字段
logfile_format=os.path.join(mulu,"access.log")
print ("read from logfile \n")
'''
数据加载及预处理
'''
for eachfile in os.listdir(logdir):
logfile=os.path.join(logdir,eachfile)
with open(logfile, 'r') as fo:
for line in fo:
spline=line.split()
#过滤字段中异常部分
if spline[6]=="-":
pass
elif spline[6]=="GET":
pass
elif spline[-1]=="-":
pass
else:
#解析成url地址
parsed = urlparse(spline[6])
# print('path :', parsed.path)
#排除数值参数
interface = ''.join([i for i in parsed.path if not i.isdigit()])
# print(interface)
#重新写入文件
with open(logfile_format, 'a') as fw:
fw.write(interface)
fw.write('\t')
fw.write(spline[-2])
fw.write('\n')
print ("output panda")
'''
数据分析
'''
#将统计的字段读入到dataframe中
reader=pd.read_table(logfile_format,sep='\t',engine='python',names=["interface","duration(ms)"] ,header=None,iterator=True)
loop=True
chunksize=10000000
chunks=[]
while loop:
try:
chunk=reader.get_chunk(chunksize)
chunks.append(chunk)
except StopIteration:
loop=False
print ("Iteration is stopped.")
df=pd.concat(chunks)
#df=df.set_index("interface")
#df=df.drop(["GET","-"])
df_groupd=df.groupby('interface')
df_groupd_max=df_groupd.max()
df_groupd_min= df_groupd.min()
df_groupd_mean= df_groupd.mean()
df_groupd_size= df_groupd.size()
'''
数据装载
'''
df_ana=pd.concat([df_groupd_max,df_groupd_min,df_groupd_mean,df_groupd_size],axis=1,keys=["max","min","average","count"])
print ("output excel")
df_ana.to_excel("result.xls")
运行结果:
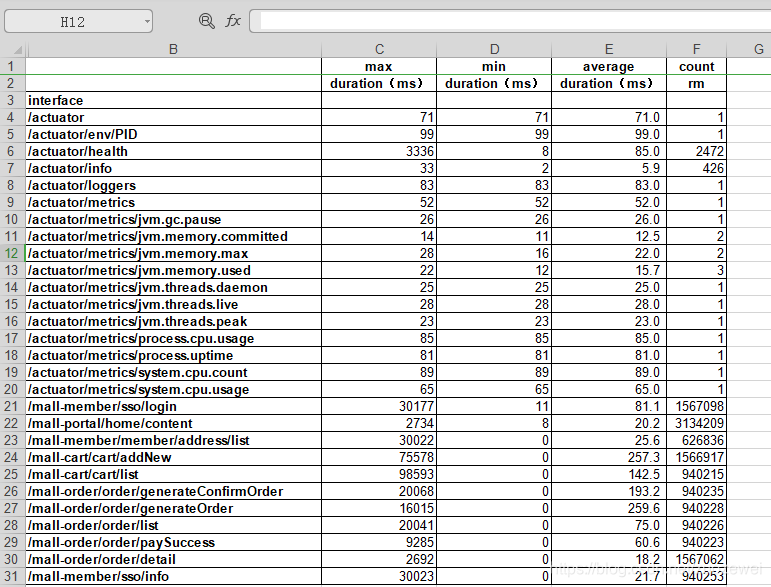
这样我们轻松得到了高峰日天各业务量统计以及接口处理时间等数据。
四、小结
通过今天的例子我们应该能看到采用 Python 对于性能工程师来说降低了数据分析的技术门槛。相信在当今的 DT 时代,任何岗位都需要用到数据分析的思维和能力。
本文源码:
参考资料:
- [1]:《性能测试实战30讲》

- 点赞
- 收藏
- 关注作者
评论(0)