AI黑科技,无人驾驶中都用到了哪些机器学习算法

前言
声明:以下是博主精心整理的机器学习和AI系列文章,博主后续会不断更新该领域的知识:
有需要的小伙伴赶紧订阅吧。
机器学习算法已经被广泛应用于自动驾驶各种解决方案,电控单元中的传感器数据处理大大提高了机器学习的利用率,也有一些潜在的应用,比如利用不同外部和内部的传感器的数据融合(如激光雷达、雷达、摄像头或物联网),评估驾驶员状况或为驾驶场景分类等。
将汽车内外传感器的数据进行融合,借此评估驾驶员情况、进行驾驶场景分类,都要用到机器学习。
自动驾驶中机器学习算法主要分为四类,即决策矩阵算法、聚类算法、模式识别算法和回归算法。我们一起来看看,这些算法都是怎样应用的。
算法概览
我们先设想这样一个自动驾驶场景——汽车的信息娱乐系统接收传感器数据融合系统的信息,如果系统发现司机身体有恙,会指导无人车开往附近的医院。
这项应用以机器学习为基础,能识别司机的语音、行为,进行语言翻译等。所有这些算法可以分为两类:监督学习和无监督学习,二者的区别在它们学习的方法。
监督学习算法利用训练数据集学习,并会坚持学到达到所要求的置信度(误差的最小概率)。监督学习算法可分为回归、分类和异常检测或维度缩减问题。
无监督学习算法会在可用数据中获取价值。这意味着算法能找到数据的内部联系、找到模式,或者根据数据间的相似程度将数据集划分出子集。无监督算法可以被粗略分类为关联规则学习和聚类。
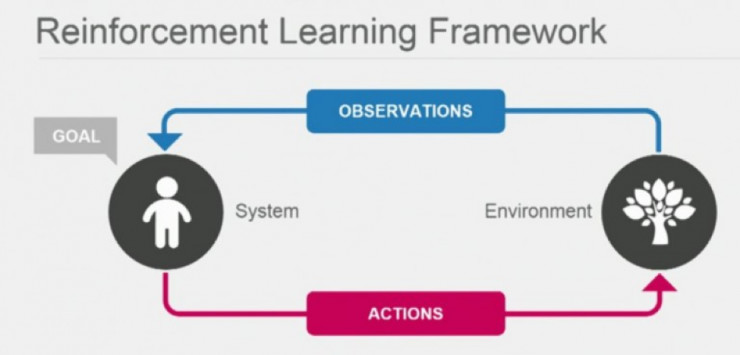
强化学习算法是另一类机器学习算法,这种学习方法介于监督学习和无监督学习之间。
监督学习会给每个训练样例目标标签,无监督学习从来不会设立标签——而强化学习就是它们的平衡点,它有时间延迟的稀疏标签——也就是未来的奖励。
每个 agent 会根据环境奖励学习自身行为。了解算法的优点和局限性,并开发高效的学习算法是强化学习的目标。
在自动驾驶汽车上,机器学习算法的主要任务之一是持续感应周围环境,并预测可能出现的变化。
我们不妨分成四个子任务:
-
检测对象
-
物体识别及分类
-
物体定位
-
运动预测
机器学习算法也可以被宽松地分为四类:
-
决策矩阵算法
-
聚类算法
-
模式识别算法
-
回归算法
机器学习算法和任务分类并不是一一对应的,比如说,回归算法既可以用于物体定位,也可以用于对象检测和运动预测。
决策矩阵算法
