Kubernetes 集群监控 controller-manager & scheduler 组件

问题描述
在上篇 Kubernetes 集群监控 kube-prometheus 部署 我们实现 kube-prometheus 的安装,我们可以看到监控指标大部分的配置都是正常的,只有两个没有管理到对应的监控目标,比如 kube-controller-manager 和 kube-scheduler 这两个系统组件。
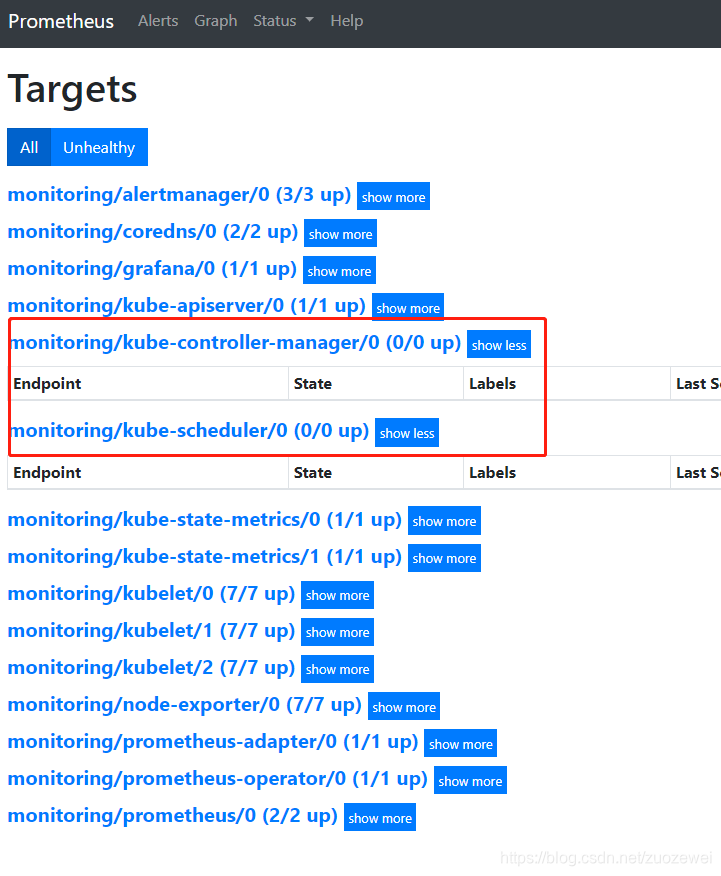
备注:
- controller-manager:负责管理集群各种资源,保证资源处于预期的状态。
- kube-scheduler:资源调度,负责决定将Pod放到哪个Node上运行。
问题分析
kube-scheduler
这其实就和 ServiceMonitor 的定义有关系了,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义:
$ vi serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s # 每30s获取一次信息
port: https-metrics # 对应 service 的端口名
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: k8s-app
namespaceSelector: # 表示去匹配某一命名空间中的service,如果想从所有的namespace中匹配用any: true
matchNames:
- kube-system
selector: # 匹配的 Service 的 labels,如果使用 mathLabels,则下面的所有标签都匹配时才会匹配该 service,如果使用 matchExpressions,则至少匹配一个标签的 service 都会被选择
matchLabels:
k8s-app: kube-scheduler
上面是一个典型的 ServiceMonitor 资源对象的声明方式,上面我们通过 selector.matchLabels 在 kube-system 这个命名空间下面匹配具有 k8s-app=kube-scheduler 这样的 Service,但是我们系统中根本就没有对应的 Service:
$ kubectl get svc -n kube-system -l k8s-app=kube-scheduler
No resources found.
