如何使用 SQL 对数据进行分析?

前言
我们通过 OLTP(联机事务处理)系统实时处理用户数据,还需要在 OLAP(联机分析处理)系统中对它们进行分析,今天我们来看下如何使用 SQL 分析数据。
使用 SQL 进行数据分析的几种方式
在 DBMS(数据库管理系统) 中,有些数据库很好地集成了 BI 工具,可以方便我们对收集的数据进行商业分析。
比如在SQL Server 中提供了 BI 分析工具,我们可以通过使用 SQL Server中的 Analysis Services 完成数据挖掘任务。SQL Server 内置了多种数据挖掘算法,比如常用的 EM、K-Means 聚类算法、决策树、朴素贝叶斯和逻辑回归等分类算法,以及神经网络等模型。我们还可以对这些算法模型进行可视化效果呈现,帮我们优化和评估算法模型的好坏。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uxDqBJLM-1592728193777)(media/15777852880253/15778092138631.jpg)]](https://img-blog.csdnimg.cn/20200621163203315.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3p1b3pld2Vp,size_16,color_FFFFFF,t_70)
另外 PostgreSQL 是一个免费开源的关系数据库(ORDBMS),它的稳定性非常强,功能强大,在 OLTP 和 OLAP 系统上表现都非常出色。同时在机器学习上,配合 Madlib 项目可以让 PostgreSQL 如虎添翼。Madlib 包括了多种机器学习算法,比如分类、聚类、文本分析、回归分析、关联规则挖掘和验证分析等功能。这样我们可以通过使用 SQL,在 PostgreSQL 中使用各种机器学习算法模型,帮我们进行数据挖掘和分析。
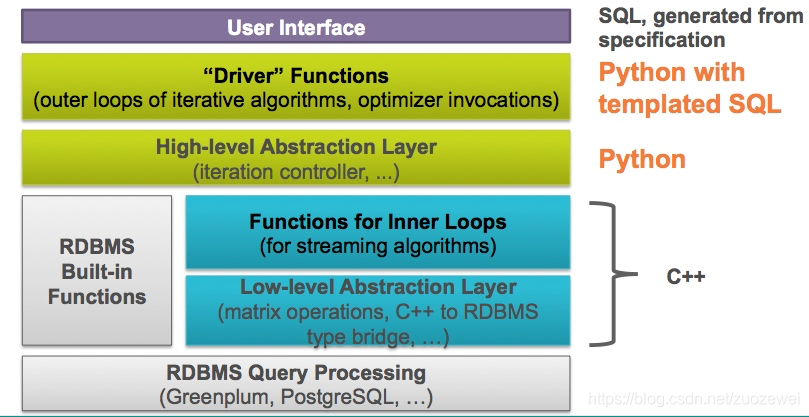
图片来源:https://cwiki.apache.org/confluence/display/MADLIB/Architecture
2018 年 Google 将机器学习(Machine Learning)工具集成到了 BigQuery 中,发布了 BigQuery ML,这样开发者就可以在大型的结构化或半结构化的数据集上构建和使用机器学习模型。通过 BigQuery 控制台,开发者可以像使用 SQL 语句一样来完成机器学习模型的训练和预测。
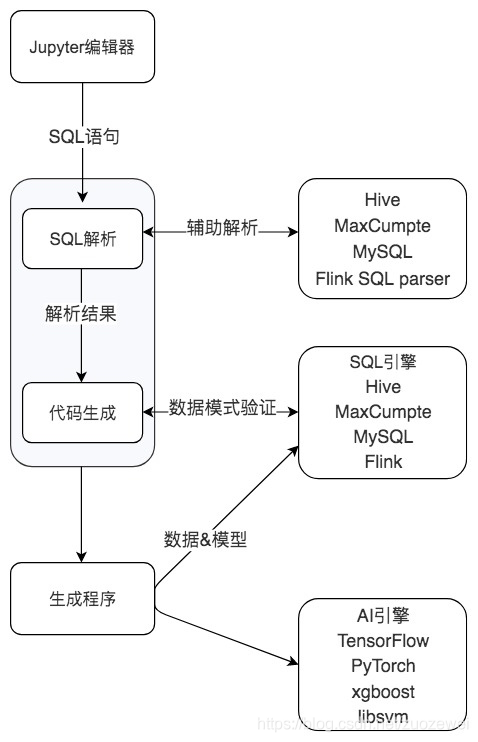
SQLFlow 是蚂蚁金服于 2019 年开源的机器学习工具,我们可以通过使用 SQL 就可以完成机器学习算法的调用,你可以将 SQLFlow 理解为机器学习的翻译器。我们在 SELECT 之后加上 TRAIN 从句就可以完成机器学习模型的训练,在 SELECT 语句之后加上 PREDICT 就可以使用模型来进行预测。这些算法模型既包括了传统的机器学习模型,也包括了基于 Tensorflow、PyTorch 等框架的深度学习模型。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mvW765Gb-1592728193780)(media/15777852880253/15778199737535.jpg)]](https://img-blog.csdnimg.cn/20200621163303466.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3p1b3pld2Vp,size_16,color_FFFFFF,t_70)
