华为云DevOps系列之 —— 持续运维与监控(二)运维监控平台概述与云上监控

【摘要】 DevOps系列之 —— 持续运维与监控(二)运维监控平台概述与云上监控
监控平台
监控的目的
- 首先我们看一下以下三个问题:
- 当产品上了规模后,在线上的运行状况十分良好?是否存在性能瓶颈和潜在的 Bug?
- 产品实际运行在产品服务器时占用的内存平均和峰值有多少?是否合理?是否有调优的余地?
- 服务的实际用户流量有多少?相比前段时间是增加了还是减少了?
- 监控的目的一般就是为了解决以上三个问题
- 根据历史监控数据,对未来做出预测
- 发生异常时及时报警,做出相应的应对措施
- 根据监控报警以及定位时间、问题等进行问题的溯源
- 通过可视化图表展示,便于直观的获取异常的定位信息
整体介绍
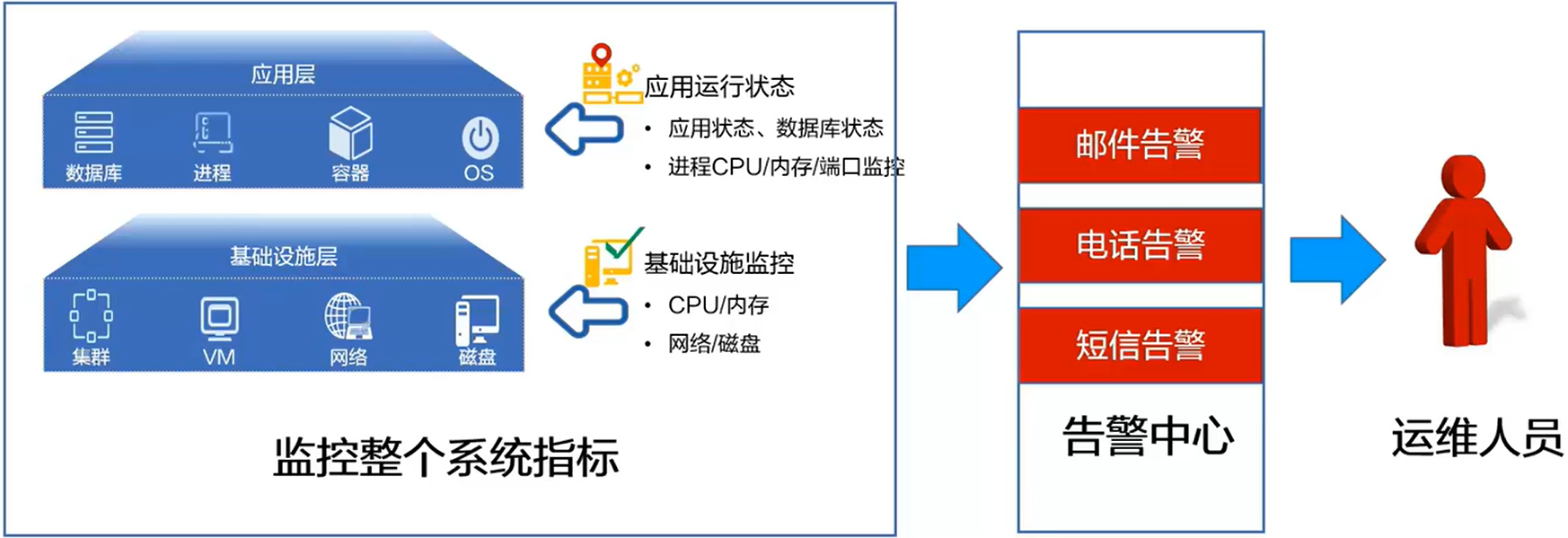
- 一个完整的监控平台需要至少包含两部分,
监控和告警- 监控:使用脚本、工具等方式获取整个系统的不同指标值,涵盖基础设施、应用。获取监控项,比如进程的 CPU/内存,节点的磁盘使用状态等
- 告警:针对每种指标设置告警,一旦指标发生异常,可以通过多种方式告知运维人员及时修复
监控指标
- 监控指标范围要求:
覆盖主机、应用多个维度 - 主机监控指标
- 网络:入方向网络流速、数据包个数、错误包个数等
- 磁盘:磁盘读/写速率、磁盘读/写状态、可用磁盘空间
- 显卡:显存容量、显存使用率、CPU 使用率
