Kubernetes 集群日志监控 EFK 部署

前言
Kubernetes 集群中会编排非常多的服务,各个服务不可能保证服务一定能稳定的运行,于是每个服务都会打印出各自的日志信息方便调试。由于服务的众多,每个服务挨个查看日志显然是一件非常复杂的事情,故而日志的统一收集、整理显得尤为重要。
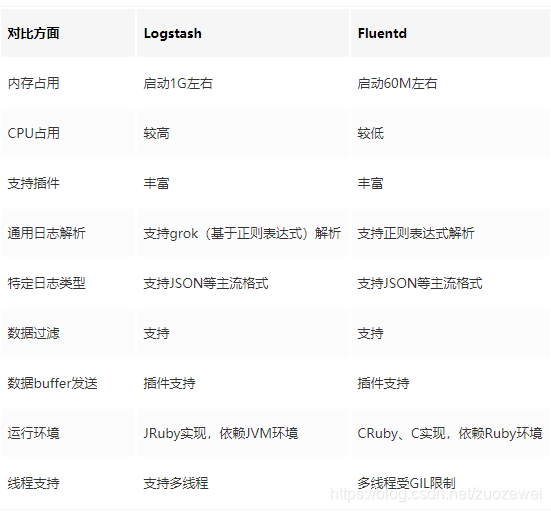
ELK 日志收集系统大家都知道,但是还有一种流行方案 EFK,肯定有很多朋友不知道!这里的 F 指的是 Fluentd,它具有 Logstash 类似的日志收集功能,但是内存占用连 Logstash 的十分之一都不到,性能优越、非常轻巧。本文将详细介绍 Fluentd 的使用。
关于 ElasticSearch & Kibana 安装请参考:
Kubernetes 集群 Helm3 安装 ElasticSearch & Kibana 7.x 版本
简介
Fluentd 是一款用于统一日志层的开源数据采集器。使用起来简单而灵活,且能统一记录层,看下下面这张图就清楚了!
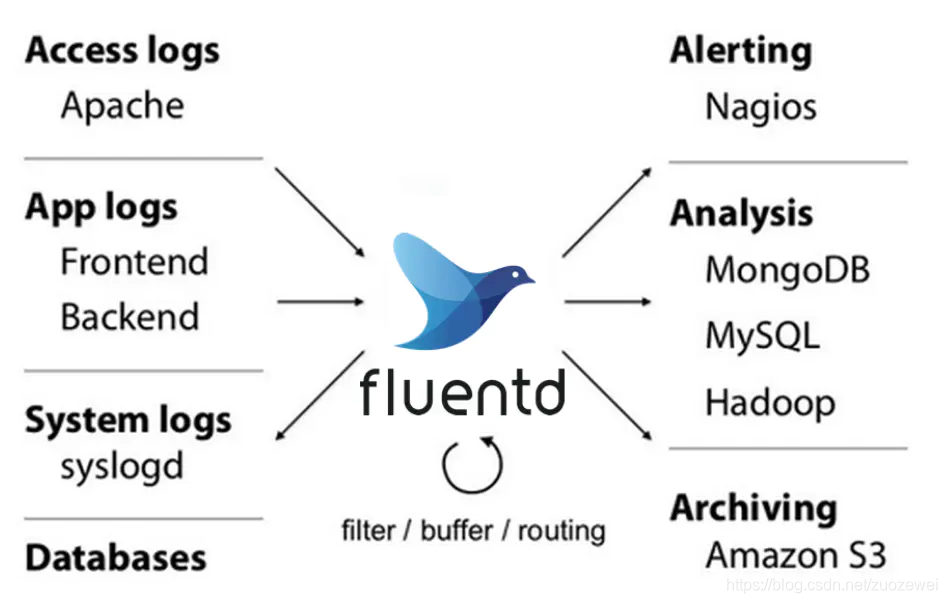
基于云原生十二原则规范,一般要求所有日志信息最好都打印输出到控制台,且打印出的日志都会以 *-json 的命名方式保存在 /var/lib/docker/containers/ 目录下,所以只要指定 Fluentd 收集地址为该目录即可方便进行日志收集工作。
接下来我们来对两个日志收集工具的各个方面做个对比:
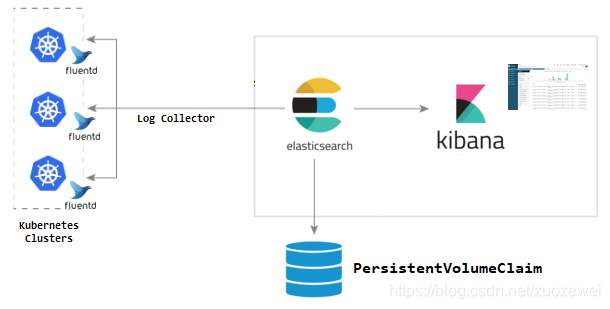
日志采集过程
采集过程简单说就是利用 Fluentd 采集 Kubernetes 节点服务器的 “/var/log” 和 “/var/lib/docker/container” 两个目录下的日志信息,然后汇总到 ElasticSearch 集群中,再经过 Kibana 展示的一个过程。
具体日志收集过程如下所述:
- 创建 Fluentd 并且将 Kubernetes 节点服务器 log 目录挂载进容器;
- Fluentd 启动采集 log 目录下的 containers 里面的日志文件;
- Fluentd 将收集的日志转换成 JSON 格式;
- Fluentd 利用 Exception Plugin 检测日志是否为容器抛出的异常日志,是就将异常栈的多行日志合并;
- Fluentd 将换行多行日志 JSON 合并;
- Fluentd 使用 Kubernetes Metadata Plugin 检测出 Kubernetes 的 Metadata 数据进行过滤,如 Namespace、Pod Name 等;
- Fluentd 使用 ElasticSearch 插件将整理完的 JSON 日志输出到 ElasticSearch 中;
- ElasticSearch 建立对应索引,持久化日志信息。
- Kibana 检索 ElasticSearch 中 Kubernetes 日志相关信息进行展示。
准备 Fluentd 配置文件
详情请访问 Kubernetes Fluentd Github地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch
下载配置文件
下载 Kubernetes ConfigMap 的配置 yaml 文件,里面包含了 Fluentd 采集 Kubernetes 集群日志的相关配置,需要提前将其下载修改一些配置让其更适合我们 Kubernetes 集群日志采集。
wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/fluentd-elasticsearch/fluentd-es-configmap.yaml
配置文件分析
接下来我们来介绍下 Fluentd 配置文件如何配置,先放出完全配置,然后我们对里面的一些配置要点进行详细说明。
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-es-config-v0.2.0
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
###### 系统配置,默认即可 #######
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
###### 容器日志—收集配置 #######
containers.input.conf: |-
# ------采集 Kubernetes 容器日志-------
<source>
@id fluentd-containers.log
@type tail #---Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
path /var/log/containers/*.log #---挂载的服务器Docker容器日志地址
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.* #---设置日志标签
read_from_head true
<parse> #---多行格式化成JSON
@type multi_format #---使用multi-format-parser解析器插件
