【Oracle数据库】手滑删错数据,一步步教你如何挽救?

【摘要】 @TOC 前言常在河边走,哪能不湿鞋?今天有客户联系说误更新数据表,导致数据错乱了,希望将这张表恢复到 一周前 的指定时间点。数据库版本为 11.2.0.1操作系统是 Windows64数据已经被更改超过1周时间数据库已开启归档模式没有DG容灾有RMAN备份 一、分析以下只列出常规恢复手段:数据已经误操作超过一周,所以排除使用UNDO快照来找回。没有DG容灾环境,排除使用DG闪回。主库已开启...
@TOC
前言
常在河边走,哪能不湿鞋?
今天有客户联系说误更新数据表,导致数据错乱了,希望将这张表恢复到 一周前 的指定时间点。
- 数据库版本为 11.2.0.1
- 操作系统是 Windows64
- 数据已经被更改超过1周时间
- 数据库已开启归档模式
- 没有DG容灾
- 有RMAN备份
一、分析
- 以下只列出常规恢复手段:
- 数据已经误操作超过一周,所以排除使用UNDO快照来找回。
- 没有DG容灾环境,排除使用DG闪回。
- 主库已开启归档模式,并且存在RMAN备份,可使用RMAN异机恢复表对应表空间,使用DBLINK捞回数据表。
- Oracle 12C后支持单张表恢复。
结论:安全起见,使用RMAN异机恢复表空间来捞回数据表。
二、思路
- 客户希望将表数据恢复到 <2021/06/08 17:00:00> 之前某个时间点。
大致操作步骤如下:
- 主库查询误更新数据表对应的表空间和无需恢复的表空间。
- 新主机安装Oracle 11.2.0.1数据库软件,无需建库,目录结构最好保持一致。
- 主库拷贝参数文件,密码文件至新主机,根据新主机修改参数文件和创建新实例所需目录。
- 新主机使用修改后的参数文件打开数据库实例到nomount状态。
- 主库拷贝备份的控制文件至新主机,新主机使用RMAN恢复控制文件,并且MOUNT新实例。
- 新主机RESTORE TABLESPACE恢复至时间点 <2021/06/08 16:00:00>。
- 新主机RECOVER DATABASE SKIP TABLESPACE恢复至时间点 <2021/06/08 16:00:00>。
- 新主机实例开启到只读模式。
