来自一个菜鸟的爬虫分析过程

前言
这篇文章放在我的笔记里很久了,今天1024准备拿出来发一发,这是有关爬取新闻网站的,之前为了比赛爬了很多新闻网站,后面有机会会一一发出来,不知道会不会被警告(希望文章能过审)
有什么错误的地方请指正,谢谢
@TOC
分析
目的:爬取汽车和房产的新闻标题,内容,和连接
分析数据
由于有反爬,无法获取html数据,所以我们用seleniu获取指定数据
- 由于他每次只能获取5条新闻

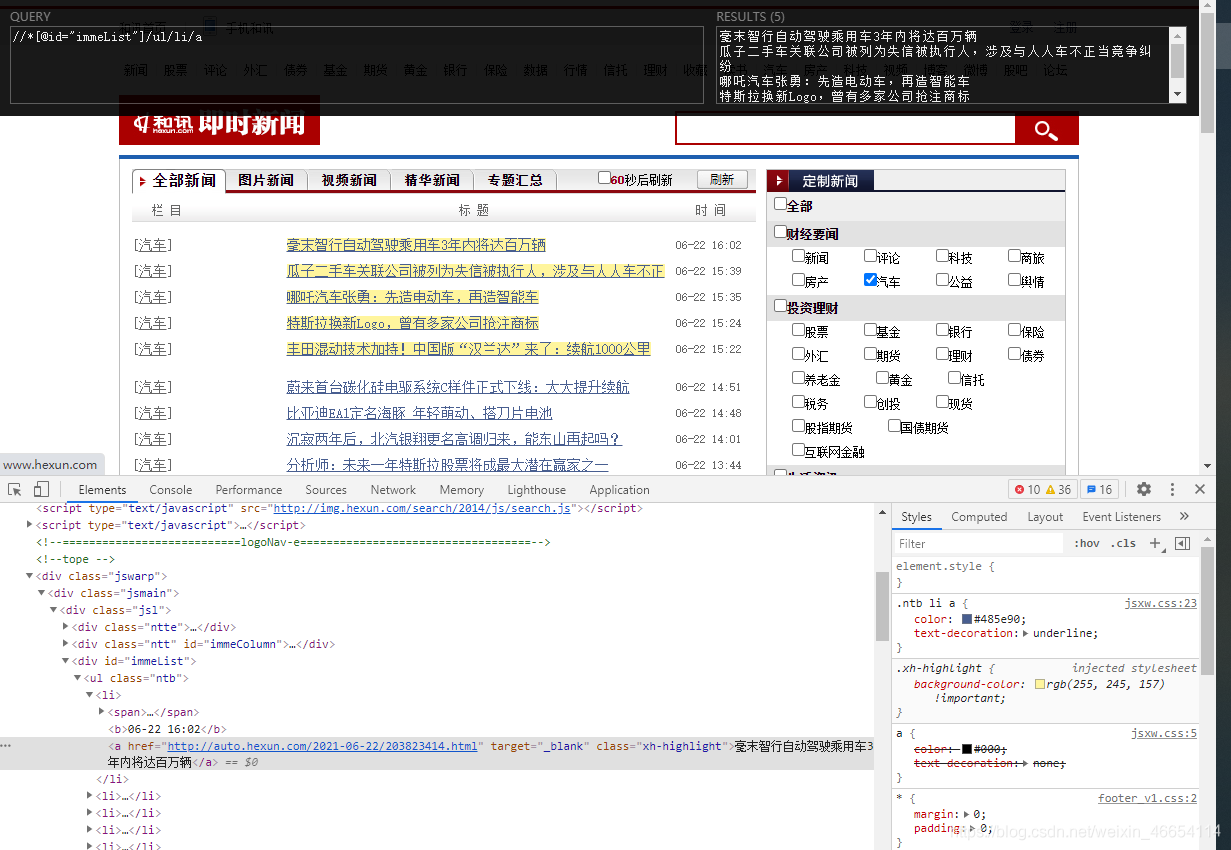
这里我尝试了各种正则,如果想直接全部获取的话是不理想的,因为我们还得获取连接,所以这里我们只能一一判断他们正则,一组组爬取
前一组新闻:
title: //*[@id="immeList"]/ul/li/a
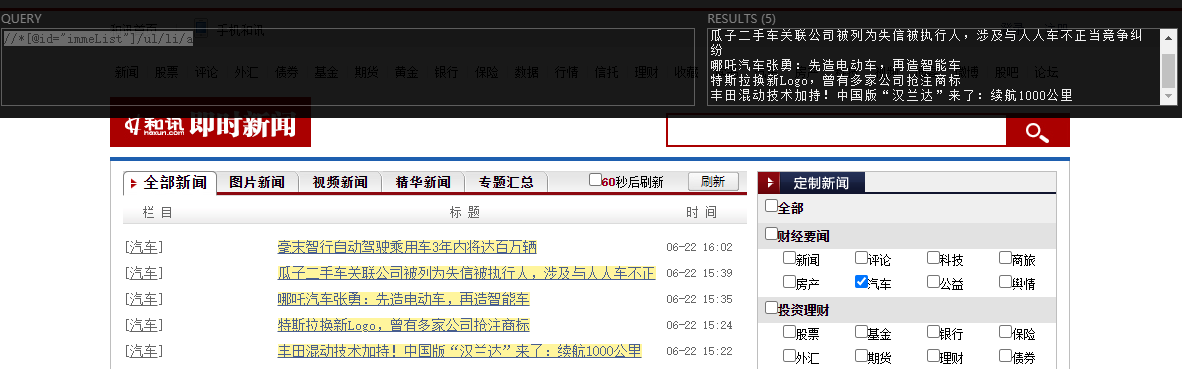
href://*[@id="immeList"]/ul/li/a/@href