<pattern>
format json #---JSON解析器
time_key time #---指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ #---时间格式
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
# -----检测Exception异常日志连接到一条日志中------
# 关于插件请查看地址:https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions
<match raw.kubernetes.**> #---匹配tag为raw.kubernetes.**日志信息
@id raw.kubernetes
@type detect_exceptions #---使用detect-exceptions插件处理异常栈信息,放置异常只要一行而不完整
remove_tag_prefix raw #---移出raw前缀
message log #---JSON记录中包含应扫描异常的单行日志消息的字段的名称。
# 如果将其设置为'',则插件将按此顺序尝试'message'和'log'。
# 此参数仅适用于结构化(JSON)日志流。默认值:''。
stream stream #---JSON记录中包含“真实”日志流中逻辑日志流名称的字段的名称。
# 针对每个逻辑日志流单独处理异常检测,即,即使逻辑日志流 的
# 消息在“真实”日志流中交织,也将检测到异常。因此,仅组合相
# 同逻辑流中的记录。如果设置为'',则忽略此参数。此参数仅适用于
# 结构化(JSON)日志流。默认值:''。
multiline_flush_interval 5 #---以秒为单位的间隔,在此之后将转发(可能尚未完成)缓冲的异常堆栈。
# 如果未设置,则不刷新不完整的异常堆栈。
max_bytes 500000
max_lines 1000
</match>
# -------日志拼接-------
<filter **>
@id filter_concat
@type concat #---Fluentd Filter插件,用于连接多个事件中分隔的多行日志。
key message
multiline_end_regexp /\n$/ #---以换行符“\n”拼接
separator ""
</filter>
# ------过滤Kubernetes metadata数据使用pod和namespace metadata丰富容器日志记录-------
# 关于插件请查看地址:https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter
<filter kubernetes.**>
@id filter_kubernetes_metadata
@type kubernetes_metadata
</filter>
# ------修复ElasticSearch中的JSON字段------
# 关于插件请查看地址:https://github.com/repeatedly/fluent-plugin-multi-format-parser
<filter kubernetes.**>
@id filter_parser
@type parser #---multi-format-parser多格式解析器插件
key_name log #---在要解析的记录中指定字段名称。
reserve_data true #---在解析结果中保留原始键值对。
remove_key_name_field true #---key_name解析成功后删除字段。
<parse>
@type multi_format
<pattern>
format json
</pattern>
<pattern>
format none
</pattern>
</parse>
</filter>
###### Kuberntes集群节点机器上的日志收集 ######
system.input.conf: |-
# ------Kubernetes minion节点日志信息,可以去掉------
#<source>
# @id minion
# @type tail
# format /^(?<time>[^ ]* [^ ,]*)[^\[]*\[[^\]]*\]\[(?<severity>[^ \]]*) *\] (?<message>.*)$/
# time_format %Y-%m-%d %H:%M:%S
# path /var/log/salt/minion
# pos_file /var/log/salt.pos
# tag salt
#</source>
