华为云DevOps系列之 —— 持续运维与监控(五)微服务治理

【摘要】 华为云DevOps系列之 —— 持续运维与监控(五)微服务治理
- 微服务架构的流行,给应用开发带来了灵活性、扩展性、伸缩性以及高可用性等优势,但与此同时,其复杂性也给运维和监控带来了很大的挑战:海量日志数据如何处理,服务如何追踪,如何高效定位故障缩短故障时长等等
- 对于一个庞大的微服务应用来讲,当一个负载过载或者是出现了一些问题的时候,我们怎么能保证它的失败不会影响到其他应用的运行,这就是通过
微服务治理来进行的
微服务治理
- 微服务
- 一种构建应用的架构方案
- 可以将应用拆分成多个核心功能
- 每个功能都被称为一项服务,可以单独构建和部署,这意味着各项服务在工作(和出现故障)时不会相互影响
- 运维监控挑战:这意味着一个应用下面可能会有成百上千个微服务需要治理,如果我们对他们分别运维监控的话,无疑这是个非常庞大且复杂的工作
- 系统复杂性上升
- 服务间依赖复杂
- 监控更复杂的系统
- 定位问题更麻烦
- 举个例子:我们在实现一个功能的时候,涉及到一些服务之间的调用,在定位问题的时候,我们并不知道这一个问题它出现在调用链中的哪一个服务里面,或者说如果这个调用里面的某一个服务出现了问题,怎么样能够自动地将这个问题所带来的危害降低为零(或降到最小)
微服务治理 —— 能力列表
- 服务发现
- 如何通过一个标志来获取服务列表,并且这个服务列表是能够随着服务的状态而动态变更的
- 负载均衡
- 将工作负载分布到多个服务器来提高网站、应用、数据库或其他服务的性能和可靠性
- 灰度发布
- 新功能上线时,能够实现未上线功能平稳过渡上线的一种方式
- 服务熔断与容错
- 下游服务因访问压力过大而响应异常时,为保证系统可用性,上游服务可暂停调用下游服务
- 服务降级
- 服务超出上限阈值时,拒绝部分请求或者将一些不重要/不紧急的服务进行延迟或暂停
- 服务限流
- 监控应用流量指标,当达到指定阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮
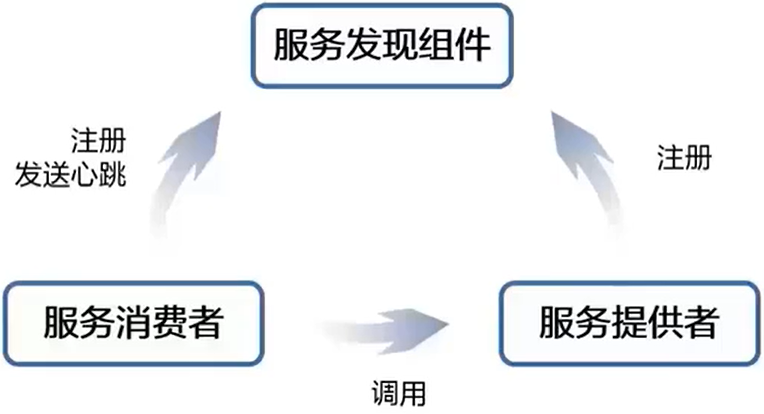
服务发现
- 服务治理领域最重要的问题就是服务发现与注册
