爬虫学习(12):爬取诗词名句网并且下载保存

【摘要】
用BeautifulSoup爬取并且下载。仅仅用作学习用途哈,不然又侵权了。 效果:
由于我是正在自学爬虫,不是很能找到非常优化的办法,是一名计算机大二学生,代码可能不是很好,还请大神指点,这是我...
用BeautifulSoup爬取并且下载。仅仅用作学习用途哈,不然又侵权了。
效果:
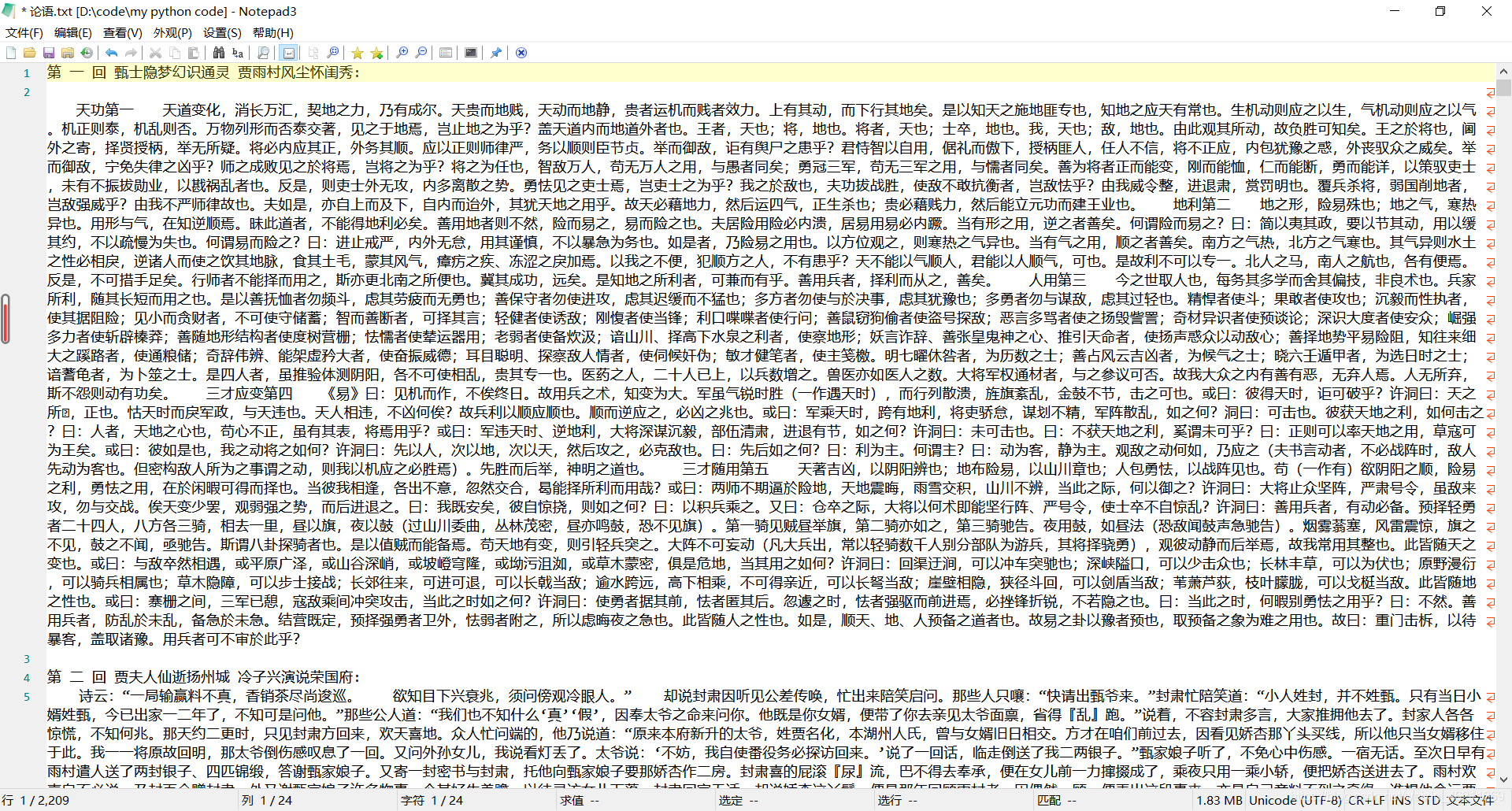
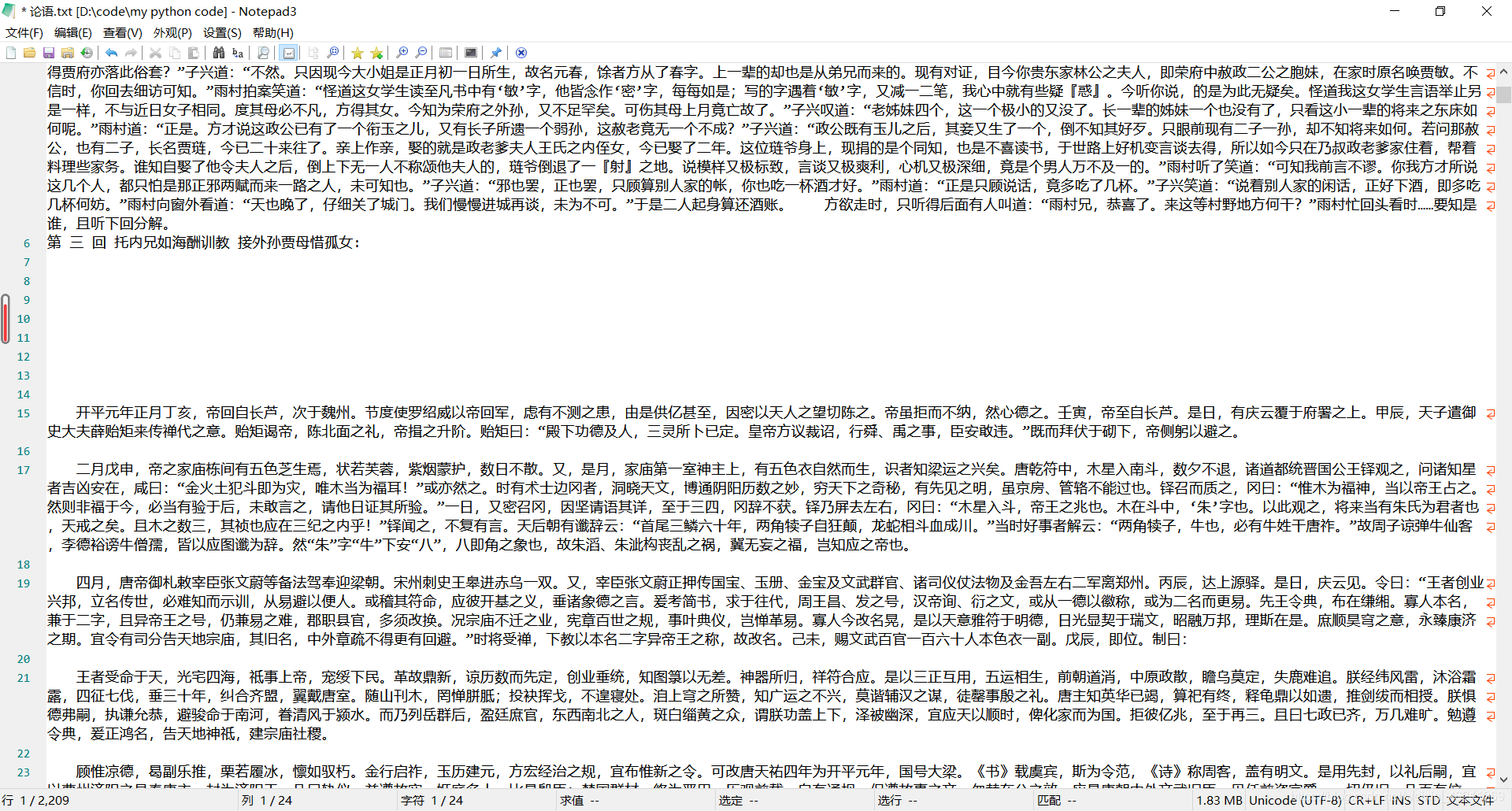
由于我是正在自学爬虫,不是很能找到非常优化的办法,是一名计算机大二学生,代码可能不是很好,还请大神指点,这是我扣扣群:970353786,希望更多喜欢学习python的可以跟我一起学习交流。
上代码:
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
url = 'https://www.shicimingju.com/book/hongloumeng.html'
page_text = requests.get(url=url,headers=headers).content.decode('utf-8')
soup = BeautifulSoup(page_text,'lxml')
mulu=soup.find_all(attrs={'class':'book-mulu'})
# mulu=soup.select('.book-mulu')
# print(mulu)
fp = open('./论语.txt','w',encoding='utf-8')
for ul in mulu:
a=ul.find_all(name='a')
for i in a:
title = i.string
new_url = 'https://www.shicimingju.com' + i['href']
# print(new_url)
# print(title)
html=requests.get(url=new_url,headers=headers).content.decode('utf-8')
new_soup=BeautifulSoup(html,'lxml')
# print(soup)
for wenben in new_soup.find_all('div',{'class':'chapter_content'}):
print(wenben.text)
c=wenben.text
fp.write(title + ':' + c + '\n')
print('下载成功')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
有问题群里找我,或者这里留言都可以
文章来源: chuanchuan.blog.csdn.net,作者:川川菜鸟,版权归原作者所有,如需转载,请联系作者。
原文链接:chuanchuan.blog.csdn.net/article/details/113668163

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)