# ------启动脚本日志,可以去掉------
# <source>
# @id startupscript.log
# @type tail
# format syslog
# path /var/log/startupscript.log
# pos_file /var/log/es-startupscript.log.pos
# tag startupscript
# </source>
# ------Docker 程序日志,可以去掉------
# <source>
# @id docker.log
# @type tail
# format /^time="(?<time>[^)]*)" level=(?<severity>[^ ]*) msg="(?<message>[^"]*)"( err="(?<error>[^"]*)")?( statusCode=($<status_code>\d+))?/
# path /var/log/docker.log
# pos_file /var/log/es-docker.log.pos
# tag docker
# </source>
#------ETCD 日志,因为ETCD现在默认启动到容器中,采集容器日志顺便就采集了,可以去掉------
# <source>
# @id etcd.log
# @type tail
# # Not parsing this, because it doesn't have anything particularly useful to
# # parse out of it (like severities).
# format none
# path /var/log/etcd.log
# pos_file /var/log/es-etcd.log.pos
# tag etcd
# </source>
#------Kubelet 日志------
# <source>
# @id kubelet.log
# @type tail
# format multiline
# multiline_flush_interval 5s
# format_firstline /^\w\d{4}/
# format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
# time_format %m%d %H:%M:%S.%N
# path /var/log/kubelet.log
# pos_file /var/log/es-kubelet.log.pos
# tag kubelet
# </source>
#------Kube-proxy 日志------
# <source>
# @id kube-proxy.log
# @type tail
# format multiline
# multiline_flush_interval 5s
# format_firstline /^\w\d{4}/
# format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
# time_format %m%d %H:%M:%S.%N
# path /var/log/kube-proxy.log
# pos_file /var/log/es-kube-proxy.log.pos
# tag kube-proxy
# </source>
#------kube-apiserver日志------
# <source>
# @id kube-apiserver.log
# @type tail
# format multiline
# multiline_flush_interval 5s
# format_firstline /^\w\d{4}/
# format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
# time_format %m%d %H:%M:%S.%N
# path /var/log/kube-apiserver.log
# pos_file /var/log/es-kube-apiserver.log.pos
# tag kube-apiserver
# </source>
#------Kube-controller日志------
# <source>
# @id kube-controller-manager.log
# @type tail
# format multiline
# multiline_flush_interval 5s
# format_firstline /^\w\d{4}/
# format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
# time_format %m%d %H:%M:%S.%N
# path /var/log/kube-controller-manager.log
# pos_file /var/log/es-kube-controller-manager.log.pos
# tag kube-controller-manager
# </source>
#------Kube-scheduler日志------
# <source>
# @id kube-scheduler.log
# @type tail
# format multiline
# multiline_flush_interval 5s
# format_firstline /^\w\d{4}/
# format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
# time_format %m%d %H:%M:%S.%N
# path /var/log/kube-scheduler.log
# pos_file /var/log/es-kube-scheduler.log.pos
# tag kube-scheduler
# </source>
#------glbc日志------