决策矩阵算法能系统分析、识别和评估一组信息集和值之间关系的表现,这些算法主要是用户决策。车辆的制动或转向是有依据的,它依赖算法对下一个运动的物体的识别、分类、预测的置信水平。
决策矩阵算法是由独立训练的各种决策模型组合起来的模型,某种程度上说,这些预测组合在一起构成整体的预测,同时降低决策的错误率。AdaBoosting 是最常用的算法。
AdaBoost
Adaptive Boosting 算法也简称为 AdaBoost,它是多种学习算法的结合,可应用于回归和分类问题。
与其他机器学习算法相比,它克服了过拟合问题,并且对异常值和噪声数据非常敏感。它需要经过多次迭代才能创造出强学习器,它具有自适应性。学习器将重点关注被分类错误的样本,最后再通过加权将弱学习器组合成强学习器。
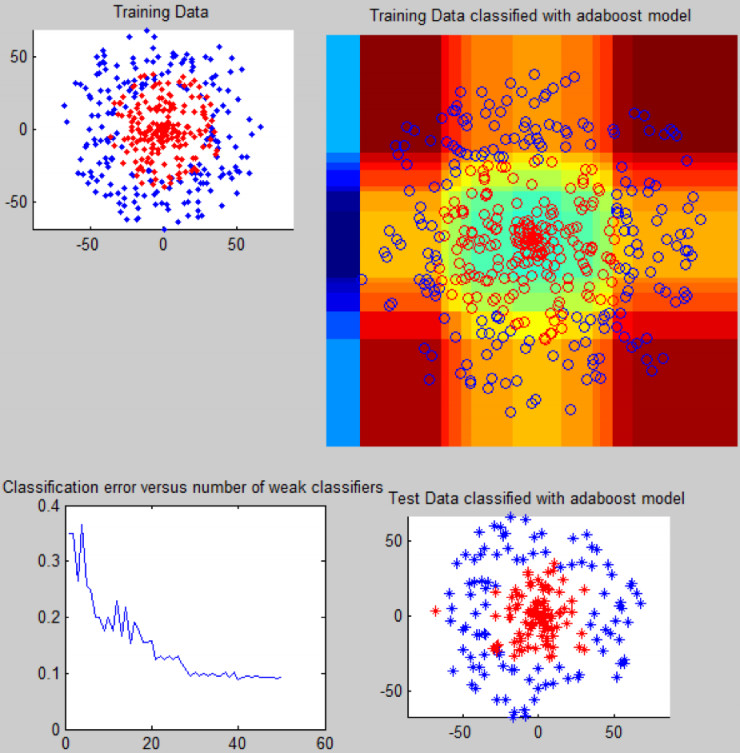
AdaBoost 帮助弱阈值分类器提升为强分类器。上面的图像描绘了如何在一个可以理解性代码的单个文件中实现 AdaBoost 算法。该函数包含一个弱分类器和 boosting 组件。
弱分类器尝试在数据维数中找到理想阈值,并将数据分为 2 类。分类器迭代时调用数据,并在每个分类步骤后,改变分类样本的权重。因此,它实际创建了级联的弱分类器,但性能像强分类器一样好。
聚类算法
有时,系统获取的图像不清楚,难以定位和检测对象,分类算法有可能丢失对象。在这种情况下,它们无法对问题分类并将其报告给系统。
造成这种现象可能的原因包括不连续数据、极少的数据点或低分辨率图像。K-means 是一种常见的聚类算法。
K-means
K-means 是著名的聚类算法,它从数据对象中选择任意 k 个对象作为初始聚类中心,再根据每个聚类对象的均值(中心对象)计算出每个对象与中心对象的距离,然后根据最小距离重新划分对象,最后重新计算调整后的聚类的均值。
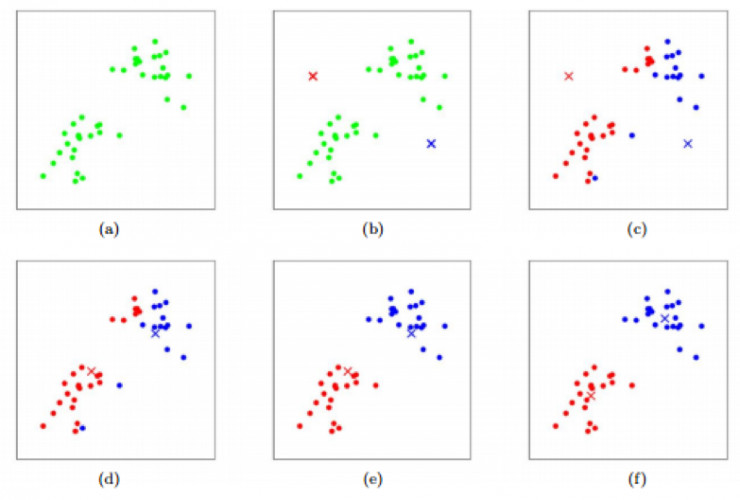
下图形象描述了 K-means 算法。其中:
-
(a)表示原始数据集。
-
-
(b)表示随机初始聚类中心。
-
-
(c-f)表示运行 2 次 k-means 迭代演示。
模式识别算法(分类)
通过高级驾驶辅助系统(ADAS)中的传感器获得的图像由各种环境数据组成,图像过滤可以用来决定物体分类样例,排除无关的数据点。在对物体分类前,模式识别是一项重要步骤,这种算法被定义为数据简化算法。数据简化算法可以减少数据集的边缘和折线(拟合线段)。
