使用 scikit-learn 的 train_test_split() 拆分数据集

目录
监督机器学习的关键方面之一是模型评估和验证。当您评估模型的预测性能时,过程必须保持公正。使用train_test_split()数据科学库scikit-learn,您可以将数据集拆分为子集,从而最大限度地减少评估和验证过程中出现偏差的可能性。
在本教程中,您将学习:
- 为什么需要在监督机器学习中拆分数据集
- 其子集,你需要的数据集,为您的模型的公正的评价
- 如何使用
train_test_split()拆分数据 - 如何
train_test_split()与预测方法结合
此外,您将从 获得有关相关工具的信息sklearn.model_selection。
数据拆分的重要性
有监督的机器学习是关于创建将给定输入(自变量或预测变量)精确映射到给定输出(因变量或响应)的模型。
您如何衡量模型的精度取决于您要解决的问题的类型。在回归分析中,您通常使用决定系数、均方根误差、平均绝对误差或类似的量。对于分类问题,您通常会应用准确度、精确度、召回率、F1 分数和相关指标。
测量精度的可接受数值因字段而异。您可以在Statistics By Jim、Quora和许多其他资源中找到详细说明。
要了解的最重要的一点是,您通常需要无偏见的评估才能正确使用这些度量、评估模型的预测性能并验证模型。
这意味着您无法使用用于训练的相同数据评估模型的预测性能。您需要使用模型之前未见过的新数据来评估模型。您可以通过在使用之前拆分数据集来实现这一点。
训练、验证和测试集
拆分数据集对于无偏见地评估预测性能至关重要。在大多数情况下,将数据集随机分成三个子集就足够了:
-
验证集用于在超参数调整期间进行无偏模型评估。例如,当您想找到神经网络中的最佳神经元数量或支持向量机的最佳内核时,您可以尝试不同的值。对于每个考虑的超参数设置,您将模型与训练集进行拟合,并使用验证集评估其性能。
-
需要测试集来对最终模型进行无偏见的评估。您不应将其用于拟合或验证。
在不太复杂的情况下,当您不必调整超参数时,可以只使用训练集和测试集。
欠拟合和过拟合
拆分数据集对于检测您的模型是否存在两个非常常见的问题之一(称为欠拟合和过拟合)可能也很重要:
-
欠拟合通常是模型无法封装数据之间关系的结果。例如,当尝试用线性模型表示非线性关系时可能会发生这种情况。欠拟合的模型在训练集和测试集上的表现都可能很差。
-
当模型具有过于复杂的结构并且学习数据和噪声之间的现有关系时,通常会发生过度拟合。此类模型通常具有较差的泛化能力。尽管它们在训练数据上运行良好,但在处理看不见的(测试)数据时通常会产生较差的性能。
使用先决条件 train_test_split()
现在您了解了拆分数据集以执行无偏模型评估并识别欠拟合或过拟合的必要性,您已准备好学习如何拆分自己的数据集。
您将使用scikit-learn 的0.23.1 版,或sklearn. 它有许多用于数据科学和机器学习的包,但在本教程中,您将重点关注model_selection包,特别是函数train_test_split()。
您可以安装sklearn使用pip install:
$ python -m pip install -U "scikit-learn==0.23.1"
如果您使用Anaconda,那么您可能已经安装了它。但是,如果您想使用全新环境,请确保您拥有指定的版本,或者使用Miniconda,那么您可以使用以下命令sklearn从 Anaconda Cloud安装conda install:
$ conda install -c anaconda scikit-learn=0.23
您还需要NumPy,但您不必单独安装它。sklearn如果你还没有安装它,你应该得到它。如果您想刷新您的 NumPy 知识,请查看官方文档或查看Look Ma, No For-Loops: Array Programming With NumPy。
应用 train_test_split()
您需要导入 train_test_split()和 NumPy 才能使用它们,因此您可以从以下import语句开始:
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
现在您已导入,您可以使用它们将数据拆分为训练集和测试集。您将通过单个函数调用同时拆分输入和输出。
使用train_test_split(),您需要提供要拆分的序列以及任何可选参数。它返回一个列表的NumPy的阵列,其它序列,或SciPy的稀疏矩阵如果合适的话:
sklearn.model_selection.train_test_split(*arrays, **options) -> list
arrays是list、NumPy 数组、pandas DataFrames或类似数组的对象的序列,这些对象包含要拆分的数据。所有这些对象一起构成了数据集,并且必须具有相同的长度。
在受监督的机器学习应用程序中,您通常会使用两个这样的序列:
- 具有输入 (
x)的二维数组 - 具有输出 (
y) 的一维数组
options 是可用于获得所需行为的可选关键字参数:
-