# <source>
# @id glbc.log
# @type tail
# format multiline
# multiline_flush_interval 5s
# format_firstline /^\w\d{4}/
# format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
# time_format %m%d %H:%M:%S.%N
# path /var/log/glbc.log
# pos_file /var/log/es-glbc.log.pos
# tag glbc
# </source>
#------Kubernetes 伸缩日志------
# <source>
# @id cluster-autoscaler.log
# @type tail
# format multiline
# multiline_flush_interval 5s
# format_firstline /^\w\d{4}/
# format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
# time_format %m%d %H:%M:%S.%N
# path /var/log/cluster-autoscaler.log
# pos_file /var/log/es-cluster-autoscaler.log.pos
# tag cluster-autoscaler
# </source>
# -------来自system-journal的日志------
<source>
@id journald-docker
@type systemd
matches [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
path /var/log/journald-docker.pos
</storage>
read_from_head true
tag docker
</source>
# -------Journald-container-runtime日志信息------
<source>
@id journald-container-runtime
@type systemd
matches [{ "_SYSTEMD_UNIT": "{{ fluentd_container_runtime_service }}.service" }]
<storage>
@type local
persistent true
path /var/log/journald-container-runtime.pos
</storage>
read_from_head true
tag container-runtime
</source>
# -------Journald-kubelet日志信息------
<source>
@id journald-kubelet
@type systemd
matches [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
path /var/log/journald-kubelet.pos
</storage>
read_from_head true
tag kubelet
</source>
# -------journald节点问题检测器------
#关于插件请查看地址:https://github.com/reevoo/fluent-plugin-systemd
#systemd输入插件,用于从systemd日志中读取日志
<source>
@id journald-node-problem-detector
@type systemd
matches [{ "_SYSTEMD_UNIT": "node-problem-detector.service" }]
<storage>
@type local
persistent true
path /var/log/journald-node-problem-detector.pos
</storage>
read_from_head true
tag node-problem-detector
</source>
# -------kernel日志------
<source>
@id kernel
@type systemd
matches [{ "_TRANSPORT": "kernel" }]
<storage>
@type local
persistent true
path /var/log/kernel.pos
</storage>
<entry>
fields_strip_underscores true
fields_lowercase true
</entry>
read_from_head true
tag kernel
</source>
###### 监听配置,一般用于日志聚合用 ######
forward.input.conf: |-
#监听通过TCP发送的消息
<source>
@id forward
@type forward
</source>