同理第二组新闻也是一样的
title://*[@id="immeList"]/ul/ul/ul/li/a
href://*[@id="immeList"]/ul/ul/ul/li/a/@href
第三组:
title://*[@id="immeList"]/ul/ul/ul/ul/ul/li/a
href://*[@id="immeList"]/ul/ul/ul/ul/ul/li/a/@href
判断到这里我们可以发现,其实他每加一组就会加上两个ul标签,那我们就好判断了
第四组://*[@id="immeList"]/ul/ul/ul/ul/ul/ul/ul/li/a
好消息,好消息,特大好消息,我突然发现了一个规律,只要在li标签前面在加个/就可以了,形成绝对路径
title://*[@id="immeList"]/ul//li/a

href://*[@id="immeList"]/ul//li/a/@href

刚刚我又发现了一个
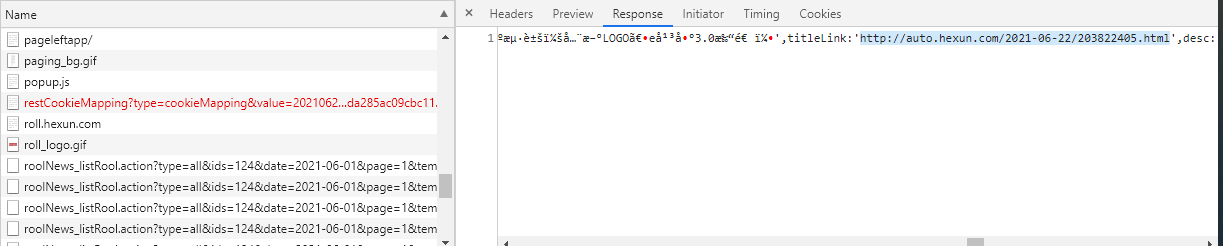
原来他的数据放在json数据这里藏起来了,不过中文是乱码,我们需要decode解析一下