- 确认新主机实例的表数据是否正确,若不正确则重复 第7步 调整时间点慢慢往 <2021/06/08 17:00:00> 推进恢复。
- 主库创建连通新主机实例的DBLINK,通过DBLINK从新主机实例捞取表数据。
注意:选择表空间恢复是因为主库数据量比较大,如果全库恢复需要大量时间。
三、测试环境模拟
- 为了数据脱敏,因此以测试环境模拟场景进行演示。
1 环境准备
| 节点 | 主机版本 | 主机名 | 实例名 | Oracle版本 | IP地址 |
|---|---|---|---|---|---|
| 主库 | rhel6.9 | orcl | orcl | 11.2.0.1 | 10.211.55.111 |
| 新主机 | rhel6.9 | orcl | 不创建实例 | 11.2.0.1 | 10.211.55.112 |
- 环境部署可以通过Oracle一键安装脚本 进行初始化环境,然后手动安装即可。
- 主库:
./OracleShellInstall.sh -i 10.211.55.111 -m Y- 新主机:
./OracleShellInstall.sh -i 10.211.55.112 -m Y
2、模拟测试场景
- 主库开启归档模式
--设置归档路径
alter system set log_archive_dest_1='LOCATION=/archivelog';
--重启开启归档模式
shutdown immediate
startup mount
alter database archivelog;
--打开数据库
alter database open;
- 创建测试数据
sqlplus / as sysdba
--创建表空间
create tablespace lucifer datafile '/oradata/orcl/lucifer01.dbf' size 10M autoextend off;
create tablespace ltest datafile '/oradata/orcl/ltest01.dbf' size 10M autoextend off;
--创建用户
create user lucifer identified by lucifer;
