如何实现 Python 库

Python for Data Science是数据分析领域专业人士的必备技能。随着 IT 行业的发展,对熟练数据科学家的需求不断增长 , Python已发展成为数据驱动开发的首选编程语言。通过本文,您将学习基础知识,如何分析数据,然后使用 Python 创建一些漂亮的可视化。
在开始之前,让我列出我将在本文中涵盖的主题。
- What is Data Science?
- Why Python For Data Science?
- Data Scientist Jobs
- Data Scientists Salary Trends
- Company Trends For Data Science
- Python Basics For Data Science
- Python Libraries For Data Science
- Master Data Science – Use Cases
什么是数据科学?
数据科学已成为技术专业人士非常有前途的职业道路。数据科学的真正本质在于解决问题的能力,以提供由数据驱动的洞察力和解决方案。关于数据科学存在很多误解,数据科学生命周期是获得更清晰的视角来理解数据科学真正含义的一种方式。
数据科学生命周期
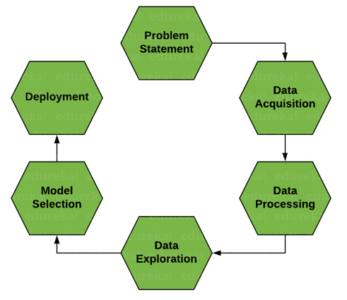
数据科学考虑了从理解业务需求到为模型构建准备数据和最终部署洞察力的整个过程。整个过程由不同的专业人员处理,包括数据分析师、数据工程师和数据科学家。角色取决于公司的规模,有时所有流程都由一名专业人员完成。让我们试着理解为什么 Python 是适合数据科学的编程语言。
为什么 Python 用于数据科学?
毫无疑问,Python 是最适合数据科学家的语言。我列出了几点,它们将帮助您理解人们为什么使用 Python 进行数据科学:
- Python 是一种免费、灵活且功能强大的开源语言
- Python 以其简单易读的语法将开发时间缩短了一半
- 使用 Python,您可以执行数据操作、分析和可视化
- Python 为机器学习应用程序和其他科学计算提供了强大的库
数据科学家工作
数据科学家是目前市场上最热门的职位,仅 2020 年预计就有超过 250,000 到 170 万个职位空缺,对于任何专业学习数据科学的人来说都是非常有希望的。
与任何其他职位空缺相比,数据科学家职位简介在任何门户网站上的开放时间都多 5 天。
据消息人士透露,未来看起来也非常有希望,数据科学就业市场将出现大规模激增,预计到 2025 年将再增加 500,000 至 1100 万个工作岗位。
随着数据流量的增加,很明显市场在数据上蓬勃发展。它几乎会在任何地方产生影响,因此范围不仅仅与特定领域有关。数据科学是任何组织、业务等不可或缺的一部分。

让我们来看看与数据科学相关的工作简介在市场上获得的辛勤工作的成果。
数据科学薪资趋势
数据科学工作市场充满了工作简介,因此为了让您更清楚地了解这里是市场上数据科学相关工作的前 3 名工作简介,其平均工资在美国和印度。

让我们来看看围绕数据科学工作市场的公司趋势。
公司数据科学趋势
数据科学是任何组织、企业等不可或缺的一部分。市场上的一些主要参与者已被列出,但我们必须清楚,这些只是更大的冰山一角。世界上流动的数据量几乎让每个组织都为数据驱动的开发对业务产生的影响而努力。因此,即使是规模较小的企业也在数据科学市场上蓬勃发展,并在行业中崭露头角。
让我们来看看要掌握数据科学必须掌握的基础知识。
数据科学的 Python 基础
现在是您接触Python 编程的时候了。但是为此,您应该对以下主题有基本的了解:
- 变量:变量是指用于存储值的保留内存位置。在 Python 中,您不需要在使用变量之前声明它们,甚至不需要声明它们的类型。
