(异步爬虫)今个儿清闲,来爬取弹幕(不限量)

最近B站新番“咒术回战”挺火的,正好现在有点时间,想把弹幕给爬下来,之后有时间分析一下看看弹幕上大家都在讨论些什么话题。由于番剧还在更新,这里只爬取第一集开播(10月3日)到今天为止的弹幕作为参考。话不多说,直接开始。
页面分析
让我们先来看看页面结构。
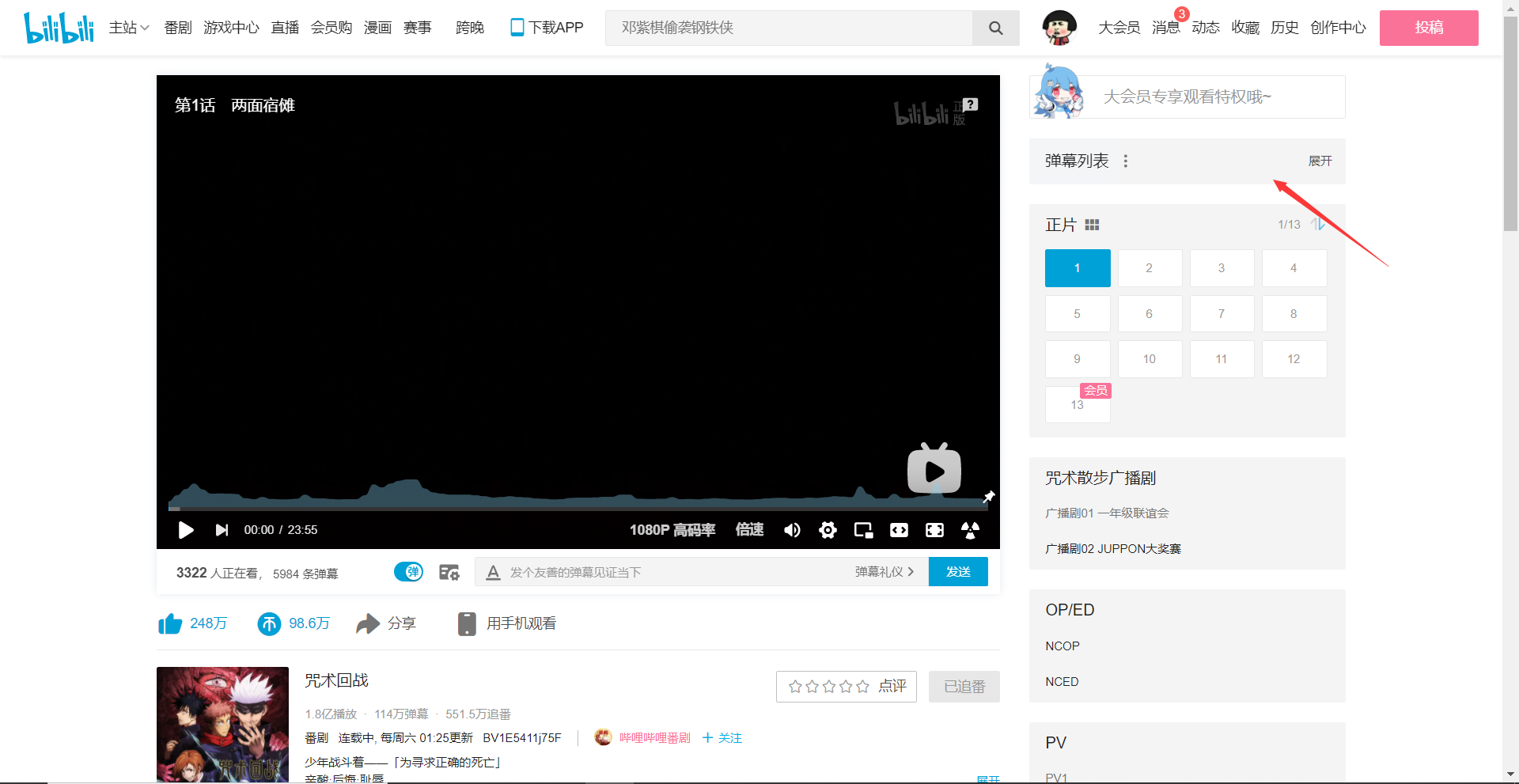
既然不是直接显示在界面上,使用常规的 requests 获取的页面数据肯定是行不通的。这时,我们自然想到使用 selenium 来获取动态加载完成后的页面数据,在完成页面获取之前我们也可以通过点击,或者下拉滚动条的方式,来使我们获取的数据更加完整。我们先展开弹幕列表同时对照页面源码来观察源码的变化情况。
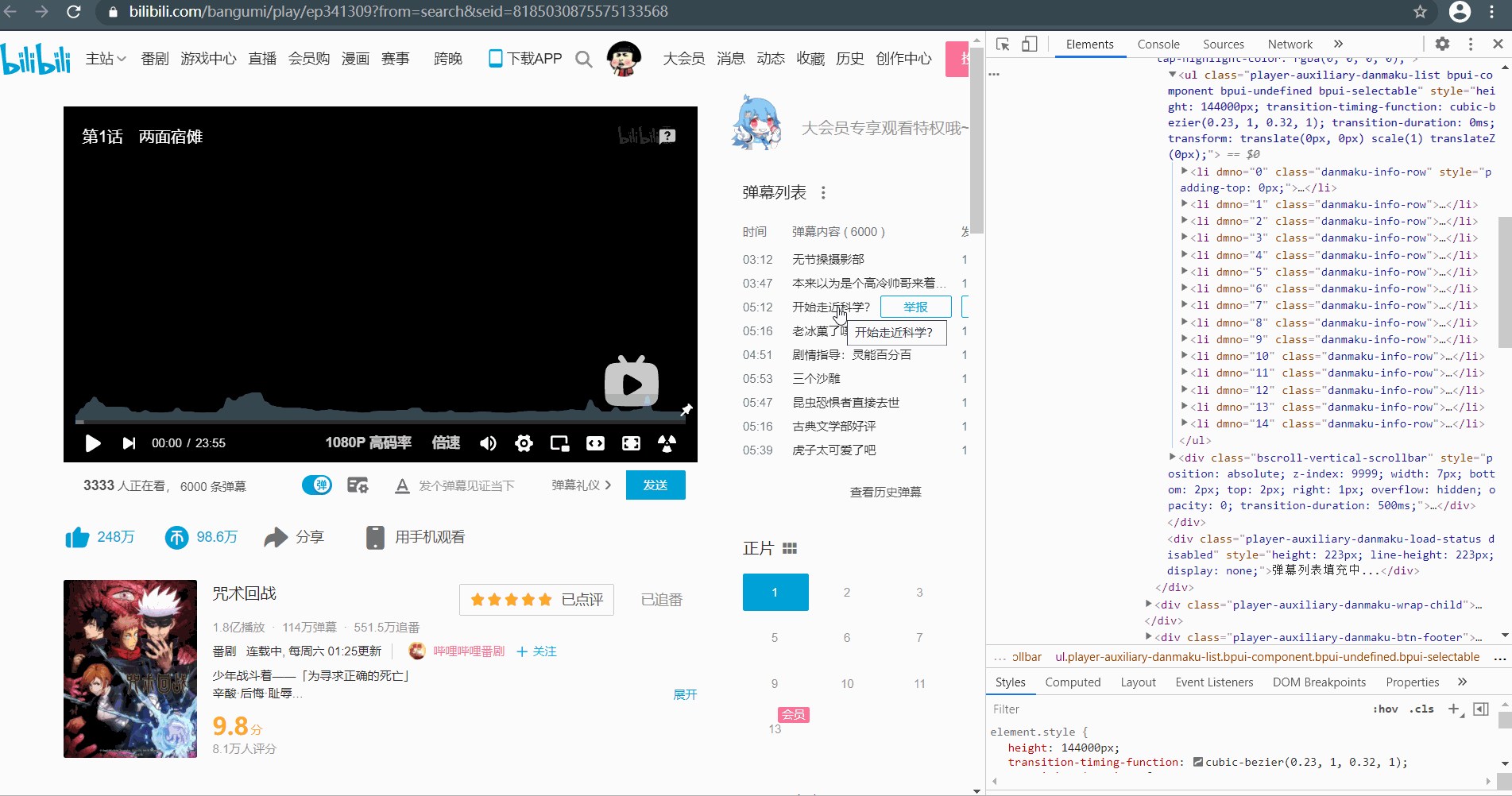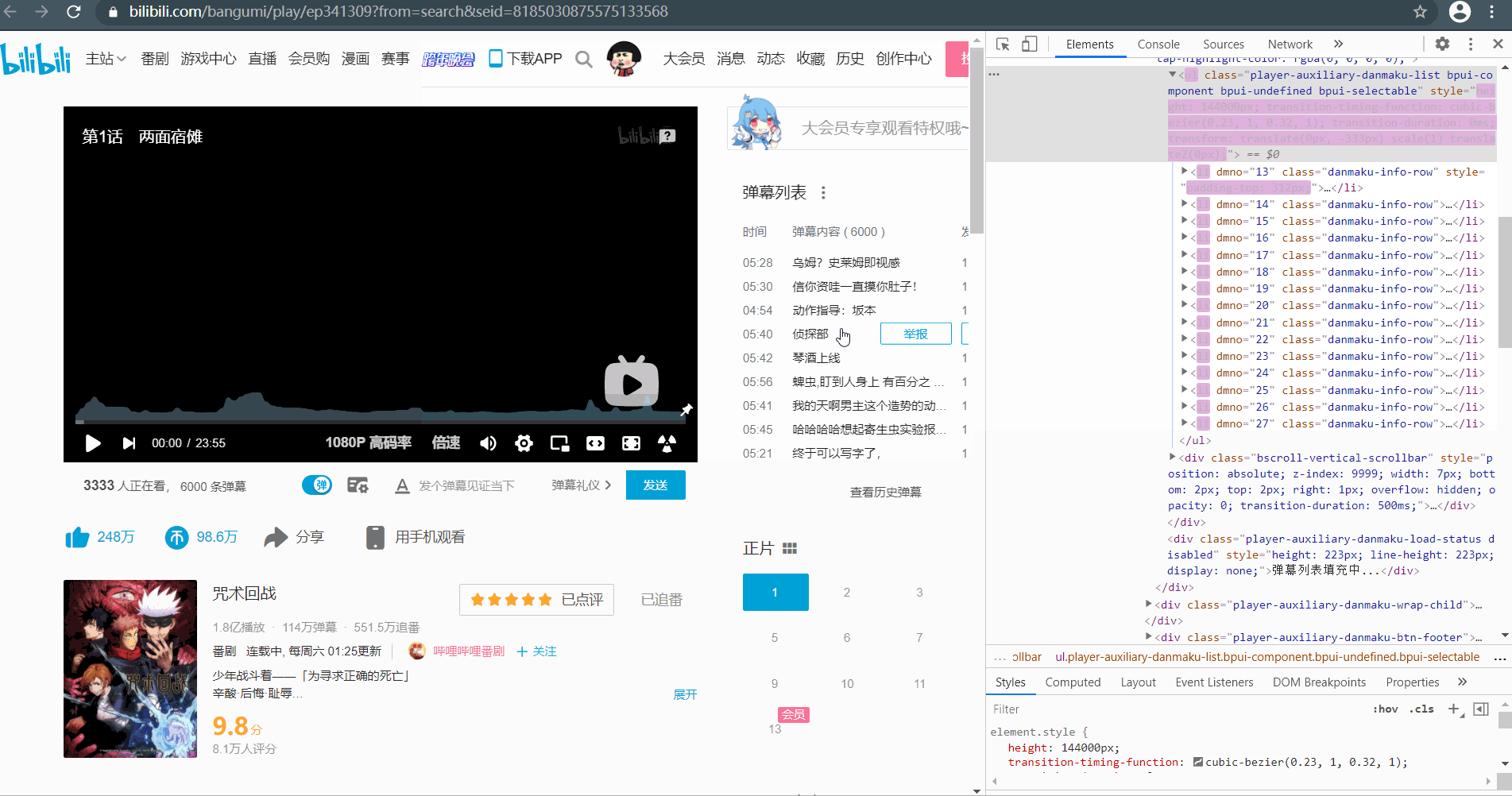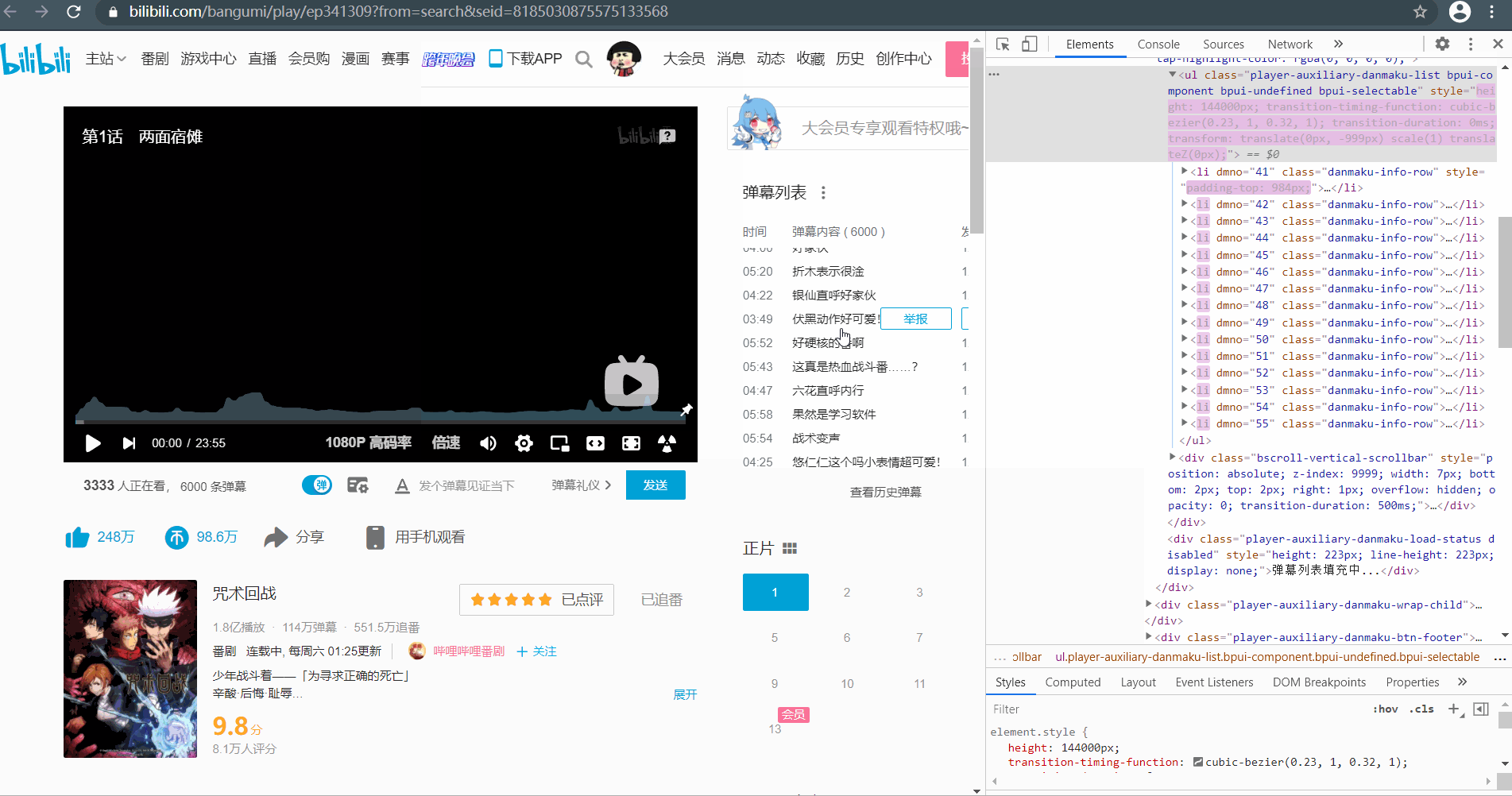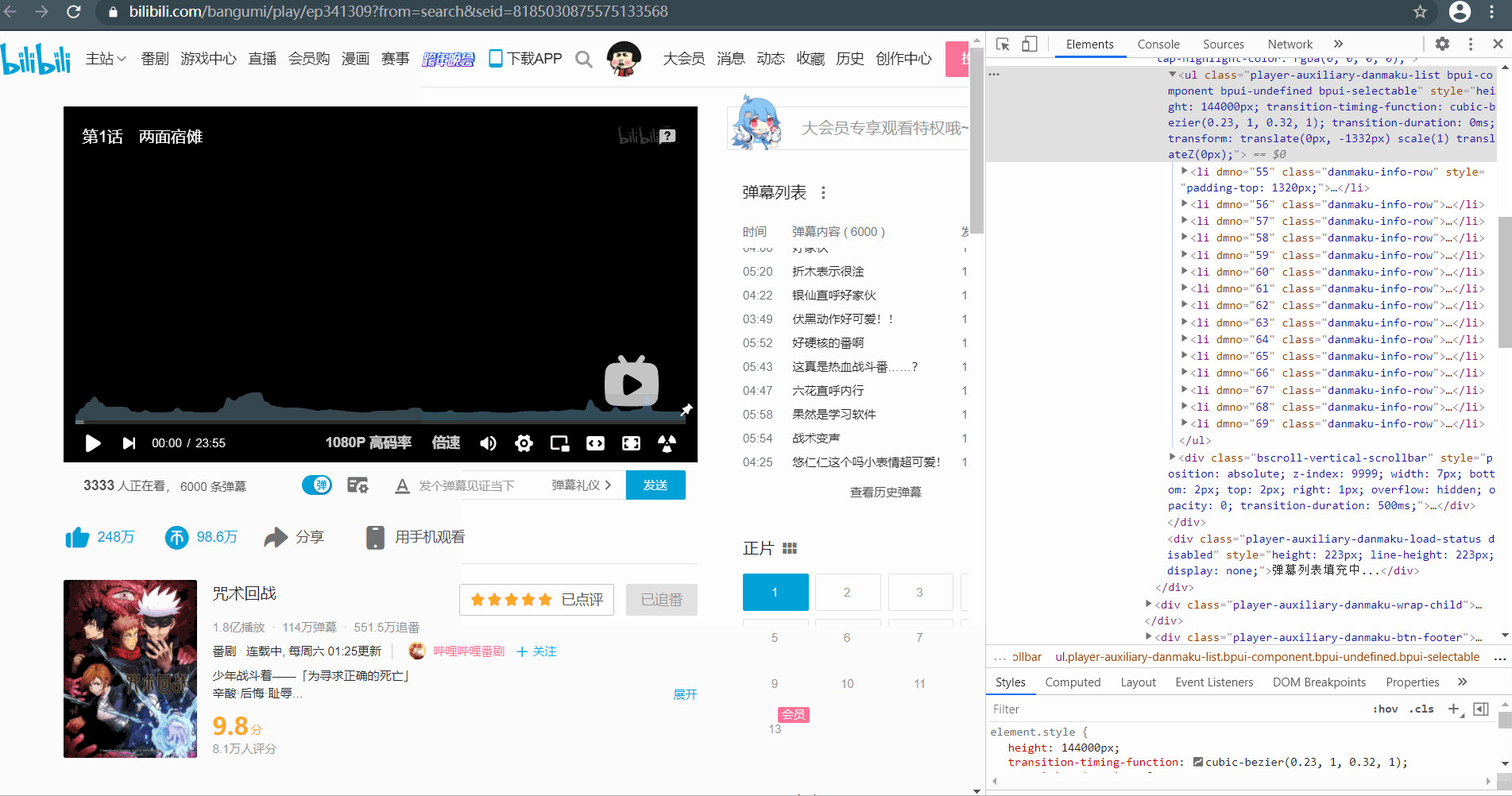
