爬虫学习(10):xpath爬取包图网高清模板视频

【摘要】
暂时我就没有发xpath基础知识了,编辑太浪费时间了,需要了解或者有问题的可以加我群问我就好了,我也正在努力学习中,不废话了,上代码,解释都在注释. 先看效果:
开始的时候下载的还不是那么高清,后来我...
暂时我就没有发xpath基础知识了,编辑太浪费时间了,需要了解或者有问题的可以加我群问我就好了,我也正在努力学习中,不废话了,上代码,解释都在注释.
先看效果:
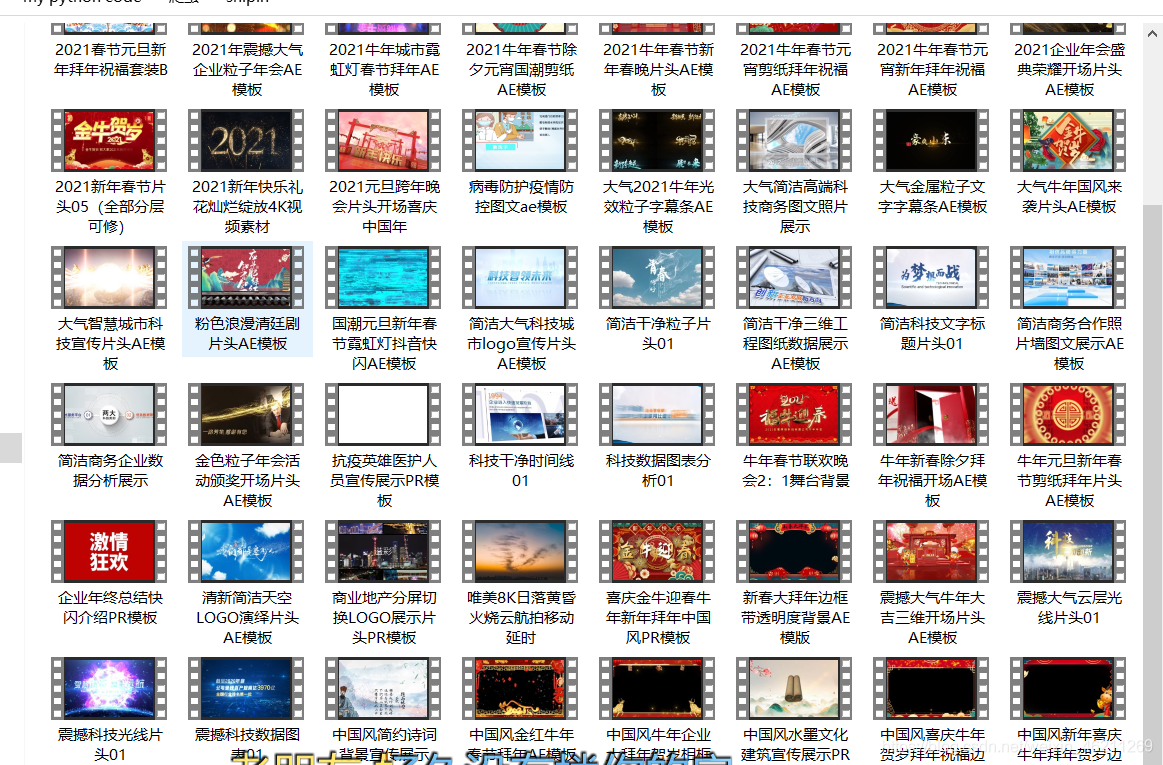
开始的时候下载的还不是那么高清,后来我琢磨半天才下载到高清的模板视频:
import requests#发送请求
from lxml import etree#处理数据
header={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}#请求头
url='https://ibaotu.com/shipin/7-0-0-0-0-1.html'#网址
response=requests.get(url=url,headers=header)#发送请求
html_text=response.content.decode('utf-8')#编译
html=etree.HTML(html_text)#自动修正html文档
video_url=html.xpath('//div[@class="video-play"]/video/@src')#视频网址
video_names=html.xpath('//span[@class="video-title"]/text()')#视频名称
# print(video_url,video_names)
path='D://code//my python code//爬虫//shipin//'#视频存放地址
for src,title in zip(video_url,video_names):
video_url = "https:" + src#视频url
url=video_url.replace(".mp4_10s","")#增加画质url
file_name = (title + ".mp4")#文件名
response=requests.get(url=url,headers=header)#在此发送新的请求
with open(path+file_name,'wb') as f: #把文件写入path地址
f.write(response.content)
print("%s下载成功"%file_name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
还有问题就自己加我群问我吧,其实我觉得解释挺详细了,加油吧。
文章来源: chuanchuan.blog.csdn.net,作者:川川菜鸟,版权归原作者所有,如需转载,请联系作者。
原文链接:chuanchuan.blog.csdn.net/article/details/113577762

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)