- 主机系统:CPU 内核总量、CPU 使用率、可用虚拟内存、NTP 服务状态等
- 应用监控指标
- 进程:CPU 内核总量、CPU 内核占用、CPU 使用率、句柄数、物理内存总量、物理内存使用率、进程状态、虚拟内存总量
- 监控指标周期要求:一般以
1分钟为监控周期,重要的指标需要做到秒级监控,例如 1s/5s 一个采样点
传统运维工具
- 日志
- 监控
Zabbix:适用于任何 IT 基础架构、服务、应用程序和资源的监控解决方案Grafana:跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知Prometheus:开源监控告警解决方案
- 调用链追踪
- 传统运维工具缺陷
- 运维人员技能要求高,配置烦杂,同时需要维护多套系统
- 无法关联分析,虽然指标很多,但需要根据运维经验逐一排查
- 对于 pinpoint 这类分布式追踪系统,学习和使用成本高,并且稳定性较差
主机监控 —— Zabbix
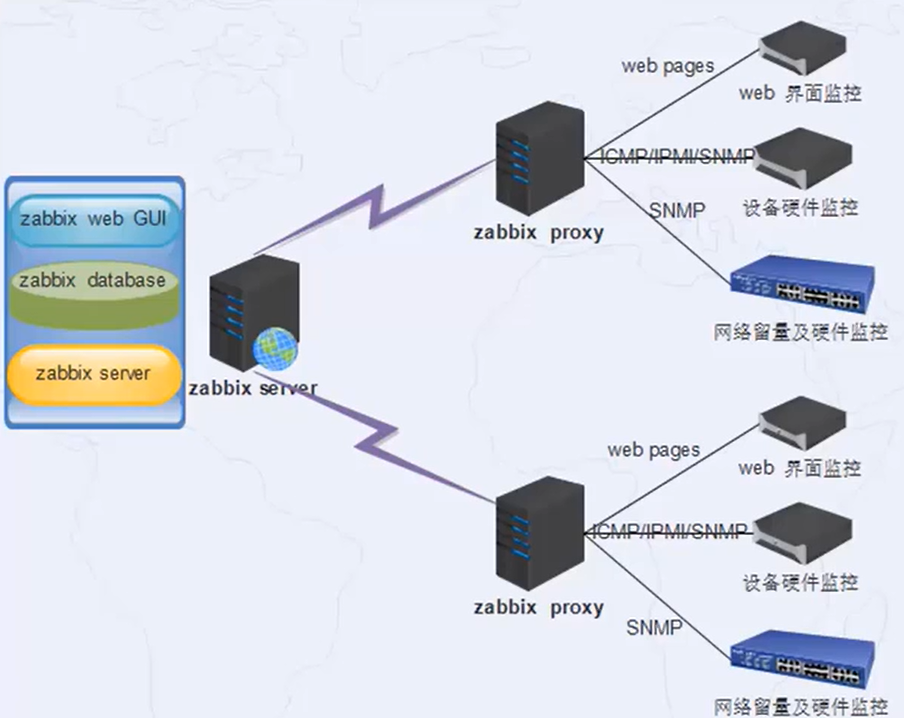
Zabbix是一款常用的监控工具,可以提供监控数据采集- Zabbix 指标采集流程
- 采集器 agentd 需要安装到被监控的主机上,负责定期收集各项数据,并发送到 zabbix server 端,zabbix server 将数据存储到时数据库中,zabbix web 将数据在前端进行展现和绘图