从上图中你能看出 SQLFlow 的使用过程,首先我们可以通过 Jupyter notebook 来完成 SQL 语句的交互。SQLFlow 支持了多种 SQL 引擎,包括 MySQL、Oracle、Hive、SparkSQL 和 Flink 等,这样我们就可以通过 SQL 语句从这些 DBMS 数据库中抽取数据,然后选择想要进行的机器学习算法(包括传统机器学习和深度学习模型)进行训练和预测。不过这个工具刚刚上线,工具、文档、社区还有很多需要完善的地方。
最后一个最常用方法是 SQL+Python,也是我们今天要重点讲解的内容。上面介绍的工具可以说既是 SQL 查询数据的入口,也是数据分析、机器学习的入口。不过这些模块耦合度高,也可能存在使用的问题。一方面工具会很大,比如在安装 SQLFlow 的时候,采用 Docker 方式进行安装,整体需要下载的文件会超过 2G。同时,在进行算法调参、优化的时候也存在灵活度差的情况。因此最直接的方式,还是将 SQL 与数据分析模块分开,采用 SQL 读取数据,然后通过 Python 来进行数据分析的处理。
案例:挖掘购物数据中的频繁项集与关联规则
下面我们通过一个案例来进行具体的讲解。
我们要分析的是购物问题,采用的技术为关联分析。它可以帮我们在大量的数据集中找到商品之间的关联关系,从而挖掘出经常被人们购买的商品组合,一个经典的例子就是“啤酒和尿布”的例子。
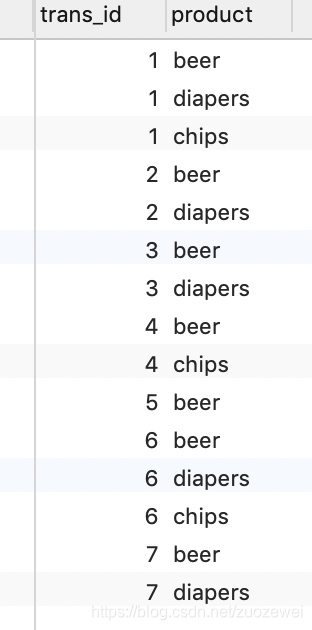
今天我们的数据集来自于一个购物样本数据,字段包括了 trans_id(交易 ID)以及 product(商品名称),具体的数据集参考下面的初始化 sql:
DROP TABLE IF EXISTS test_data;
CREATE TABLE test_data (
trans_id INT,
product TEXT
);
INSERT INTO test_data VALUES (1, 'beer');
INSERT INTO test_data VALUES (1, 'diapers');
INSERT INTO test_data VALUES (1, 'chips');
INSERT INTO test_data VALUES (2, 'beer');
INSERT INTO test_data VALUES (2, 'diapers');
INSERT INTO test_data VALUES (3, 'beer');
INSERT INTO test_data VALUES (3, 'diapers');
INSERT INTO test_data VALUES (4, 'beer');
INSERT INTO test_data VALUES (4, 'chips');
INSERT INTO test_data VALUES (5, 'beer');
INSERT INTO test_data VALUES (6, 'beer');
INSERT INTO test_data VALUES (6, 'diapers');
INSERT INTO test_data VALUES (6, 'chips');
INSERT INTO test_data VALUES (7, 'beer');
INSERT INTO test_data VALUES (7, 'diapers');
这里我们采用的关联分析算法是 Apriori 算法,它帮我们查找频繁项集,首先我们需要先明白什么是频繁项集。
频繁项集就是支持度大于等于最小支持度阈值的项集,小于这个最小值支持度的项目就是非频繁项集,而大于等于最小支持度的项集就是频繁项集。支持度是个百分比,指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