train_size是定义训练集大小的数字。如果您提供float,则它必须介于0.0和之间,1.0并且将定义用于测试的数据集的份额。如果您提供int,则它将代表训练样本的总数。默认值为None。 -
test_size是定义测试集大小的数字。它非常类似于train_size. 您应该提供train_size或test_size。如果两者都没有给出,则用于测试的数据集的默认份额为0.25,或 25%。 -
random_state是在分裂期间控制随机化的对象。它可以是 的一个int或一个实例RandomState。默认值为None。 -
shuffle是布尔对象(True默认情况下),用于确定在应用拆分之前是否对数据集进行混洗。 -
stratify是一个类似数组的对象,如果不是None,则确定如何使用分层拆分。
现在是时候尝试数据拆分了!您将首先创建一个要使用的简单数据集。数据集将包含二维数组中的输入x和一维数组中的输出y:
>>> x = np.arange(1, 25).reshape(12, 2)
>>> y = np.array([0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0])
>>> x
array([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10],
[11, 12],
[13, 14],
[15, 16],
[17, 18],
[19, 20],
[21, 22],
[23, 24]])
>>> y
array([0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0])
要获取数据,请使用arange(),这对于基于数值范围生成数组非常方便。您还可以.reshape()用来修改由 返回的数组的形状arange()并获得二维数据结构。
您可以使用单个函数调用拆分输入和输出数据集:
>>> x_train, x_test, y_train, y_test = train_test_split(x, y)
>>> x_train
array([[15, 16],
[21, 22],
[11, 12],
[17, 18],
[13, 14],
[ 9, 10],
[ 1, 2],
[ 3, 4],
[19, 20]])
>>> x_test
array([[ 5, 6],
[ 7, 8],
[23, 24]])
>>> y_train
array([1, 1, 0, 1, 0, 1, 0, 1, 0])
>>> y_test
array([1, 0, 0])
给定两个序列,例如x和yhere,train_test_split()执行拆分并按以下顺序返回四个序列(在本例中为 NumPy 数组):
x_train:第一个序列的训练部分 (x)x_test:第一个序列的测试部分 (x)y_train:第二个序列的训练部分 (y)y_test:第二个序列的测试部分 (y)
您可能会得到与您在此处看到的结果不同的结果。这是因为数据集拆分默认是随机的。每次运行该函数时结果都不同。但是,这通常不是您想要的。
有时,为了使您的测试具有可重复性,您需要对每个函数调用使用相同的输出进行随机拆分。你可以用参数来做到这一点random_state。的值random_state并不重要——它可以是任何非负整数。您可以使用一个实例来numpy.random.RandomState代替,但这是一种更复杂的方法。
在前面的示例中,您使用了一个包含 12 个观测值(行)的数据集,并获得了一个包含 9 行的训练样本和一个包含三行的测试样本。那是因为您没有指定所需的训练和测试集大小。默认情况下,将 25% 的样本分配给测试集。对于许多应用程序来说,这个比率通常是合适的,但它并不总是您所需要的。
通常,您需要明确定义测试(或训练)集的大小,有时您甚至想尝试不同的值。您可以使用参数train_size或test_size.
修改代码,以便您可以选择测试集的大小并获得可重现的结果:
>>> x_train, x_test, y_train, y_test = train_test_split(
... x, y, test_size=4, random_state=4
... )
>>> x_train
array([[17, 18],
[ 5, 6],
[23, 24],
[ 1, 2],
[ 3, 4],
[11, 12],
[15, 16],
[21, 22]])
>>> x_test
array([[ 7, 8],
[ 9, 10],
[13, 14],
[19, 20]])
>>> y_train
array([1, 1, 0, 0, 1, 0, 1, 1])
>>> y_test
array([0, 1, 0, 0])
通过此更改,您将获得与之前不同的结果。之前,您有一个包含 9 个项目的训练集和包含三个项目的测试集。现在,由于参数test_size=4,训练集有八个项目,测试集有四个项目。你会得到相同的结果,test_size=0.33因为 12 的 33% 大约是 4。
最后两个示例之间还有一个非常重要的区别:现在每次运行该函数时都会得到相同的结果。这是因为您已使用random_state=4.