失败归来
我回来了,这个不是json格式,也不能说不是,就是他的标点符号不符合规范应该用“”双引号,目前我知道了除了手动调整标点符号没有其他方法了
我尝试了转为json

也尝试了通过正则提取(奈何技术不够老报错)

以下是爬取的数据,只能呆呆看着

文档写到这里我还是不愿放弃,因为数据就在眼前,弄好了数度快的不止一倍,于是我突发奇想,我可不可以使用replace直接替换他的标点符号’变成“,这样应该就能变成json格式,说干就干


成功装换
可是这样子还是不行,因为比如sum,list等没有背双引号包围,不算json格式
于是我们在替换,


虽然看起来有点笨重,不过效果挺好,可是我们发现titleLink被title替换了,所以我们要单独写一个replace

大功告成
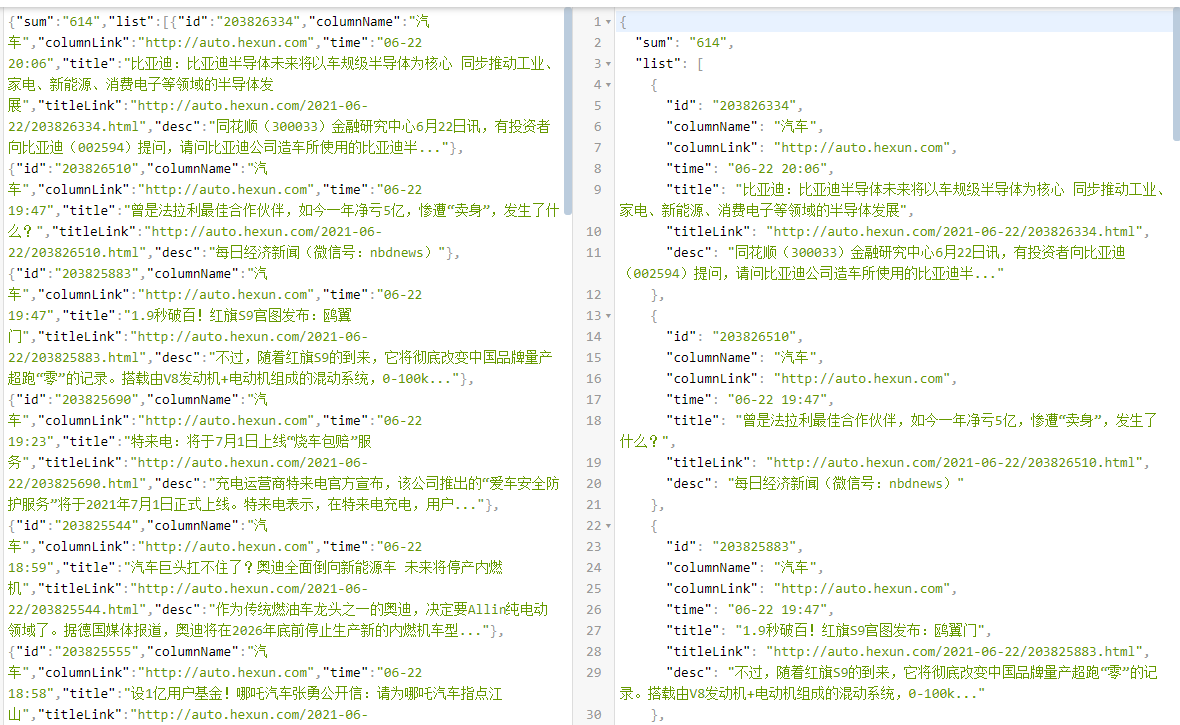
json格式终于出来了,不容易啊,这回可以大展身手了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TIQYhdHO-1634993282095)(https://gitee.com/ksjjs/picture-bed/raw/master/blogPicture/image-20210622215041254.png)]