我们再来看下 Apriori 算法的基本原理。
Apriori 算法其实就是查找频繁项集 (frequent itemset) 的过程:
0.设置一个最小支持度,
1.从K=1开始,筛选频繁项集。
2.在结果中,组合K+1项集,再次筛选
3.循环1、2步。直到找不到结果为止,K-1项集的结果就是最终结果。
我们来看下数据理解一下,下面是所有的订单,以及每笔订单购买的商品:
| 订单编号 | 购买的商品 |
|---|---|
| 1 | beer(啤酒)、diapers(尿布)、chips(薯条) |
| 2 | beer(啤酒)、diapers(尿布) |
| 3 | beer(啤酒)、diapers(尿布) |
| 4 | beer(啤酒)、chips(薯条) |
| 5 | beer(啤酒) |
| 6 | beer(啤酒)、diapers(尿布)、chips(薯条) |
| 7 | beer(啤酒)、diapers(尿布) |
在这个例子中,“啤酒”出现了 7 次,那么这 7 笔订单中“牛奶”的支持度就是 7/7=1。同样“啤酒 + 尿布”出现了 5 次,那么这 7 笔订单中的支持度就是 5/7=0.71。
同时,我们还需要理解一个概念叫做“置信度”,它表示的是当你购买了商品 A,会有多大的概率购买商品 B,在这个例子中,置信度(啤酒→尿布)=5/7=0.71,代表如果你购买了啤酒,会有 71% 的概率会购买尿布;置信度(啤酒→薯条)=3/7=0.43,代表如果你购买了啤酒,有 43% 的概率会购买薯条。
所以说置信度是个条件概念,指的是在 A 发生的情况下,B 发生的概率是多少。
我们在计算关联关系的时候,往往需要规定最小支持度和最小置信度,这样才可以寻找大于等于最小支持度的频繁项集,以及在频繁项集的基础上,大于等于最小置信度的关联规则。
使用 MADlib+PostgreSQL 完成购物数据的关联分析
针对上面的购物数据关联分析的案例我们可以使用工具自带的关联规则进行分析,下面我们演示使用 PostgreSQL 数据库在 Madlib 工具中都可以找到相应的关联规则,通过写 SQL 的方式就可以完成关联规则的调用分析。
开发环境
- Windows/MacOS
- Navicat Premium 11.2.7及以上
服务器环境
- Centos 7.6
- Docker
- PostgreSQL 9.6
- MADlib 1.4及以上
使用 Docker 安装 MADlib+PostgreSQL
拉取 docker 镜像(这个镜像提供了需要的 postgres 等环境,并没有安装 madlib) :
docker pull madlib/postgres_9.6:latest
下载 MADlib github 源码. 假定下载的源码位置为 /home/git-repo/github/madlib:
cd /home/git-repo/github && git clone git@github.com:apache/madlib.git
启动容器,并建立本机目录与容器中系统的路径映射,共享的目录在容器和本机之间是读写共享的。
docker run -d -it --name madlib -v /home/git-repo/github/madlib:/incubator-madlib/ madlib/postgres_9.6
启动容器后,连接容器编译 MADlib 组件,编译用时约 30 分钟:
docker exec -it madlib bash
mkdir /incubator-madlib/build-docker
cd /incubator-madlib/build-docker
cmake ..
