数据库sql优化总结之1-百万级数据库优化方案+案例分析

目录
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
3、应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
项目背景
有三张百万级数据表
知识点表(ex_subject_point)9,316条数据
试题表(ex_question_junior)2,159,519条数据 有45个字段
知识点试题关系表(ex_question_r_knowledge)3,156,155条数据
测试数据库为:mysql (5.7)
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
案例分析:
-
SELECT ex_question_junior.QUESTION_ID
-
FROM ex_question_junior
-
WHERE ex_question_junior.GRADE_ID=1
执行时间:17.609s (多次执行,在17s左右徘徊)
优化后:给GRADE_ID字段添加索引后
执行时间为:11.377s(多次执行,在11s左右徘徊)
备注:我们一般在什么字段上建索引?
这是一个非常复杂的话题,需要对业务及数据充分分析后再能得出结果。主键及外键通常都要有索引,其它需要建索引的字段应满足以下条件:
a、字段出现在查询条件中,并且查询条件可以使用索引;
b、语句执行频率高,一天会有几千次以上;
c、通过字段条件可筛选的记录集很小,那数据筛选比例是多少才适合?
这个没有固定值,需要根据表数据量来评估,以下是经验公式,可用于快速评估:
小表(记录数小于10000行的表):筛选比例<10%;
大表:(筛选返回记录数)<(表总记录数*单条记录长度)/10000/16
单条记录长度≈字段平均内容长度之和+字段数*2
以下是一些字段是否需要建B-TREE索引的经验分类:

2、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
select id from t where num is null
最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.
备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL。
不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num = 0
案例分析:
在mysql数据库中对字段进行null值判断,是不会放弃使用索引而进行全表扫描的。
-
SELECT ex_question_junior.QUESTION_ID
-
FROM ex_question_junior
-
WHERE IS_USE is NULL
执行时间是:11.729s
-
SELECT ex_question_junior.QUESTION_ID
-
FROM ex_question_junior
-
WHERE IS_USE =0
执行时间是12.253s
时间几乎一样。
3、应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
案例分析:
在mysql数据库中where 子句中使用 != 或 <> 操作符,引擎不会放弃使用索引。
-
EXPLAIN
-
SELECT ex_question_junior.QUESTION_ID
-
FROM ex_question_junior
-
WHERE ex_question_junior.GRADE_ID !=15

执行时间是:17.579s
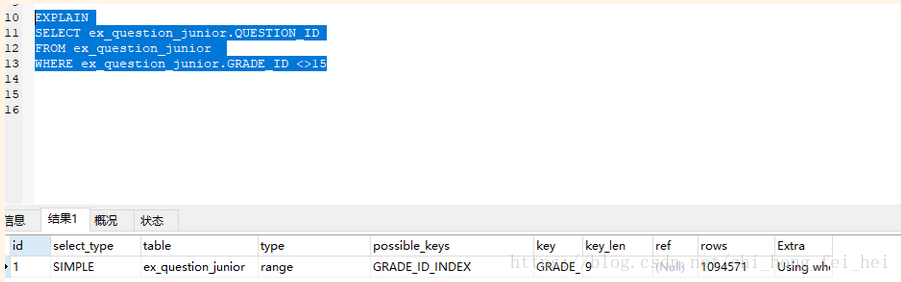
执行时间是:16.966s
4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
案例分析:
GRADE_ID字段有索引,QUESTION_TYPE没索引
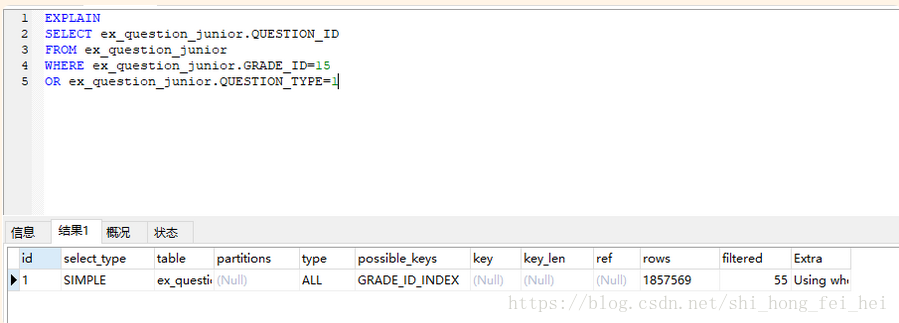
执行时间是:11.661s
优化方案:
通过union all 方式,把有索引字段和非索引字段分开。索引字段就有效果了