这不就简简单单获取标题了,咋们在获取个内容助助兴

这里又有问题了,我之前觉得这个方便是因为里面有内容可以获取,不用弄二次连接,我以为那个内容…后面还会有数据,没想到还真那么少,那我们只能获取内容连接进入内容继续爬了
哭了哭了,不过代码量减少了很多
获取页数
目前代码
headers = {
'Connection': 'close',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36'
}
while True:
url = 'http://roll.hexun.com/roolNews_listRool.action?type=all&ids=105&date=2021-06-23&page=1'
response = requests.get(url, headers=headers)
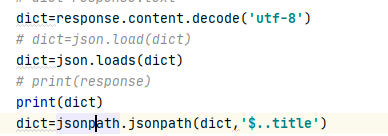
# dict=response.content.decode('utf-8')
dict=response.text
dict=dict.replace("'",'"').replace('sum','"sum"').replace('list','"list"').replace('id','"id"')\
.replace('columnName','"columnName"').replace('columnLink','"columnLink"').replace('time','"time"')\
.replace('title','"title"').replace('desc','"desc"')
dict=dict.replace('"title"Link','"titleLink"' )
dict=json.loads(dict)
dict=jsonpath.jsonpath(dict,'$..title')
print(dict)
break
我们想要他自动一页页爬取,可以调整page,循环遍历,还可以调整时间获取以前的数据

那我们如何知道他是多少页呢?
我们可以通过id判断,因为如果到了最后一页,无论你如何增加页数id都不变,那么到时候我们就不存数据,直接跳出循环,到达下一个日期

id=jsonpath.jsonpath(dict,'$..id')
hrefs=jsonpath.jsonpath(dict,'$..titleLink')
print(id)
print(hrefs)

这里思路已经清晰了,通过指定日期和页数获取数数据,通过数据id判断是否到达最后的页数
我们这里先爬取2021年的数据,1月到6月份的
由于每月的天数不一样,二月有28天
可以加上以下代码
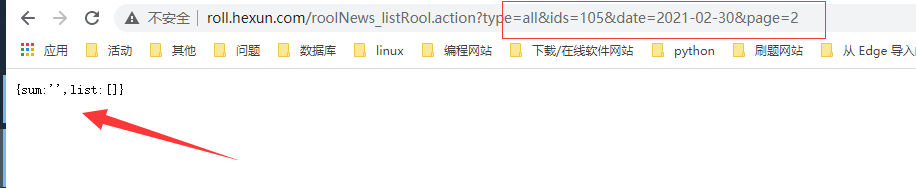
sum = jsonpath.jsonpath(dict, '$..sum')
if sum[0] == '':
return 0
由于我们的页数是定死的,所以我们获取数据的时候可以加个判断
return 0
if id!=0:
hexvn_id=hexvn(data_month=2,data_day=30,page=1,id=0)
if hexvn_id==0:
break
6/23下午八点,又发现问题
http://roll.hexun.com/roolNews_listRool.action?type=all&ids=105&date=2021-01-5&page=1