监控平台 —— Prometheus

Prometheus是一套开源的监控、报警、时间序列数据库的组合,最初由 SoundCloud 公司开发。Prometheus 在 2016年加入 CNCF(Cloud Native Computing
Foundation),成为继 Kubernetes 之后的第二个由基金会主持的项目。目前社区非常活跃,有高达 1.4 万个 Star。Prometheus 非常适合监控 Kubernetes- 与一般的监控系统相比,Prometheus 具有如下特点
- 时序数据库存储监控数据能够存储更大量的数据,不依赖于其他存储系统,安装非常简单
- 灵活的查询语言(PromQl)
- 通过基于 HTTP 的 pull 方式采集时序数据,可以通过 Pushgateway 进行时序列数据推送
- 多种可视化和仪表盘支持
Prometheus 架构
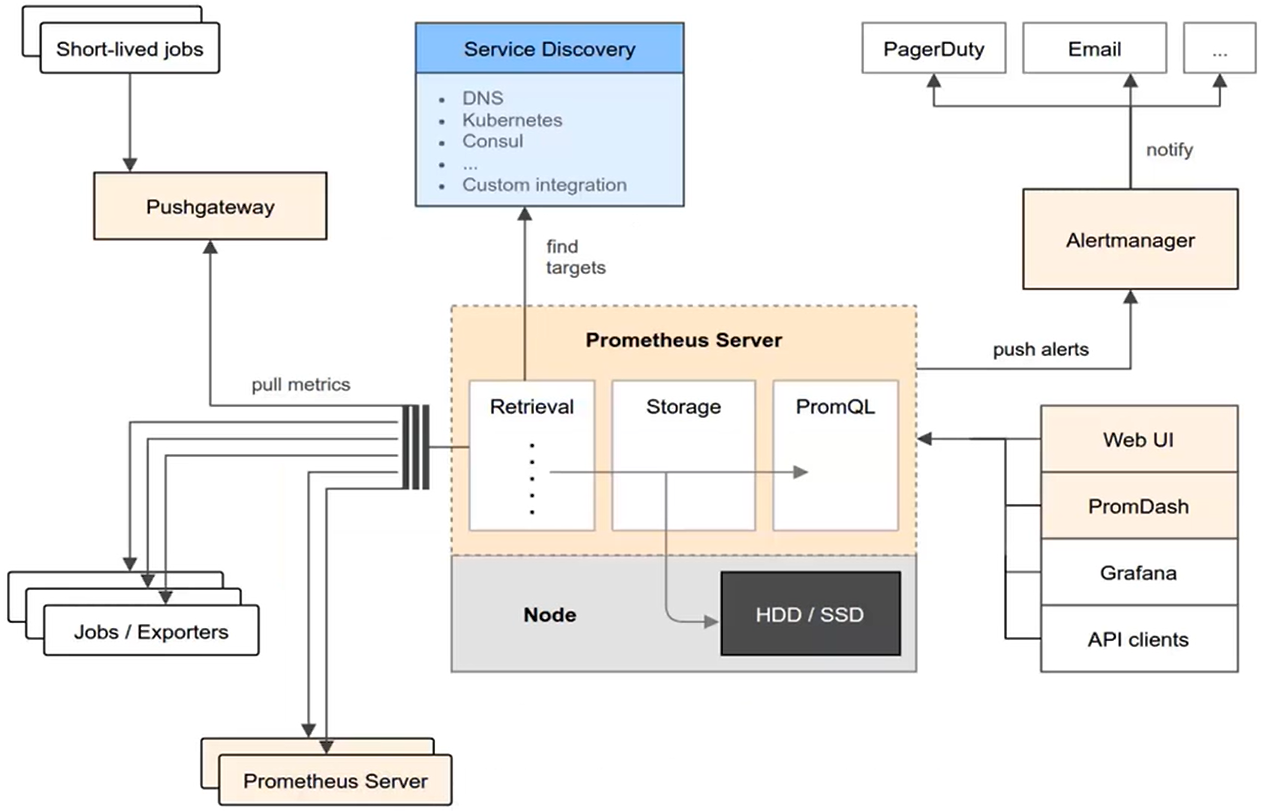
- Prometheus 的重要组成部分是
Prometheus Server,其中又包括Retrieval、Storage、PromQL三部分- Retrieval:负责定时去指定的API上抓取采样指标数据
- Storage:负责将采样数据高效安全地持久化存储到磁盘中
- PromQL:负责提供查询
- Prometheus Server 端会存储所有数据,并对这些数据进行分析,基于规则进行报警