grant dba to lucifer;
--创建表
conn lucifer/lucifer
create table lucifer(id number not null,name varchar2(20)) tablespace lucifer;
--插入数据
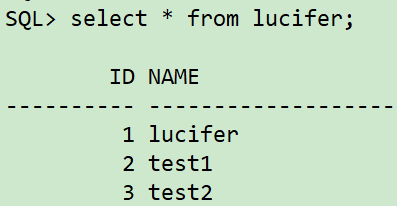
insert into lucifer values(1,'lucifer');
insert into lucifer values(2,'test1');
insert into lucifer values(3,'test2');
commit;
- 进行数据库全备
run {
allocate channel c1 device type disk;
allocate channel c2 device type disk;
crosscheck backup;
crosscheck archivelog all;
sql"alter system switch logfile";
delete noprompt expired backup;
delete noprompt obsolete device type disk;
backup database include current controlfile format '/backup/backlv0_%d_%T_%t_%s_%p';
backup archivelog all DELETE INPUT;
release channel c1;
release channel c2;
}
- 模拟数据修改
sqlplus / as sysdba
conn lucifer/lucifer
delete from lucifer where id=1;
update lucifer set name='lucifer' where id=2;
commit;
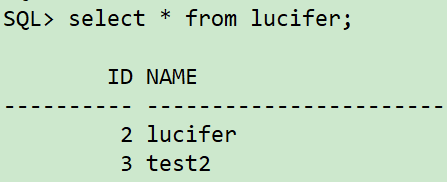
注意:为了模拟客户环境,假设无法通过UNDO快照找回,当前删除时间点为:<2021/06/17 18:10:00>。
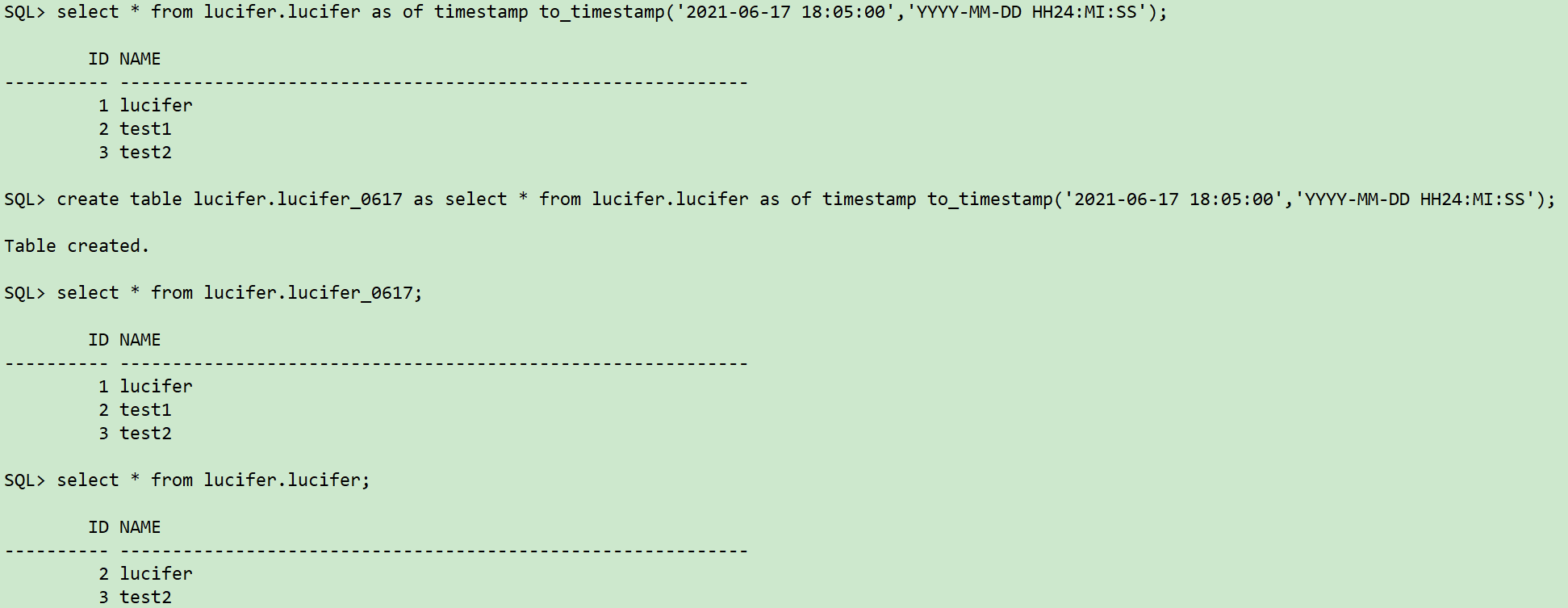