还是json格式不对,经检查发现是因为符号导致的,很奇怪
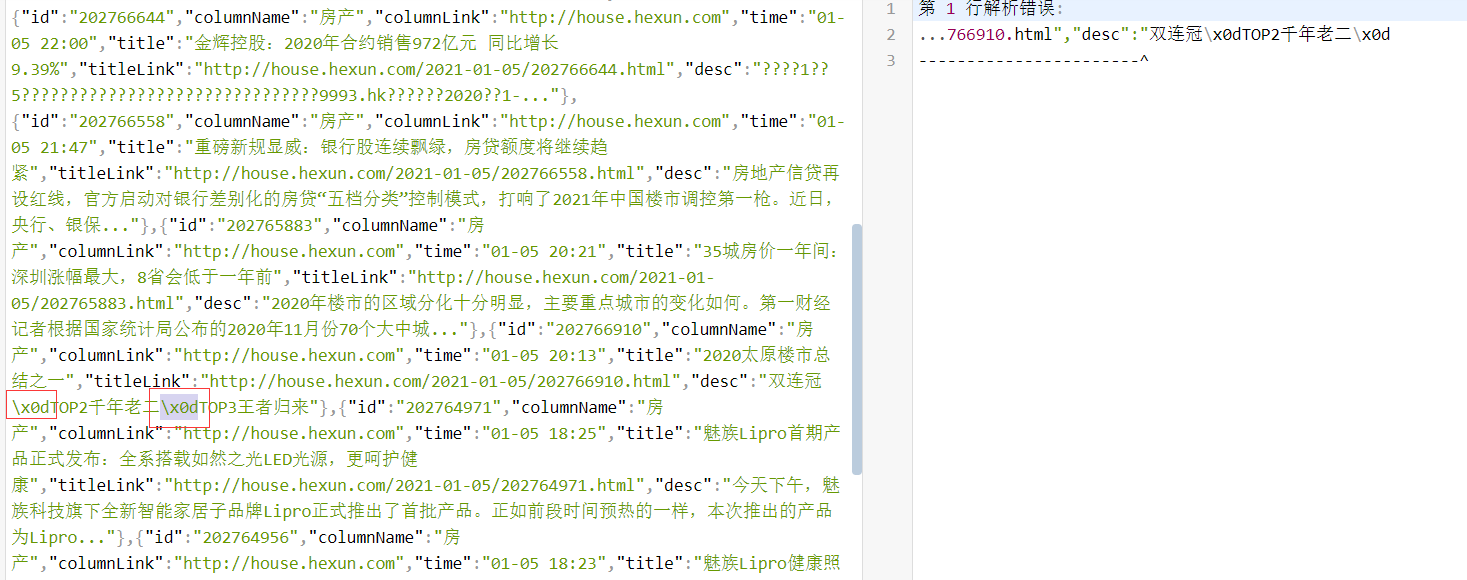
去掉之后就好了
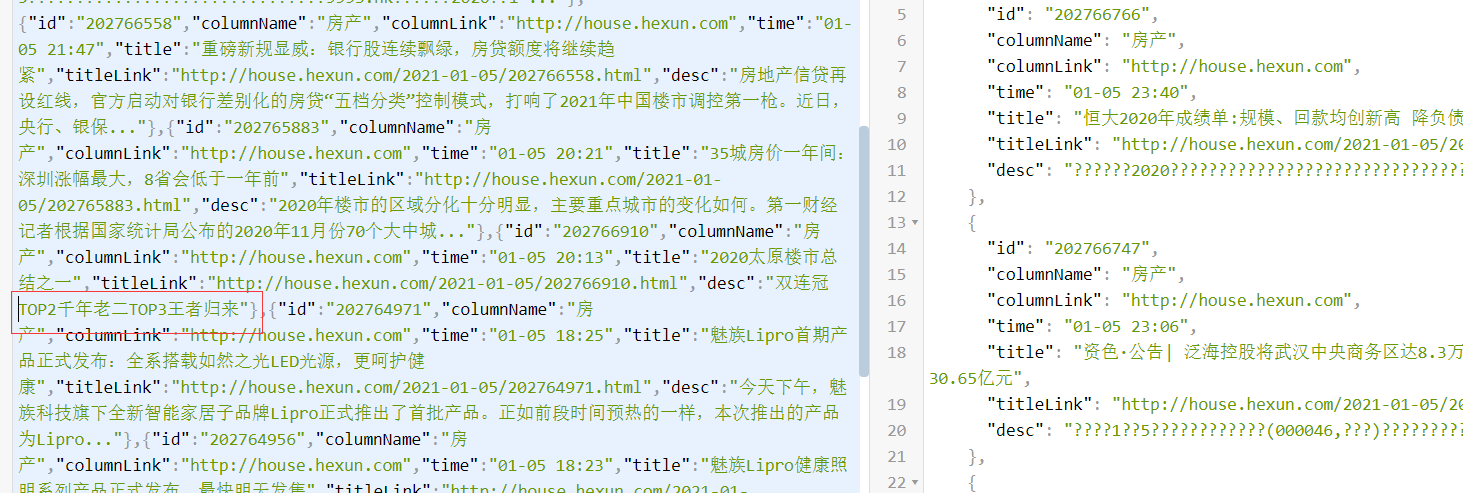
我们按照老方法替换为空
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H1KGXcNG-1634993282104)(E:\图片\博客图片\image-20210623201028482.png)]
发现不行,我们试试split,然并卵,没啥用,最后只能通过正则方式
"""冠\x0dTOP2千年老二\x0dTOP3王者归来""""
# 利用正则匹配\x开头的特殊字符
result = re.findall(r'\\x[a-f0-9]{2}', dict)
for x in result:
# 替换找的的特殊字符
dict = dict.replace(x, '')
学习了,挺牛的
爬取到第五天第5页又出现了问题