- Prometheus 利用自身的时序数据库,有着非常高效的存储
- Alertmanager 是独立于 Prometheus 之外的一个组件,提供十分灵活的报警方式。另外,可以通过 Web UI、Grafana、API clients 等可视化界面查询数据
- Prometheus支持通过配置文件、文本文件、ZooKeeper、Consul、DNS SRV lookup 等方式指定抓取目标
- Prometheus 是通过主动获取的方式采集数据,但是客户端有两种方式输送数据
- 一种方式是业务服务提供 HTTP 接口,Prometheus 定时从业务服务中获取数据
- 另外一种方式是业务服务推送数据到 Pushgateway,Prometheus 定时从 Pushgateway 中获取数据
监控平台 —— Prometheus+Grafana
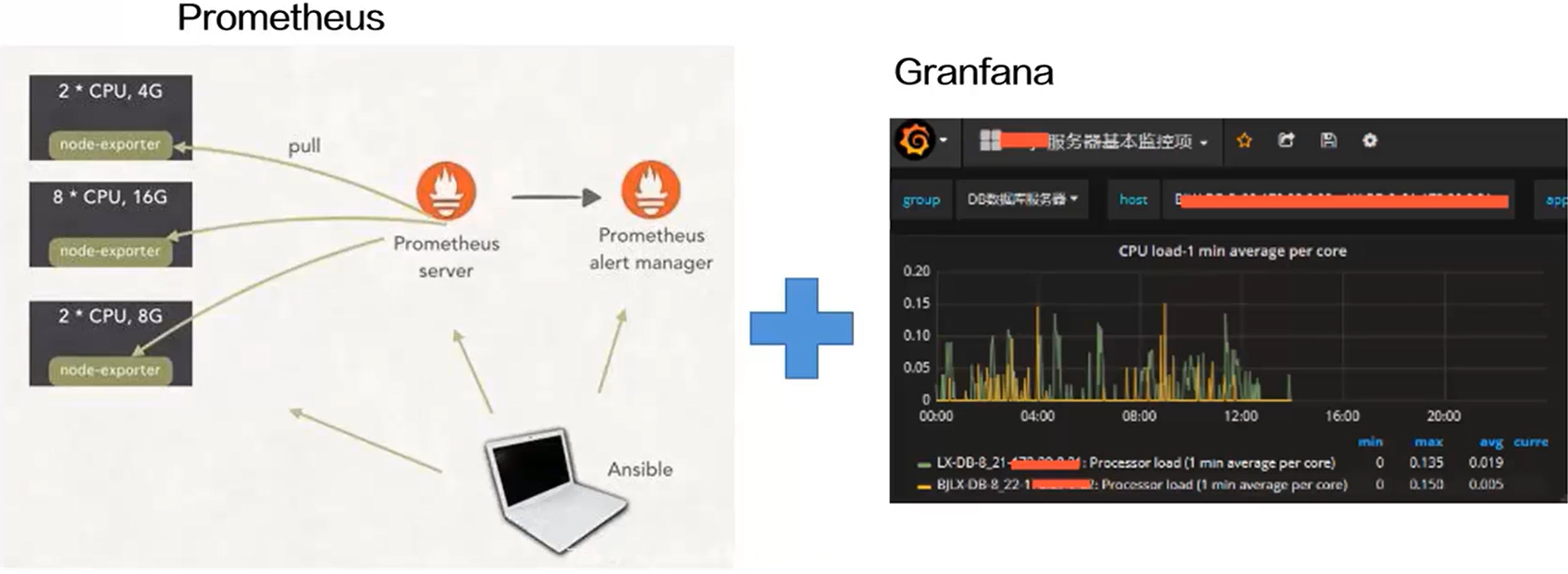
- 主流用法
- prometheus 作为监控指标处理中心,对接 Grafana 进行指标展示
- Prometheus 和 Grafana 是一对完美的组合,把它们集成起来非常简单
容器监控
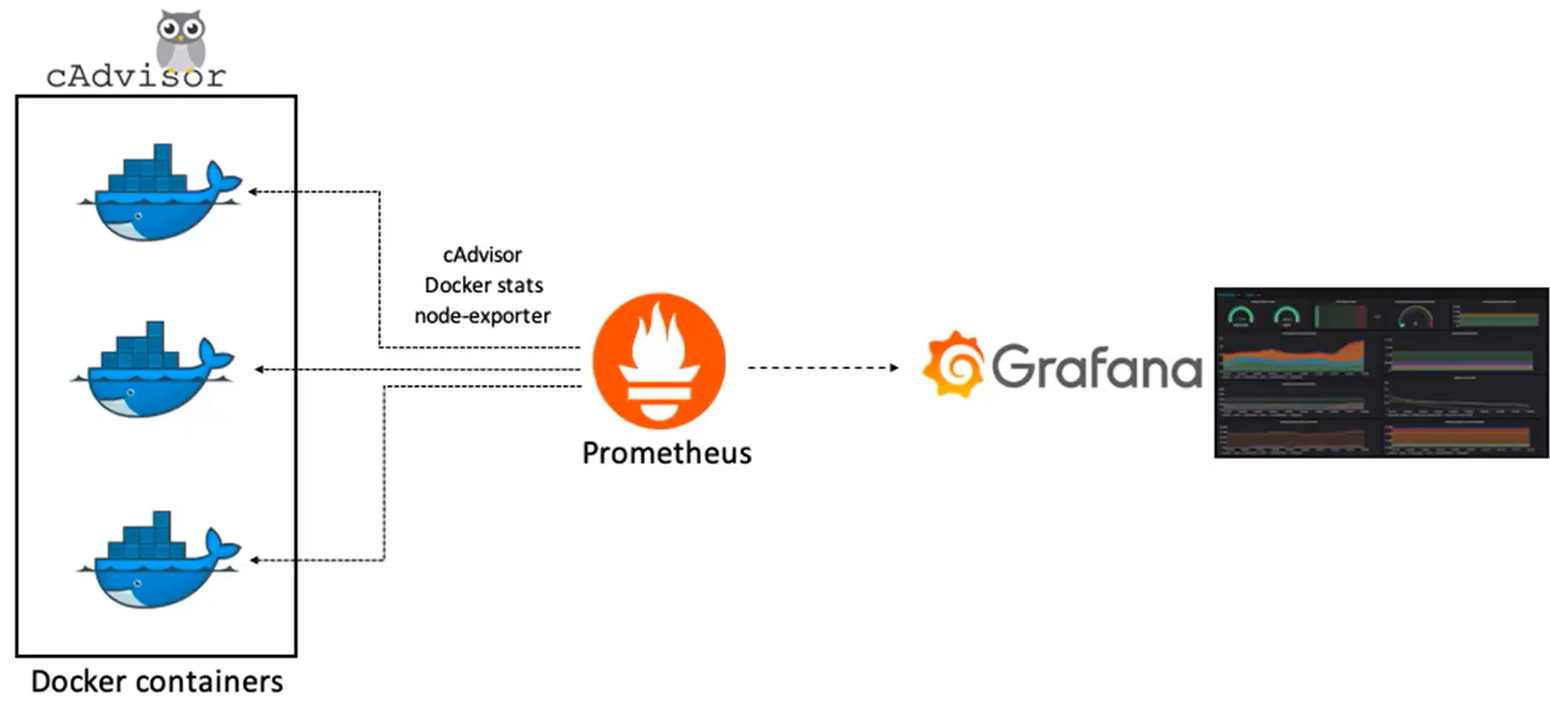
- Prometheus 的重要应用场景是容器的监控
- 比如在 Docker 场景下,它可以通过 node-exporter 等不同的 exporter 把容器中间所有的数据采集到 Prometheus 的后台数据库中,然后对接 Grafana 能够集成 PromQL 等查询语言进行常见指标的查询
