条件编译命令分析:#error 和 #line,#pragma,# 和 ## 操作符使用

知识来源主要是陈正冲老师的《C语言深度解剖》及Delphi Tang老师的《C语言剖析》,有兴趣的朋友可以看我置顶文章获取
#error 和 #line 使用分析
#error 用于生成一个编译错误消息
用法:
#error message (message不需要使用双引号)
#error 编译指示字用于自定义程序特有编译错误消息
类似的,#warning用于生成编译警告
#error 是一种预编译器指示字
#error 可以用于提示编译条件是否满足

实验1:#error预处理实验
-
#include <stdio.h>
-
-
#ifndef __cplusplus
-
#error This file should be processed with C++ compiler.
-
#endif
-
-
class CppClass
-
{
-
private:
-
int m_value;
-
public:
-
CppClass()
-
{
-
-
}
-
-
~CppClass()
-
{
-
}
-
};
-
-
int main()
-
{
-
return 0;
-
}
实验2:#error在条件编译中的应用
-
#include <stdio.h>
-
-
void f()
-
{
-
#if ( PRODUCT == 1 )
-
printf("This is a low level product!\n");
-
#elif ( PRODUCT == 2 )
-
printf("This is a middle level product!\n");
-
#elif ( PRODUCT == 3 )
-
printf("This is a high level product!\n");
-
#endif
-
}
-
-
int main()
-
{
-
f();
-
-
printf("1. Query Information.\n");
-
printf("2. Record Information.\n");
-
printf("3. Delete Information.\n");
-
-
#if ( PRODUCT == 1 )
-
printf("4. Exit.\n");
-
#elif ( PRODUCT == 2 )
-
printf("4. High Level Query.\n");
-
printf("5. Exit.\n");
-
#elif ( PRODUCT == 3 )
-
printf("4. High Level Query.\n");
-
printf("5. Mannul Service.\n");
-
printf("6. Exit.\n");
-
#endif
-
-
return 0;
-
}
#line的使用
#line用于强制指定新的行号和编译文件名,并对源文件程序的代码重新编译
用法:
#line number filename
#line 编译指示字的本质是重定义_LINE_ 和_FILE_
实验3:#line的使用
-
#include <stdio.h>
-
-
// The code section is written by A.
-
// Begin
-
#line 1 "a.c"
-
-
// End
-
-
// The code section is written by B.
-
// Begin
-
#line 1 "b.c"
-
-
// End
-
-
// The code section is written by Delphi.
-
// Begin
-
#line 1 "delphi_tang.c"
-
-
-
int main()
-
{
-
printf("%s : %d\n", __FILE__, __LINE__);
-
-
printf("%s : %d\n", __FILE__, __LINE__);
-
-
return 0;
-
}
-
-
// End
小结:

#pragma 含义:
- #pragma用于指示编译器完成一些特定的动作
- #pragma所定义的很多指示字是有编译器特有的
- #pragma在不同的编译器间是不可以移植的
- 预处理器将忽略它不认识的#pragma指令
- 不同的编译器可能以不同的方式解释同一条#pragma指令
一般用法:#pragma parameter (不同的parameter参数语法和意义各不相同)
#pragma message
- message 参数在大多数编译器中都有类似的实现
- message参数在编译时输出消息到编译输出窗口中
- message 用于条件编译中可提示代码的版本信息
-
-
#if defined(ANDROID20)
-
#pragma message("Compile Android SDK 2.0 ...")
-
#define VERSION "Android 2.0"
-
#endif
-
-
与#error 和#warning 不同,#pragma message 仅仅代表一条编译信息,不代表程序错误
-
实验1 #pragma message使用分析
-
#include <stdio.h>
-
-
#if defined(ANDROID20)
-
#pragma message("Compile Android SDK 2.0...")
-
#define VERSION "Android 2.0"
-
#elif defined(ANDROID23)
-
#pragma message("Compile Android SDK 2.3...")
-
#define VERSION "Android 2.3"
-
#elif defined(ANDROID40)
-
#pragma message("Compile Android SDK 4.0...")
-
#define VERSION "Android 4.0"
-
#else
-
#error Compile Version is not provided!
-
#endif
-
-
int main()
-
{
-
printf("%s\n", VERSION);
-
-
return 0;
-
}
-
#pragma once
-
-
int g_value = 1;
#pragma once
- #pragma once用于保证头文件只被编译一次
- #pragma once是编译器相关的,不一定被编译
实验2:#pragma once使用
-
#include <stdio.h>
-
#include "global.h"
-
#include "global.h"
-
-
int main()
-
{
-
printf("g_value = %d\n", g_value);
-
-
return 0;
-
}
#pragma pack
内存对齐:不同类型的数据在内存中按照一定的规则排列 ,而不一定是顺序的一个个的排序
举个例子:

