SQL 数据科学:初学者的一站式解决方案

自从数据科学被列为那个时代最有前途的工作以来,我们都在努力加入学习数据科学的竞赛。这篇关于 SQL for Data Science 的博文将帮助您了解如何使用 SQL 来存储、访问和检索数据以执行数据分析。
为什么数据科学需要 SQL?
您知道我们每天生成超过 2.5 千亿字节的数据吗?这种数据生成的速度是数据科学、人工智能、机器学习等高端技术流行的原因。
从数据中获得有用的见解被称为数据科学。数据科学涉及提取、处理和分析大量数据。目前我们需要的是工具,可用于存储和管理这一庞大的数据量。

SQL 可用于存储、访问和提取海量数据,以便更顺畅地执行整个数据科学过程。
什么是 SQL?
SQL代表结构化查询语言,是一种旨在管理关系数据库的查询语言。
但究竟什么是关系数据库?
关系数据库是一组定义良好的表,可以从中访问、编辑、更新数据等,而无需更改数据库表。SQL 是关系数据库的标准 (API)。
回到 SQL,SQL 编程可用于对数据执行多项操作,例如查询、插入、更新、删除数据库记录。使用 SQL 的关系数据库示例包括 MySQL 数据库、Oracle 等。
- SQL 命令 - SQL 初学者指南
- 了解 SQL 数据类型——关于 SQL 数据类型你需要知道的一切
- 在 SQL 中创建表——关于在 SQL 中创建表你需要知道的一切
- SQL 和 NoSQL 数据库之间的差异 – MySQL 和 MongoDB 比较
在开始演示 SQL 之前,让我们先熟悉基本的 SQL 命令。
SQL 基础知识
SQL提供了一组简单的修改数据表的命令,我们来看看一些基本的SQL命令:
- CREATE DATABASE –创建一个新的数据库
- CREATE TABLE –创建一个新表
- INSERT INTO –将新数据插入数据库
- SELECT –从数据库中提取数据
- UPDATE –更新数据库中的数据
- DELETE –从数据库中删除数据
- ALTER DATABASE –修改数据库
- ALTER TABLE –修改表
- DROP TABLE –删除一个表
- CREATE INDEX –创建索引以搜索元素
- DROP INDEX –删除索引
为了更好地理解 SQL,让我们安装 MySQL,看看如何处理数据。
安装 MySQL
安装 MySQL 是一项简单的任务。这是一个分步指南,可帮助您在系统上安装 MySQL。
安装完成后 MySQL,请按照以下部分进行简单演示,该演示将向您展示如何插入、操作和修改数据。
用于数据科学的 SQL – MySQL 演示
在这个演示中,我们将看到如何创建数据库并处理它们。这是一个初学者级别的演示,可帮助您开始对 SQL 进行数据分析。
让我们开始吧!
步骤 1:创建 SQL 数据库
SQL 数据库是一个存储仓库,可以在其中以结构化格式存储数据。现在让我们使用MySQL创建一个数据库:
CREATE DATABASE edureka;
USE edureka;在上面的代码中,有两条SQL命令:
注意:SQL 命令以大写字母定义,分号用于终止 SQL 命令。
-
CREATE DATABASE:此命令创建一个名为“edureka”的数据库
-
USE:该命令用于激活数据库。在这里,我们正在激活“edureka”数据库。
第 2 步:创建具有所需数据特征的表
创建表就像创建数据库一样简单。您只需要使用它们各自的数据类型定义表的变量或特征。让我们看看如何做到这一点:
CREATE TABLE toys (TID INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT, Item_name TEXT, Price INTEGER, Quantity INTEGER);
在上面的代码片段中,发生了以下事情:
- 使用'CREATE TABLE' 命令创建一个名为toys 的表。
- 玩具表包含 4 个特征,即 TID(交易 ID)、Item_name、价格和数量。
- 每个变量都用它们各自的数据类型定义。
- TID 变量被声明为主键。主键基本上表示可以存储唯一值的变量。
您可以使用以下命令进一步检查定义表的详细信息:
DESCRIBE toys;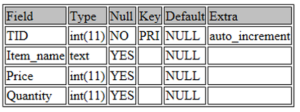
第 3 步:向表中插入数据