- 数据类型: Python 支持多种数据类型,它定义了对变量的可能操作和存储方法。数据类型列表包括 – 数字、列表、字符串、元组、集合和字典。
- 运算符: 运算符有助于操纵操作数的值。Python 中的运算符列表包括 - 算术、比较、赋值、逻辑、按位、成员资格和身份。
- 条件语句:条件语句有助于根据条件执行一组语句。有即三个条件语句 - If、Elif 和 Else。
- 循环: 循环用于迭代小段代码。共有三种类型的循环,即While、for 和嵌套循环。
- 函数: 函数用于将您的代码划分为有用的块,允许您对代码进行排序,使其更具可读性,重用它并节省一些时间。
更多信息和实际实现可以参考这篇博客: Python教程。
加载数据
首先,第一步是将数据加载到您的程序中。我们可以通过使用 Python panda 库中的 read_csv() 来实现。
import pandas as pd
data = pd.read_csv("file_name.csv")在程序中加载数据后,您可以浏览数据。

清理数据
下一步是通过进行一些数据探索来寻找数据中的不规则性。此阶段涉及找出空值并将其替换为其他值或完全删除该行。
data.describe()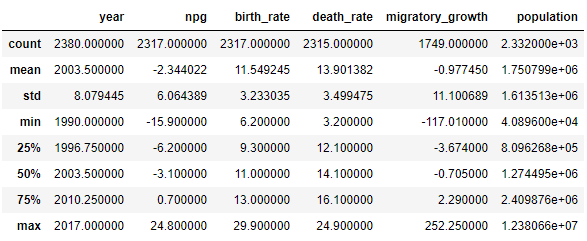
#to check for null values
data.isnull().sum()
#drop the null values
df = data.dropna()
#checking again to be double sure
df.isnull().sum()

可视化
完成清理后,我们可以继续进行一些可视化,以了解数据集各个方面之间的关系。
sns.scatterplot(x=df["npg"], y=df["birth_rate"])
根据我们的分析,我们可以得出结论并提供对数据驱动的问题和见解的见解。
用于数据科学的 Python 库
这是 Python 与数据科学的实际力量发挥作用的部分。 Python 附带了许多用于科学计算、分析、可视化等的库。其中一些列在下面:
Numpy
NumPy是用于数据科学的 Python 核心库,代表“Numerical Python”。用于科学计算,包含强大的n维数组对象,提供集成C、C++等工具。通用数据的多维容器,您可以在其中执行各种 Numpy操作 和特殊 功能。
Pandas
Pandas是 Python 中用于数据科学的重要库。它用于数据操作和分析。 它非常适合不同的数据,例如表格、有序和无序 时间序列、矩阵数据等。
MatplotLib
Matplotlib是一个强大的 Python 可视化库。它可用于 Python 脚本、shell、Web 应用程序服务器和其他 GUI 工具包。您可以使用不同 类型的绘图 以及 使用 Matplotlib 的多个绘图的工作方式。
Seaborn
Seaborn是一个 Python 中的统计绘图库。因此,无论何时您将 Python 用于数据科学,您都将使用matplotlib (用于 2D 可视化)和 Seaborn,它具有漂亮的默认样式和用于绘制统计图形的高级界面。
Scikit-Learn
Scikit learn是主要吸引力之一,您可以在其中使用 Python 实现机器学习。它是一个免费的库,包含用于数据分析和挖掘目的的简单有效的工具。您可以 使用 scikit-learn实现各种算法,例如逻辑回归、时间序列算法。建议你去 通过这个关于Scikit-learn 的教程视频, 在继续之前了解机器学习和各种技术。
使用案例掌握数据科学
让我们继续并借助一些示例进行学习。这些示例由问题陈述驱动我们将根据数据科学生命周期过程得出我们的结论。
问题陈述一
使用 FIFA 数据集的最佳球队选择