在内存中存储方式如图:
为什么 需要内存对齐?
- CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是1,2,4,8,16 。。。字节
- 当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
- 某些硬件平台只能从规定的相对地址处读取特定类型的数据,否则则产生硬件异常
#pragma pack 用于指定内存对齐方式
#pragma pack 能够改变编译器的默认对齐方式

struct占用的内存大小
- 第一个 成员起始于0偏移处
- 每个成员按其类型大小和pack参数中较小的一个进行对齐
- 偏移地址必须能被对齐参数整除
- 结构体成员的带下取其内部长度最大的数据成员作为其大小
- 结构退总长度必须为所有对齐参数的整数倍
编辑器在默认状态下按照4字节对齐
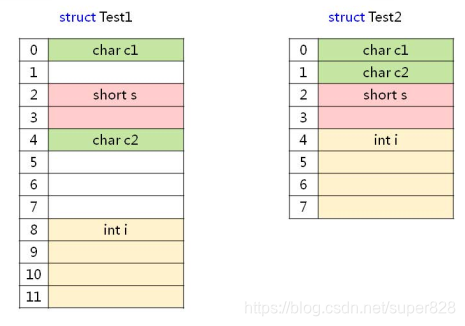
实验3:结构体大小计算
-
#include <stdio.h>
-
-
#pragma pack(2)
-
struct Test1
-
{
-
char c1;
-
short s;
-
char c2;
-
int i;
-
};
-
#pragma pack()
-
-
#pragma pack(4)
-
struct Test2
-
{
-
char c1;
-
char c2;
-
short s;
-
int i;
-
};
-
#pragma pack()
-
-
int main()
-
{
-
printf("sizeof(Test1) = %d\n", sizeof(struct Test1));
-
printf("sizeof(Test2) = %d\n", sizeof(struct Test2));
-
-
return 0;
-
}
实验4:
-
#include <stdio.h>
-
-
#pragma pack(8)
-
-
struct S1
-
{
-
short a;
-
long b;
-
};
-
-
struct S2
-
{
-
char c;
-
struct S1 d;
-
double e;
-
};
-
-
#pragma pack()
-
-
int main()
-
{
-
printf("%d\n", sizeof(struct S1));
-
printf("%d\n", sizeof(struct S2));
-
-
return 0;
-
}
小结:

# 和 ## 操作符使用
#运算符用于预处理期将宏参数转换为字符串
#的转换作用是在预处理期完成的,因此只在宏定义中有效
编译器不知道#的转换作用
用法:
-
#define STRING(x) #x
-
-
printf("%s\n",STRING(Hello World!));
实验1:#运算符的基本用法
-
#include <stdio.h>
-
-
#define STRING(x) #x
-
-
int main()
-
{
-
-
printf("%s\n", STRING(Hello world!));
-
printf("%s\n", STRING(100));
-
printf("%s\n", STRING(while));
-
printf("%s\n", STRING(return));
-
-
return 0;
-
}
实验2:#运算符的妙用
-
#include <stdio.h>
-
-
#define CALL(f, p) (printf("Call function %s\n", #f), f(p))
-
-
int square(int n)
-
{
-
return n * n;
-
}
-
-
int func(int x)
-
{
-
return x;
-
}
-
-
int main()
-
{
-
int result = 0;
-
-
result = CALL(square, 4);
-
-
printf("result = %d\n", result);
-
-
result = CALL(func, 10);
-
-
printf("result = %d\n", result);
-
-
return 0;
-
}
##运算符用于在预处理期粘连两个标识符
##的连接作用是字预处理期完成的,因此只在宏定义中有效
编译器不知道##的连接作用
用法:
-
#define CONNECT(a,b) a##b
-
int CONNECT(a,1); //int a1;
-
a1 = 2;
实例3:##运算符的基本用法
-
#include <stdio.h>
-
-
#define NAME(n) name##n
-
-
int main()
-
{
-
-
int NAME(1);
-
int NAME(2);
-
-
NAME(1) = 1;
-
NAME(2) = 2;
-
-
printf("%d\n", NAME(1));
-
printf("%d\n", NAME(2));
-
-
return 0;
-
}
实例4:##运算符的工程应用
-
#include <stdio.h>
-
-
#define STRUCT(type) typedef struct _tag_##type type;\
-
struct _tag_##type
-
-
STRUCT(Student)
-
{
-
char* name;
-
int id;
-
};
-
-
int main()
-
{
-
-
Student s1;
-
Student s2;
-
-
s1.name = "s1";
-
s1.id = 0;
-
-
s2.name = "s2";
-
s2.id = 1;
-
-
printf("s1.name = %s\n", s1.name);
-
printf("s1.id = %d\n", s1.id);
-
printf("s2.name = %s\n", s2.name);
-
printf("s2.id = %d\n", s2.id);
-
-
return 0;
-
}
小结:

文章来源: allen5g.blog.csdn.net,作者:CodeAllen的博客,版权归原作者所有,如需转载,请联系作者。
原文链接:allen5g.blog.csdn.net/article/details/89064814

- 点赞
- 收藏
- 关注作者
评论(0)