由于访问频率过快过多被拦截,我们设置一个sleep,有人问为什么不设置ip代理,我设置过了没用
#设置dailiip
def check_ip(url):
proxies = {
"https": "http://1.70.65.186:9999",
"https": "http://1.70.67.162:9999",
"https": "http://1.70.67.22:9999",
"https": "http://1.70.64.178:9999",
"https": "http://1.70.64.87:9999",
}
try:
response = requests.get(url, headers=headers,proxies=proxies)
print(response)
# if response.text:
print("代理ip可用", proxies)
return response
except Exception as e:
print("代理ip不可用{},用本机的106.12.204.140:1024".format(e))
response = requests.get(url, headers=headers)
return response
我们没爬取一页休息6秒

虽然慢一点,但是安全可靠,nice
又有错误了


这里有个id
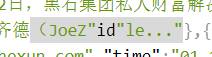
太麻烦了,我直接不爬这一天,任性

又有新的错误,就不能好好让我学习么
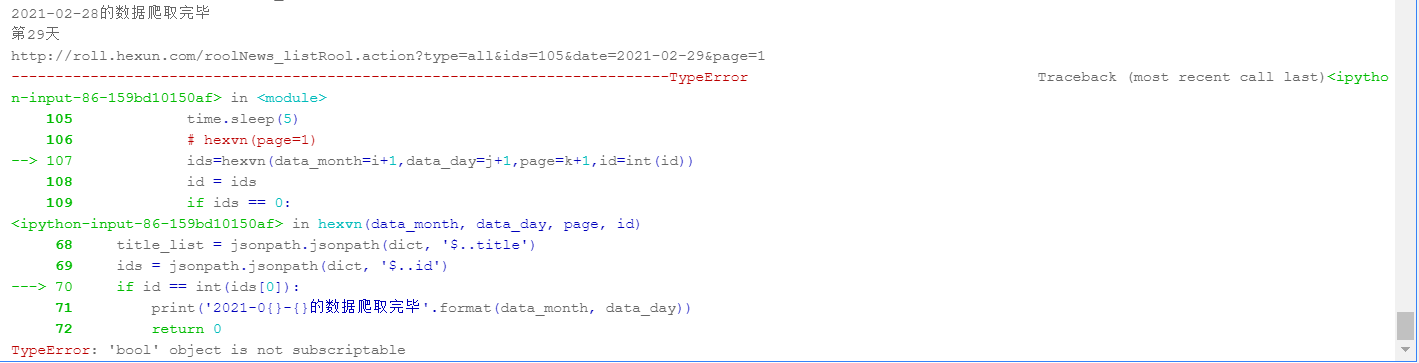
sum = jsonpath.jsonpath(dict, '$..sum')
if sum[0] == '':
return 0
这行代码居然忘记加了,cao,由于我们这里2月份 爬完了,懒得重新爬,直接从第三月爬起

