【2020东京奥运会】 数据分析及可视化

写在前面
首先要声明一点标题没写错哦!是【2020东京奥运会】,应该看过直播的人都知道,至于原因可以自行百度哈,今天给我女朋友看了一下文章,她竟然直接说我标题写错了,哈哈,所以感觉在这有必要解释一下~
8月8日,小日…呃…子过得挺好的日本选手的国家 举办的东京奥运会已经结束了。在奥运期间,主办方种种 奇葩操作 直接把我看傻,最终它们也通过独特的“手段” 挤入了前三名,在这里首先谢谢他们刷新了我对奥运的认知。同时,借此机会看看我国今年奥运会的获奖情况,话不多说进入正文。

数据获取
奥运会相关数据来自以下两个接口。
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/detail-total/15/110000004609
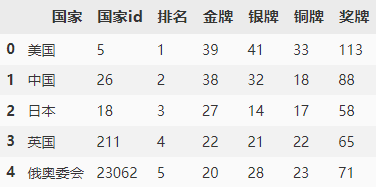
:one: 下面通过第一个接口,解析获取我们所需的数据,主要包含国家的排名与奖牌数。
打开链接之后,可以发现主要信息都在 allMedalData 字段内。

在网页中确认需要提取的内容,然后通过对应的 key 进行提取。