展开弹幕,当我们向下滑动时,之前出现浏览过的弹幕别没有保留在页面源码 li 标签中,源码中只显示固定长度的弹幕,这样的话使用 selenium 模拟滑动,即使滑倒弹幕最底端,上面的数据在获取页面数据时还是获取不到。
无奈我们只能换一条思路,无法获取页面中加载出来的弹幕,我们可以通过接口获取每日历史弹幕。点击查看历史弹幕,选择日期后,通过抓包工具可找到一个 name 为 history 的数据包。
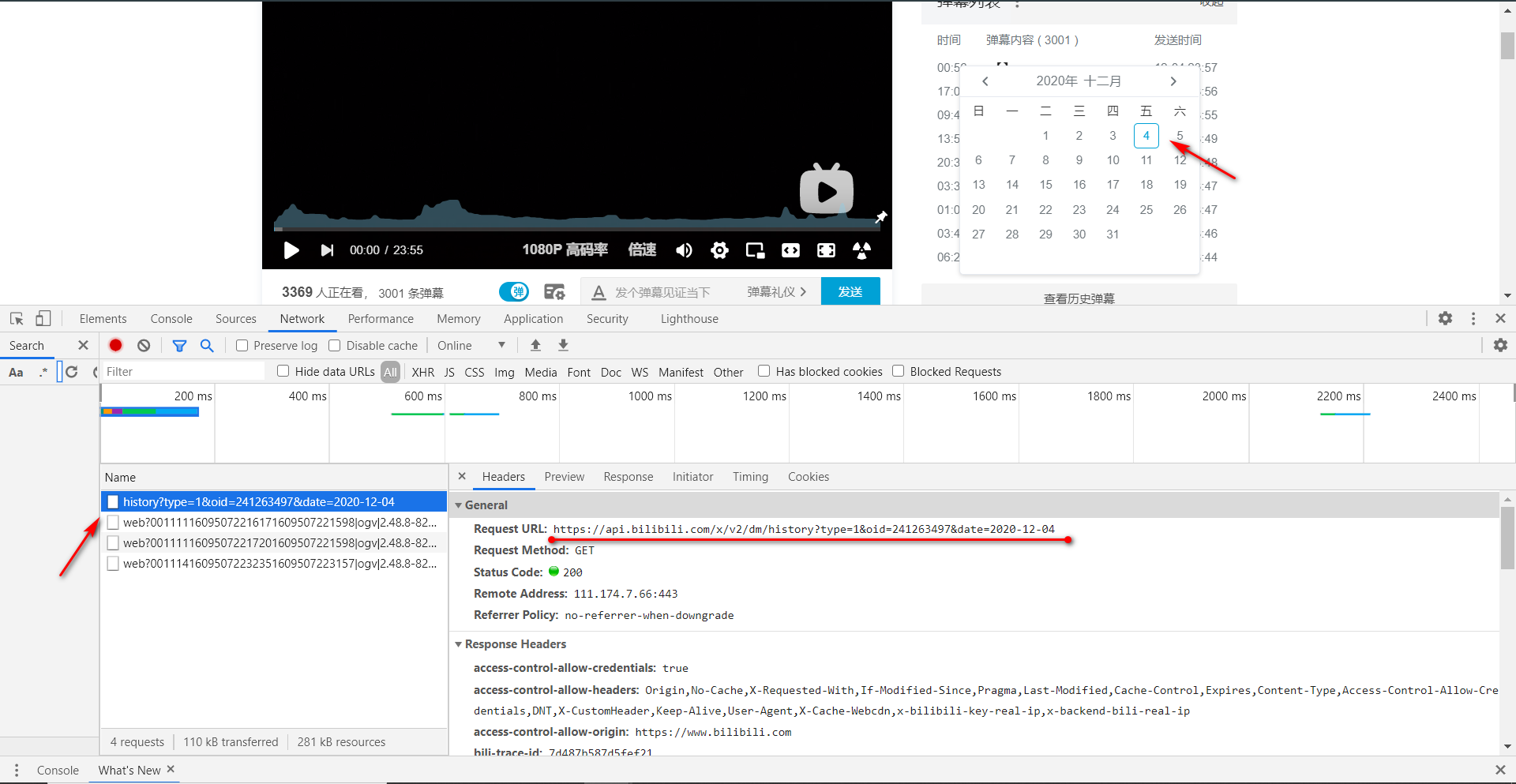
我们对 Request Url 发起请求即可获取历史弹幕。数据类型为 xml ,内容如下。
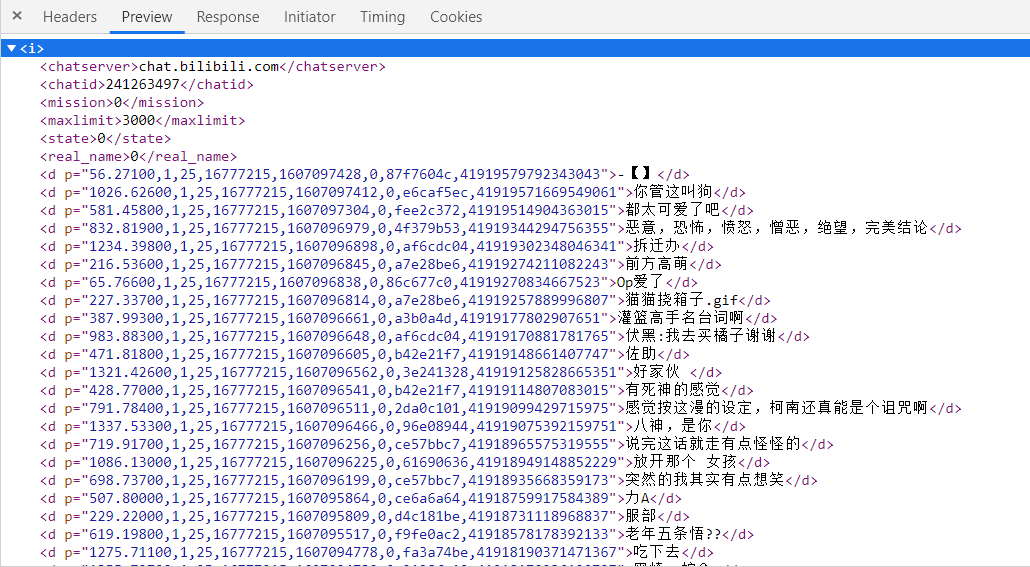
由于在登录后才可以查看历史弹幕,那么我们发起请求时 cookie 也需要添加到 headers 中。思路有了,开始敲代码!
代码设计
获取url列表
Request URL: https://api.bilibili.com/x/v2/dm/history?type=1&oid=241263497&date=2020-12-04
Request URL: https://api.bilibili.com/x/v2/dm/history?type=1&oid=241263497&date=2020-12-05