所以我们需要去创建一个对应的 Service 对象,才能核 ServiceMonitor 进行关联。
kube-controller-manage
我们来查看一下 kube-controller-manager 的 ServiceMonito 资源的定义:
$ vi serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
metricRelabelings:
- action: drop
sourceLabels:
- __name__
- action: drop
regex: scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)
sourceLabels:
- __name__
- action: drop
regex: apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)
sourceLabels:
- __name__
- action: drop
regex: kubelet_docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)
sourceLabels:
- __name__
- action: drop
regex: reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)
sourceLabels:
- __name__
- action: drop
regex: etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)
sourceLabels:
- __name__
- action: drop
regex: transformation_(transformation_latencies_microseconds|failures_total)
sourceLabels:
- __name__
- action: drop
regex: (admission_quota_controller_adds|crd_autoregistration_controller_work_duration|APIServiceOpenAPIAggregationControllerQueue1_adds|AvailableConditionController_retries|crd_openapi_controller_unfinished_work_seconds|APIServiceRegistrationController_retries|admission_quota_controller_longest_running_processor_microseconds|crdEstablishing_longest_running_processor_microseconds|crdEstablishing_unfinished_work_seconds|crd_openapi_controller_adds|crd_autoregistration_controller_retries|crd_finalizer_queue_latency|AvailableConditionController_work_duration|non_structural_schema_condition_controller_depth|crd_autoregistration_controller_unfinished_work_seconds|AvailableConditionController_adds|DiscoveryController_longest_running_processor_microseconds|autoregister_queue_latency|crd_autoregistration_controller_adds|non_structural_schema_condition_controller_work_duration|APIServiceRegistrationController_adds|crd_finalizer_work_duration|crd_naming_condition_controller_unfinished_work_seconds|crd_openapi_controller_longest_running_processor_microseconds|DiscoveryController_adds|crd_autoregistration_controller_longest_running_processor_microseconds|autoregister_unfinished_work_seconds|crd_naming_condition_controller_queue_latency|crd_naming_condition_controller_retries|non_structural_schema_condition_controller_queue_latency|crd_naming_condition_controller_depth|AvailableConditionController_longest_running_processor_microseconds|crdEstablishing_depth|crd_finalizer_longest_running_processor_microseconds|crd_naming_condition_controller_adds|APIServiceOpenAPIAggregationControllerQueue1_longest_running_processor_microseconds|DiscoveryController_queue_latency|DiscoveryController_unfinished_work_seconds|crd_openapi_controller_depth|APIServiceOpenAPIAggregationControllerQueue1_queue_latency|APIServiceOpenAPIAggregationControllerQueue1_unfinished_work_seconds|DiscoveryController_work_duration|autoregister_adds|crd_autoregistration_controller_queue_latency|crd_finalizer_retries|AvailableConditionController_unfinished_work_seconds|autoregister_longest_running_processor_microseconds|non_structural_schema_condition_controller_unfinished_work_seconds|APIServiceOpenAPIAggregationControllerQueue1_depth|AvailableConditionController_depth|DiscoveryController_retries|admission_quota_controller_depth|crdEstablishing_adds|APIServiceOpenAPIAggregationControllerQueue1_retries|crdEstablishing_queue_latency|non_structural_schema_condition_controller_longest_running_processor_microseconds|autoregister_work_duration|crd_openapi_controller_retries|APIServiceRegistrationController_work_duration|crdEstablishing_work_duration|crd_finalizer_adds|crd_finalizer_depth|crd_openapi_controller_queue_latency|APIServiceOpenAPIAggregationControllerQueue1_work_duration|APIServiceRegistrationController_queue_latency|crd_autoregistration_controller_depth|AvailableConditionController_queue_latency|admission_quota_controller_queue_latency|crd_naming_condition_controller_work_duration|crd_openapi_controller_work_duration|DiscoveryController_depth|crd_naming_condition_controller_longest_running_processor_microseconds|APIServiceRegistrationController_depth|APIServiceRegistrationController_longest_running_processor_microseconds|crd_finalizer_unfinished_work_seconds|crdEstablishing_retries|admission_quota_controller_unfinished_work_seconds|non_structural_schema_condition_controller_adds|APIServiceRegistrationController_unfinished_work_seconds|admission_quota_controller_work_duration|autoregister_depth|autoregister_retries|kubeproxy_sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds|non_structural_schema_condition_controller_retries)
sourceLabels:
- __name__
- action: drop
regex: etcd_(debugging|disk|request|server).*
sourceLabels:
- __name__
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-controller-manager
参考 kube-scheduler 的介绍,这里也是通过 selector.matchLabels 在 kube-system 这个命名空间下面匹配具有 k8s-app=kube-controller-manager 这样的 Service,但是我们系统中根本就没有对应的 Service:
$ kubectl get svc -n kube-system -l k8s-app=kube-controller-manager
No resources found.