我们有一个由各种球员组成的数据集,包括关于他们的技能、国籍、俱乐部等的统计数据。我们的目标是在特定球队阵型的所有球员中找到一支最好的球队。
所以我们的方法是在不同的球队位置寻找最好的球员。我们将建立的阵型是 4-3-3。因此,我们将寻找的位置是 – ('LCB', 'CB','CB','RCB','LCM','RCM','CDM','LW','RW','ST' )
我们将遵循以下步骤,以打造最佳团队。
- 加载数据集
- 清理数据集
- 探索数据
- 可视化
- 结论
加载数据集
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.read_csv(r"C:UsersWaseemDesktopdatasetsfifa-20-complete-player-datasetplayers_20.csv")
fifa = pd.DataFrame(data, columns=['short_name', 'age', 'height_cm', 'nationality', 'club', 'weight_kg', 'overall', 'potential','team_position',
'team_jersey_number'])
fifa.head()
我们制作了一个单独的数据框,其中仅包含我们得出结论所需的列。为了决定任何位置的最佳球员,整体和潜力将是一个非常重要的限制因素。
清理数据
我们将从空值中清除数据集。
fifa.isnull().sum()
fifa = fifa.dropna()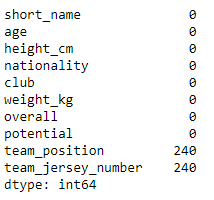
大多数空值位于球队位置和球队球衣列中,对于我们的问题陈述,球队位置是驱动因素,因此我们将删除这些空值。
探索数据
我们可以探索数据以获取有关数据的一些见解。
top = fifa.short_name[(fifa.overall > 88) & (fifa.potential >89 )]
print(top)上面的代码为我们提供了总分超过 88 和潜力超过 89 的球员的名字。
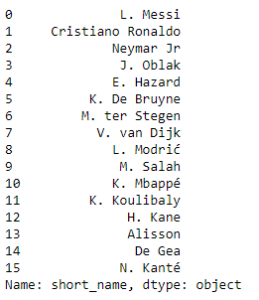
现在,我们将继续进行一些可视化,以了解数据集中各列之间的关系。
可视化
sns.catplot(x='team_position', kind='count', data=fifa, height=5, aspect=3)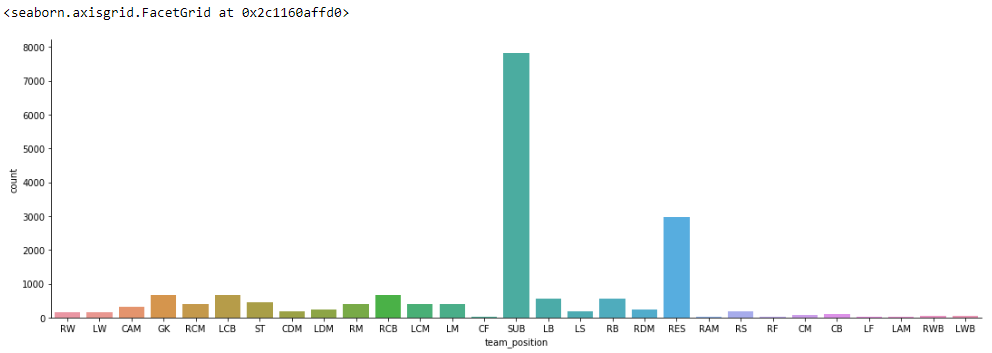
sns.catplot(x='overall', kind='count', data=fifa, height= 5, aspect= 3)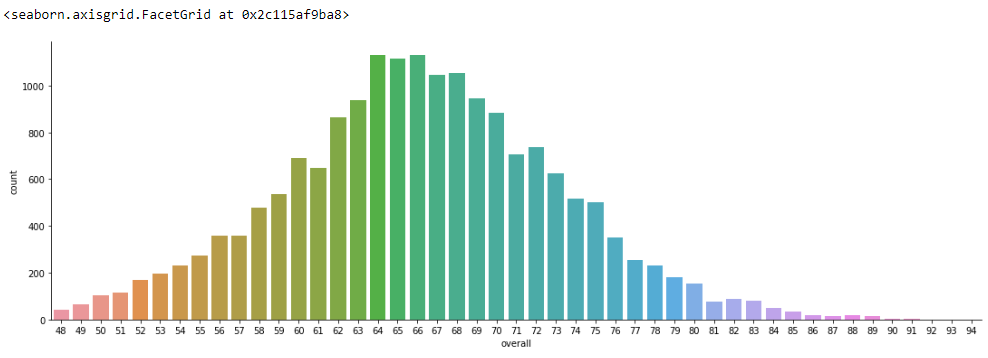
sns.catplot(x='club', y='overall',kind='box', data=fifa[0:20], height= 5, aspect= 3)
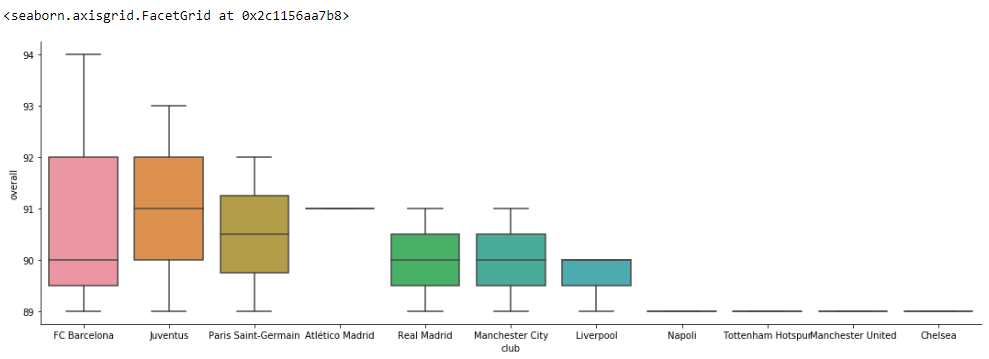
从上面的可视化中,我们能够计算出玩家之间的整体分布。俱乐部中的球员人数和球队位置以及他们的人数。所以这对于我们的问题陈述就足够了。
在此基础上,我们会为各个团队位置找到最佳球员。
LW位置的最佳球员
plt.figure(figsize=(15,6))
sd = fifa[(fifa['team_position'] == 'LW')].sort_values('overall', ascending=False)[:5]
x2 = np.array(list(sd['short_name']))
y2 = np.array(list(sd['overall']))
