女友忽然欲买文胸,但不知何色更美,Python解之

情景再现
今日天气尚好,女友忽然欲买文胸,但不知何色更美,遂命吾剖析何色买者益众,为点议,事后而奖励之。
本文关键词
协程并发😊、IP被封😳、IP代理😏、代理被封😭、一种植物🌿
挑个“软柿子”
打开京东,直接搜 【文胸】,挑个评论最多的
进入详情页,往下滑,可以看到商品介绍啥的,同时商品评价也在这里。

接下来重头戏,F12 打开 开发者工具,选择 Network,然后点击全部评价,抓取数据包。
将 url 打开,发现确实是评论数据。

单页爬取
那我们先写个小 demo 来尝试爬取这页的代码,看看有没有什么问题。
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
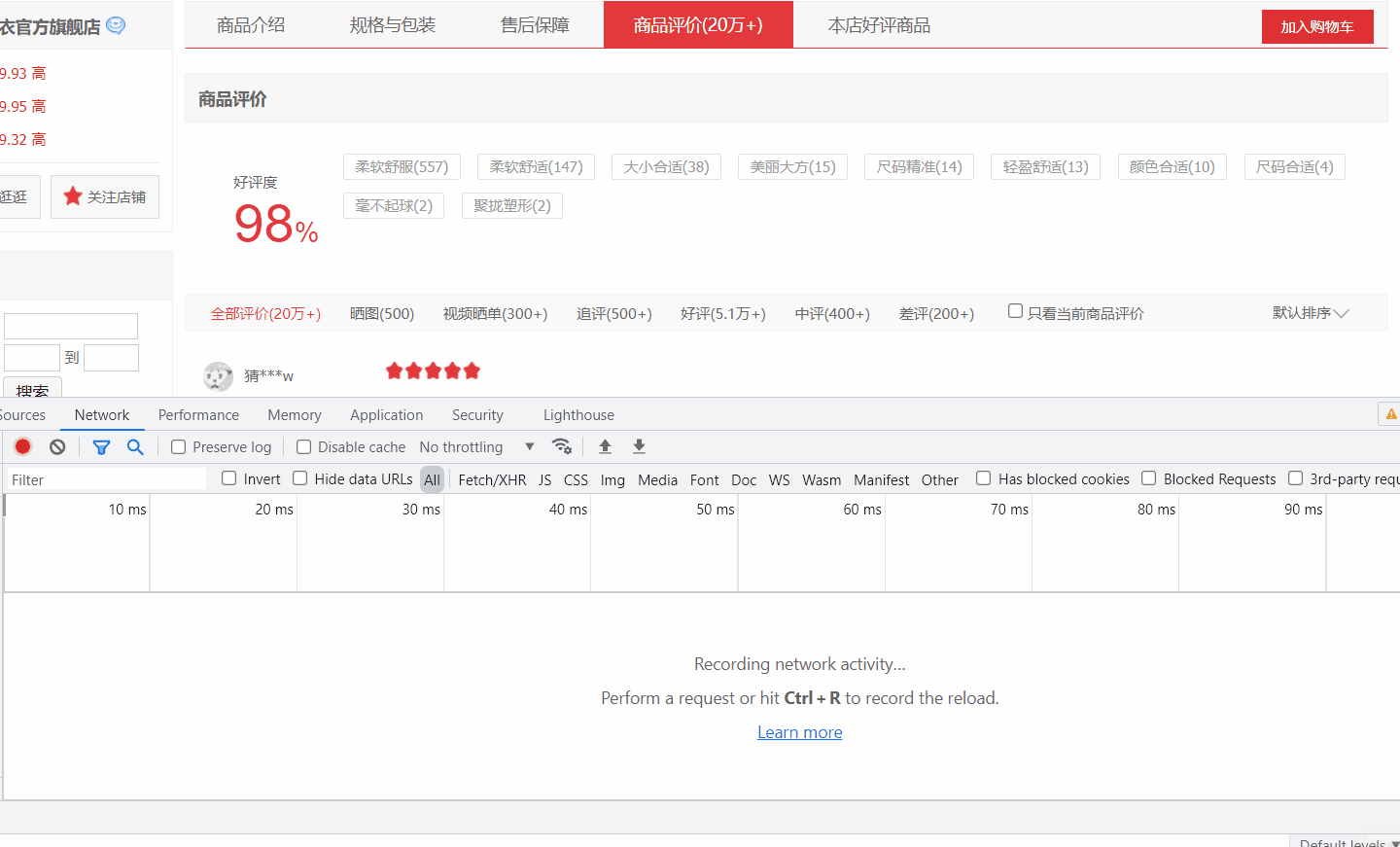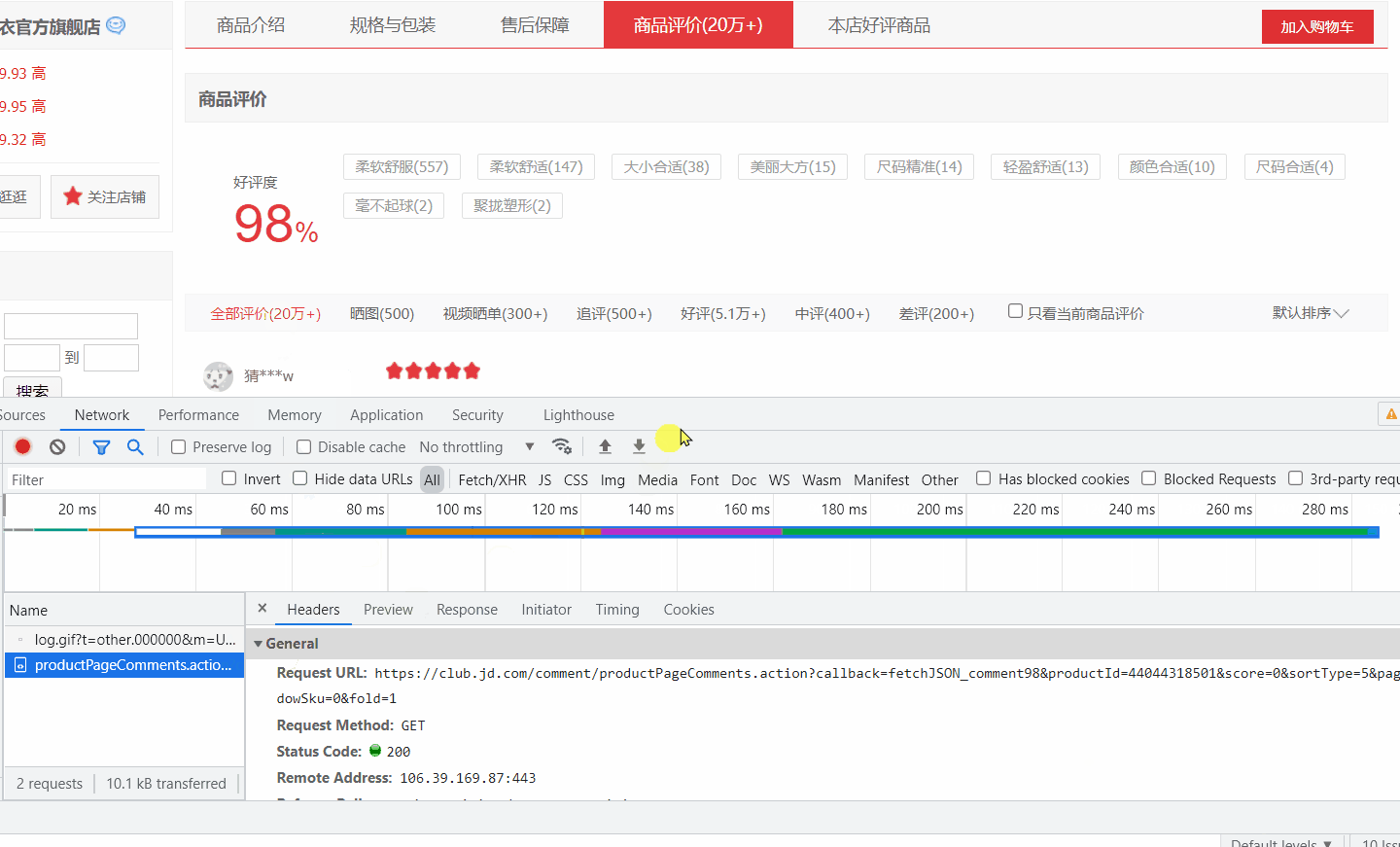