执行时间是:11.811s
但是,非索引字段依然查询速度会很慢,所以查询条件,能加索引的尽量加索引
5.in 和 not in 也要慎用,否则会导致全表扫描
案例分析
注:在mysql数据库中where 子句中对索引字段使用 in 和 not in操作符,引擎不会放弃使用索引。

注:在mysql数据库中where 子句中对不是索引字段使用 in 和 not in操作符,会导致全表扫描。
案例分析2:
用between和in的区别
-
SELECT ex_question_junior.QUESTION_ID
-
FROM ex_question_junior
-
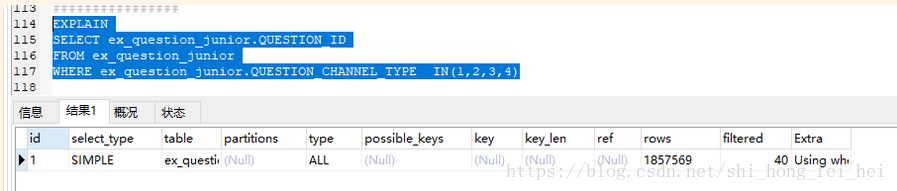
WHERE ex_question_junior.QUESTION_TYPE IN(1,2,3,4)
执行时间为1.082s
-
SELECT ex_question_junior.QUESTION_ID
-
FROM ex_question_junior
-
WHERE ex_question_junior.QUESTION_TYPE between 1 and 4
执行时间为0.924s
时间上是相差不多的
案例分析3:
用exists 和 in区别:结论
用exists 和 in区别:结论
1. in()适合B表比A表数据大的情况(A<B)
select * from A
where id in(select id from B)
2. exists()适合B表比A表数据小的情况(A>B)
select * from A
where exists(
select 1 from B where B.id = A.id
)
3.当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用.语法
select * from A
where id in(select id from B)
ex_question_r_knowledge表数据量大,ex_subject_point表数据量小
****************************************************************************
ex_question_r_knowledge(A)表数据量大,ex_subject_point表数据量小(B)(A>B)
用exists适合
-
SELECT *
-
FROM ex_question_r_knowledge
-
WHERE ex_question_r_knowledge.SUBJECT_POINT_ID IN
-
(
-
SELECT ex_subject_point.SUBJECT_POINT_ID
-
FROM ex_subject_point
-
WHERE ex_subject_point.SUBJECT_ID=7
-
)
-
SELECT *
-
FROM ex_question_r_knowledge
-
WHERE exists
-
(
-
SELECT 1
-
FROM ex_subject_point
-
WHERE ex_subject_point.SUBJECT_ID=7
-
AND ex_subject_point.SUBJECT_POINT_ID = ex_question_r_knowledge.SUBJECT_POINT_ID
-
)
执行时间是:13.537s
*************************************************************************
ex_subject_point表数据量小(A),ex_question_r_knowledge(B)表数据量大(A<B)
用in适合
-
SELECT *
-
FROM ex_subject_point
-
WHERE
-