PCA(原理分量分析)和 HOG(定向梯度直方图),支持向量机(Support Vector Machines,SVM)是 ADAS 中常用的识别算法。我们也经常用到 K 最近邻(KNN,K-NearestNeighbor)分类算法和贝叶斯决策规则。
支持向量机(SVM)
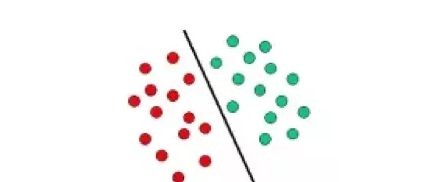
SVM 依赖于定义决策边界的决策层概念。决策平面分隔由不同的类成员组成的对象集。下面是一个示意图,在这里,物体要么属于红色类要么绿色类,分隔线将彼此分隔开。落在左边的新物体会被标记为红色,落在右边就被标记为绿色。
回归算法
这种算法的专长是预测事件,回归分析会对两个或更多变量之间的关联性进行评估,并对不同规模上的变量效果进行对照。
回归算法通常由三种度量标准驱动:
-
回归线的形状
-
因变量的类型
-
因变量的数量
在无人车的驱动和定位方面,图像在 ADAS 系统中扮演着关键角色。对于任何算法来说,最大的挑战都是如何开发一种用于进行特征选取和预测的、基于图像的模型。
回归算法利用环境的可重复性来创造一个概率模型,这个模型揭示了图像中给定物体位置与该图像本身间的关系。
通过图形采样,此概率模型能够提供迅速的在线检测,同时也可以在线下进行学习。模型还可以在不需要大量人类建模的前提下被进一步扩展到其他物体上。
算法会将某一物体的位置以一种在线状态下的输出和一种对物体存在的信任而返回。回归算法同样可以被应用到短期预测和长期学习中,在自动驾驶上,则尤其多用于决策森林回归、神经网络回归以及贝叶斯回归。
回归神经网络
神经网络可以被用在回归、分类或非监督学习上。它们将未标记的数据分组并归类,或者监督训练后预测连续值。神经网络的最后一层通常通过逻辑回归将连续值变为变量 0 或 1。
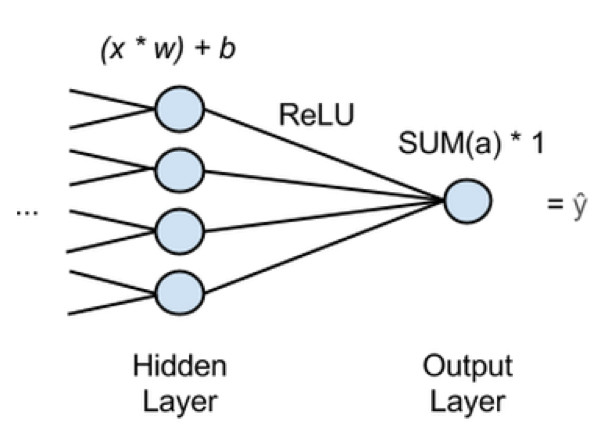
在上面的图表中,x 代表输入,特征从网络中的前一层传递到下一层。许多 x 将输入到最后一个隐藏层的每个节点,并且每一个 x 将乘以相关权重 w。
乘积之和将被移动到一个激活函数中,在实际应用中我们经常用到 ReLu 激活函数。它不像 Sigmoid 函数那样在处理浅层梯度问题时容易饱和。
文章来源: wenyusuran.blog.csdn.net,作者:文宇肃然,版权归原作者所有,如需转载,请联系作者。
原文链接:wenyusuran.blog.csdn.net/article/details/113938930

- 点赞
- 收藏
- 关注作者
评论(0)