Python词频统计的3种方法

【摘要】
大家好,我是小小明。
上次,我分享了《100毫秒过滤一百万字文本的停用词》,这次我将分享如何进行词频统计。
当然我们首先需要准备好数据:
数据准备
import jieba
with open(...
大家好,我是小小明。
上次,我分享了《100毫秒过滤一百万字文本的停用词》,这次我将分享如何进行词频统计。
当然我们首先需要准备好数据:
数据准备
import jieba
with open("D:/hdfs/novels/天龙八部.txt", encoding="gb18030") as f:
text = f.read()
with open('D:/hdfs/novels/names.txt', encoding="utf-8") as f:
for line in f:
if line.startswith("天龙八部"):
names = next(f).split()
break
for word in names:
jieba.add_word(word)
# 加载停用词
with open("stoplist.txt", encoding="utf-8-sig") as f:
stop_words = f.read().split()
stop_words.extend(['天龙八部', '\n', '\u3000', '目录', '一声', '之中', '只见'])
stop_words = set(stop_words)
all_words = [word for word in cut_word if len(word) > 1 and word not in stop_words]
print(len(all_words), all_words[:20])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
结果:
216435 ['天龙', '释名', '青衫', '磊落', '险峰', '行玉壁', '月华', '明马', '疾香', '幽崖', '高远', '微步', '生家', '子弟', '家院', '计悔情', '虎啸', '龙吟', '换巢', '鸾凤']
- 1
统计词频排名前N的词
原始字典自写代码统计:
wordcount = {}
for word in all_words:
wordcount[word] = wordcount.get(word, 0)+1
sorted(wordcount.items(), key=lambda x: x[1], reverse=True)[:10]
- 1
- 2
- 3
- 4
结果:
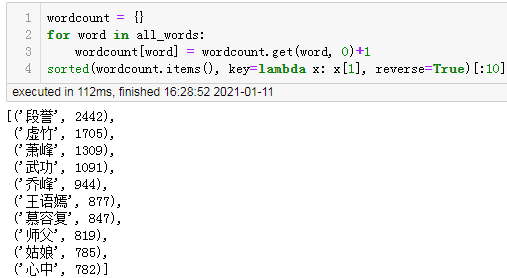
使用计数类进行词频统计:
from collections import Counter
wordcount = Counter(all_words)
wordcount.most_common(10)
- 1
- 2
- 3
- 4
结果:
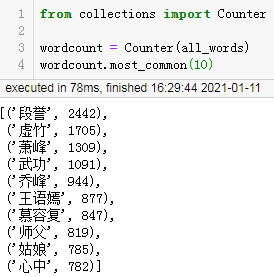
使用pandas进行词频统计:
pd.Series(all_words).value_counts().head(10)
- 1
结果:

从上面的结果可以看到使用collections的Counter类来计数会更快一点,而且编码也最简单。
分词过程中直接统计词频
Pandas只能对已经分好的词统计词频,所以这里不再演示。上面的测试表示,Counter直接对列表进行计数比pyhton原生带快,但循环中的表现还未知,下面再继续测试一下。
首先使用原生API直接统计词频并排序:
%%time
wordcount = {}
for word in jieba.cut(text):
if len(word) > 1 and word not in stop_words:
wordcount[word] = wordcount.get(word, 0)+1
print(sorted(wordcount.items(), key=lambda x: x[1], reverse=True)[:10])
- 1
- 2
- 3
- 4
- 5
- 6
结果:
[('段誉', 2496), ('说道', 2151), ('虚竹', 1633), ('萧峰', 1301), ('武功', 1095), ('阿紫', 922), ('阿朱', 904), ('乔峰', 900), ('王语嫣', 877), ('慕容复', 871)]
Wall time: 6.04 s
- 1
- 2
下面我们使用Counter统计词频并排序:
%%time
wordcount = Counter()
for word in jieba.cut(text):
if len(word) > 1 and word not in stop_words:
wordcount[word] += 1
print(wordcount.most_common(10))
- 1
- 2
- 3
- 4
- 5
- 6
结果:
[('段誉', 2496), ('说道', 2151), ('虚竹', 1633), ('萧峰', 1301), ('武功', 1095), ('阿紫', 922), ('阿朱', 904), ('乔峰', 900), ('王语嫣', 877), ('慕容复', 871)]
Wall time: 6.21 s
- 1
- 2
可以看到Counter在循环中计数时反而慢了一丁点,但由于Counter类整体性能更加,编写起来简单,所以一般都用Counter进行统计计数。
总结
今天我向你分享了词频统计的三种方法,本期还同步分享了 set集合和字典的基本原理,希望你能学会所获。
我是小小明,咱们下期再见。
文章来源: xxmdmst.blog.csdn.net,作者:小小明-代码实体,版权归原作者所有,如需转载,请联系作者。
原文链接:xxmdmst.blog.csdn.net/article/details/112486090

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)