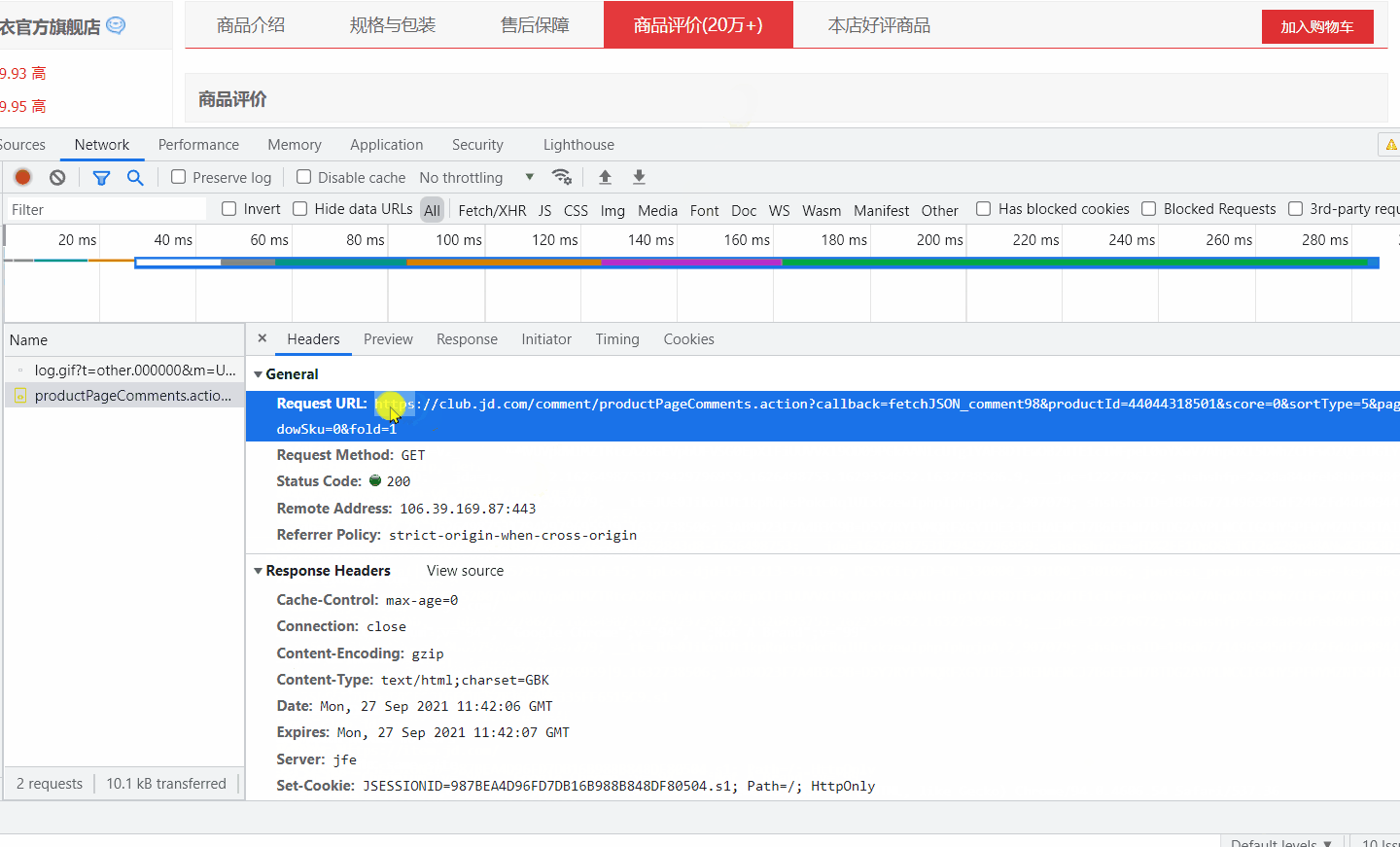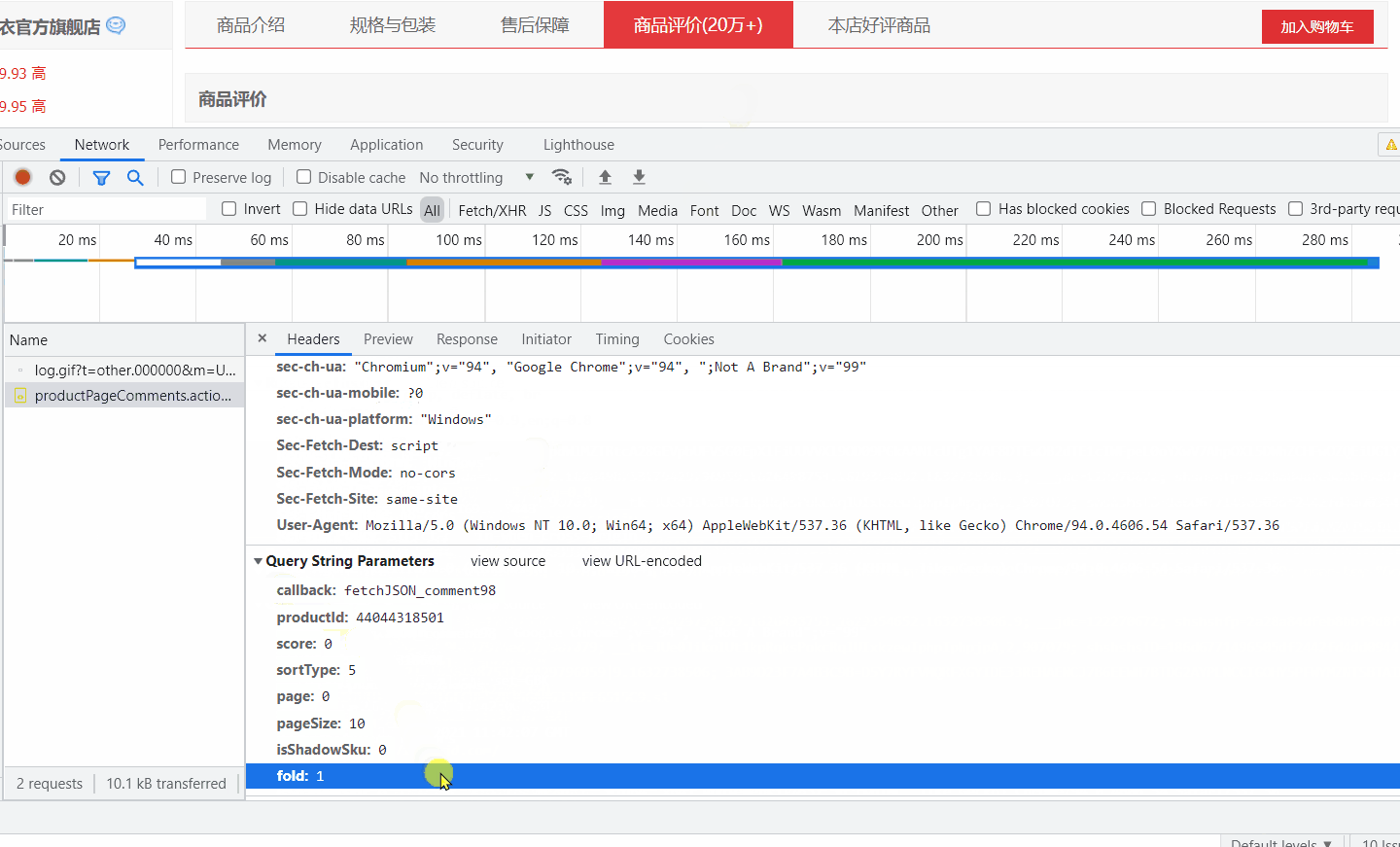
params = {
'callback':'fetchJSON_comment98',
'productId':'35152509650',
'score':'0',
'sortType':'6',
'page': '5',
'pageSize':'10',
'isShadowSku':'0',
'rid':'0',
'fold':'1'
}
url = 'https://club.jd.com/comment/productPageComments.action?'
page_text = requests.get(url=url, headers=headers, params=params).text
page_text