- 在一个微服务应用中,一组运行的服务实例是动态变化的,实例有动态分配的网络地址,因此,为了使得客户端能够向服务发起请求,必须要有服务发现机制,在此基础之上进行微服务的其他治理功能
- 首先要把服务的消费者/提供者 IP 注册到服务发现组件,消费者向提供者调用服务的时候有两种方式

客服端服务发现:客户端通过查询服务注册中心,获取可用的服务的实际网络地址(IP 和端口),然后通过负载均衡算法来选择一个可用的服务实例,并将请求发送至该服务- 优点:架构简单,扩展灵活,方便实现负载均衡功能
- 缺点:强耦合,有一定开发成本
服务端服务发现:客户端向 load balancer 发送请求,load balancer 查询服务注册中心找到可用的服务,然后转发请求到该服务上。和客户端发现一样,服务都要到注册中心进行服务注册和注销- 优点:服务的发现逻辑对客户端是透明的
- 缺点:需要额外部署和维护高可用的负载均衡器
- 服务注册中心
- 服务发现的核心
- 保存可用服务实例的网址(IP Address & Port)
- 可用性和实时更新功能
- 服务注册方式
Self-Registration:服务实例必须自己主动的到注册中心注册和注销,比如可以使用 heartbeat 机制来实现Third-Party-Registration:通过其他组件来实现服务注册功能
负载均衡
概述
- 在分布式系统中,负载均衡(Load Balancing)是一种将任务分派到多个服务端进程的方法
- 负载均衡保证了分布式服务器中,不会有某一个服务负载过高
- 通过将任务均匀的分派到各个服务器,负载均衡可以提高应用的响应速度和可用性
使用场景
- 一、应用于高访问量的业务
- 如果应用访问量很高,您可以通过配置监听规则将流量分发到不同的 ECS 实例上。此外,您可以使用会话保持功能将同一客户端的请求转发到同一台后端 ECS,提高访问效率
- 二、横向扩张系统
- 可以根据业务发展的需要,通过随时添加和移除 ECS 实例来扩展应用系统的服务能力,适用于各种 Web 服务器和 App 服务器
- 三、消除单点故障
- 可以在负载均衡实例下添加多台 ECS 实例。当其中一部分 ECS 实例发生故障后,负载均衡会自动屏蔽故障的 ECS 实例,将请求分发给正常运行的 ECS 实例,保证应用系统仍能正常工作