现在我们已经创建了一个表,让我们用一些值填充它。在本博客的前面,我提到了如何仅使用单个命令(即 INSERT INTO)将数据添加到表中。
让我们看看这是如何完成的:
INSERT INTO toys VALUES (NULL, "Train", 550, 88);
INSERT INTO toys VALUES (NULL, "Hotwheels_car", 350, 80);
INSERT INTO toys VALUES (NULL, "Magic_Pencil", 70, 100);
INSERT INTO toys VALUES (NULL, "Dog_house", 120, 54);
INSERT INTO toys VALUES (NULL, "Skateboard", 700, 42);
INSERT INTO toys VALUES (NULL, "G.I. Joe", 300, 120);在上面的代码片段中,我们简单地使用 INSERT INTO 命令将 6 个观察值插入到我们的“玩具”表中。对于每个观察,在括号内,我已经指定了在创建表时定义的每个变量或特征的值。
TID 变量设置为 NULL,因为它从 1 自动递增。
现在让我们显示表中存在的所有数据。这可以通过使用以下命令来完成:
SELECT * FROM toys;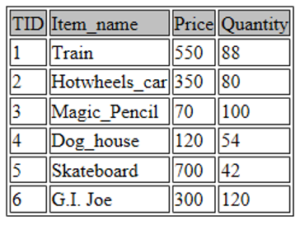
第 4 步:修改数据条目
假设您决定提高 GI Joe 的价格,因为它为您带来了很多客户。您将如何更新数据库中变量的价格?
很简单,只需使用以下命令:
UPDATE toys SET Price=350 WHERE TID=6;UPDATE 命令允许您修改存储在表中的任何值/变量。SET 参数允许您选择特定功能,而 WHERE 参数用于标识要更改的变量/值。在上面的命令中,我更新了 TID 为 6 (GI Joe) 的数据条目的价格。
现在让我们查看更新后的表:
SELECT * FROM toys;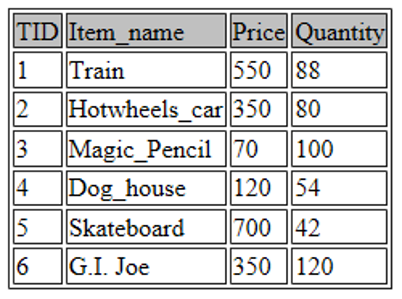
您还可以通过引用您要查看的列来修改您要显示的内容。例如,下面的命令将只显示玩具的名称及其各自的价格:
SELECT Item_name, Price FROM toys;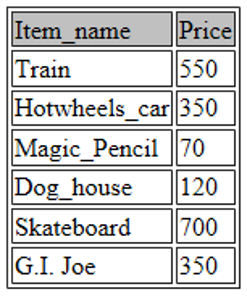
第 5 步:检索数据
所以在插入数据并修改之后,终于可以根据业务需求提取和检索数据了。在这里可以检索数据以进行进一步的数据分析和数据建模。
请注意,这是一个让您开始使用 SQL 的简单示例,但是,在实际场景中,数据要复杂得多且规模更大。尽管如此,SQL 命令仍然保持不变,这就是 SQL 如此简单易懂的原因。它可以使用一组简单的 SQL 命令处理复杂的数据集。
现在让我们通过一些修改来检索数据。请参阅下面的代码,并尝试在不查看输出的情况下了解它的作用:
SELECT * FROM toys LIMIT 2;你猜到了!它显示了我的表格中出现的前两个观察结果。
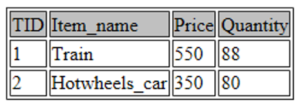
让我们尝试一些更有趣的事情。
SELECT * FROM toys ORDER BY Price ASC;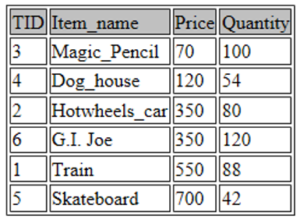
如图所示,这些值按照价格变量的升序排列。如果您想查找最常购买的三个项目,您会怎么做?
真的很简单!
SELECT * FROM toys ORDER BY Quantity DESC LIMIT 3;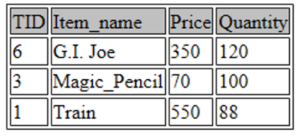
让我们再试一次。
SELECT * FROM toys WHERE Price > 400 ORDER BY Price ASC;
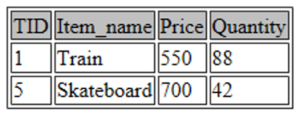
此查询提取价格超过 400 的玩具的详细信息,并按价格升序排列输出。
这就是您可以使用 SQL 处理数据的方式。现在您已经了解了用于数据科学的 SQL 的基础知识,我相信您很想了解更多信息。以下是一些可以帮助您入门的博客:
可以让您精通监督学习、无监督学习和自然语言处理等技术。它包括有关人工智能和机器学习的最新进展和技术方法,例如深度学习、图形模型和强化学习。

- 点赞
- 收藏
- 关注作者
评论(0)