下图显示了调用时发生的情况train_test_split():
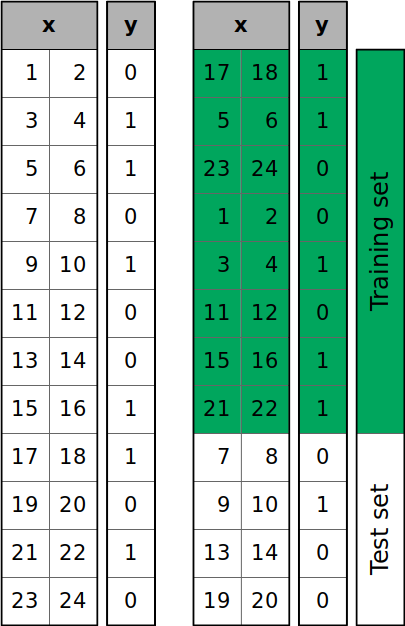
数据集的样本被随机打乱,然后根据你定义的大小分成训练集和测试集。
你可以看到它y有六个零和六个一。但是,测试集的四个项目中有三个零。如果您想(大约)y通过训练和测试集保持值的比例,则通过stratify=y. 这将启用分层拆分:
>>> x_train, x_test, y_train, y_test = train_test_split(
... x, y, test_size=0.33, random_state=4, stratify=y
... )
>>> x_train
array([[21, 22],
[ 1, 2],
[15, 16],
[13, 14],
[17, 18],
[19, 20],
[23, 24],
[ 3, 4]])
>>> x_test
array([[11, 12],
[ 7, 8],
[ 5, 6],
[ 9, 10]])
>>> y_train
array([1, 0, 1, 0, 1, 0, 0, 1])
>>> y_test
array([0, 0, 1, 1])
现在y_train并y_test具有与原始y数组相同的零和一比率。
在某些情况下,分层拆分是可取的,例如当您对不平衡数据集进行分类时,属于不同类别的样本数量存在显着差异的数据集。
最后,您可以使用以下命令关闭数据混洗和随机拆分shuffle=False:
>>> x_train, x_test, y_train, y_test = train_test_split(
... x, y, test_size=0.33, shuffle=False
... )
>>> x_train
array([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10],
[11, 12],
[13, 14],
[15, 16]])
>>> x_test
array([[17, 18],
[19, 20],
[21, 22],
[23, 24]])
>>> y_train
array([0, 1, 1, 0, 1, 0, 0, 1])
>>> y_test
array([1, 0, 1, 0])
现在您有一个拆分,其中原始x和y数组中的前三分之二样本分配给训练集,最后三分之一分配给测试集。没有洗牌。没有随机性。
监督机器学习 train_test_split()
现在是时候看看train_test_split()解决监督学习问题时的实际情况了。在研究更大的问题之前,您将从一个可以用线性回归解决的小回归问题开始。您还将看到您也可以train_test_split()用于分类。
线性回归的极简示例
在此示例中,您将应用迄今为止学到的知识来解决一个小的回归问题。您将学习如何创建数据集,将它们拆分为训练和测试子集,并将它们用于线性回归。
与往常一样,您将从导入必要的包、函数或类开始。您将需要 NumPy LinearRegression、 和train_test_split():
>>> import numpy as np
>>> from sklearn.linear_model import LinearRegression
>>> from sklearn.model_selection import train_test_split
现在您已经导入了您需要的所有内容,您可以创建两个小数组x和y, 来表示观察结果,然后像以前一样将它们拆分为训练集和测试集:
>>> x = np.arange(20).reshape(-1, 1)
>>> y = np.array([5, 12, 11, 19, 30, 29, 23, 40, 51, 54, 74,
... 62, 68, 73, 89, 84, 89, 101, 99, 106])
>>> x
array([[ 0],
[ 1],
[ 2],
[ 3],
[ 4],
[ 5],
[ 6],
[ 7],
[ 8],
[ 9],
[10],
[11],
[12],
[13],
[14],
[15],
[16],
[17],
[18],
[19]])
>>> y
array([ 5, 12, 11, 19, 30, 29, 23, 40, 51, 54, 74, 62, 68,
73, 89, 84, 89, 101, 99, 106])
>>> x_train, x_test, y_train, y_test = train_test_split(