通过对比请求的 url ,不难发现只有日期是改变的, type 应该是弹幕的类型,oid 为番剧集数的 id ,每一集的 oid 都是不同的。那么我们只需更改 date 的值即可获取 url 列表了。
def get_url_list():
url_list = []
# url模板
url = 'https://api.bilibili.com/x/v2/dm/history?type=1&oid=241263497&date=%s'
# 获取当前日期与开播日期间隔的天数
interval_days = (datetime.now() - datetime(2020, 10, 3)).days
for interval in range(interval_days, -1, -1):
# 获取当前时间减去间隔得到的时间
time = (datetime.now() - timedelta(days=interval)).strftime('%Y-%m-%d')
# 将格式化的url添加到字符串中
url_list.append(url%time)
return url_list
获取响应数据
这里我们使用协程实现异步请求,若使用基于同步的 requests 请求库,效率就相差很多了。为确保获取完整数据以及防止 ip 访问频率过高,在请求时除了添加 headers ,我还使用了代理 ip 来提高爬取的稳定性。
在请求过程中,如果发现数据不对劲,那么极有可能是请求被拦截,你不妨打印一下获取的响应数据。图中所示的响应数据即为请求被拦截。

在爬取时为防止请求被拦截(被识别出是爬虫),添加一个判断条件,当响应码不是 200 时,更换 ip 继续请求,直至成功获得响应数据。当然代理 ip 也有可能请求超时,这时就需要通过捕获异常,更换 ip 继续请求。代码如下。
async def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'cookie': "finger=158939783; buvid3=942BBE8D-D7FB-4454-A483-E1C11686D57E155804infoc; LIVE_BUVID=AUTO2615719148192115; stardustvideo=1; rpdid=|(k|lmJ|RR~u0J'ul~umuR)ku; im_notify_type_406471840=0; CURRENT_FNVAL=80; CURRENT_QUALITY=112; _uuid=49B9C403-6E0C-AEED-F106