- 四、同城容灾(多可用区容灾)
- 五、跨地域容灾
负载均衡两种方式
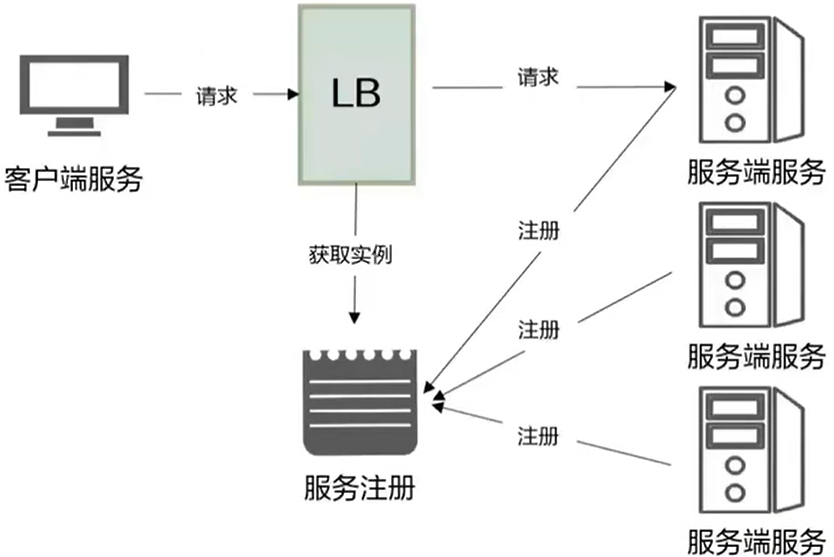
- 服务端负载均衡
- 通过一个负载均衡器和服务注册中心相连,客户端只需要将请求发送给负载均衡器,对于负载均衡器会将请求转发给哪一台服务器,这都是由服务端的负载均衡器来完成的任务,他会向服务中心获取一个当前可以正常执行的服务器,然后从负载均衡器发送请求
- 通过一个负载均衡器和服务注册中心相连,客户端只需要将请求发送给负载均衡器,对于负载均衡器会将请求转发给哪一台服务器,这都是由服务端的负载均衡器来完成的任务,他会向服务中心获取一个当前可以正常执行的服务器,然后从负载均衡器发送请求
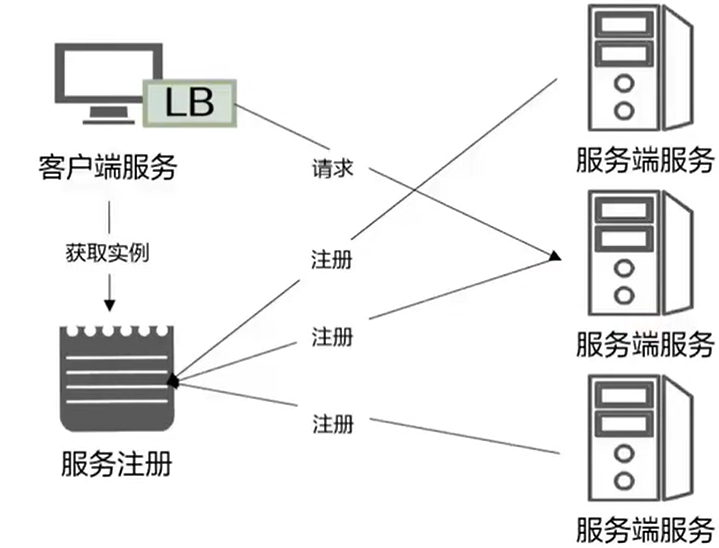
- 客户端的负载均衡
- 客户端自己去服务注册中心获取一个服务端的 IP 的地址,由客户端自己直接连接服务端的服务
- 内置负载均衡策略有:RoundRobin、Random、WeightedResponse、SessionStickiness,默认的是 RoundRobin
灰度发布
什么是灰度发布
- 为保障新特性能平稳上线,可以通过灰度发布功能选择少部分用户试用,降低发布风险
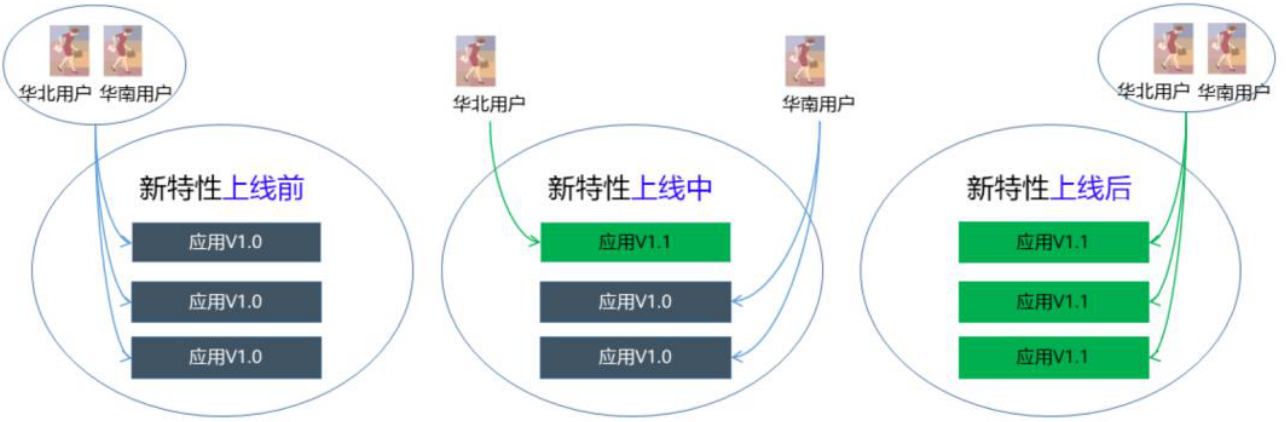
发布策略
- 流量权重
- 比如我们将 80% 的流量固定在 1.0 版本,将 20% 的流量灰度到 2.0 版本,这样我们在 20% 的流量发现灰度的版本可以正常运行起来的时候,我们再把所有的 V1.0 升级到 V2.0
- 比如我们将 80% 的流量固定在 1.0 版本,将 20% 的流量灰度到 2.0 版本,这样我们在 20% 的流量发现灰度的版本可以正常运行起来的时候,我们再把所有的 V1.0 升级到 V2.0
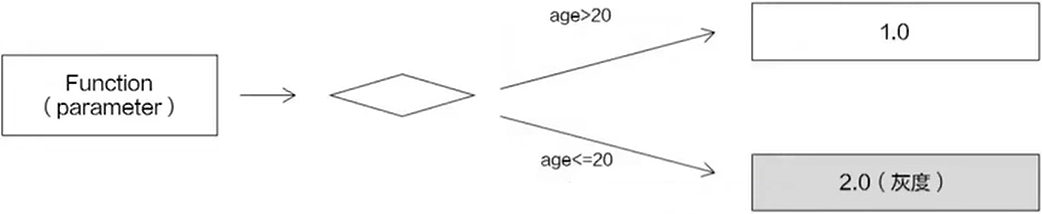
- 自定义参数:根据接口参数进行灰度导流
- 这里我们会对请求的某一个参数进行控制,比如我们将年龄大于 20 岁的保留 1.0 版本,年龄小于 20 岁的使用 2.0 版本(即灰度版本),当在年龄小于 20 的群里里面发现应用可以正常运行的时候,再把所有的 1.0 版本的应用升级到 2.0 版本