... x, y, test_size=8, random_state=0
... )
您的数据集有 20 个观察值,或x-y对。您指定参数test_size=8,因此数据集被划分为包含 12 个观测值的训练集和包含 8 个观测值的测试集。
现在您可以使用训练集来拟合模型:
>>> model = LinearRegression().fit(x_train, y_train)
>>> model.intercept_
3.1617195496417523
>>> model.coef_
array([5.53121801])
LinearRegression创建代表模型的对象,同时.fit()训练或拟合模型并返回它。对于线性回归,拟合模型意味着确定回归线的最佳截距 ( model.intercept_) 和斜率 ( model.coef_) 值。
尽管您可以使用x_train和y_train检查拟合优度,但这不是最佳实践。对模型预测性能的无偏估计基于测试数据:
>>> model.score(x_train, y_train)
0.9868175024574795
>>> model.score(x_test, y_test)
0.9465896927715023
.score()返回判定系数,或- [R ²,用于传递的数据。其最大值为1。越高[R ²价值,更好的配合。在这种情况下,训练数据会产生稍高的系数。然而,[R与试验数据计算²是模型的预测性能可以客观地衡量。
这是它在图表上的样子:
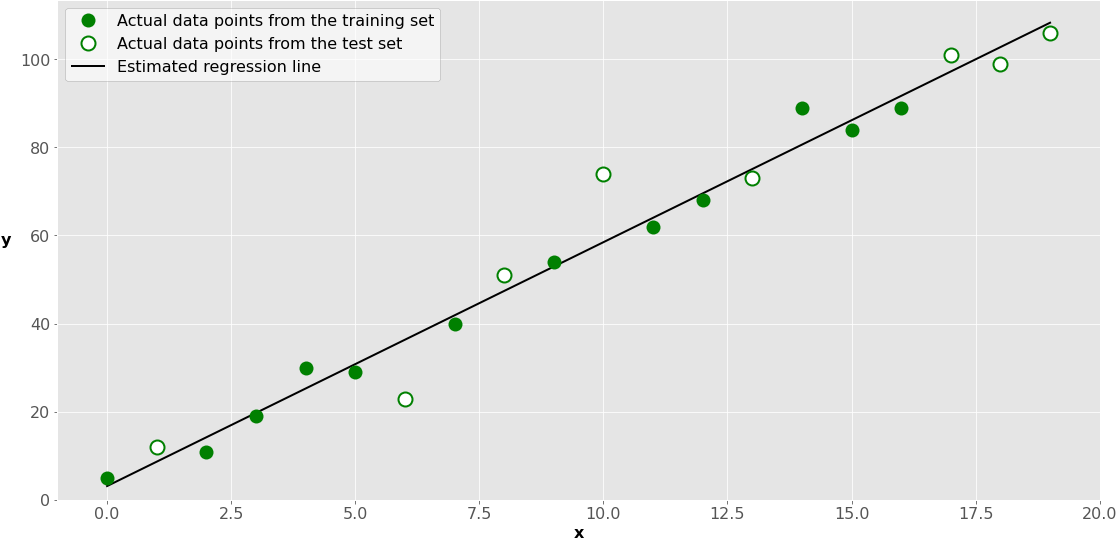
绿点代表用于训练的x-y对。黑线称为估计回归线,由模型拟合的结果定义:截距和斜率。因此,它仅反映绿点的位置。
白点代表测试集。您可以使用它们来估计模型(回归线)的性能以及未用于训练的数据。
回归示例
现在您已准备好拆分更大的数据集来解决回归问题。您将使用著名的波士顿房价数据集,该数据集包含在sklearn. 该数据集有 506 个样本、13 个输入变量和作为输出的房屋价值。您可以使用 检索它load_boston()。
首先,导入train_test_split()和load_boston():
>>> from sklearn.datasets import load_boston
>>> from sklearn.model_selection import train_test_split
现在您已经导入了这两个函数,您可以获取要使用的数据:
>>> x, y = load_boston(return_X_y=True)
如您所见,load_boston()参数return_X_y=True返回一个包含两个 NumPy 数组的元组:
- 具有输入的二维数组
- 具有输出的一维数组
下一步是像以前一样拆分数据:
>>> x_train, x_test, y_train, y_test = train_test_split(
... x, y, test_size=0.4, random_state=0
... )
现在你有了训练集和测试集。训练数据包含在x_train和y_train,而测试的数据是x_test和y_test。
当您处理较大的数据集时,通常将训练或测试大小作为比率传递更方便。test_size=0.4意味着大约 40% 的样本将分配给测试数据,其余 60% 将分配给训练数据。
最后,您可以使用训练集 ( x_trainand y_train) 拟合模型和测试集 ( x_testand y_test) 以对模型进行无偏评估。在此示例中,您将应用三种众所周知的回归算法来创建适合您的数据的模型:
- 线性回归
LinearRegression() - 梯度推进与
GradientBoostingRegressor() - 随机森林带
RandomForestRegressor()
该过程与前面的示例几乎相同:
- 导入您需要的类。
- 使用这些类创建模型实例。
.fit()使用训练集拟合模型实例。.score()使用测试集评估模型。
以下是针对所有三种回归算法执行上述步骤的代码:
>>> from sklearn.linear_model import LinearRegression
>>> model = LinearRegression().fit(x_train, y_train)
>>> model.score(x_train, y_train)
0.7668160223286261
>>> model.score(x_test, y_test)
0.6882607142538016