- 如果使用UNDO快照,比较方便:
--查找UNDO快照数据是否正确
select * from lucifer.lucifer as of timestamp to_timestamp('2021-06-17 18:05:00','YYYY-MM-DD HH24:MI:SS');
--将UNDO快照数据捞至新建表中
create table lucifer.lucifer_0617 as select * from lucifer.lucifer as of timestamp to_timestamp('2021-06-17 18:05:00','YYYY-MM-DD HH24:MI:SS');
四、RMAN完整恢复过程
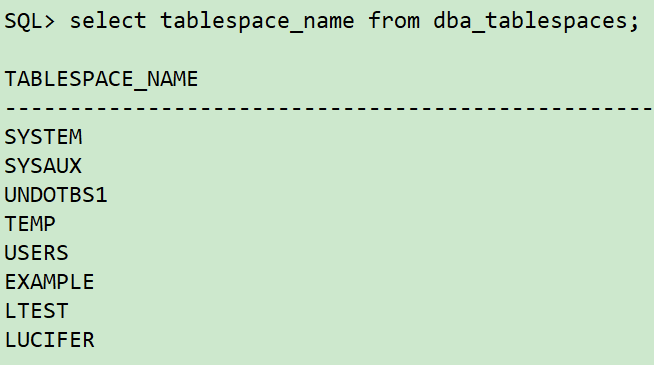
1 主库查询误更新数据表对应的表空间和无需恢复的表空间
--查询误更新数据表对应表空间
select owner,tablespace_name from dba_segments where segment_name='LUCIFER';
--查询所有表空间
select tablespace_name from dba_tablespaces;

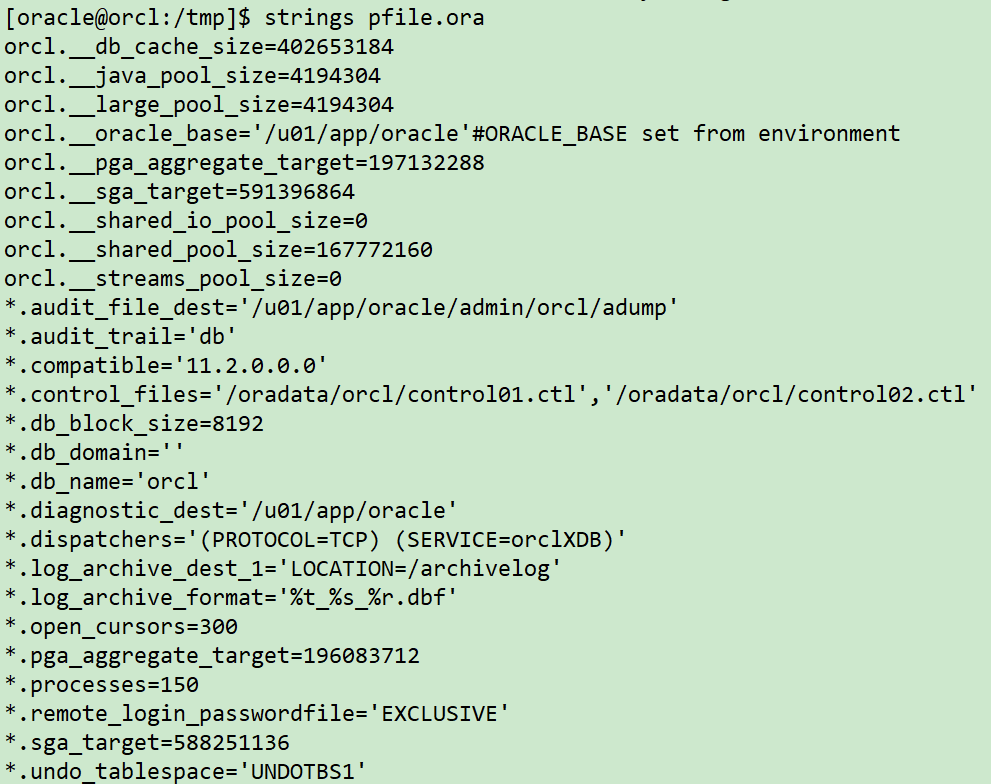
2 主库拷贝参数文件,密码文件至新主机,根据新主机修改参数文件和创建新实例所需目录
##生成pfile参数文件
sqlplus / as sysdba
create pfile='/home/oracle/pfile.ora' from spfile;
##拷贝至新主机
su - oracle
scp /home/oracle/pfile.ora 10.211.55.112:/tmp
scp $ORACLE_HOME/dbs/orapworcl 10.211.55.112:$ORACLE_HOME/dbs
###新主机根据实际情况修改参数文件并且创建目录
mkdir -p /u01/app/oracle/admin/orcl/adump
mkdir -p /oradata/orcl/
mkdir -p /archivelog