所以我们同样需要去创建一个对应的 Service 对象,才能核 ServiceMonitor 进行关联。
问题处理
创建对应 Service
创建 prometheus-kubeSchedulerService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
其中最重要的是上面 labels 和 selector 部分,labels 区域的配置必须和我们上面的 ServiceMonitor 对象中的 selector 保持一致,selector 下面配置的是 component=kube-scheduler,为什么会是这个 label 标签呢,我们可以去 describe 下 kube-scheduler 这个 Pod:
Name: kube-scheduler-k8s-master.novalocal
Namespace: kube-system
Priority: 2000000000
Priority Class Name: system-cluster-critical
Node: k8s-master.novalocal/172.16.106.200
Start Time: Thu, 20 Aug 2020 11:28:22 +0800
Labels: component=kube-scheduler
tier=control-plane
......
我们可以看到这个 Pod 具有 component=kube-scheduler 和 tier=control-plane 这两个标签,而前面这个标签具有更唯一的特性,所以使用前面这个标签较好,这样上面创建的 Service 就可以和我们的 Pod 进行关联了,直接创建即可:
$ kubectl apply -f prometheus-kubeSchedulerService.yaml
$ kubectl get svc -n kube-system -l k8s-app=kube-scheduler
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-scheduler ClusterIP None <none> 10251/TCP 16s
可以用同样的方式来修复下 kube-controller-manager 组件的监控,只需要创建一个如下所示的 Service 对象,只是端口改成 10252 即可:
$ vi prometheus-kubeControllerManagerService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: http-metrics
port: 10252
targetPort: 10252
如果是二进制部署还得创建对应的 Endpoints 对象将两个组件挂入到 kubernetes 集群内,然后通过 Service 提供访问,才能让 Prometheus 监控到。
更改 kubernetes 配置
由于 Kubernetes 集群是由 kubeadm 搭建的,其中 kube-scheduler 和 kube-controller-manager 默认绑定 IP 是 127.0.0.1 地址。Prometheus Operator 是通过节点 IP 去访问,所以我们将 kube-scheduler 绑定的地址更改成 0.0.0.0。
修改 kube-scheduler 配置
编辑 /etc/kubernetes/manifests/kube-scheduler.yaml 文件
$ vim /etc/kubernetes/manifests/kube-scheduler.yaml
将 command 的 bind-address 地址更改成 0.0.0.0
......
spec:
containers:
- command:
- kube-scheduler
- --bind-address=0.0.0.0 #改为0.0.0.0
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
......
修改 kube-controller-manager 配置
编辑 /etc/kubernetes/manifests/kube-controller-manager.yaml 文件
$ vim /etc/kubernetes/manifests/kube-controller-manager.yaml
将 command 的 bind-address 地址更改成 0.0.0.0
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=0.0.0.0 #改为0.0.0.0
......