传统监控告警
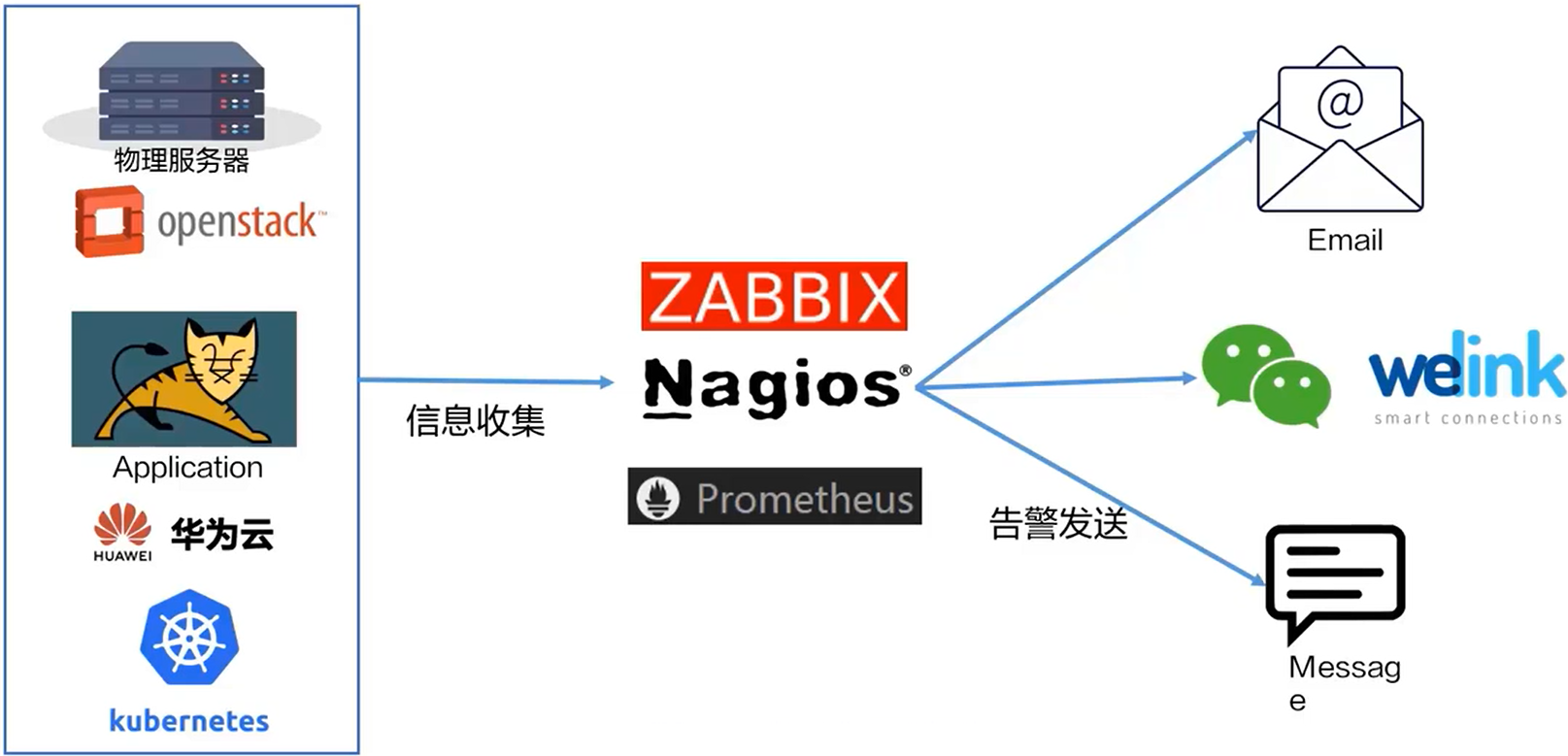
- 如图所示,我们采集了物理服务器、各种应用以及各种云厂商的数据,然后将这些数据放到 Zabbix、Prometheus 中去,同时设置一定的阈值告警,当告警触发的时候,我们可以选择 Email、Messaage 或者是第三方的通讯工具(微信、Welink)进行告警通知
监控视图

- 监控视图是监控系统的重要组成部分。一般情况下,一个监控结果的可视化展示,对于运维人员来说也是非常必要的
- 如上图展示了三种不同产品的界面,包括 Kibana、Zabbix 以及 Grafana,从图中我们可以看到一些重要指标的历史曲线图,然后我们可以把这些指标放到一张图中进行对比,这样方便我们在运维的时候能够及时的发现这些异常的信息
云上运维实践 —— 华为云云上运维解决方案
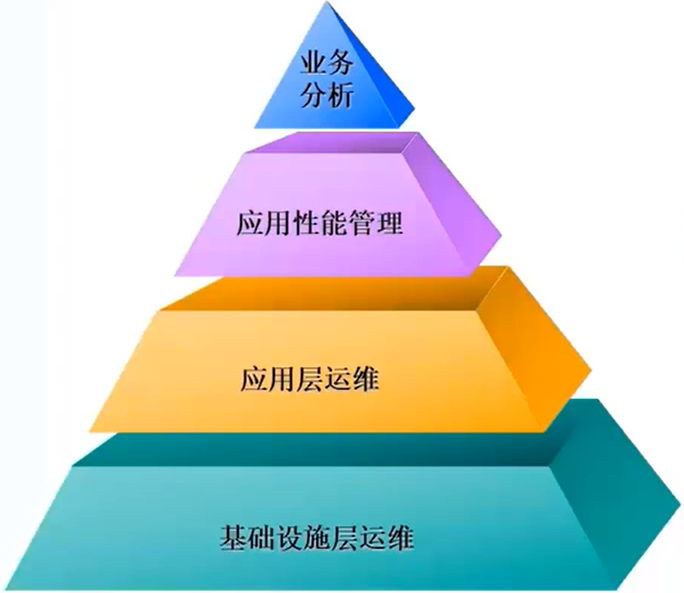
- 华为云云上运维解决方案可以完成
基础设施层、应用层、应用性能层这三层的一站式运维

- 其工作原理是在云服务器上安装采集器和探针
采集器主要用来采集指标、日志、事件等运行、运维数据探针主要是安装在应用中,用来采集应用的调用链、用户体验等数据- 采集器和探针会将基础设施数据、应用数据、用户体验数据采集并分析处理,之后通过监控指标、日志、拓扑、事务、调用链等展现出来,实现资源、云上业务、用户体验全面运维