chown -R oracle:oinstall /archivelog
chown -R oracle:oinstall /oradata
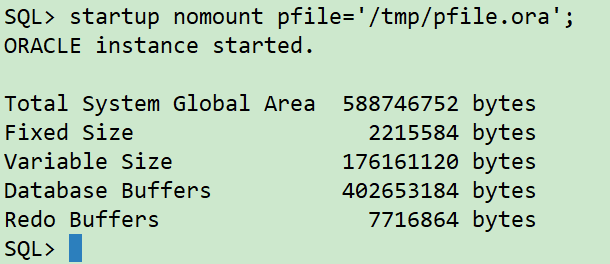
3 新主机使用修改后的参数文件打开数据库实例到nomount状态
sqlplus / as sysdba
startup nomount pfile='/tmp/pfile.ora';
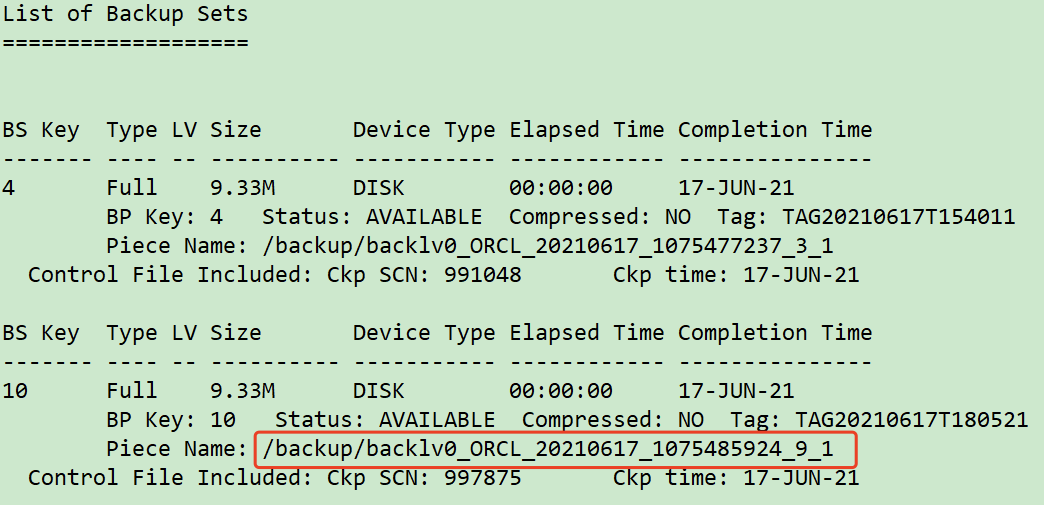
4 主库拷贝备份的控制文件至新主机,新主机使用RMAN恢复控制文件,并且MOUNT新实例
rman target /
list backup of controlfile;
##拷贝备份文件至新主机
scp /backup/backlv0_ORCL_20210617_107548592* 10.211.55.112:/tmp
scp /u01/app/oracle/product/11.2.0/db/dbs/0c01l775_1_1 10.211.55.112:/tmp
##新主机恢复控制文件并开启到mount状态
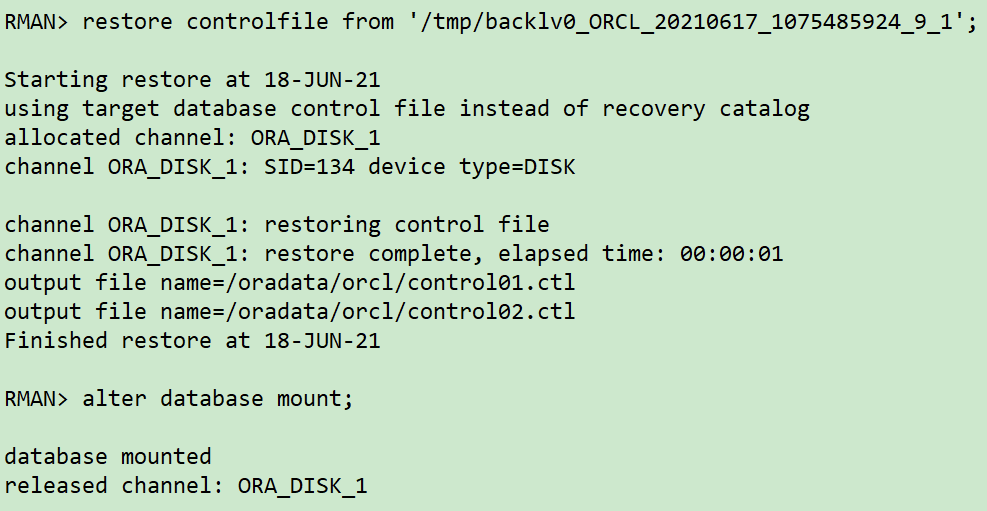
rman target /
restore controlfile from '/tmp/backlv0_ORCL_20210617_1075485924_9_1';
alter database mount;
通过 list backup of controlfile; 可以看到控制文件位置。

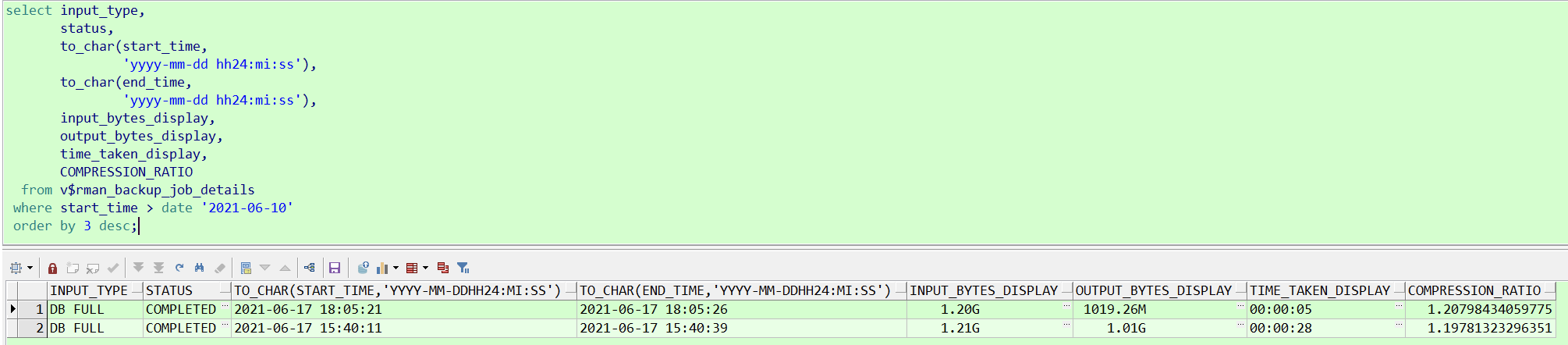
5 新主机RESTORE TABLESPACE恢复至时间点 <2021/06/17 18:06:00>
##新主机注册备份集
rman target /
catalog start with '/tmp/backlv0_ORCL_20210617_107548592';
crosscheck backup;
delete noprompt expired backup;
delete noprompt obsolete device type disk;