###### Prometheus metrics 数据收集 ######
monitoring.conf: |-
# input plugin that exports metrics
# 输出 metrics 数据的 input 插件
<source>
@id prometheus
@type prometheus
</source>
<source>
@id monitor_agent
@type monitor_agent
</source>
# 从 MonitorAgent 收集 metrics 数据的 input 插件
<source>
@id prometheus_monitor
@type prometheus_monitor
<labels>
host ${hostname}
</labels>
</source>
# ------为 output 插件收集指标的 input 插件------
<source>
@id prometheus_output_monitor
@type prometheus_output_monitor
<labels>
host ${hostname}
</labels>
</source>
# ------为in_tail 插件收集指标的input 插件------
<source>
@id prometheus_tail_monitor
@type prometheus_tail_monitor
<labels>
host ${hostname}
</labels>
</source>
###### 输出配置,在此配置输出到ES的配置信息 ######
# ElasticSearch fluentd插件地址:https://docs.fluentd.org/v1.0/articles/out_elasticsearch
output.conf: |-
<match **>
@id elasticsearch
@type elasticsearch
@log_level info #---指定日志记录级别。可设置为fatal,error,warn,info,debug,和trace,默认日志级别为info。
type_name _doc
include_tag_key true #---将 tag 标签的 key 到日志中。
host elasticsearch-logging #---指定 ElasticSearch 服务器地址。
port 9200 #---指定 ElasticSearch 端口号。
#index_name fluentd.${tag}.%Y%m%d #---要将事件写入的索引名称(默认值:) fluentd。
logstash_format true #---使用传统的索引名称格式logstash-%Y.%m.%d,此选项取代该index_name选项。
#logstash_prefix logstash #---用于logstash_format指定为true时写入logstash前缀索引名称,默认值:logstash。
<buffer>
@type file #---Buffer 插件类型,可选file、memory
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff #---重试模式,可选为exponential_backoff、periodic。
# exponential_backoff 模式为等待秒数,将在每次失败时成倍增长
flush_thread_count 2
flush_interval 10s
retry_forever
retry_max_interval 30 #---丢弃缓冲数据之前的尝试的最大间隔。
chunk_limit_size 5M #---每个块的最大大小:事件将被写入块,直到块的大小变为此大小。
queue_limit_length 8 #---块队列的长度。
overflow_action block #---输出插件在缓冲区队列已满时的行为方式,有throw_exception、block、
# drop_oldest_chunk,block方式为阻止输入事件发送到缓冲区。
</buffer>
</match>
配置要点解析:
<source>:定义了日志收集的来源,可以有tcp、udp、tail(文件)、forward(tcp+udp)、http等方式。<parse>:定义对原始数据的解析方式,可以将日志转化为JSON。<filter>:可以对收集的日志进行一系列的处理,比如说将日志打印到控制台或者对日志进行解析。<match>:定义了收集到的日志最后输出到哪里,可以输出到stdout(控制台)、file、elasticsearch、mongo等里面。
定制配置并调整参数
创建 Fluentd ConfigMap
创建 fluentd-es-config.yaml 文件:
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-es-config
namespace: efk
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
#------系统配置参数-----
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