make
make doc
make install
在容器中安装 MADlib:
src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres install
运行 MADlib 测试:
# Run install check, on all modules:
src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres install-check
# Run install check, on a specific module, say svm:
src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres install-check -t svm
# Run dev check, on all modules (more comprehensive than install check):
src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres dev-check
# Run dev check, on a specific module, say svm:
src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres dev-check -t svm
# 如果需要,重新安装 Reinstall MADlib:
src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres reinstall
如果需要,先关掉并删除容器,删完再起新容器需要重新安装:
docker kill madlib
docker rm madlib
用配置好的容器制作新镜像,先查看容器 ID, 在用容器 ID 创建新镜像:
docker ps -a
docker commit <container id> my/madlib_pg9.6_dev
用新镜像创建新容器:
docker run -d -it -p 5432:5432 --name madlib_dev -v /home/my/git-repo/github/madlib:/incubator-madlib/ madlib/postgres_9.6
连接容器进行交互(发现新容器还是没有安装,但是不用编译了,安装也很快,装完测试一下)
docker exec -it madlib_dev bash
cd /incubator-madlib/build-docker
src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres install
src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres install-check
使用 Navicat 远程连接 PostgreSQL(假定没有修改登录用户和密码,默认没有密码)
最后,新建表并初始化数据:
使用 SQL 完成关联规则的调用分析
最后使用 SQL + MADlib 进行关联分析,这里我们设定了参数最小支持度为 0.25,最小置信度为 0.5。根据条件生成 transactions 中的关联规则,如下所示:
SELECT * FROM madlib.assoc_rules( .25, -- 支持度
.5, -- 置信度
'trans_id', -- Transaction id 字段
'product', -- Product 字段
'test_data', -- 输入数据
NULL, -- 输出模式
TRUE -- 详细输出
);
查询结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0TlxsX0M-1592728193789)(media/15777852880253/15778524671785.jpg)]](https://img-blog.csdnimg.cn/20200621163549784.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3p1b3pld2Vp,size_16,color_FFFFFF,t_70)
关联规则存储在 assoc_rules 表中:
SELECT * FROM assoc_rules
ORDER BY support DESC, confidence DESC;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FRk74l6h-1592728193790)(media/15777852880253/15778525462568.jpg)]](https://img-blog.csdnimg.cn/20200621163556895.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3p1b3pld2Vp,size_16,color_FFFFFF,t_70)
注意:
关联规则会始终创建一个名为的表assoc_rules。如果要保留多个关联规则表,请在再次运行之前复制该表。
使用 SQL+Python 完成购物数据的关联分析
除此以外,我们还可以直接使用 SQL 完成数据的查询,然后通过 Python 的机器学习工具包完成关联分析。
开发环境
- Windows/MacOS
- Navicat Premium 11.2.7及以上
- Python 3.6
服务器环境
- Centos 7.6
- Docker
- MySQL 5.7
使用 Docker 安装 MySQL
拉取官方镜像(我们这里选择5.7,如果不写后面的版本号则会自动拉取最新版):
docker pull mysql:5.7
检查是否拉取成功:
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/mysql 5.7 db39680b63ac 2 days ago 437 MB
启动容器:
docker run -p 3306:3306 --name mymysql -v $PWD/conf:/etc/mysql/conf.d -v $PWD/logs:/logs -v $PWD/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
- –name:容器名,此处命名为 mymysql;
- -e:配置信息,此处配置 mysql 的 root 用户的登陆密码;
- -p:端口映射,此处映射 主机 3306 端口到容器的 3306 端口;
- -d:源镜像名,此处为 mysql:5.7;
- -v:主机和容器的目录映射关系,":"前为主机目录,之后为容器目录。
检查容器是否正常运行:
[root@VM_0_10_centos ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d1e682cfdf76 mysql:5.7 "docker-entrypoint..." 14 seconds ago Up 13 seconds 0.0.0.0:3306->3306/tcp, 33060/tcp mymysql