新的问题
创建完成后,隔一小会儿后去 Prometheus 页面上查看 targets 下面 kube-scheduler 是否可以采集到指标数据了。
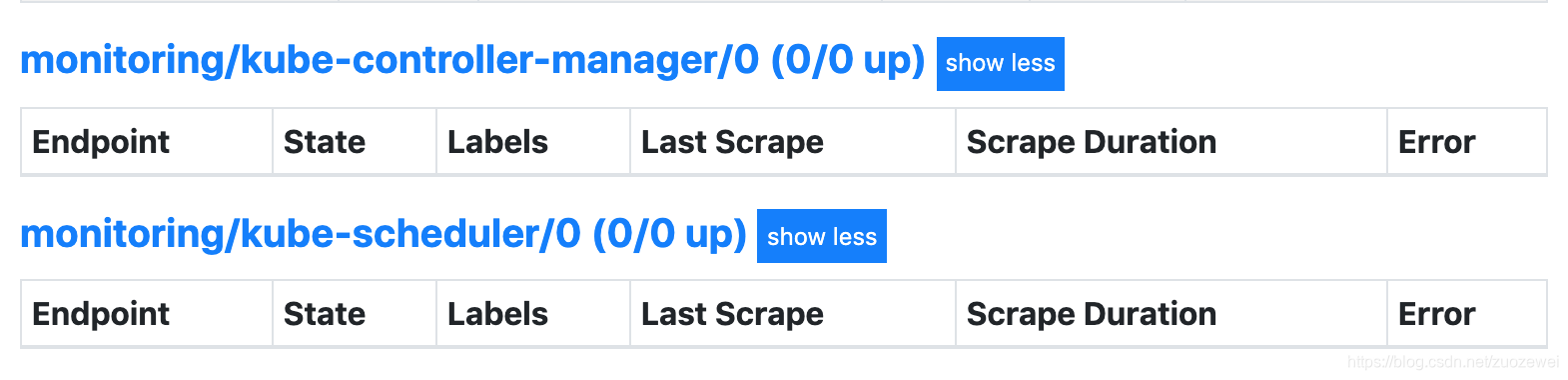
不过我们看到上述问题并没有解决。
通过对比,我们发现 ServiceMonitor 的资源在新版 v0.6.0 中的改动较大,于是我创建了两个旧版本的资源定义。
$ vi prometheus-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- interval: 30s # 每30s获取一次信息
port: http-metrics # 对应 service 的端口名
jobLabel: k8s-app
namespaceSelector: # 表示去匹配某一命名空间中的service,如果想从所有的namespace中匹配用any: true
matchNames:
- kube-system