##恢复表空间LUCIFER和系统表空间,指定时间点 `2021/06/17 18:06:00`
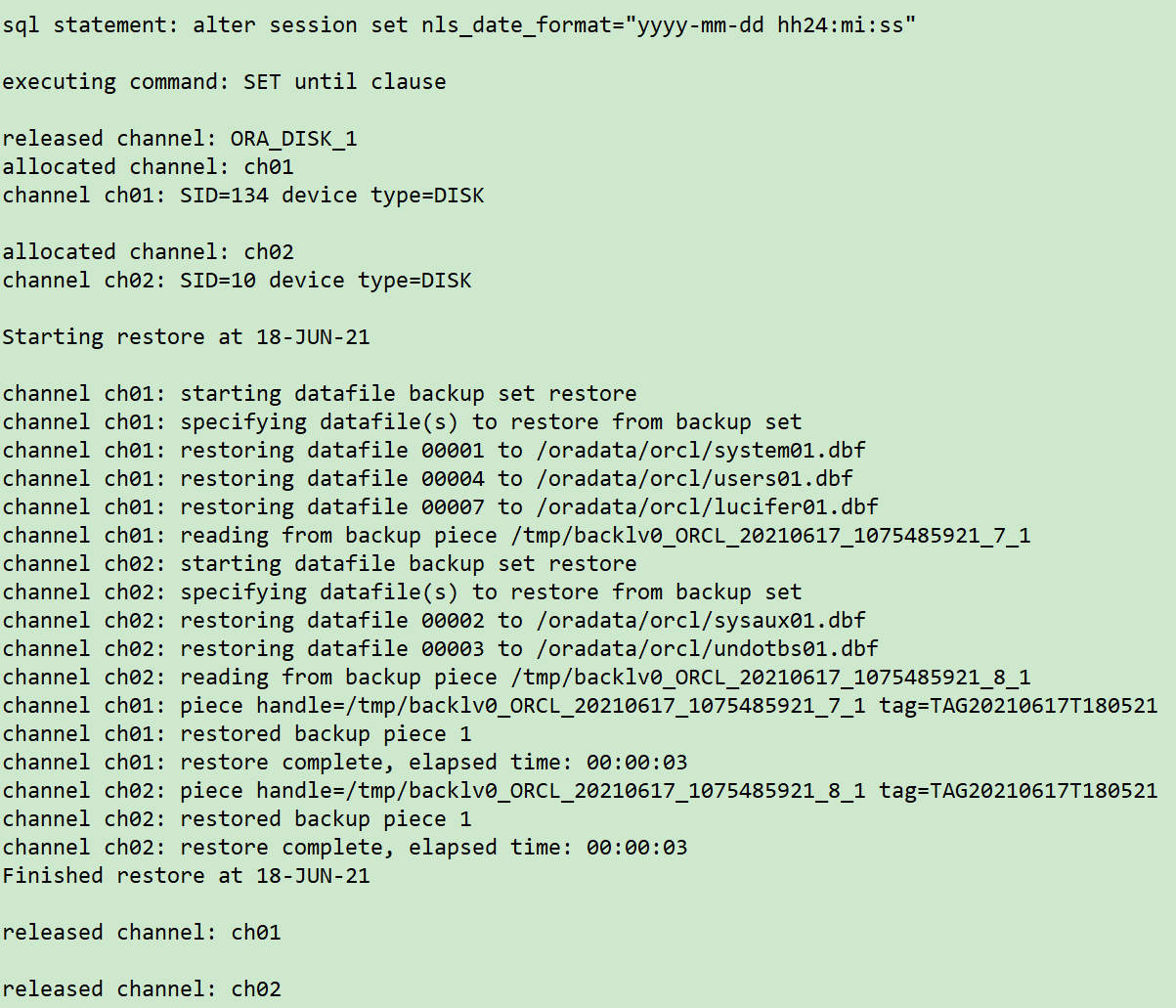
run {
sql 'alter session set nls_date_format="yyyy-mm-dd hh24:mi:ss"';
set until time '2021-06-17 18:06:00';
allocate channel ch01 device type disk;
allocate channel ch02 device type disk;
restore tablespace SYSTEM,SYSAUX,UNDOTBS1,USERS,LUCIFER;
release channel ch01;
release channel ch02;
}
6 新主机RECOVER DATABASE SKIP TABLESPACE恢复至时间点 <2021/06/17 18:06:00>
rman target /
run {
sql 'alter session set nls_date_format="yyyy-mm-dd hh24:mi:ss"';
set until time '2021-06-17 18:06:00';
allocate channel ch01 device type disk;
recover database skip tablespace LTEST,EXAMPLE;
release channel ch01;
}
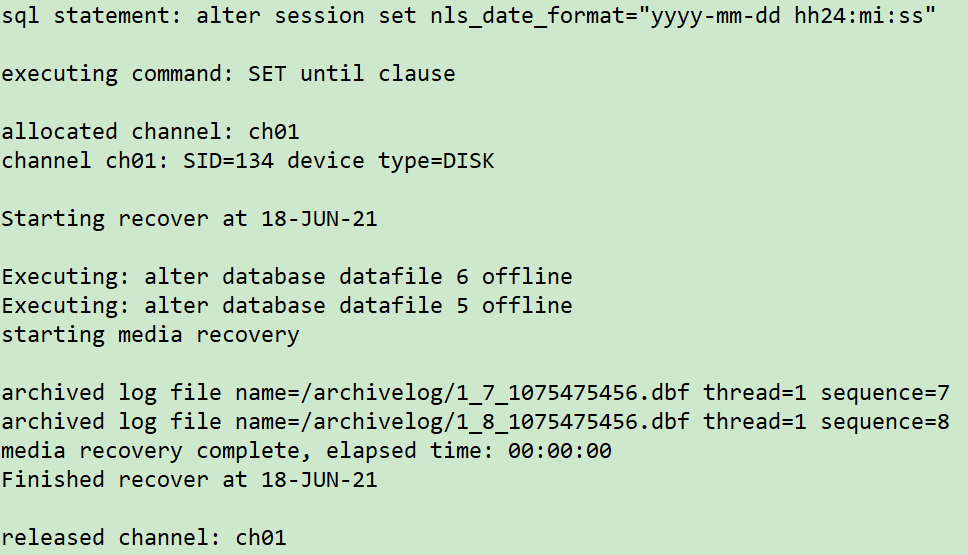
这里有一个小BUG:客户环境是Windows,执行这一步最后报错,手动offline数据文件依然无法开启数据库。

解决方案:
--将恢复跳过的表空间都offline drop掉,执行以下查询结果
select 'alter database datafile '|| file_id ||' offline drop;' from dba_data_files where tablespace_name in ('LTEST','EXAMPLE');
--再次开启数据库