- 这里我们会对请求的某一个参数进行控制,比如我们将年龄大于 20 岁的保留 1.0 版本,年龄小于 20 岁的使用 2.0 版本(即灰度版本),当在年龄小于 20 的群里里面发现应用可以正常运行的时候,再把所有的 1.0 版本的应用升级到 2.0 版本

灰度发布案例
- 假设一个系统要新上线一个功能 some-feature,需要用户 Alice 做内部测试后才能完全发布
- 线上正在运行服务 some-feature-A,新部署一个服务 some-feature-B,使用新版本的 Image 和 ConfigMap
- 去负载均衡器页面修改转发规则,新增 header 转发规则将 name=Alice 的流量分配给 some-feature-B,剩余流量给 some-feature-A
- 登录 Alice 用户进行测试,并更新 some-feature-B 的 Image 和 ConfigMap,直至验证通过
- 修改 some-feature-A 的 Image 和 ConfigMap 与 some-feature-B 一致
- 删除负载均衡器上的转发规则,所有流量指向服务 some-feature-A
- 删除服务 some-feature-B
服务限流
什么是服务限流
- 限流:在流量高峰时,可以根据消费者
优先级适当调整流量限制,保护生产者不被流量击垮 - 目的:通过对并发访问/请求进行限速或者一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务(定向到错误页或告知资源没有了)、排队或等待(比如秒杀、评论、下单)、降级(返回兜底数据或默认数据,如商品详情页库存默认有货)

服务限流策略
- 限制总并发数(比如数据库连接池、线程池)
- 限制瞬时并发数(如 nginx 的 limit_conn 模块,用来限制瞬时并发连接数)
- 限制时间窗口内的平均速率(如 Guvav 的 RateLimiter、nginx 的 limit_req 模块,限制每秒的平均速率)
- 其他还有如限制远程接口调用速率、限制 MQ 的消费速率
