Pandas实例|药品发放汇总与excel表数据回填

【摘要】
作者:小小明
需求
有一个卫生院需要统计一下每个村扶贫药品发放的数据。
数据形式是在一个文件夹下,每个村的数据都存储在一个独立的excel文件中,需要将每个村的数据进行汇总,汇总形式如下:...
作者:小小明
需求
有一个卫生院需要统计一下每个村扶贫药品发放的数据。
数据形式是在一个文件夹下,每个村的数据都存储在一个独立的excel文件中,需要将每个村的数据进行汇总,汇总形式如下:
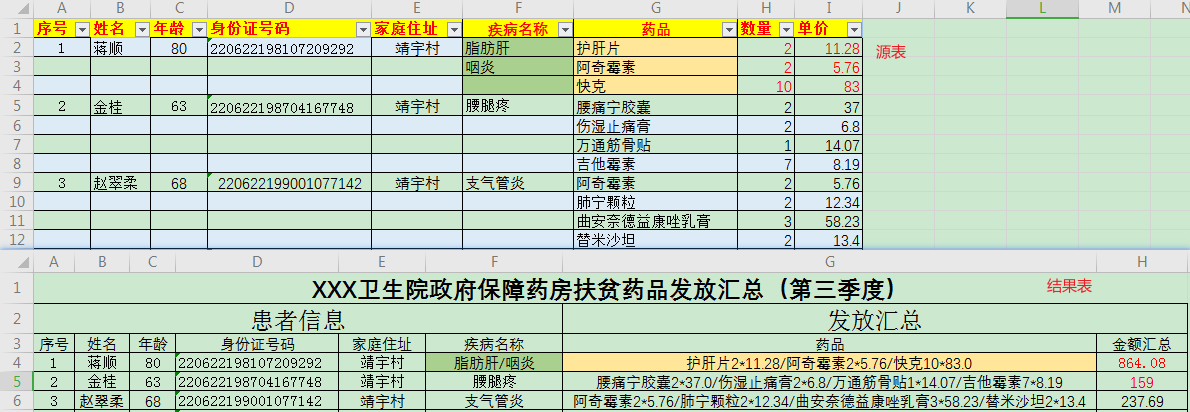
数据处理流程
首先读取该文件夹下的其中一个文件进行测试:
from pathlib import Path
import pandas as pd
for name in Path(r"F:\jupyter\test\药品数据汇总\基础表").glob("[!~]*.xls*"):
filename = str(name.absolute())
df = pd.read_excel(filename, sheet_name="基础表")
break
df.head(10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