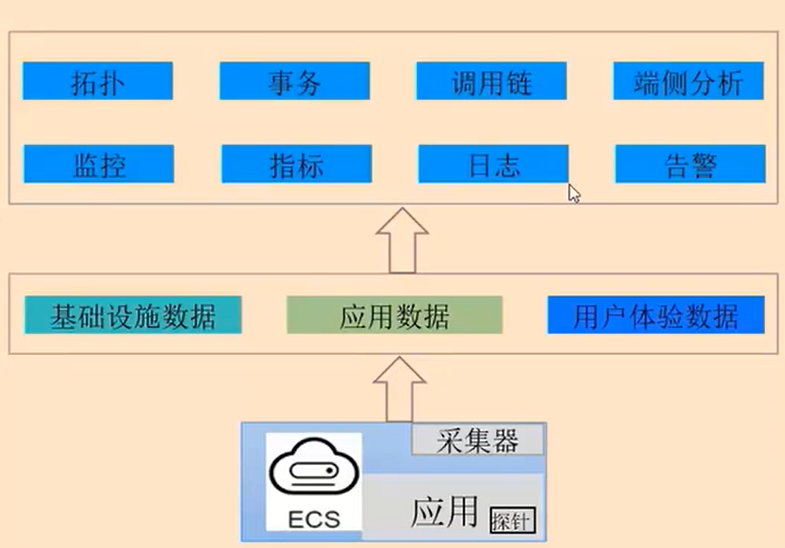
华为云 AOM 运维管理平台
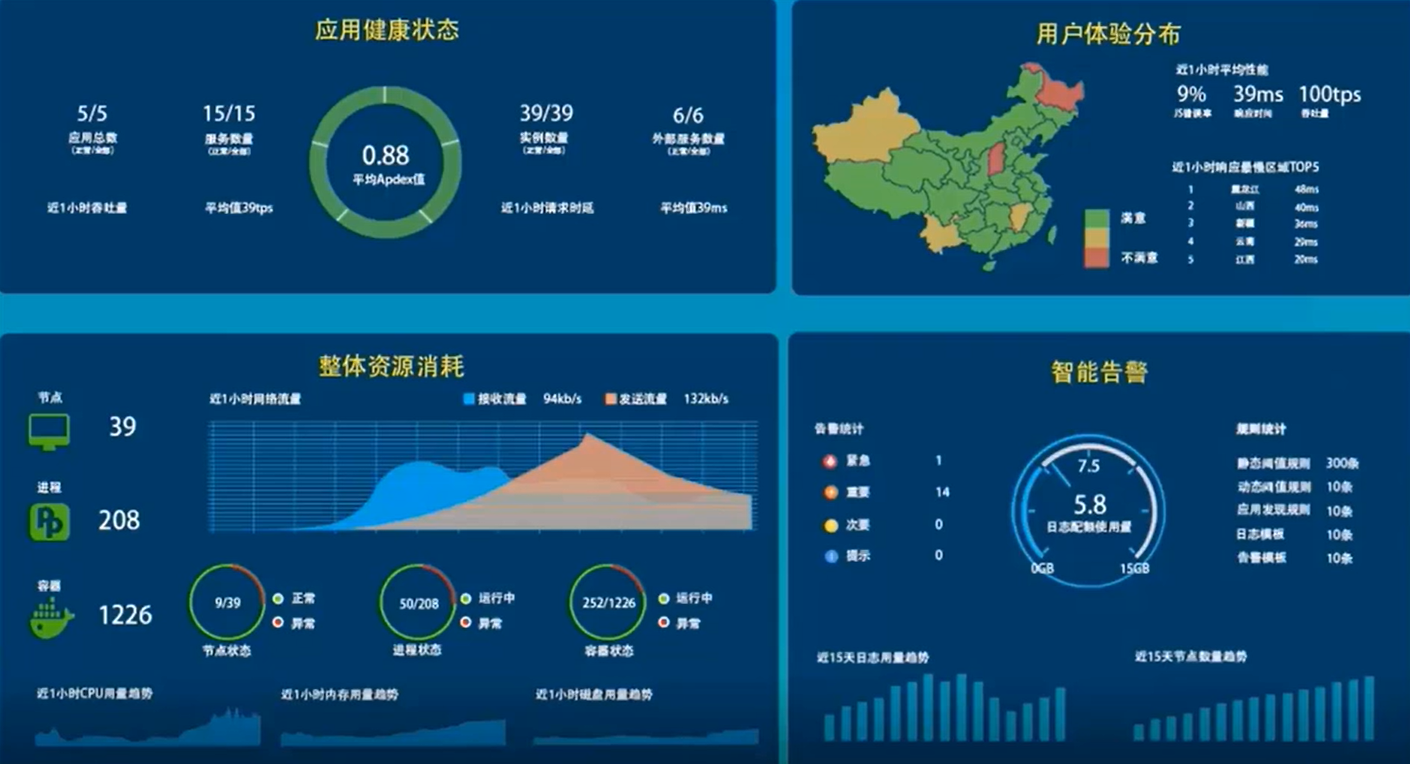
- 应用运维管理(Application Operations Management,AOM)是云上应用的一站式立体化运维管理平台,实时监控应用及云资源
- 通过采集器 ICagent 采集各项指标、日志等不同维度的数据
- 在 Dashboard 可以看到整个系统的运行情况(应用健康情况、用户体验分布、整体的资源消耗、告警中心的各项不同指标等)
AOM 监控对象
- 主机监控
- 主机包括弹性云服务器(ECS)、裸金属服务器(BMS)和 GPU 加速云服务器(GACS)
- 应用监控
- 应用是根据业务需要,对相同或者相近业务的一组服务进行逻辑划分
- 应用的类型:系统应用和自定义应用
- 容器监控
- 监控的对象仅为通过 CCE 部署的工作负载,通过 ServiceStage 创建应用
- 中间件监控
- 当购买了弹性负载均衡(ELB)、虚拟私有云(VPC)、关系型数据库(RDS)、分布式缓存服务(DCS)后,无需额外安装其他插件,即可在 AOM 界面监控这些云服务的运行状态及各种指标
ECS 监控

- 在 ECS 监控中,我们可以罗列到不同的 ECS 主机名称、状态、IP 地址、CPU 使用率、物理内存使用率等等