-EB07E720DA8E77792infoc; blackside_state=0; fingerprint3=1cdc68f9c484657ac6a71df190afb556; sid=arefm2nd; fingerprint=8b41e39ee276d01b2ed70f677e090d9b; buivd_fp=942BBE8D-D7FB-4454-A483-E1C11686D57E155804infoc; fingerprint_s=2cba7720f0fa69a142e39118d29b55b5; bp_article_offset_406471840=474805593736841983; bp_t_offset_406471840=474850961478201127; PVID=1; buvid_fp=942BBE8D-D7FB-4454-A483-E1C11686D57E155804infoc; buvid_fp_plain=6406A16C-F786-4F63-B253-FE49CA5CAEA6143077infoc; bfe_id=fdfaf33a01b88dd4692ca80f00c2de7f; DedeUserID=406471840; DedeUserID__ckMd5=b61a313dfd873915; SESSDATA=9a671851%2C1625047384%2C542f9*11; bili_jct=475eaa698b53f2bc408cb650b2e0aaeb; bp_video_offset_406471840=475267392923742025"
}
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
try:
async with session.get(url=url, proxy='http://' + choice(proxy_list), headers=headers, timeout=8) as response:
# 更改相应数据的编码格式
response.encoding = 'utf-8'
# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。
page_text = await response.text()
# 未成功获取数据时,更换ip继续请求
if response.status != 200:
continue
print(f"{url.split('=')[-1]}爬取完成!")