#------Kubernetes 容器日志收集配置------
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.*
read_from_head true
<parse>
@type multi_format
<pattern>
format json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
<filter **>
@id filter_concat
@type concat
key message
multiline_end_regexp /\n$/
separator ""
</filter>
<filter kubernetes.**>
@id filter_kubernetes_metadata
@type kubernetes_metadata
</filter>
<filter kubernetes.**>
@id filter_parser
@type parser
key_name log
reserve_data true
remove_key_name_field true
<parse>
@type multi_format
<pattern>
format json
</pattern>
<pattern>
format none
</pattern>
</parse>
</filter>
#------系统日志收集-------
system.input.conf: |-
<source>
@id journald-docker
@type systemd
matches [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
path /var/log/journald-docker.pos
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-container-runtime
@type systemd
matches [{ "_SYSTEMD_UNIT": "{{ fluentd_container_runtime_service }}.service" }]
<storage>
@type local
persistent true
path /var/log/journald-container-runtime.pos
</storage>
read_from_head true
tag container-runtime
</source>
<source>
@id journald-kubelet
@type systemd
matches [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
path /var/log/journald-kubelet.pos
</storage>
read_from_head true
tag kubelet
</source>
<source>
@id journald-node-problem-detector
@type systemd
matches [{ "_SYSTEMD_UNIT": "node-problem-detector.service" }]
<storage>
@type local
persistent true
path /var/log/journald-node-problem-detector.pos
</storage>
read_from_head true
tag node-problem-detector
</source>
<source>
@id kernel
@type systemd
matches [{ "_TRANSPORT": "kernel" }]
<storage>
@type local
persistent true
path /var/log/kernel.pos
</storage>
<entry>
fields_strip_underscores true
fields_lowercase true
</entry>
read_from_head true
tag kernel
</source>
#------输出到 ElasticSearch 配置------
output.conf: |-
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
type_name _doc
include_tag_key trues
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
logstash_format true
logstash_prefix kubernetes
logst
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 5
flush_interval 8s
retry_forever
retry_max_interval 30
chunk_limit_size 5M
queue_limit_length 10
overflow_action block
compress gzip #开启gzip提高日志采集性能
</buffer>