- 点击 ECS 监控的详情,可以看到当前主机的拓扑图,包括当前主机中间运行了多少条实例,当前主机的显卡、网卡、磁盘以及文件系统的各种状态,方便运维人员进行多维度的下钻
容器集群监控
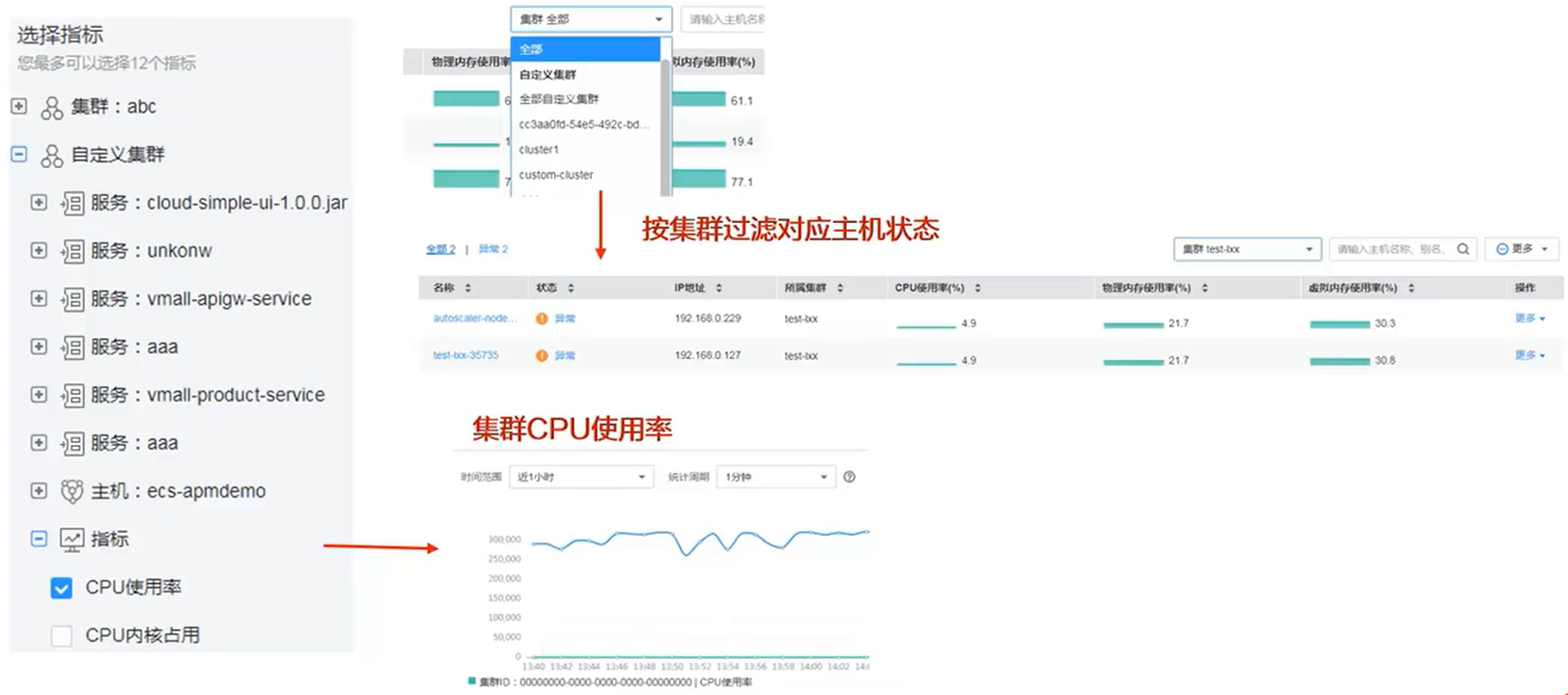
- 按照集群维度进行主机监控,获取集群、主机、服务之间的关联关系
- 可以按照集群对主机进行过滤,获取到集群下面所有主机的 CPU、物理内存等
- 目前 AOM 支持 NTP 服务器、物理内存、CPU 等多个维度的指标数据
AOM 告警管理
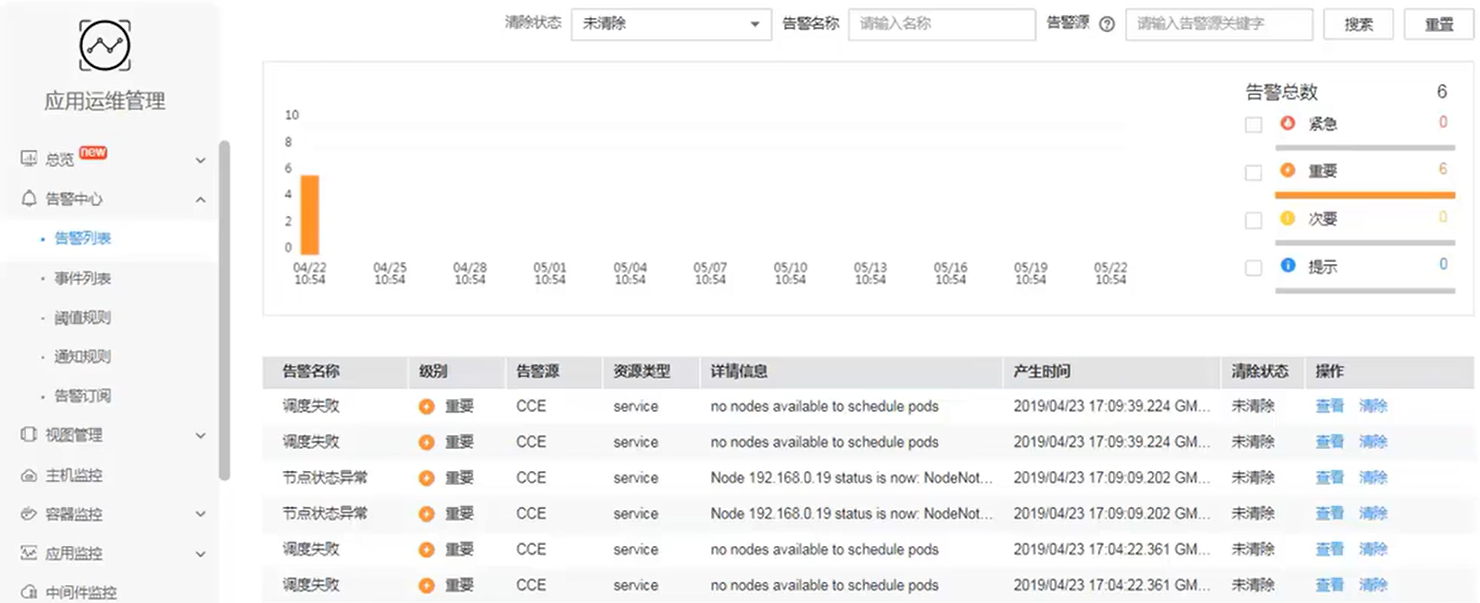
- 告警是指 AOM 自身,或 AOS、ServiceStage、CCE、APM 等外部服务在异常情况或者可能导致异常情况下上报的信息,
- 通过静态阈值规则可对资源的指标设置阈值条件
- 当指标数据满足阈值条件时,会产生阈值告警(阈值告警即由阈值规则触发而产生的告警)
- 当没有指标数据上报时,会产生数据不足事件(数据不足事件即由阈值规则触发而产生的事件)
AOM 告警中心
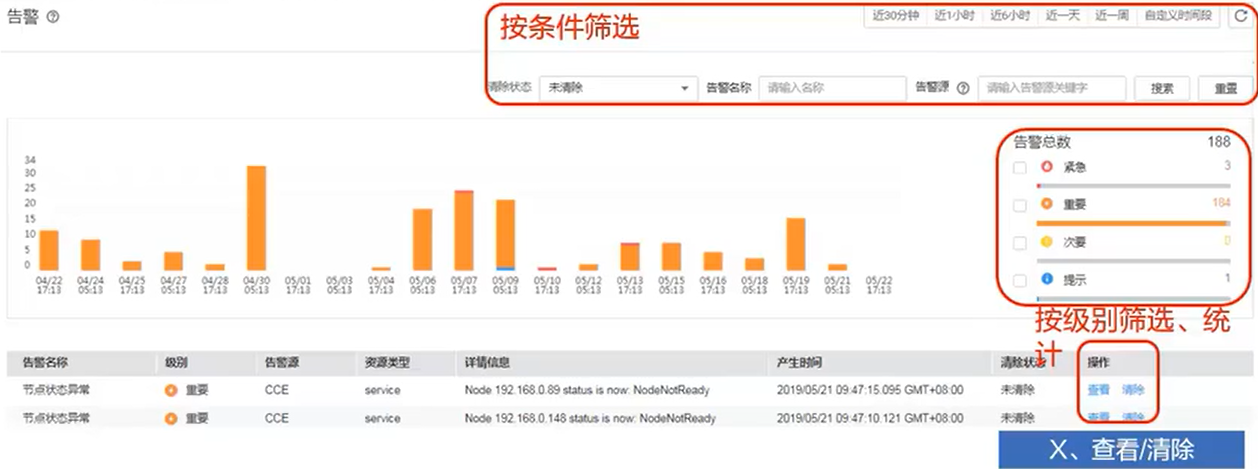
- 设置条件
- 要使用告警,需要先设置告警条件,即告警阈值规则。AOM支持一条一条或批量设置告警规则。告警规则可以是各类指标,主机、网络、磁盘、文件系统、服务、进程等的指标,如状态、CPU、内存、磁盘可用空间、磁盘空间容量、磁盘读写速率等;应用的吞吐量、成功率、时延、错误调用数等指标