爬到5月完了,有12600条数据
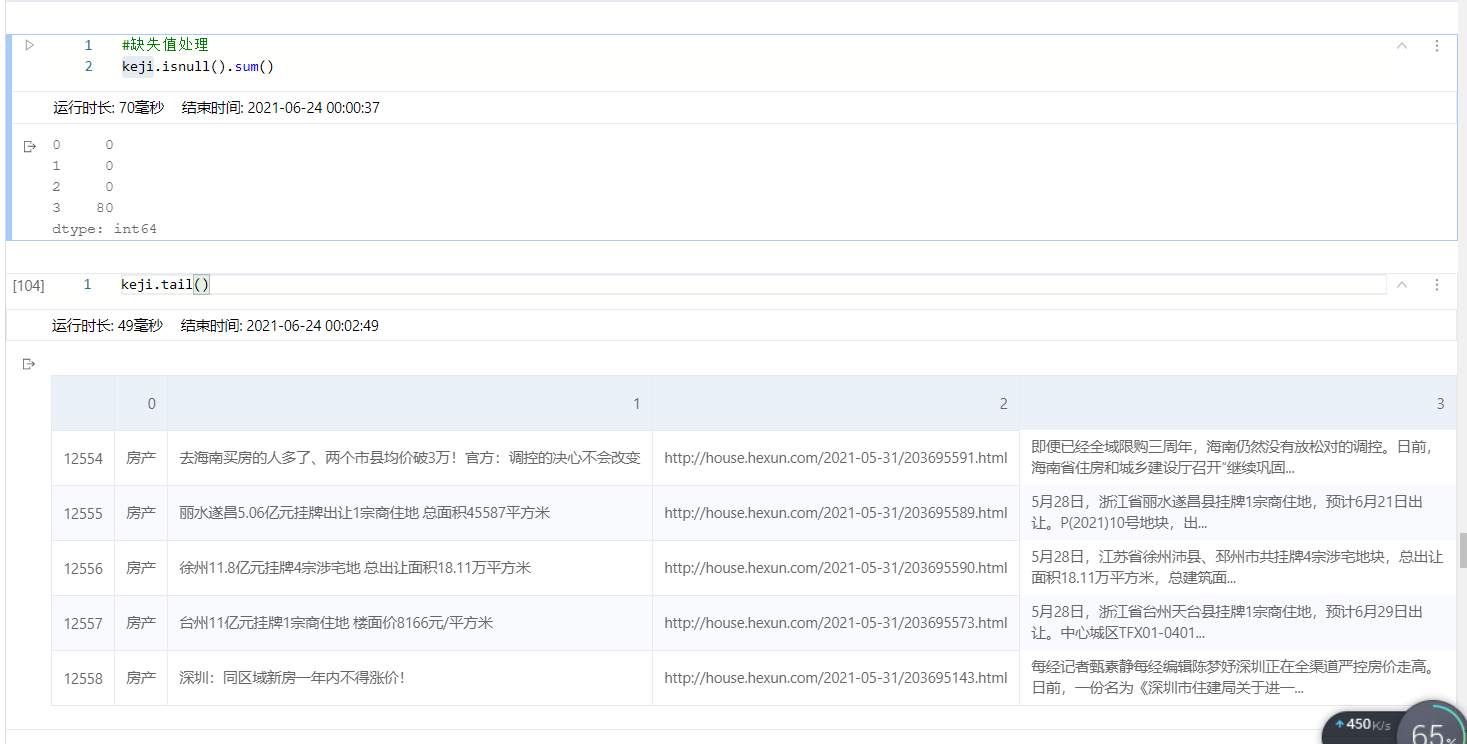
重复数据无
代码获取
💕教程传送门github仓库地址
或者通过以下方式:
💕↓ ↓ ↓ ↓完整代码:回复 新闻 即可获取↓ ↓ ↓ ↓

{kind=link}
- 点赞
- 收藏
- 关注作者
评论(0)