可以看到容器 ID、容器的源镜像、启动命令、创建时间、状态、端口映射信息、容器名字。
进入 docker 本地连接 MySQL 客户端:
sudo docker exec -it mymysql bash
mysql -u root -p
设置远程访问账号,并授权远程连接:
CREATE USER 'zuozewei'@'%' IDENTIFIED WITH mysql_native_password BY 'zuozewei';
GRANT ALL PRIVILEGES ON *.* TO 'zuozewei'@'%';
使用 Navicat 远程连接 MySQL,新建数据库并初始化数据。
编写 Python 脚本完成数据分析
首先我们通过 SQLAlchemy 来完成 SQL 查询,使用 efficient_apriori 工具包的 Apriori 算法。
整个工程一共包括 3 个部分:
- 第一个部分为数据加载,首先我们通过
sql.create_engine创建 SQL 连接,然后从数据集表中读取全部的数据加载到 data 中。这里需要配置 MySQL 账户名和密码; - 第二步为数据预处理。我们还需要得到一个 transactions 数组,里面包括了每笔订单的信息,其中每笔订单是以集合的形式进行存储的,这样相同的订单中 item 就不存在重复的情况,同时也可以使用 Apriori 工具包直接进行计算;
- 最后一步,使用 Apriori 工具包进行关联分析,这里我们设定了参数 min_support=0.25,min_confidence=0.5,也就是最小支持度为 0.25,最小置信度为 0.5。根据条件找出 transactions 中的频繁项集 itemsets 和关联规则 rules。
下载依赖库:
#pip3 install 包名 -i 源的url 临时换源
#清华大学源:https://pypi.tuna.tsinghua.edu.cn/simple/
# 强大的数据结构库,用于数据分析,时间序列和统计等
pip3 install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
# python的orm程序
pip3 install SQLAlchemy -i https://pypi.tuna.tsinghua.edu.cn/simple/
# Apriori算法的高效纯Python实现
pip3 install efficient-apriori -i https://pypi.tuna.tsinghua.edu.cn/simple/
# MySQL驱动
pip3 install mysql-connector -i https://pypi.tuna.tsinghua.edu.cn/simple/
具体的代码如下:
from efficient_apriori import apriori
import sqlalchemy as sql
import pandas as pd
'''
数据加载
'''
# 创建数据库连接
engine = sql.create_engine('mysql+mysqlconnector://zuozewei:zuozewei@server_ip/SQLApriori')
# 查询数据
query = 'SELECT * FROM test_data'
# 加载到 data 中
data = pd.read_sql_query(query, engine)
'''
数据预处理
'''
# 得到一维数组 orders_series,并且将 Transaction 作为 index, value 为 Item 取值
orders_series = data.set_index('trans_id')['product']
# 将数据集进行格式转换
transactions = []
temp_index = 0
for i, v in orders_series.items():
if i != temp_index:
temp_set = set()
temp_index = i
temp_set.add(v)
transactions.append(temp_set)
else:
temp_set.add(v)
'''
数据分析
'''
# 挖掘频繁项集和频繁规则
itemsets, rules = apriori(transactions, min_support=0.25, min_confidence=0.5)
print('频繁项集:', itemsets)
print('关联规则:', rules)
运行结果:
频繁项集: {
1: {('beer',): 7, ('chips',): 3, ('diapers',): 5},
2: {('beer', 'chips'): 3, ('beer', 'diapers'): 5, ('chips', 'diapers'): 2},
3: {('beer', 'chips', 'diapers'): 2}
}
关联规则: [
{chips} -> {beer},
{diapers} -> {beer},
{beer} -> {diapers},
{chips} -> {diapers},
{chips, diapers} -> {beer},
{beer, chips} -> {diapers},
{chips} -> {beer, diapers}
]
从结果中我们能看到购物组合中:
- 商品个数为 1 的频繁项集有 3 种,分别为 beer(啤酒)、chips(薯条)、diapers(尿布) 等;
- 商品个数为 2 的频繁项集有 3 种,包括{beer(啤酒), chips(薯条)},{beer(啤酒), diapers(尿布)},{chips(薯条), diapers(尿布)}等;
- 其中关联规则有 7 种,包括了购买 chips(薯条) 的人也会购买 beer(啤酒),购买 diapers(尿布)的同时也会 beer(啤酒) 等。
总结
通过 SQL 完成数据分析、机器学习还是推荐使用到 Python,因为这是 Python 所擅长的。通过今天的例子我们应该能看到采用 SQL 作为数据查询和分析的入口是一种数据全栈的思路,对于数据开发人员来说降低了数据分析的技术门槛。相信在当今的 DT 时代,我们的业务增长会越来越依靠于 SQL 引擎 + AI 引擎。
参考文献:
- [1]:http://madlib.apache.org/docs/latest/group__grp__assoc__rules.html
- [2]:https://sql-machine-learning.github.io/
- [3]:https://www.jianshu.com/p/8e1e64c08cb7
- [4]:《数据分析实战45讲》陈旸 清华大学计算机博士

- 点赞
- 收藏
- 关注作者
评论(0)