- 产生告警
- AOM 根据设置的条件自动检测,满足条件时产生告警,展现在告警列表中
- 告警通知
- 通过邮件、短信、HTTP/HTTPS 等方式将告警信息通知到用户
- 告警订阅
- 如果需要将告警转发到第三方系统中,可以使用告警订阅功能将数据转发到分布式消息服务的 kafka 队列中去,然后第三方系统从 kakfa 中消费数据
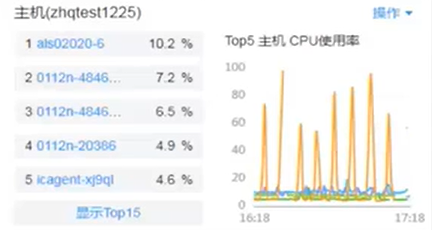
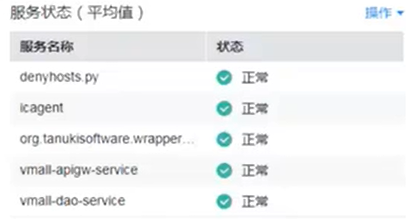
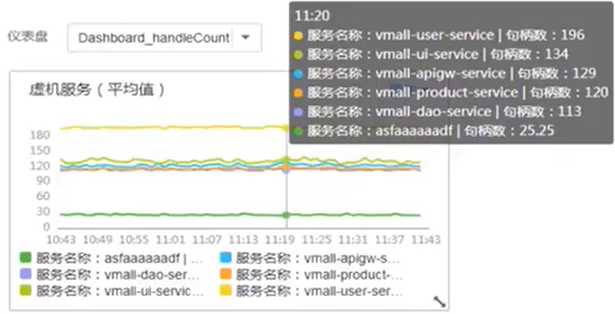
AOM —— 自定义仪表盘
- 支持多种图标形式(曲线图、服务状态、资源 TOP)
- 资源 TopN 图标
- 服务状态图标
- 曲线图
- 资源 TopN 图标
- 支持全屏监控和全屏轮播功能,能够全面、深入地掌握监控数据
最后,欢迎大家关注我的个人微信公众号 『小小猿若尘』,获取更多IT技术、干货知识、热点资讯。同时,我在公众号中分享了精心整理的一些视频资料(包括 Python全栈教程、AI教程、前端、数据库等),大家回复相应关键词即可获取网盘视频链接,感谢大家的关注😊


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)