break
except:
# 捕获异常,继续请求
continue
return save_to_csv(page_text)
数据保存
获取了响应数据,我们通过正则提取出我们需要的部分进行保存即可。这里,为了方便之后数据分析,我将提取的数据保存到 DataFrame ,简单的处理后保存为 csv 文件。代码如下。
def save_to_csv(page_text):
# 正则获取相关弹幕信息
other_data = re.findall('<d p="(.*?)">', page_text)
comment = re.findall('<d p=".*?">(.*?)</d>', page_text)
# 创建dataframe保存数据
df = pd.DataFrame(columns=['other_data', 'date', 'comment'])
df['other_data'] = other_data
df['comment'] = comment
df['date'] = df['other_data'].str.split(',').str[4]
df['date'] = pd.to_datetime(df['date'], unit='s')
df.to_csv(r'C:\Users\pc\Desktop\bilibili.csv', index=False, mode='a')
print('成功保存:' + str(len(df)) + '条')
完整代码
# -*- coding: utf-8 -*-
'''
作者 : 丁毅
开发时间 : 2020/12/31 15:13
'''
from datetime import datetime, timedelta
from 爬虫.proxy_pool.get_IP_fromdb import proxydb
import pandas as pd
import re
import aiohttp
import asyncio
from random import sample,choice
pro = proxydb('127.0.0.1', 3306, 'root', 'password')
proxy_list = pro.get_IP_fromdb()
def get_url_list():
url_list = []
# url模板
url = 'https://api.bilibili.com/x/v2/dm/history?type=1&oid=241263497&date=%s'
# 获取当前日期与开播日期间隔的天数
interval_days = (datetime.now() - datetime(2020, 10, 3)).days
for interval in range(interval_days, -1, -1):
# 获取当前时间减去间隔得到的时间
time = (datetime.now() - timedelta(days=interval)).strftime('%Y-%m-%d')
# 将格式化的url添加到字符串中
url_list.append(url%time)
return url_list
async def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'cookie': "finger=158939783; buvid3=942BBE8D-D7FB-4454-A483-E1C11686D57E155804infoc; LIVE_BUVID=AUTO2615719148192115; stardustvideo=1; rpdid=|(k|lmJ|RR~u0J'ul~umuR)ku; im_notify_type_406471840=0; CURRENT_FNVAL=80; CURRENT_QUALITY=112; _uuid=49B9C403-6E0C-AEED-F106-EB07E720DA8E77792infoc; blackside_state=0; fingerprint3=1cdc68f9c484657ac6a71df190afb556; sid=arefm2nd; fingerprint=8b41e39ee276d01b2ed70f677e090d9b; buivd_fp=942BBE8D-D7FB-4454-A483-E1C11686D57E155804infoc; fingerprint_s=2cba7720f0fa69a142e39118d29b55b5; bp_article_offset_406471840=474805593736841983; bp_t_offset_406471840=474850961478201127; PVID=1; buvid_fp=942BBE8D-D7FB-4454-A483-E1C11686D57E155804infoc; buvid_fp_plain=6406A16C-F786-4F63-B253-FE49CA5CAEA6143077infoc; bfe_id=fdfaf33a01b88dd4692ca80f00c2de7f; DedeUserID=406471840; DedeUserID__ckMd5=b61a313dfd873915; SESSDATA=9a671851%2C1625047384%2C542f9*11; bili_jct=475eaa698b53f2bc408cb650b2e0aaeb; bp_video_offset_406471840=475267392923742025"
}
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
try:
async with session.get(url=url, proxy='http://' + choice(proxy_list), headers=headers, timeout=8) as response:
# 更改相应数据的编码格式
response.encoding = 'utf-8'
# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。
page_text = await response.text()
# 未成功获取数据时,更换ip继续请求
if response.status != 200:
continue
print(f"{url.split('=')[-1]}爬取完成!")