selector: # 匹配的 Service 的 labels,如果使用 mathLabels,则下面的所有标签都匹配时才会匹配该 service,如果使用 matchExpressions,则至少匹配一个标签的 service 都会被选择
matchLabels:
k8s-app: kube-scheduler
$ vi prometheus-serviceMonitorKubeControllerManager.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: monitoring
spec:
endpoints:
- interval: 30s
metricRelabelings:
- action: drop
regex: etcd_(debugging|disk|request|server).*
sourceLabels:
- __name__
port: http-metrics
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-controller-manager
重新更新资源文件:
$ kubectl apply -f prometheus-serviceMonitorKubeControllerManager.yaml
$ kubectl apply -f prometheus-serviceMonitorKubeScheduler.yaml
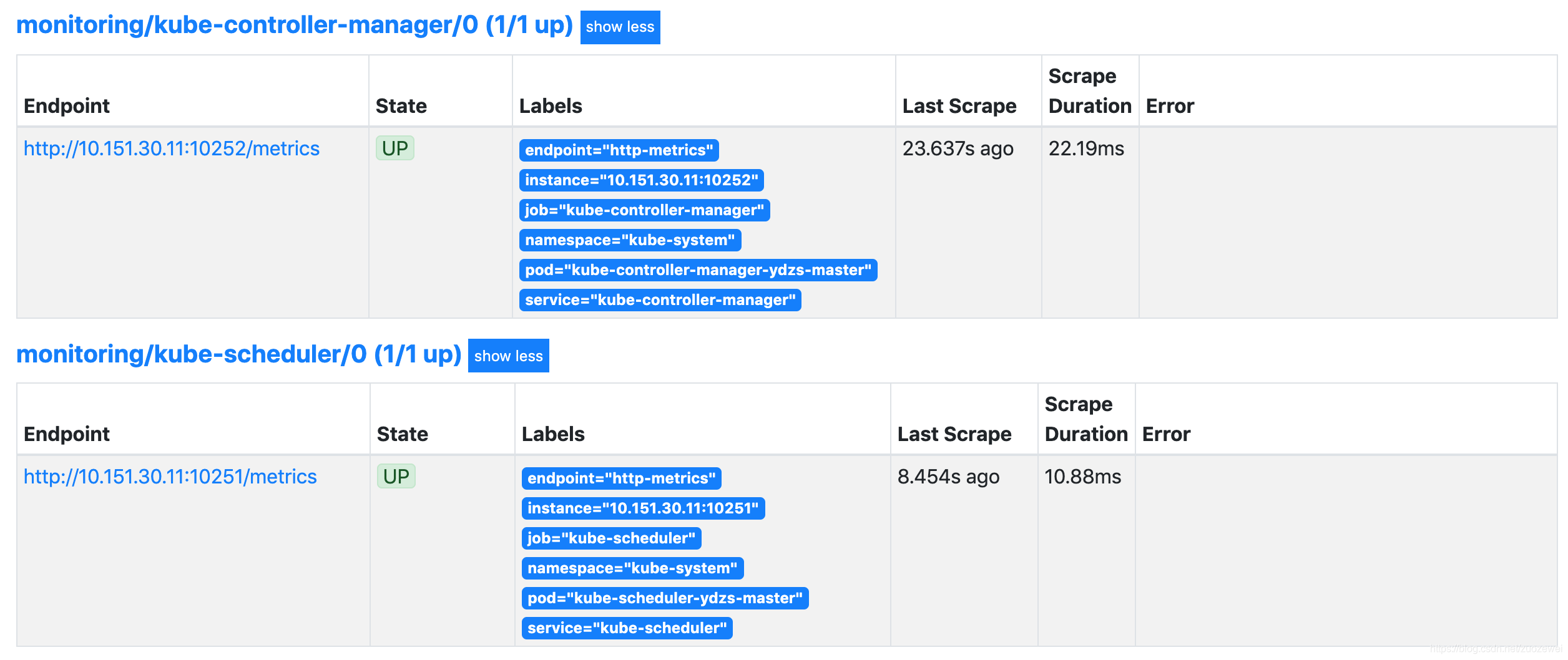
创建完成后,隔一小会儿后去 Prometheus 页面上查看 targets 下面 kube-scheduler 已经可以采集到指标数据了。
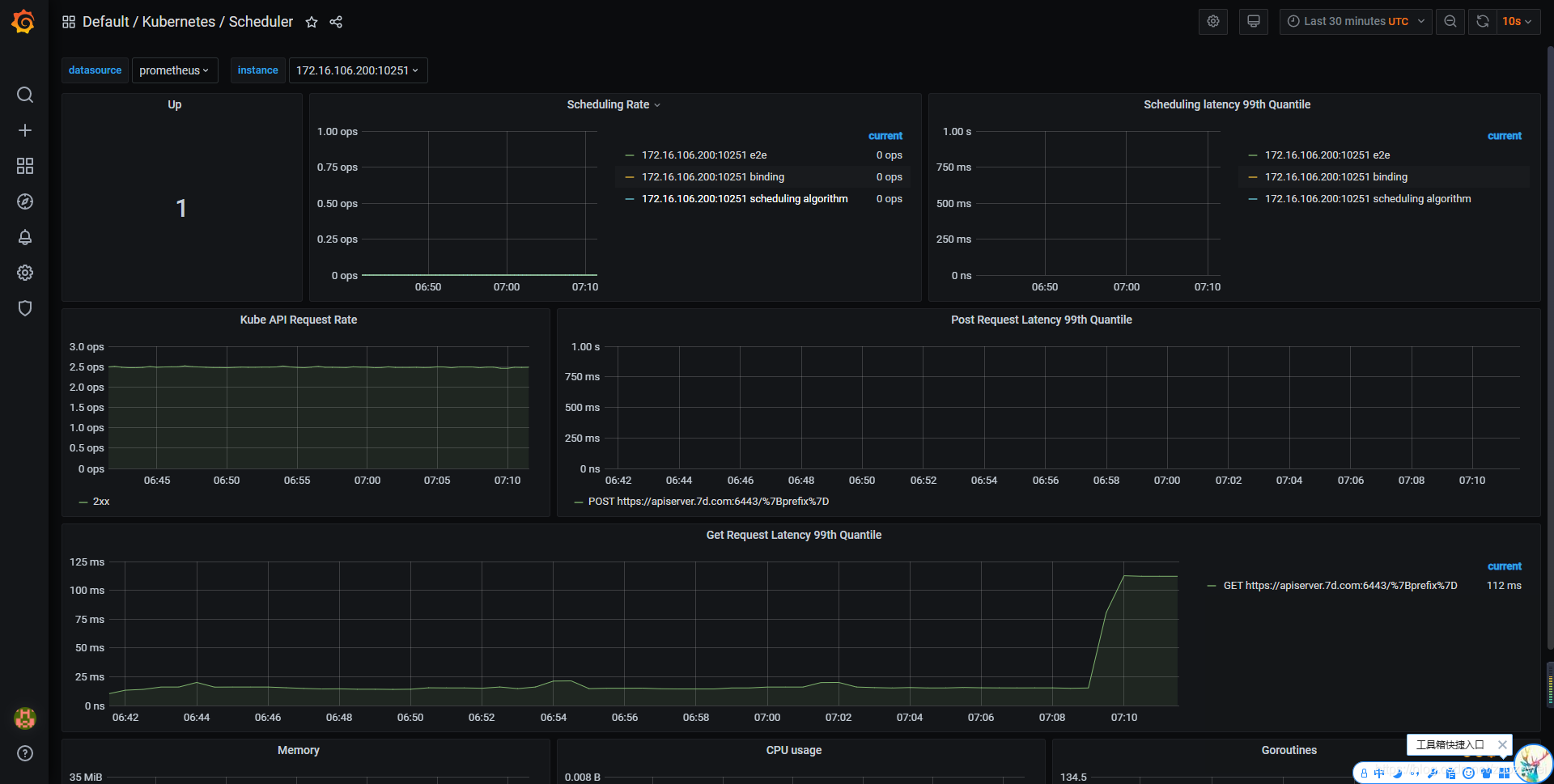
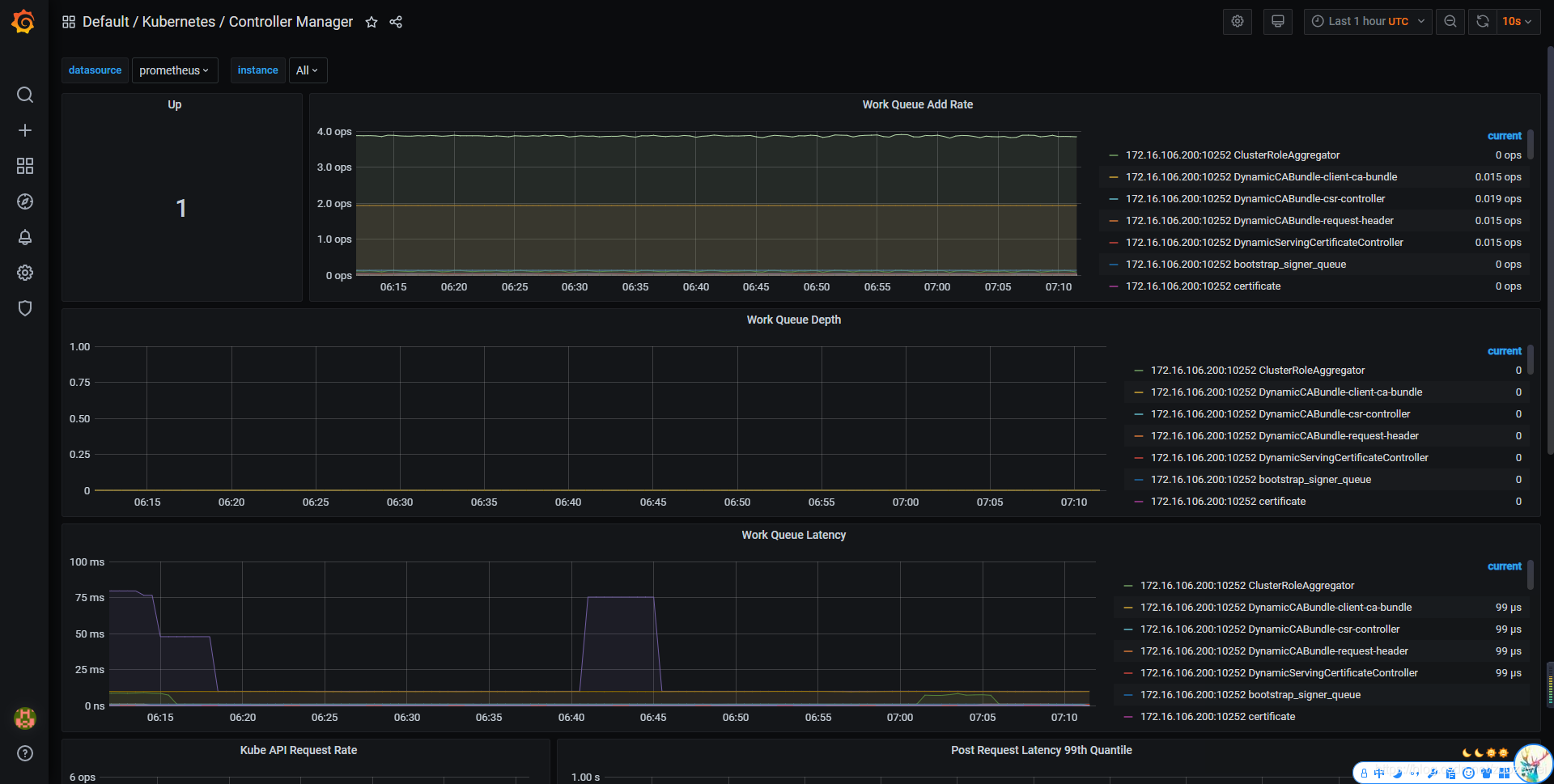
查看 Grafana 监控图表
上面的监控数据配置完成后,我们就可以去查看下 Grafana 下面的监控图表了,同样使用上篇配置的 NodePort 访问即可。
