How Self-Attention with Relative Position Representations works

本文的主要内容是基于相对位置表示的自注意力机制是如何工作的。
1. 引论
本篇文章是基于 Self-Attention with Relative Position Representations(https://arxiv.org/pdf/1803.02155.pdf),它提出了一种对Transformer的输入序列中的位置编码的替代方法。它改变了Transformer的自注意力机制,从而可以考虑序列元素之间的相对位置。
2. 动机
RNN的结构是通过隐状态对序列信息进行编码的。
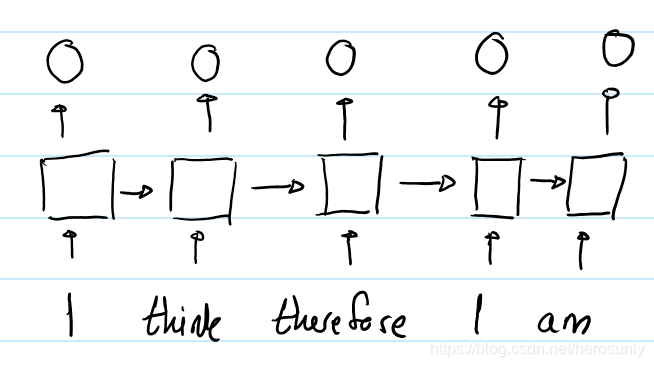
In contrast, the self-attention layer of a Transformer (without any positional representation) causes identical words at different positions to have the same output representation. For example:
第二个 I I I的输出和第一个 I I I的输出是不同的,这是因为输入到其中的隐状态是不同的。对于第二个 I I I来说,隐状态经过了单词"I think therefore",而第一个 I I I是刚刚经过初始化的。因此,RNN的隐状态会使得处于不同位置的相同词具有不同的输出表示。恰恰相反的是,具有自注意力机制的Transformer(没有位置编码的)会使得不同位置的相同词具有相同的输出表示。
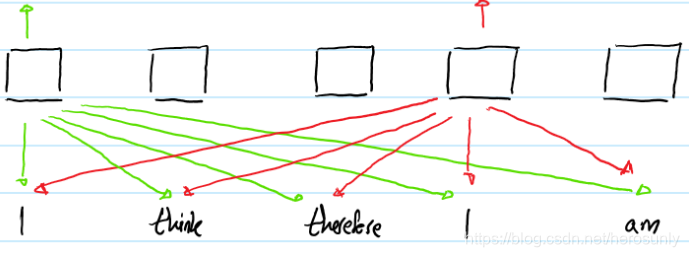
上图表示的是输入序列为"I think therefore I am",然后传送到Transformer的的结果。出于可读性的原因,只显示了输入对应的输出“ I I I”表示(以不同的颜色)。尽管两个" I I I"位于序列不同的位置,
文章来源: blog.csdn.net,作者:herosunly,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/herosunly/article/details/90231220

- 点赞
- 收藏
- 关注作者
评论(0)