import requests
import pandas as pd
data_url = 'https://app-sc.miguvideo.com/vms-livedata/olympic\
-medal/total-table/15/110000004609'
# 请求数据
data = requests.get(data_url).json()
df = pd.DataFrame()
for item in data['body']['allMedalData']:
df = df.append([[item['countryName'],
item['countryId'],
item['rank'],
item['goldMedalNum'],
item['silverMedalNum'],
item['bronzeMedalNum'],
item['totalMedalNum']]])
# 修改列名
df.columns = ['国家', '国家id', '排名', '金牌', '银牌', '铜牌', '奖牌']
# 重置索引
df.reset_index(drop=True, inplace=True)
df.head()
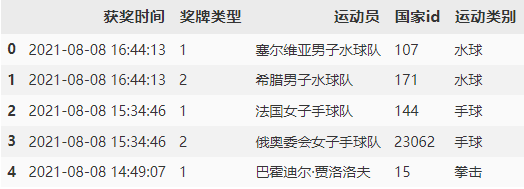
:two: 第二个链接同样如此。
data_url = 'https://app-sc.miguvideo.com/\
vms-livedata/olympic-medal/detail-total/15/110000004609'
data = requests.get(data_url).json()
detail_df = pd.DataFrame()
# 请求数据
for item in data['body']['medalTableDetail']:
detail_df = detail_df.append([[item['awardTime'],
item['medalType'],
item['sportsName'],
item['countryId'],
item['bigItemName']]])
# 修改列名
detail_df.columns = ['获奖时间', '奖牌类型', '运动员', '国家id', '运动类别']
