【物联网】30.物联网数据分析的基础 - 机器学习

机器学习可以说是高级分析的典型代表。机器学习领域汇集了众多技术,这些技术用于让计算机基于大量数据来学习数据的倾向并作出某些判断。机器学习的算法可以根据输入的数据类型分为“监督学习”和“非监督学习”两种。
监督学习和非监督学习
当用机器学习的算法让计算机学习数据倾向时,算法会根据用于学习的数据中是否含有“正确答案”的数据而有所不同。打个比方,假设现在要从传感器数据来判断分析设备的故障情况和建筑物的损坏情况等异常状况。如果采用监督学习的算法,就需要输入过去实际发生异常状况时的数据,即需要明确地输入“异常”的数据。说白了,算法要学习“正确答案”和“不正确答案”之间存在的差异。
相对而言,非监督学习不区分输入的数据是否存在异常,也就是说,非监督学习算法会学习数据整体的倾向,在整体中找出倾向不同的数据,将其判断为“异常值”。
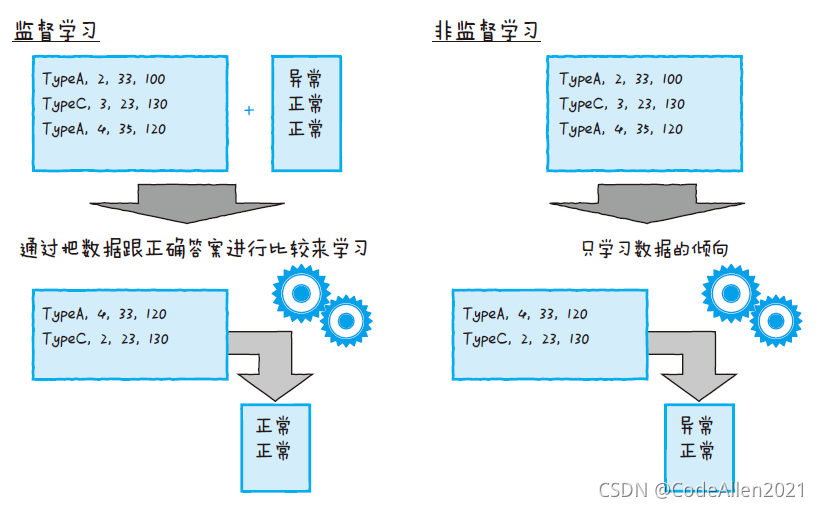
对于想要还原场景的情况,需要基于是否有当时的数据这一点来判断是采用监督学习还是非监督学习。特别是对于那些极少发生的异常情况,如果不能准备正确答案,就需要考虑采用非监督学习。另外,如果无法预测以后会发生什么异常状况,那么使用非监督学习来建立平常状态的模型,就能检测出和平常状态不同的状态(即异常)。
如果确定了想要发现的异常的种类,也采集到了足够的数据,那么采用监督学习会更加精确地检测出异常情况。
分析方法的种类
那么在理解了监督学习和非监督学习的基础上,接下来就以聚类和类别分类等为切入点来了解一下这些分析方法。根据其用法,分析方法可以分为几种。其中,图所示的3 种方法的使用频率特别高,接下来将详细讲解这3 种方法。
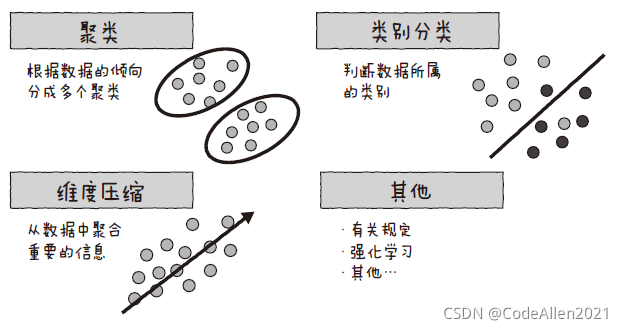
聚类分析
聚类分析,其目的是基于样本(样本数据)具有的特征,把相似的样本分成多个组(聚类)。具体的聚类算法包括K-means 算法、自组织映射、层次聚类等。这些方法能够根据数据的特征找到并整合具有同样特征的数据。
K-means 算法就是针对数据的分布来事先指定要把数据分成多少个块,即分成多少个聚类,由此来机械性地生成数据块的一种算法。
类别分类
类别分类分析的目的在于把数据分成两组或者更多组。虽然有人可能会感觉它跟聚类分析很相似,但类别分析用在已经明确想好了要分类的对象,基于过去的数据来分出对象组和非对象组的场合。类别分类算法包括线性判别式分析、决策树分析、支持向量机(SVM)等。特别是支持向量机还被用于图像识别算法,即识别某张图像上都拍摄了什么内容。
维度压缩
维度压缩也叫“维度约简”或“降维”,即对于大型数据中的大量数据,尽全力留下其中的重要信息并压缩冗余的信息,借此来缩小数据量的分析方法。维度压缩包括主成分分析、因子分析、多维尺度法等。很多时候设备发来的传感器信息太多,或是要分析从无数台设备发来的海量信息时,还会出现很多不需要的信息,即对于获取结果来说没有什么用的信息。此时,通过进行维度压缩,就能切去不需要的信息,把数据转化成一种更易于分析的形式。
文章来源: allen5g.blog.csdn.net,作者:CodeAllen2021,版权归原作者所有,如需转载,请联系作者。
原文链接:allen5g.blog.csdn.net/article/details/121298751

- 点赞
- 收藏
- 关注作者
评论(0)