我们需要将指定的列向下填充缺失值用于分组聚合,如果直接调用datafream的fillna方法会将整个表所有的列都填充,官方文档对该方法并没有出一个只填充指定列的参数。
所以我采用以下方法对指定的列进行填充:
group_columns = ["序号", "姓名", "年龄", "身份证号码", "家庭住址"]
for c in group_columns:
df[c].ffill(inplace=True)
df.head()
- 1
- 2
- 3
- 4
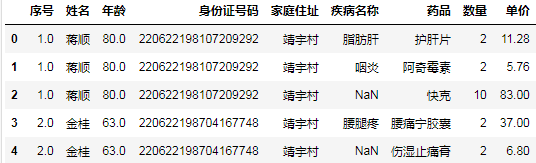
注意:ffill方法等价于fillna(method=‘ffill’)
序号和年龄列由于一开始存在缺失值,导致转换成浮点数类型,现在已经填充后,我们可以将其转换回来:
df.序号 = df.序号.astype("int16")
df.年龄 = df.年龄.astype("int16")
- 1
- 2
注意:int16表示2字节的整数,这么写是考虑到2字节的整数足够装的下年龄,可以节约一点内存,速度也会更快。
根据结果要求,计算一些辅助列:
df.eval("金额汇总=数量*单价", inplace=True)
df.药品 = df.药品+df.数量.astype(str)+"*"+df.单价.astype(str)
df.head()
- 1
- 2
- 3
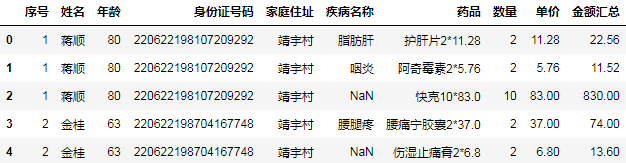
然后分组聚合:
def join_func(s):
return "/".join(s.dropna())
result = df.groupby(group_columns, as_index=False).agg({"疾病名称": join_func, "药品": join_func, "金额汇总": "sum"})
result
- 1
- 2
- 3
- 4
- 5
数据处理思路2
区别在于,前面的代码的思路是,先填充指定列,聚合时去空值再拼接。这里的思路是一次性全部填充,聚合时去除重复值再拼接。
完整代码:
import pandas as pd
def join_func(s):
return s.drop_duplicates().str.cat(sep='/')
df = pd.read_excel('基础表/靖宇村.xlsx', sheet_name="基础表")
df.ffill(inplace=True)
df = df.astype({"序号": "int16", "年龄": "int16"}, copy=False)
df.eval("金额汇总=数量*单价", inplace=True)
df.药品 = df.药品+df.数量.astype(str)+"*"+df.单价.astype(str)
group_columns = ["序号", "姓名", "年龄", "身份证号码", "家庭住址"]
result = df.groupby(group_columns, as_index=False) \
.agg({"疾病名称": join_func, "药品": join_func, "金额汇总": "sum"})
result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
数据处理思路3
思路:只填充第一列,其余分组列只取第一项。
import pandas as pd
def join_func(s):
return s.str.cat(sep='/')
df = pd.read_excel('基础表/靖宇村.xlsx', sheet_name="基础表")
df.序号.ffill(inplace=True)
df.年龄.ffill(inplace=True)
df = df.astype({"序号": "int16", "年龄": "int16"}, copy=False)
df.eval("金额汇总=数量*单价", inplace=True)
df.药品 = df.药品+df.数量.astype(str)+"*"+df.单价.astype(str)
result = df.groupby("序号", as_index=False) \
.agg({"姓名": "first", "年龄": "first", "身份证号码": "first", "家庭住址": "first", "疾病名称": join_func, "药品": join_func, "金额汇总": "sum"})
result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
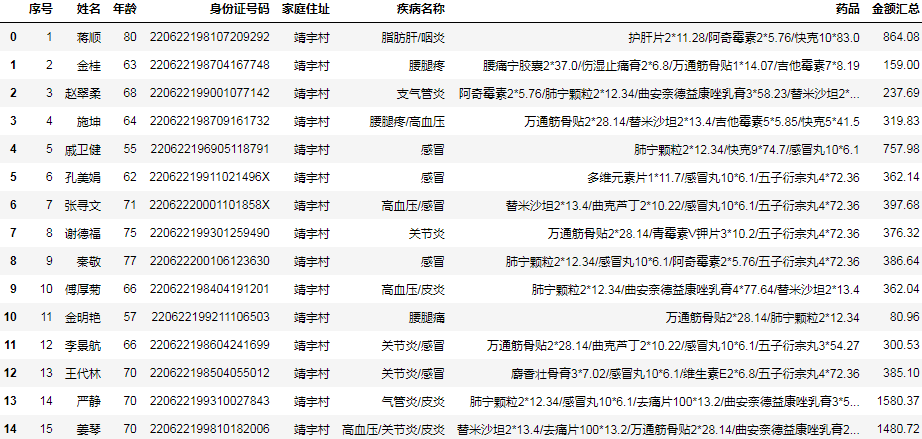
将结果写入模板文件
下面我们将结果写入到下面的模板文件中:
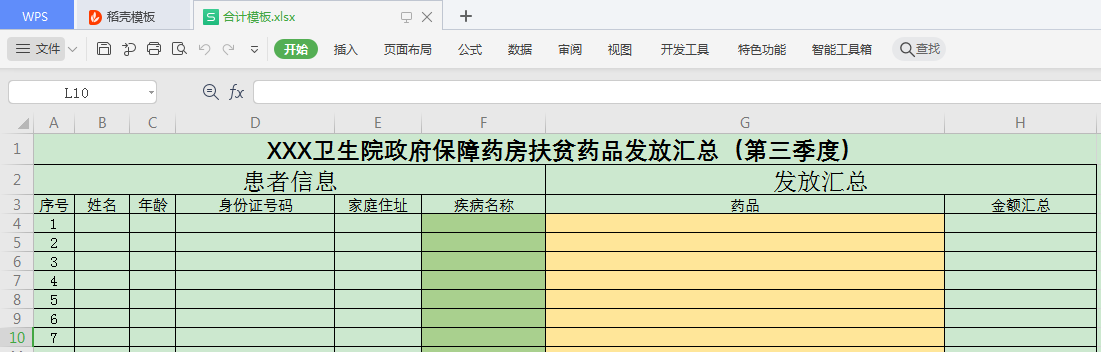
写出代码:
from openpyxl import load_workbook
book = load_workbook("合计模板.xlsx")
sheet = book["合计表"]
length = result.shape[0]
data = result.values
for i, row in enumerate(sheet[f"A4:H{length+3}"]):
for j, cell in enumerate(row):
cell.value = data[i, j]
book.save("结果表/靖宇村.xlsx")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果:

整体处理代码
已经全部测试完成,下面整理一下完整代码:
import os
from pathlib import Path
import pandas as pd
from openpyxl import load_workbook
import copy
if not os.path.exists("结果表"):
os.mkdir("结果表")
def join_func(s):
return "/".join(s.dropna())
group_columns = ["序号", "姓名", "年龄", "身份证号码", "家庭住址"]
for name in Path("基础表").glob("[!~]*.xls*"):
book = load_workbook("合计模板.xlsx")
sheet = book["合计表"]
filename = str(name.absolute())
df = pd.read_excel(filename, sheet_name="基础表")
df.ffill(inplace=True)
df = df.astype({"序号": "int16", "年龄": "int16"}, copy=False)
df.eval("金额汇总=数量*单价", inplace=True)
df.药品 = df.药品+df.数量.astype(str)+"*"+df.单价.astype(str)
group_columns = ["序号", "姓名", "年龄", "身份证号码", "家庭住址"]
result = df.groupby(group_columns, as_index=False) \
.agg({"疾病名称": join_func, "药品": join_func, "金额汇总": "sum"})
length = result.shape[0]
data = result.values
for i, row in enumerate(sheet[f"A4:H{length+3}"]):
for j, cell in enumerate(row):
cell.value = data[i, j]
book.save(f"结果表/{name.name}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
执行后,已经顺利得到每个村对应的汇总结果。
文章来源: xxmdmst.blog.csdn.net,作者:小小明-代码实体,版权归原作者所有,如需转载,请联系作者。
原文链接:xxmdmst.blog.csdn.net/article/details/113769118

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)