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> model = GradientBoostingRegressor(random_state=0).fit(x_train, y_train)
>>> model.score(x_train, y_train)
0.9859065238883613
>>> model.score(x_test, y_test)
0.8530127436482149
>>> from sklearn.ensemble import RandomForestRegressor
>>> model = RandomForestRegressor(random_state=0).fit(x_train, y_train)
>>> model.score(x_train, y_train)
0.9811695664860354
>>> model.score(x_test, y_test)
0.8325867908704008
您已经使用训练和测试数据集拟合了三个模型并评估了它们的性能。获得的准确度的度量.score()是确定系数。它可以用训练集或测试集计算。但是,正如您已经了解到的,使用测试集获得的分数代表了对性能的无偏估计。
正如文件中所提到的,您可以提供可选的参数LinearRegression(),GradientBoostingRegressor()和RandomForestRegressor()。GradientBoostingRegressor()并出于同样的原因RandomForestRegressor()使用该random_state参数train_test_split():处理算法中的随机性并确保可重复性。
对于某些方法,您可能还需要特征缩放。在这种情况下,您应该使用训练数据拟合缩放器,并使用它们来转换测试数据。
分类示例
您可以使用train_test_split()与回归分析相同的方式来解决分类问题。在机器学习中,分类问题涉及训练模型以将标签应用于输入值或对输入值进行分类并将数据集分类。
在教程Logistic Regression in Python 中,您将找到一个手写识别任务的示例。该示例提供了将数据拆分为训练集和测试集以避免评估过程中的偏差的另一个演示。
其他验证功能
该软件包sklearn.model_selection提供了许多与模型选择和验证相关的功能,包括:
- 交叉验证
- 学习曲线
- 超参数调优
交叉验证是一组技术,它结合了预测性能的度量以获得更准确的模型估计。
广泛使用的交叉验证方法之一是k折交叉验证。在其中,您将数据集划分为k 个(通常是五个或十个)大小相同的子集或folds,然后执行k次训练和测试程序。每次,您使用不同的折叠作为测试集,所有剩余的折叠作为训练集。这提供了k个预测性能的度量,然后您可以分析它们的平均值和标准偏差。
您可以使用KFold、StratifiedKFold、LeaveOneOut和来自 的其他一些类和函数实现交叉验证sklearn.model_selection。
一个学习曲线,有时也被称为训练曲线,表演的训练和验证集的预测分数是如何依赖于训练样本的数量。您可以使用learning_curve()获取此依赖项,它可以帮助您找到训练集的最佳大小、选择超参数、比较模型等。
超参数调整,也称为超参数优化,是确定用于定义机器学习模型的最佳超参数集的过程。sklearn.model_selection为您提供了几个选项用于此目的,包括GridSearchCV,RandomizedSearchCV,validation_curve(),和其他人。拆分数据对于超参数调整也很重要。
结论
您现在知道为什么以及如何使用train_test_split()from sklearn。您已经了解到,为了对机器学习模型的预测性能进行无偏估计,您应该使用尚未用于模型拟合的数据。这就是为什么您需要将数据集拆分为训练、测试以及某些情况下的验证子集。
在本教程中,您学习了如何:
- 使用
train_test_split()得到的训练和测试集 - 用参数控制子集的大小
train_size和test_size - 使用参数确定分割的随机性
random_state - 使用参数获取分层分割
stratify - 使用
train_test_split()作为的一部分监督机器学习方法
您还看到,该sklearn.model_selection模块提供了其他几种模型验证工具,包括交叉验证、学习曲线和超参数调整。
如果您有任何问题或意见,请将它们放在下面的评论部分。

- 点赞
- 收藏
- 关注作者
评论(0)