- 另外还可以根据网络连接数、网络流量、CPU 或者内存负载等来限流
服务熔断与容错
什么是熔断与容错
- 熔断:在某个生产者在指定时间段持续出现故障时,消费者主动断开其连接,如果生产者故障排除,则连接自动恢复
- 容错:在消费者访问生产者在某一个实例失败时,则根据容错策略进行错误处理,如:选择另一个实例重试、按时间间隔持续重试同一实例,或者快速返回失败不重试
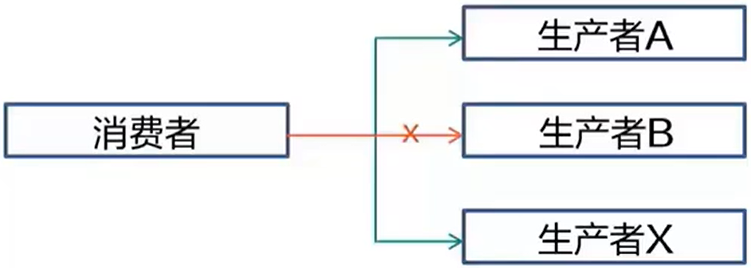
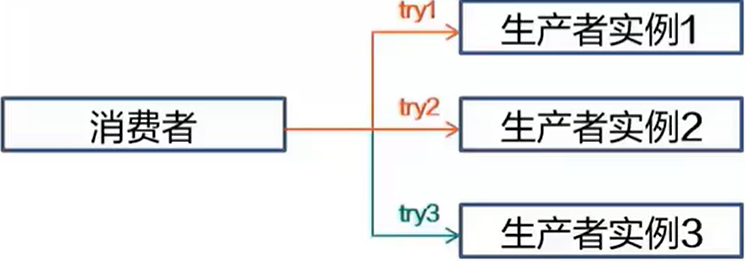
熔断与容错解决的问题
- 对于一个分布式系统,如果某个请求的调用链中的某个服务出现故障,响应变慢,会导致整个链路的响应变慢,请求堆积
- 当这种情况变得越来越严重的时候,占用的资源会越来越多,当到达系统瓶颈时,会造成整个系统崩溃,所有请求都不可用,熔断与容错就是为了解决这个问题
- 熔断可以将问题服务隔离开,令请求可以快速返回
- 待问题服务变为正常状态后,再从熔断状态中恢复过来
- 通过这种机制,我们可以临时断开次要业务路径,保障系统整体的可用性
- 如下图,如果 A 出现了故障,A 要调用 C ,如果 C 出现了故障,调用 A 的时候也可能会出现故障,这样就会造成故障堆积
- 如果我们把实例 C 隔离,在它请求到服务 A 的时候,不去调用服务 C,这样系统就可以保证健康的状态
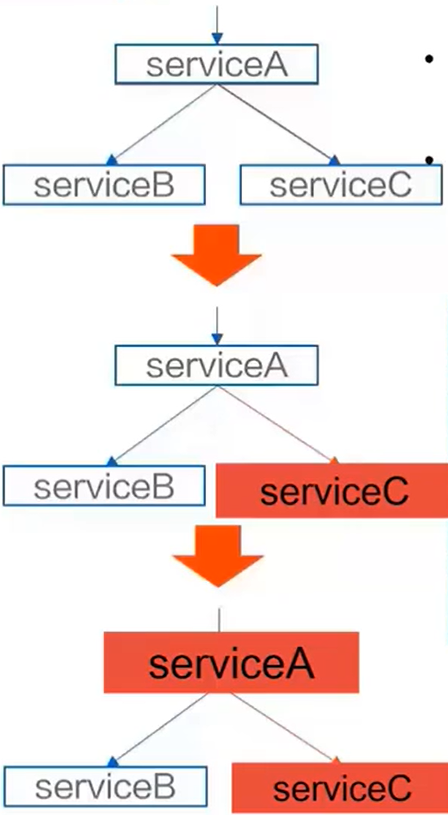
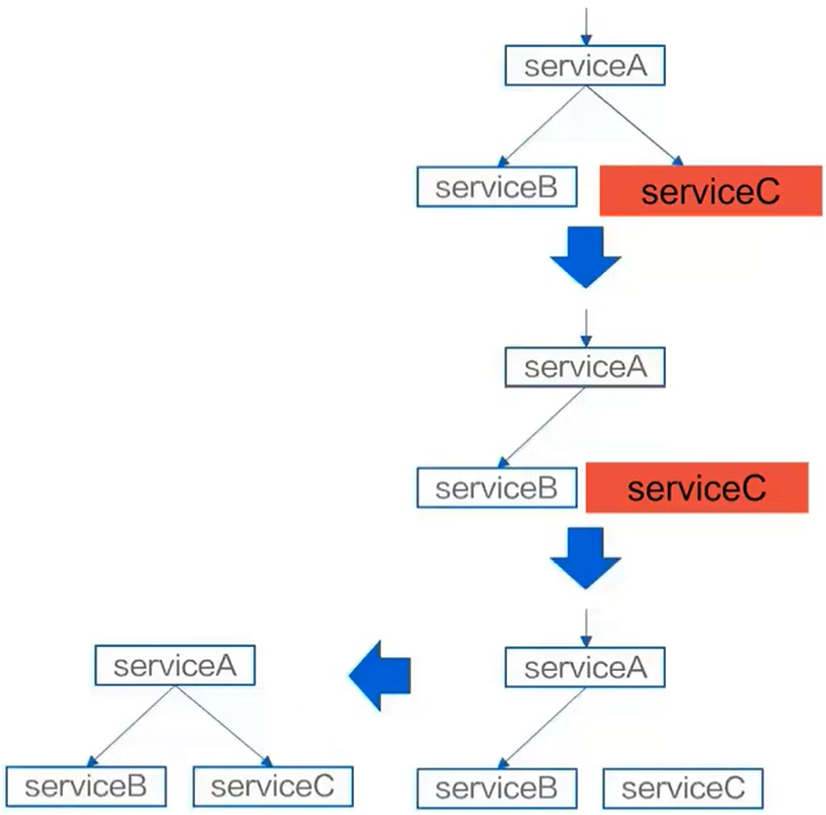
降级
- 降低:在生产者出现故障时,消费者可以主动断开与生产者的连接,以保护消费者避免故障传染,能正常对外提供服务
- 目的:保证重要或基本服务正常运行,非重要服务延迟使用或暂停使用。如果不熔断,很有可能产生雪崩效应

最后,欢迎大家关注我的个人微信公众号 『小小猿若尘』,获取更多IT技术、干货知识、热点资讯。同时,我在公众号中分享了精心整理的一些视频资料(包括 Python全栈教程、AI教程、前端、数据库等),大家回复相应关键词即可获取网盘视频链接,感谢大家的关注😊


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)