ex_subject_point.SUBJECT_POINT_ID IN( SELECT
-
ex_question_r_knowledge.SUBJECT_POINT_ID FROM
-
ex_question_r_knowledge WHERE
-
ex_question_r_knowledge.GRADE_TYPE=2 )
-
SELECT * FROM ex_subject_point WHERE
-
ex_subject_point.SUBJECT_POINT_ID IN( SELECT
-
ex_question_r_knowledge.SUBJECT_POINT_ID FROM
-
ex_question_r_knowledge WHERE
-
ex_question_r_knowledge.GRADE_TYPE=2 )
执行时间是:1.554s
-
SELECT *
-
FROM ex_subject_point
-
WHERE exists(
-
SELECT ex_question_r_knowledge.SUBJECT_POINT_ID
-
FROM ex_question_r_knowledge
-
WHERE ex_question_r_knowledge.GRADE_TYPE=2
-
AND ex_question_r_knowledge.SUBJECT_POINT_ID= ex_subject_point.SUBJECT_POINT_ID
-
)
执行时间是:11.978s
6、like模糊全匹配也将导致全表扫描
案例分析
-
EXPLAIN
-
SELECT *
-
FROM ex_subject_point
-
WHERE ex_subject_point.path like "%/11/%"
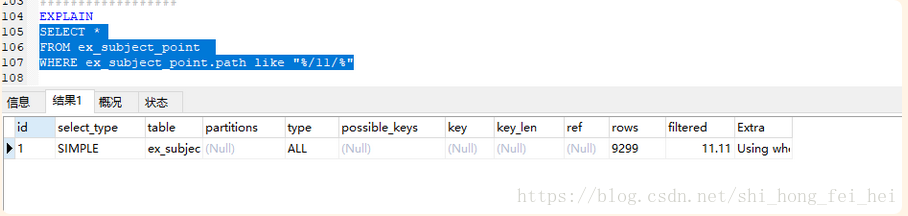
若要提高效率,可以考虑全文检索。lucene了解一下。或者其他可以提供全文索引的nosql数据库,比如tt server或MongoDB
还会陆续更新,还有几个小节。
昨天晚上突发奇想,like 模糊全匹配,会导致全表扫描,那模糊后匹配和模糊前匹配也会是全表扫描吗?
今天开电脑,做了下测试。结果如下:
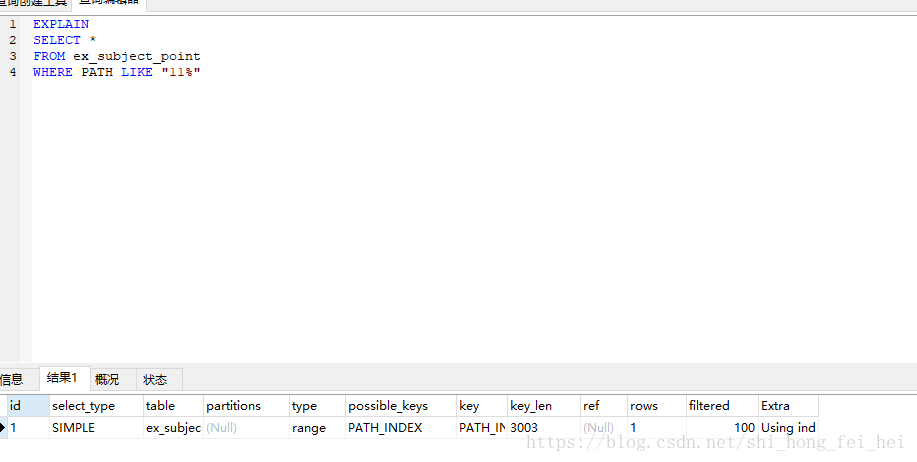
like模糊后匹配,不会导致全表扫描
like模糊前匹配,会导致全表扫描
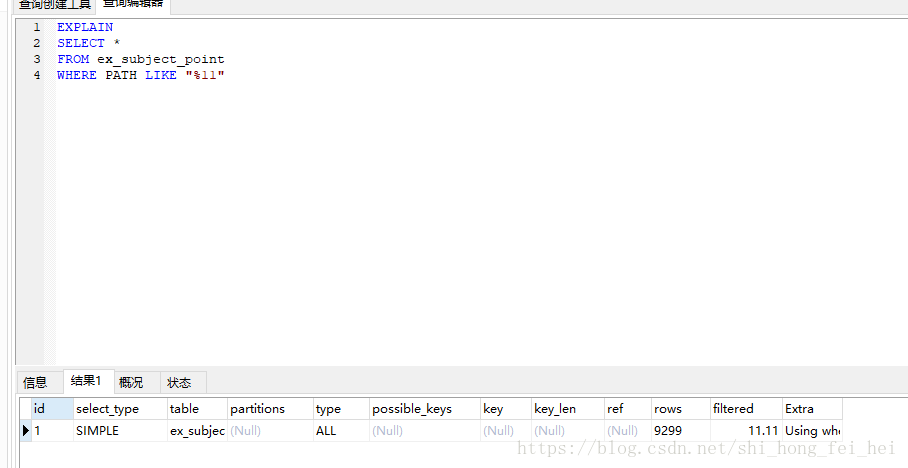
MY SQL的原理就是这样的,LIKE模糊全匹配会导致索引失效,进行全表扫描;LIKE模糊前匹配也会导致索引失效,进行全表扫描;但是LIKE模糊后匹配,索引就会有效果。
参考:
https://mp.weixin.qq.com/s?__biz=MzIxMjg4NDU1NA==&mid=2247483684&idx=1&sn=f5abc60e696b2063e43cd9ccb40df101&chksm=97be0c01a0c98517029ff9aa280b398ab5c81fa1fcfe0e746222a3bfe75396d9eea1e249af38&mpshare=1&scene=1&srcid=0606XGHeBS4RBZloVv786wBY#rd
***************************************************************************
作者:小虚竹
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。
我不是个伟大的程序员,我只是个有着一些优秀习惯的好程序员而己
文章来源: xiaoxuzhu.blog.csdn.net,作者:小虚竹,版权归原作者所有,如需转载,请联系作者。
原文链接:xiaoxuzhu.blog.csdn.net/article/details/81022161

- 点赞
- 收藏
- 关注作者
评论(0)