alter database open read only;
注意:如果显示缺归档日志,可以参考如下步骤:
##查询恢复需要的归档日志号时间 alter session set nls_date_format="yyyy-mm-dd hh24:mi:ss"; select first_time,sequence# from v$archived_log where sequence#='7'; ##通过备份RESTORE吐出所需的归档日志 rman target / catalog start with '/tmp/0c01l775_1_1'; crosscheck archivelog all; run { allocate channel ch01 device type disk; SET ARCHIVELOG DESTINATION TO '/archivelog'; restore ARCHIVELOG SEQUENCE 7; release channel ch01; } ##再次recover进行恢复至指定时间点 2021-06-17 18:06:00 run { sql 'alter session set nls_date_format="yyyy-mm-dd hh24:mi:ss"'; set until time '2021-06-17 18:06:00'; allocate channel ch01 device type disk; recover database skip tablespace LTEST,EXAMPLE; release channel ch01; }
7 新主机实例开启到只读模式
sqlplus / as sysdba
alter database open read only;

8 确认新主机实例的表数据是否正确
select * from lucifer.lucifer;

注意:若不正确则重复 第7步 调整时间点慢慢往 2021/06/17 18:10:00 推进恢复:
##关闭数据库 sqlplus / as sysdba shutdown immediate; ##开启数据库到mount状态 startup mount pfile='/tmp/pfile.ora'; ##重复 第7步,往前推进1分钟,调整时间点为 `2021/06/08 18:07:00` rman target / run { sql 'alter session set nls_date_format="yyyy-mm-dd hh24:mi:ss"'; set until time '2021-06-17 18:07:00'; allocate channel ch01 device type disk; recover database skip tablespace LTEST,EXAMPLE; release channel ch01; }
9 主库创建连通新主机实例的DBLINK,通过DBLINK从新主机实例捞取表数据
sqlplus / as sysdba
CREATE PUBLIC DATABASE LINK ORCL112
CONNECT TO lucifer
IDENTIFIED BY lucifer
USING '(DESCRIPTION_LIST=
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=10.211.55.112)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=orcl)
)
)
)';
--通过dblink捞取数据
create table lucifer.lucifer_0618 as select /*+full(lucifer)*/ * from lucifer.lucifer@ORCL112;
select * from lucifer.lucifer_0618;

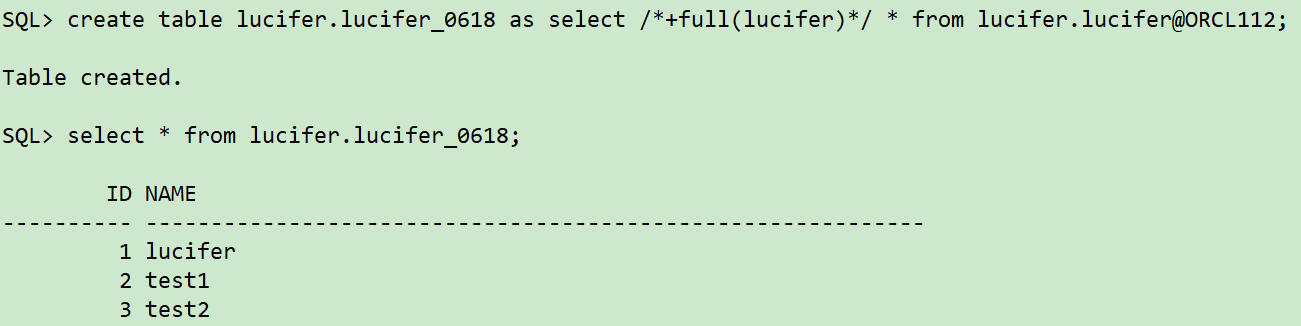
至此,整个RMAN恢复过程就结束了。
总之,有备份什么都好说。所以,作为DBA,备份一定要做好!!!
本次分享到此结束啦~
如果觉得文章对你有帮助,点赞、收藏、关注、评论,一键四连支持,你的支持就是我创作最大的动力。
技术交流可以 关注公众号:Lucifer三思而后行

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)