sns.barplot(x2, y2, palette=sns.color_palette("Blues_d"))
plt.ylabel("LW Score")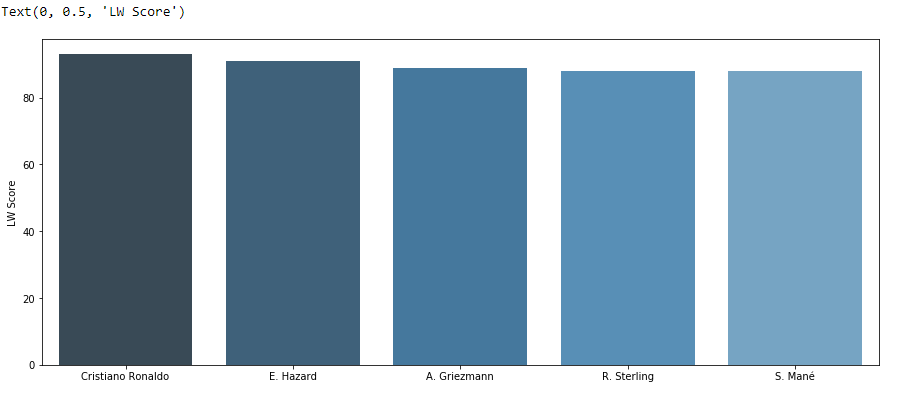
同样,我们也可以为其他位置挑选最好的球员。
结论
基于 FIFA 数据集的 4-3-3 阵型的最佳球队将是:
fifa_skills = pd.DataFrame(data, columns= ['short_name','team_position','pace','shooting','passing','dribbling','defending','overall'
])
team = fifa_skills[(fifa_skills.short_name == 'L. Messi')|
(fifa_skills.short_name == 'H. Kane')|
(fifa_skills.short_name == 'Cristiano Ronaldo')|
(fifa_skills.short_name == 'K. de Bruyne')|
(fifa_skills.short_name == 'Sergio Busquets')|
(fifa_skills.short_name == 'David Silva')|
(fifa_skills.short_name == 'F. Acerbi')|
(fifa_skills.short_name == 'S. de Vrij')|
(fifa_skills.short_name == 'V. van Dijk')|
(fifa_skills.short_name == 'Pique')]
print(team)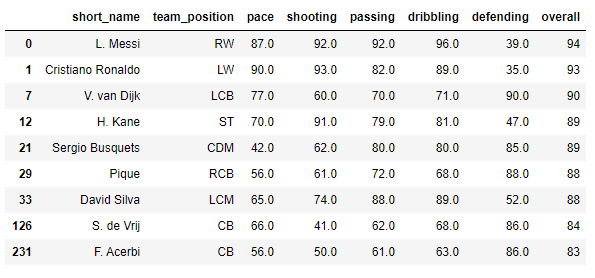
问题陈述二
单个股票预测
在这个问题陈述中,我们有一个带有单一股票值的干净数据集。我们将使用python制作一个预测模型来预测特定日期的单个股票价格。
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import datetime
df = pd.read_csv("trainset.csv")
df.head()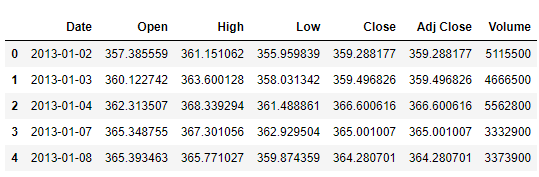
df.isnull().sum()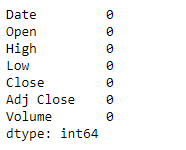
df['Date'] = df.Date.astype(str)
df['Date'] = df.Date.str.replace("-","").astype(float)
dates = df['Date']
x = dates.values.reshape(-1,1)
prices = df.Open
y = prices.values.reshape(-1,1)
reg = LinearRegression()
reg.fit(x,y)
pred = reg.predict(x[[0]])
print(pred)
plt.scatter(x,y,color='red')
plt.plot(x, reg.predict(x))输出: array([[415.36098414]])
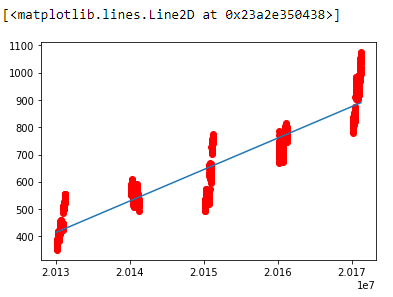
在上面的例子中,我们做了一个预测模型,使用线性回归来预测单个股票的价格。类似地,我们可以使用更大的数据集为许多复杂问题制作预测模型。
这使我们到了本文的结尾,在那里我们学习了如何将 Python 用于数据科学。我希望您清楚本教程中与您分享的所有内容。

- 点赞
- 收藏
- 关注作者
评论(0)