</match>
创建 Flunetd ServiceAccount
创建 fluentd-rbac.yaml 文件:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: efk
labels:
k8s-app: fluentd-es
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: efk
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
创建 Fluentd PriorityClass
创建 fluentd-priorityclass.yaml 文件:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: fluentd-priority
value: 1000000
globalDefault: false
description: ""
创建 Fluentd DaemonSet
创建 fluentd.yaml 文件:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es
namespace: efk
labels:
k8s-app: fluentd-es
version: v3.0.2
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v3.0.2
template:
metadata:
labels:
k8s-app: fluentd-es
version: v3.0.2
#此注释确保如果节点被驱逐,fluentd不会被驱逐
#支持关键的基于pod注释的优先级方案。
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
spec:
priorityClassName: fluentd-priority #给 Fluentd 设置优先级资源
serviceAccountName: fluentd-es #给 Fluentd 分配权限账户
#设置容忍所有污点,这样可以收集所有节点日志如 Master 节点一般都被设污,不设置无法在其节点启动 fluentd。
tolerations:
- operator: "Exists"
containers:
- name: fluentd-es
image: quay.io/fluentd_elasticsearch/fluentd:v3.0.2
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q #不启用管理,-q 命令用平静时期于减少warn级别日志(-qq:减少error日志)
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch-client"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: 'FLUENT_ELASTICSEARCH_USER' #环境变量配置,这里引入上面设置的用户名、密码 secret 文件
valueFrom:
secretKeyRef:
name: elastic-credentials
key: username
- name: 'FLUENT_ELASTICSEARCH_PASSWORD'
valueFrom:
secretKeyRef:
name: elastic-credentials
key: password
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
terminationGracePeriodSeconds: 30 #Kubernetes 将会给应用发送SIGTERM信号,用来优雅地关闭应用
volumes:
- name: varlog #将 Kubernetes 节点服务器日志目录挂入
hostPath:
path: /var/log
- name: varlibdockercontainers #挂入 Docker 容器日志目录
hostPath:
path: /var/lib/docker/containers
- name: config-volume #挂入 Fluentd 的配置参数
configMap:
name: fluentd-es-config
安装 Fluentd
kubectl create namespace efk
# 创建 Fluentd ConfigMap
kubectl apply -f fluentd-es-config.yaml -n efk
# 创建 Fluentd ServiceAccount
kubectl apply -f fluentd-rbac.yaml -n efk
# 创建 Fluentd PriorityClass
kubectl apply -f fluentd-priorityclass.yaml -n efk
# 创建 Fluentd DaemonSet
kubectl apply -f fluentd.yaml -n efk
查看 Fluentd 相关资源
$ kubectl get pod,daemonset -n efk | grep fluent