数据处理
数据是获取了,但前面多了一些没用的字符(后面也有),很明显不能直接转成 json 格式,需要处理一下。
page_text = page_text[20: len(page_text) - 2]
data = json.loads(page_text)
data

现在数据格式处理好了,可以上手解析数据,提取我们所需要的部分。这里我们只提取 id(评论id)、color(产品颜色)、comment(评价)、time(评价时间)。
import pandas as pd
df = pd.DataFrame({'id': [],
'color': [],
'comment': [],
'time': []})
for info in data['comments']:
df = df.append({'id': info['id'],
'color': info['productColor'],
'comment': info['content'],
'time': info['creationTime']},
ignore_index=True)
df

翻页操作
那么接下来就要寻找翻页的关键了,下面用同样的方法获取第二页、第三页的url,进行对比。

简单分析一下,page 字段是页数,翻页会用到,值得注意的是 sortType,字面意思是排序类型,猜测排序方式可能是:热度、时间等。经过测试发现 sortType=5 肯定不是按时间排序的,应该是热度,我们要获取按时间排序的,这样后期比较好处理,然后试了几个值,最后确定当 sortType=6 时是按评价时间排序。图中最后还有个 rid=0 ,不清楚什么作用,我爬取两个相同的url(一个加 rid 一个不加),测试结果是相同的,所以不用管它。
撸代码
先写爬取结果:开始想爬 10000 条评价,结果请求过多IP凉了,从IP池整了丶代理,也没顶住,拼死拼活整了1000条,时间不够,如果时间和IP充足,随便爬。经过测试发现这个IP封锁时间不会超过一天,第二天我跑了一下也有数据。下面看看主要的代码。
主调度函数
设置爬取的 url 列表,windows 环境下记得限制并发量,不然报错,将爬取的任务添加到 tasks 中,挂起任务。
async def main(loop):
# 获取url列表
page_list = list(range(0, 1000))
# 限制并发量
semaphore = asyncio.Semaphore(500)
# 创建任务对象并添加到任务列表中
tasks = [loop.create_task(get_page_text(page, semaphore)) for page in page_list]
# 挂起任务列表
await asyncio.wait(tasks)
页面抓取函数
抓取方法和上面讲述的基本一致,只不过换成 aiohttp 进行请求,对于SSL证书的验证也已设置。程序执行后直接进行解析保存。
async def get_page_text(page, semaphore):
async with semaphore:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
params = {
'callback': 'fetchJSON_comment98',
'productId': '35152509650',
'score': '0',
'sortType': '6',
'page': f'{page}',
'pageSize': '10',
'isShadowSku': '0',
# 'rid': '0',
'fold': '1'
}
url = 'https://club.jd.com/comment/productPageComments.action?'
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
try:
async with session.get(url=url, proxy='http://' + choice(proxy_list), headers=headers, params=params,
timeout=4) as response:
# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。
page_text = await response.text()
# 未成功获取数据时,更换ip继续请求
if response.status != 200:
continue
print(f"第{page}页爬取完成!")
break
except Exception as e:
print(e)
# 捕获异常,继续请求
continue
return parse_page_text(page_text)
解析保存函数
将 json 数据解析以追加的形式保存到 csv 中。
def parse_page_text(page_text):
page_text = page_text[20: len(page_text) - 2]
data = json.loads(page_text)
df = pd.DataFrame({'id': [],
'color': [],
'comment': [],
'time': []})
for info in data['comments']:
df = df.append({'id': info['id'],
'color': info['productColor'],
'comment': info['content'],
'time': info['creationTime']},
ignore_index=True)
header = False if Path.exists(Path('评价信息.csv')) else True
df.to_csv('评价信息.csv', index=False, mode='a', header=header)
print('已保存')
可视化
颜色分布
排名前三分别是灰粉色、黑色、裸感肤色,多的不说,自己体会哈。

评价词云图
可以看出评价的关键词大多是对上身感觉的一些描述,穿着舒服当然是第一位的~

完结撒花,该向女朋友汇报工作了~
对于刚入门 Python 或是想要入门 Python 的小伙伴,可以通过作者个人主页内的简介联系作者哦!一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。

- 点赞
- 收藏
- 关注作者
评论(0)