小结
核查 Kubernetes 集群中的一些资源对象、节点以及组件监控,主要由以下三个步骤组成:
- 第一步核查 ServiceMonitor 对象,其用于 Prometheus 添加监控项;
- 第二步核查 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象;
- 第三步确保 Service 对象可以正确获取到 metrics 数据。
温馨提示
在 1.19.2 版本出现这种情况:
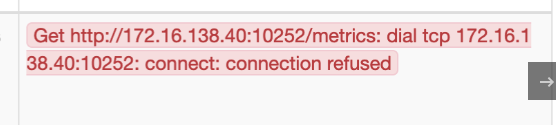
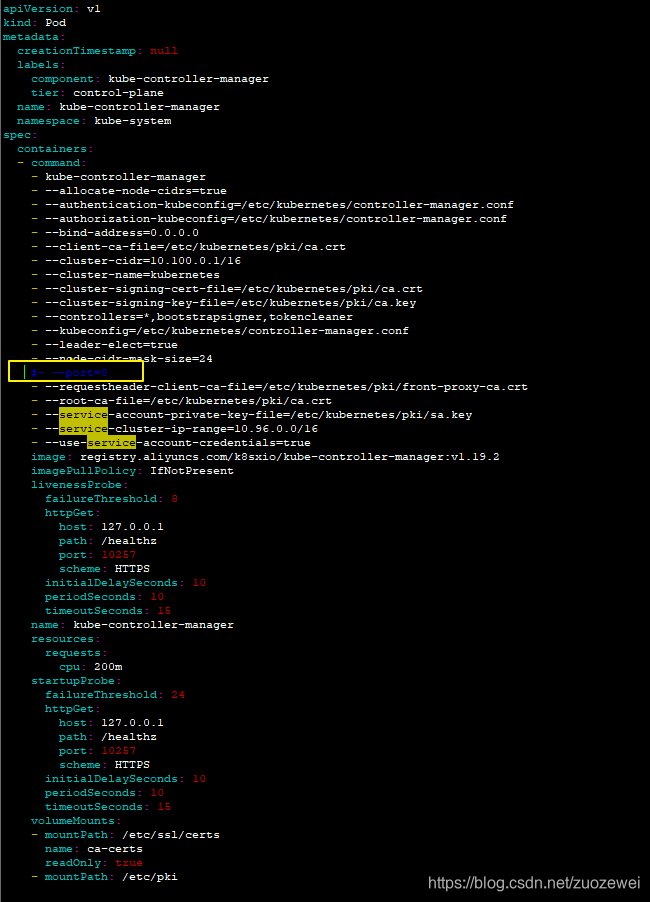
经过分析发现是 /etc/kubernetes/manifests 下的 kube-controller-manager.yaml 和 kube-scheduler.yaml 设置的默认端口是0,在文件中注释掉就可以了,如下图:
本文源码:

- 点赞
- 收藏
- 关注作者
评论(0)