pod/fluentd-es-8ggfj 1/1 Running 0 161m
pod/fluentd-es-gp2gb 1/1 Running 0 161m
pod/fluentd-es-jdwln 1/1 Running 0 161m
pod/fluentd-es-jnjxs 1/1 Running 0 161m
pod/fluentd-es-lkh6z 1/1 Running 0 161m
pod/fluentd-es-mds57 1/1 Running 0 161m
pod/fluentd-es-mkphs 1/1 Running 0 161m
daemonset.apps/fluentd-es 7 7 7 7 7 <none> 161m
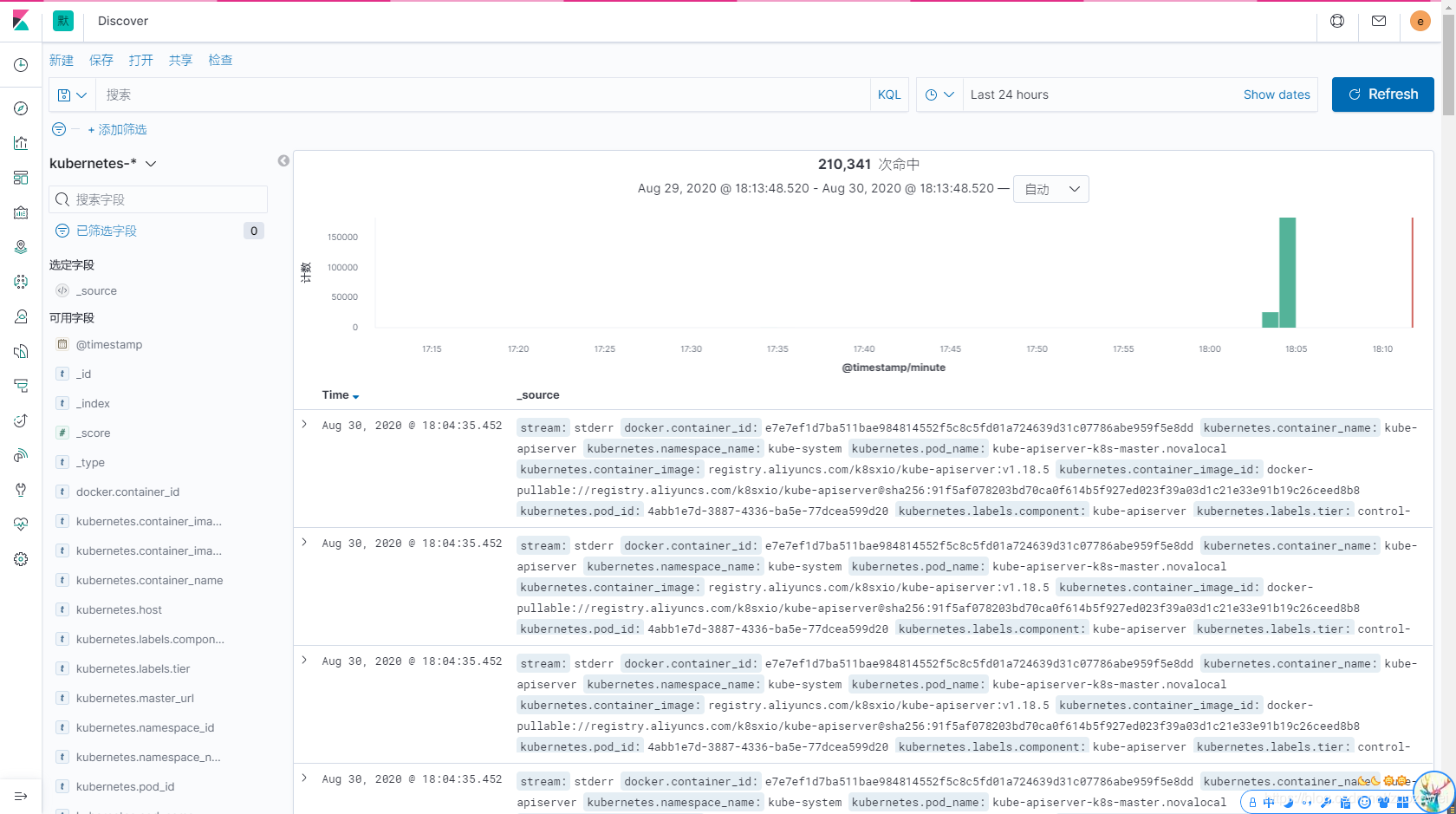
Kibana 查看采集的日志信息
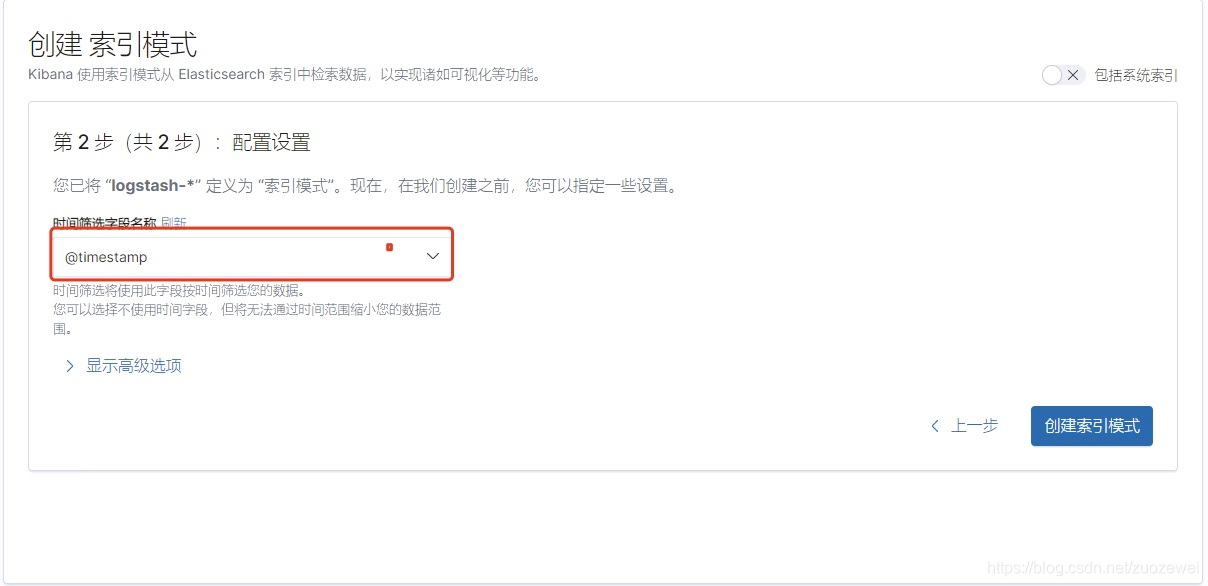
Kibana 设置索引
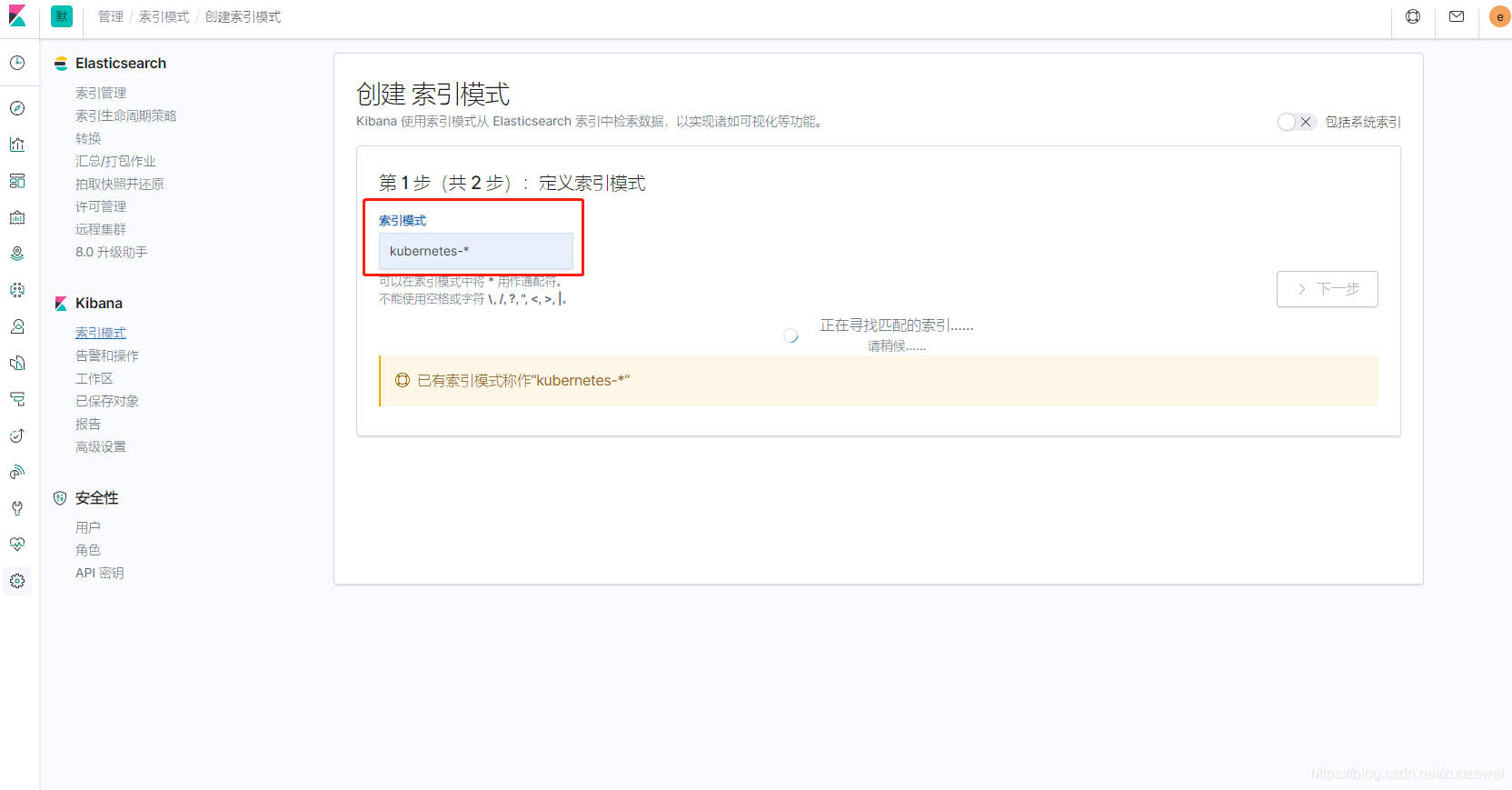
由于在 Fluentd 输出配置中配置了 “logstash_prefix kubernetes” 这个参数,所以索引是以 kubernetes 为前缀显示,如果未设置则默认为 “logstash” 为前缀。
Kibana 查看 Kubernetes 日志信息
遇到的问题
Falied to flush the buffer, and the file buffer directory is filled with bad logs
错误日志
/usr/local/bundle/gems/kubeclient-4.6.0/lib/kubeclient.rb:27: warning: Using the last argument as keyword parameters is deprecated; maybe ** should be added to the call
/usr/local/bundle/gems/kubeclient-4.6.0/lib/kubeclient/common.rb:61: warning: The called method `initialize_client' is defined here
2020-09-01 02:21:13 +0000 [error]: config error in:
<match **>
@id elasticsearch
@type elasticsearch
@log_level "info"
type_name "_doc"
include_tag_key trues
host "elasticsearch-client"
port 9200
user "elastic"
password xxxxxx
logstash_format true
logstash_prefix "kubernetes"
logst
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 5
flush_interval 8s
retry_forever
retry_max_interval 30
chunk_limit_size 5M
queue_limit_length 10
overflow_action block
compress gzip
</buffer>
</match>
2020-09-01 02:21:13 +0000 [error]: config error file="/etc/fluent/fluent.conf" error_class=Fluent::ConfigError error="'include_tag_key' parameter is required but nil is specified"
解决办法
参考链接:https://github.com/fluent/fluentd/issues/2534
在缓冲区配置中添加了<secondary>:
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
type_name _doc
include_tag_key trues
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
logstash_format true
logstash_prefix kubernetes
logst
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 5
flush_interval 8s
retry_forever
retry_max_interval 30
chunk_limit_size 5M
queue_limit_length 10
overflow_action block
compress gzip #开启gzip提高日志采集性能
</buffer>
# Secondary
<secondary>
@type secondary_file
directory /tmp/fluentd
basename bad-chunk-${chunk_id}
</secondary>
</match>
相关资料:
参考资料:

- 点赞
- 收藏
- 关注作者
评论(0)