break
except:
# 捕获异常,继续请求
continue
return save_to_csv(page_text)
def save_to_csv(page_text):
# 正则获取相关弹幕信息
other_data = re.findall('<d p="(.*?)">', page_text)
comment = re.findall('<d p=".*?">(.*?)</d>', page_text)
# 创建dataframe保存数据
df = pd.DataFrame(columns=['other_data', 'date', 'comment'])
df['other_data'] = other_data
df['comment'] = comment
df['date'] = df['other_data'].str.split(',').str[4]
df['date'] = pd.to_datetime(df['date'], unit='s')
df.to_csv(r'C:\Users\pc\Desktop\bilibili.csv', index=False, mode='a')
print('成功保存:' + str(len(df)) + '条')
async def main(loop):
# 获取url列表
url_list = get_url_list()
# 创建任务对象并添加岛任务列表中
tasks = [loop.create_task(get_page(url)) for url in url_list]
# 挂起任务列表
await asyncio.wait(tasks)
if __name__=='__main__':
start = datetime.now()
# 修改事件循环的策略
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
# 创建事件循环对象
loop = asyncio.get_event_loop()
# 将任务添加到事件循环中并运行循环直至完成
loop.run_until_complete(main(loop))
# 关闭事件循环对象
loop.close()
print("总耗时:", datetime.now() - start)
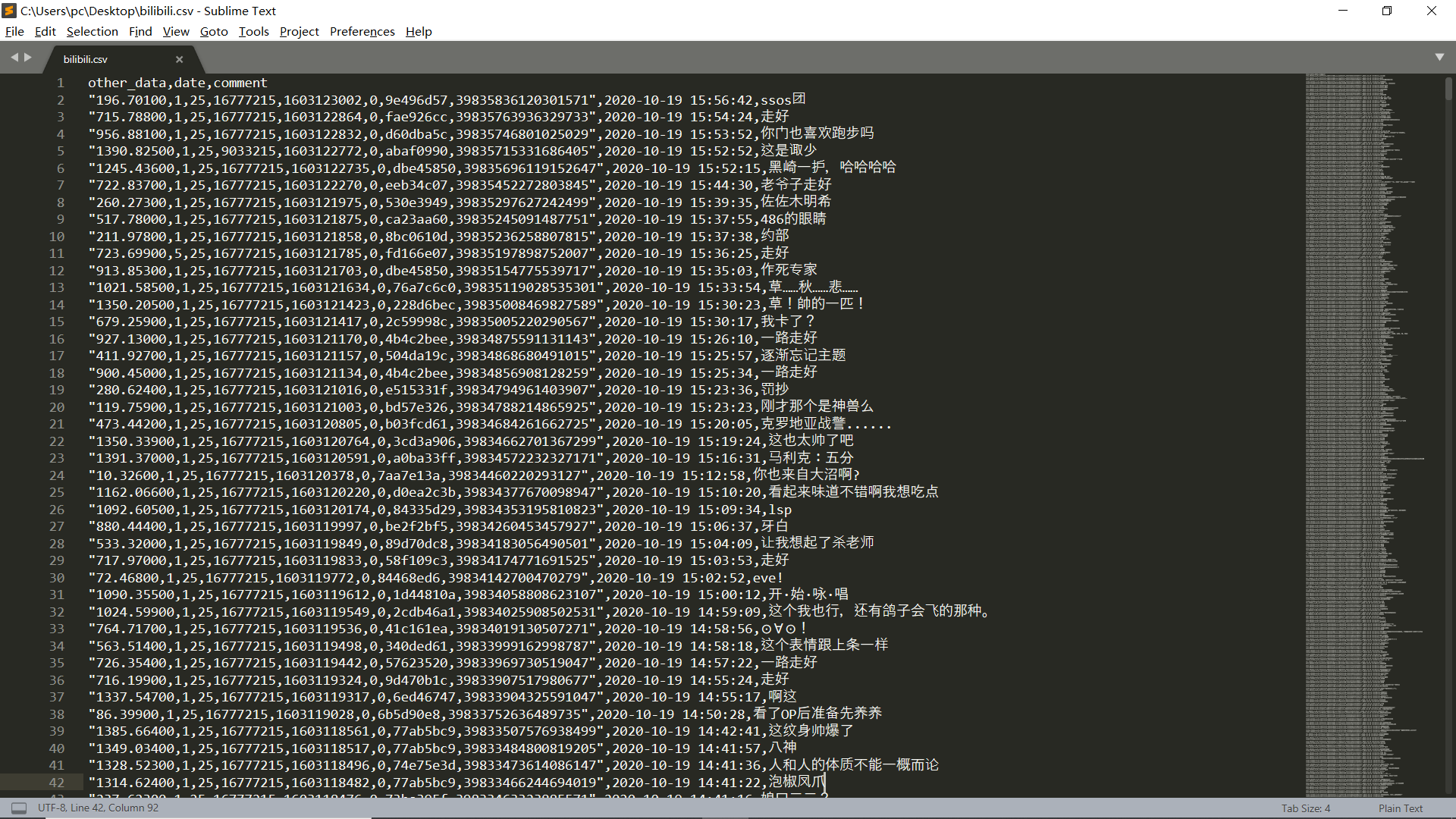
结果截图:

bilibili.csv 文件
总结
由于中途请求多次被拦截,代理 ip 也更换了很多次,同时 ip 的响应速度有点慢(自己网上爬的代理),整个爬取时间还是有点长,但相比于 requests 肯定还是要快很多的。之后有时间简单分析一下数据,看看弹幕中一些大家关心的话题。
对于刚入门 Python 或是想要入门 Python 的小伙伴,可以通过 个人简介 联系作者哦!一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。

- 点赞
- 收藏
- 关注作者
评论(0)