# 重置索引
detail_df.reset_index(drop=True, inplace=True)
detail_df.head()
数据预处理
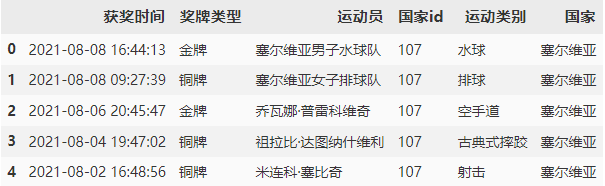
第二个接口获取的数据中没有国家名称,需要参照第一个接口的数据按照 “国家id” 列进行匹配。修改 “奖牌类型”,将“1,2,3” 修改为 “金牌,银牌,铜牌”。
detail_df.loc[detail_df['奖牌类型'] == 1, '奖牌类型'] = '金牌'
detail_df.loc[detail_df['奖牌类型'] == 2, '奖牌类型'] = '银牌'
detail_df.loc[detail_df['奖牌类型'] == 3, '奖牌类型'] = '铜牌'
courtry_df = df.loc[:, ['国家', '国家id']]
detail_df = pd.merge(detail_df, courtry_df, on='国家id', how = "inner")
detail_df.head()
数据整理完毕可以将数据保存到本地,方便可视化。
df.to_csv('东京奥运会国家排名.csv', index=False)
detail_df.to_csv('东京奥运会获奖详情.csv', index=False)
数据可视化
各地区奖牌数量分布
先看一下各地区奖牌数量分布,颜色越深奖牌数(总数)越多。得奖多的地区也侧面反映了国家的实力。

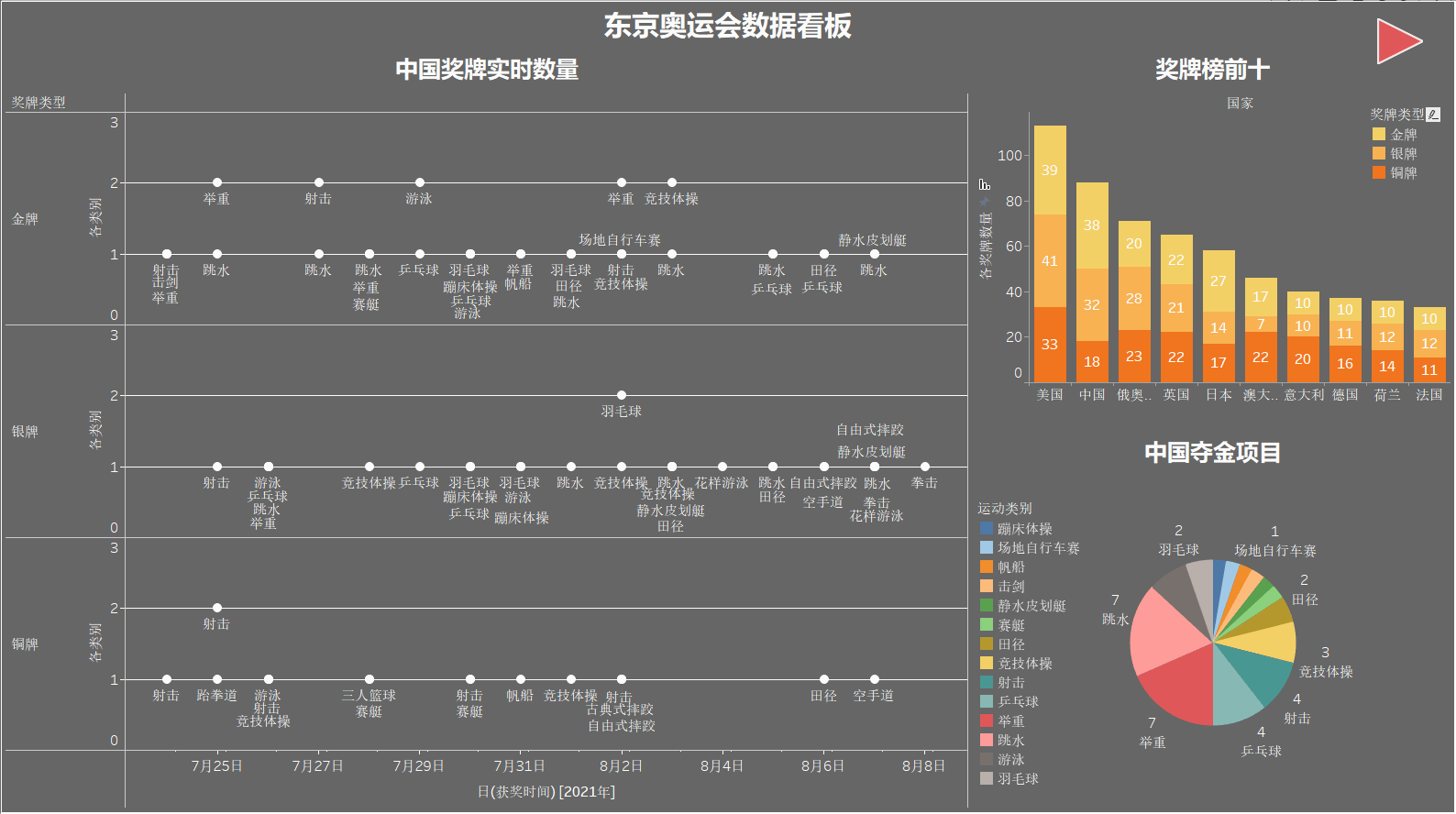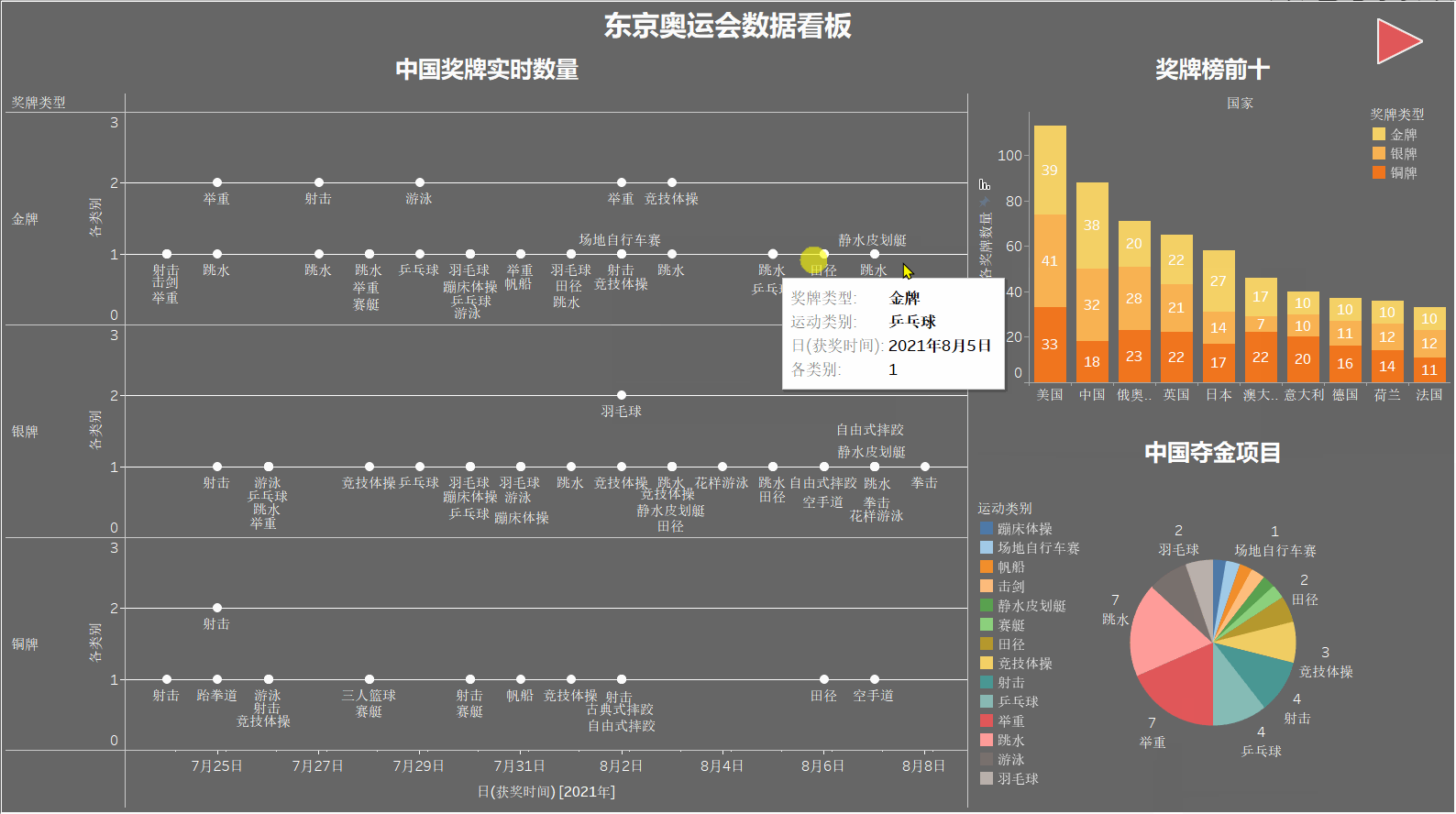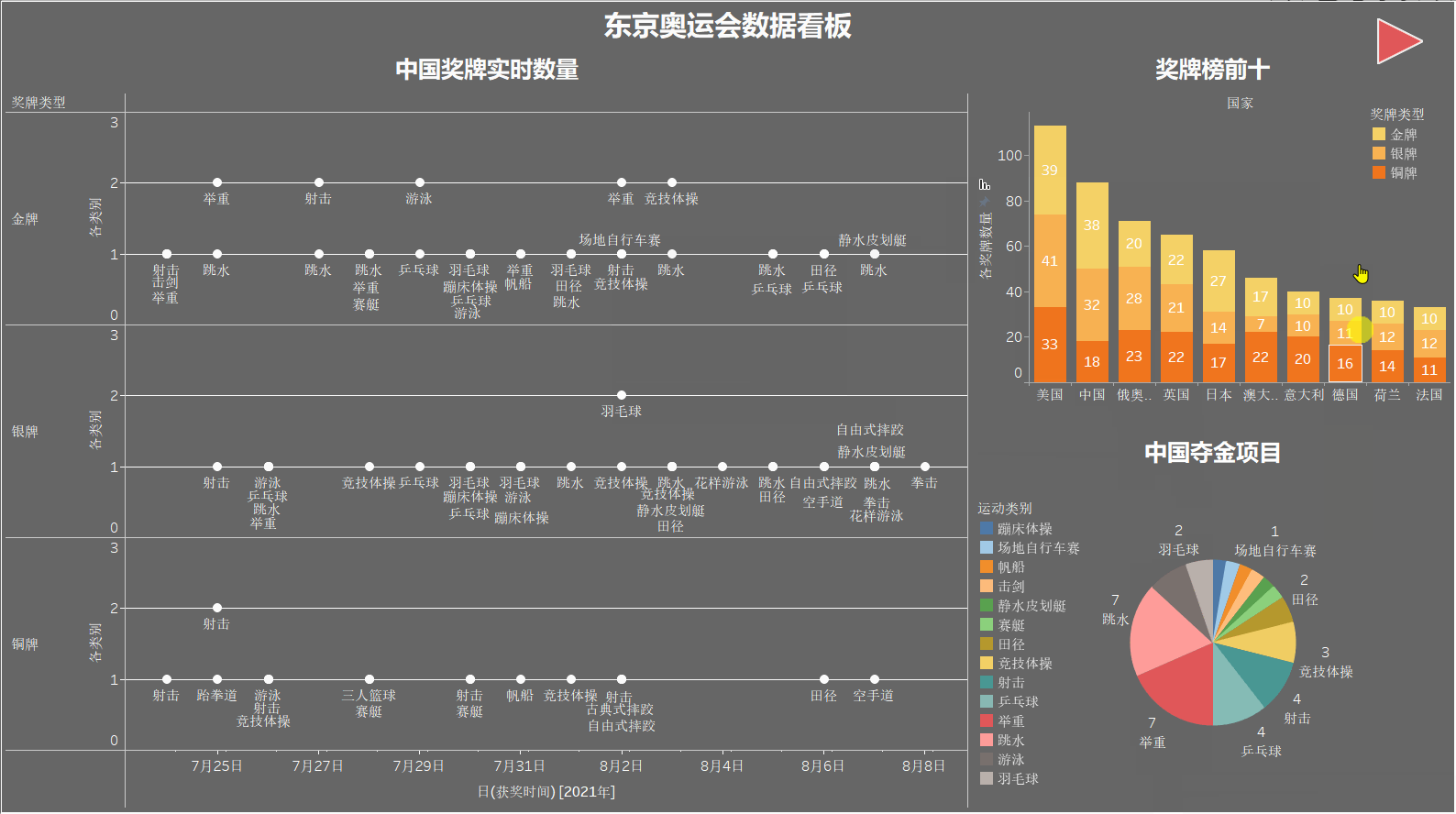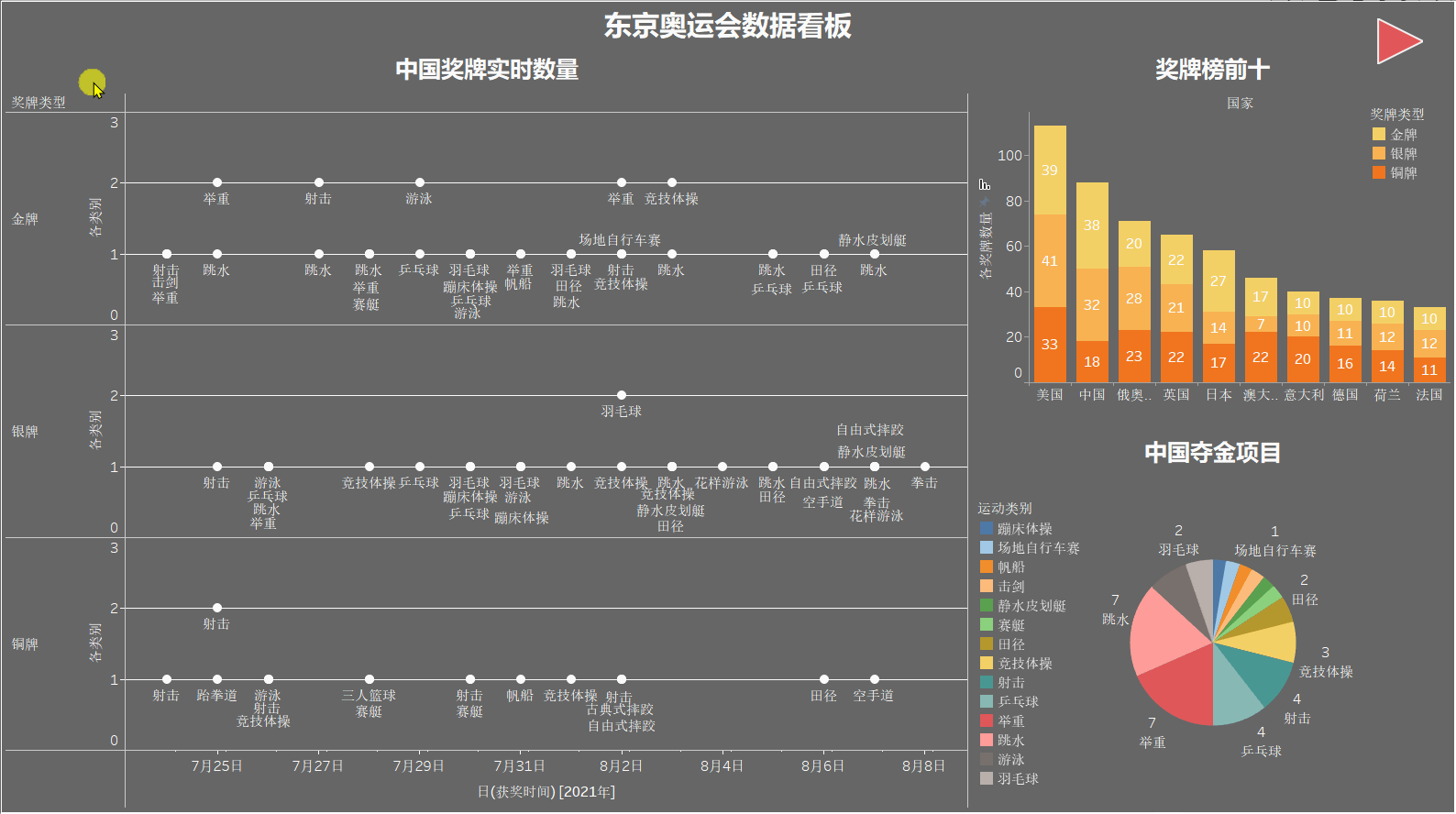
奖牌榜前十
制作堆叠条形图,展示奖牌榜前十名,每个柱子从上到下依次为金牌、银牌、铜牌的数量,图例没在边上没截进去,见谅~

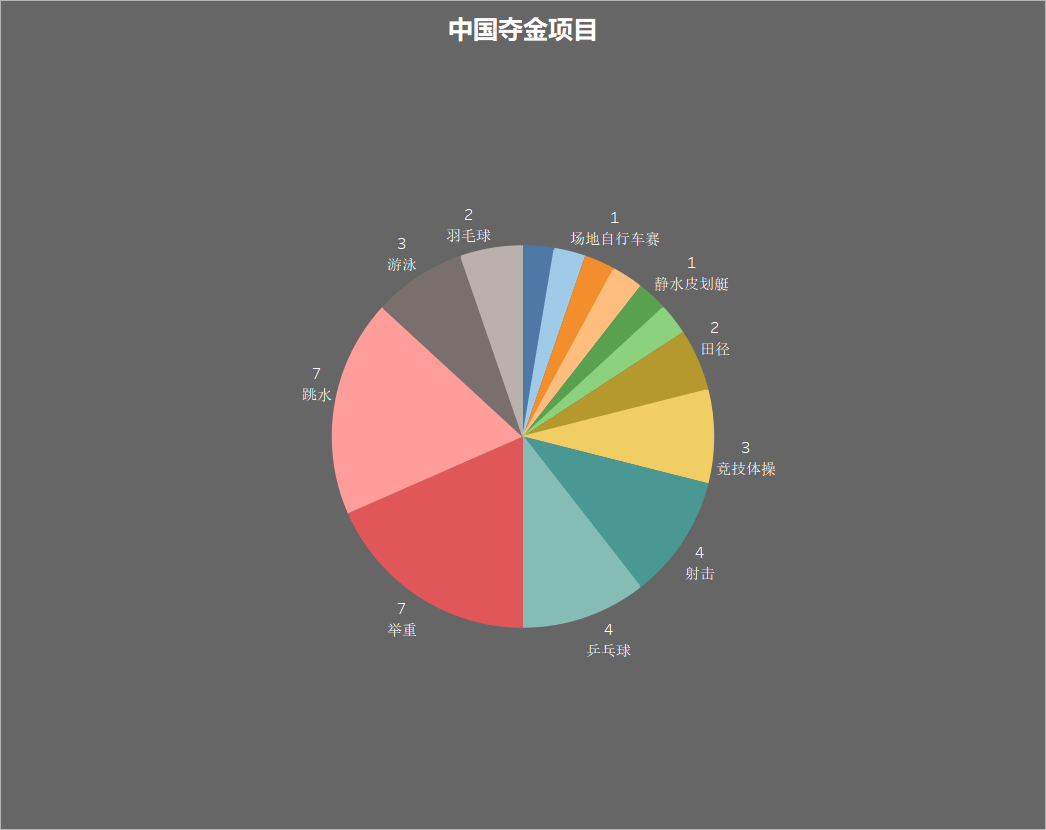
中国夺金项目分类
使用饼图来显示我国夺金的项目分类,像 举重、跳水、乒乓球 一直都是我们的夺金热门项目。
中国奖牌实时数量
该图展示我国每日金银铜获取的实时情况,可以清晰地看出每天各个项目的获奖情况。

合成看板
将上面制作的图标合成在一个仪表盘中,提高观赏性~

由于地图太大,就在两个看板中添加了跳转按钮,以此实现看板跳转。效果如下。
总结
在此次奥运会中,我国代表队在大部分项目都有出色的表现,传统优势项目也保持了优势地位。举重共8个小项目获得 7金1银 ,跳水8个小项目获得 7金5银 ,均取得历史最好成绩。在整体上来看我国夺金项目覆盖面宽,除优势项目外,还获取 蹦床体操、场地自行车赛、帆船、击剑、净水皮划艇、赛艇、田径、羽毛球 等项目的金牌。
由于数据量不多,不能够较全面的分析整个比赛,这发表一下自己的看法,同时在这里期待下届奥运会我国运动健儿的表现~
这就是本文所有的内容了,如果感觉还不错的话。❤ 点个赞再走吧!!!❤
后续会继续分享《Python数据分析及可视化》方面文章,如果感兴趣的话可以点个关注不迷路哦~。

源码可以通过可以通微信搜 Python新视野,回复“东京奥运会”直接获取。对于刚入门 Python 或是想要入门 Python 的小伙伴,也可以通过上述方式一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。

- 点赞
- 收藏
- 关注作者
评论(0)