大数据技术为什么快?

在之前的博客《什么是大数据?看这一篇就足够了!》中,小菌为大家较为详细的介绍了一些关于大数据的知识。其中提到了大数据的四个特点,即海量化,多样化,快速化和高价值。本篇博客,小菌决定就以快速化这个特点展开,为大家科普下大数据技术为什么快?
先让我们来看下传统数据与大数据处理方式的对比:
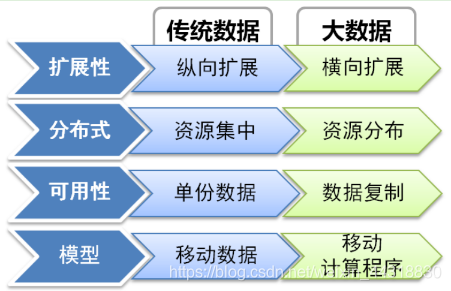
接下来小菌将根据这个四个角度来为各位小伙伴们好好分析。
拓展性
纵向扩展
表示在需要处理更多负载时通过提高单个系统处理能力的方法来解决问题。最简单的情况就是为应用系统提供更为强大的硬件。
例如如果数据库所在的服务器实例只有8G内存、低配CPU、小容量硬盘,进而导致了数据库不能高效地运行,那么我们就可以通过将该服务器的内存扩展至16G、更换大容量硬盘或者更换高性能服务器来解决这个问题。

横向扩展
是将服务分割为众多的子服务并在负载平衡等技术的帮助下在应用中添加新的服务实例
例如如果数据库所在的服务器实例只有一台服务器,进而导致了数据库不能高效地运行,那么我们就可以通过增加服务器数量,将其构成一个集群来解决这个问题。
分布式
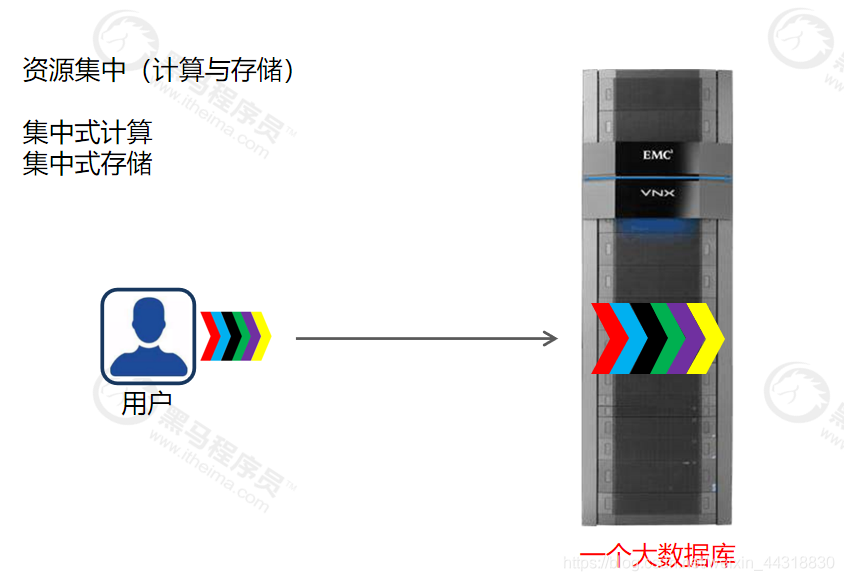
传统的方式资源(cpu/内存/硬盘)集中,大数据方式资源(cpu/内存/硬盘)分布(前提:同等配置的前提下)
资源集中(计算与存储)
集中式计算
数据计算几乎完全依赖于一台中、大型的中心计算机的处理能力。和它相连的终端(用户设备)具有各不相同的智能程度。实际上大多数终端完全不具有处理能力,仅仅作为一台输入输出设备使用。
集中式存储
指建立一个庞大的数据库,把各种信息存入其中,各种功能模块围绕信息库的周围并对信息库进行录入、修改、查询、删除等操作的组织方式。
分布式(计算与存储)
分布式计算
是一种计算方法,是将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。
分布式存储
是一种数据存储技术,通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落,多台服务器。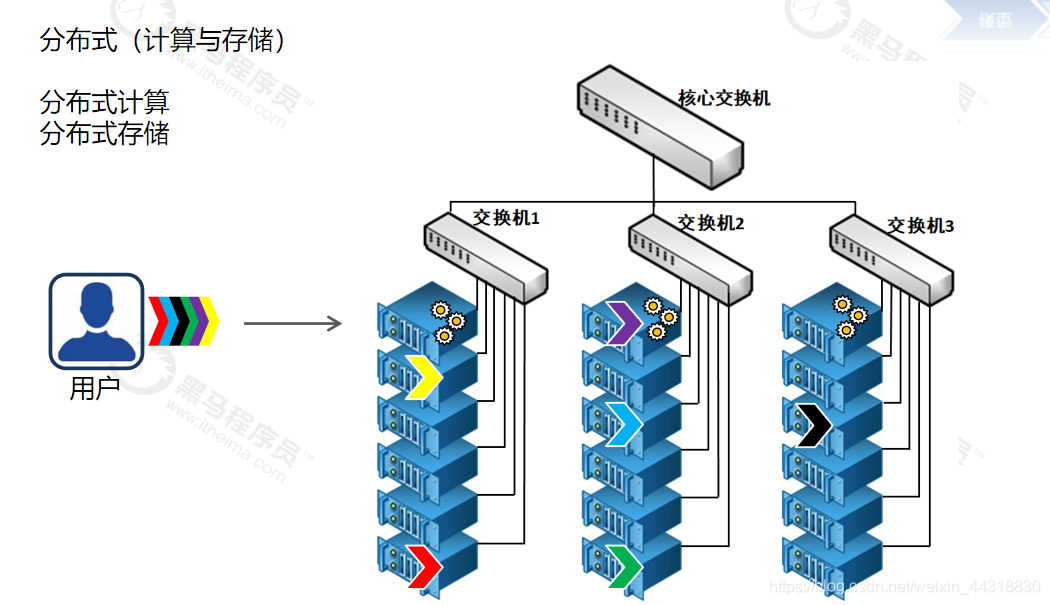
拓展性
传统数据备份方式单份备份,大数据数据备份方式多分备份(数据复制,默认三个副本)
单份数据
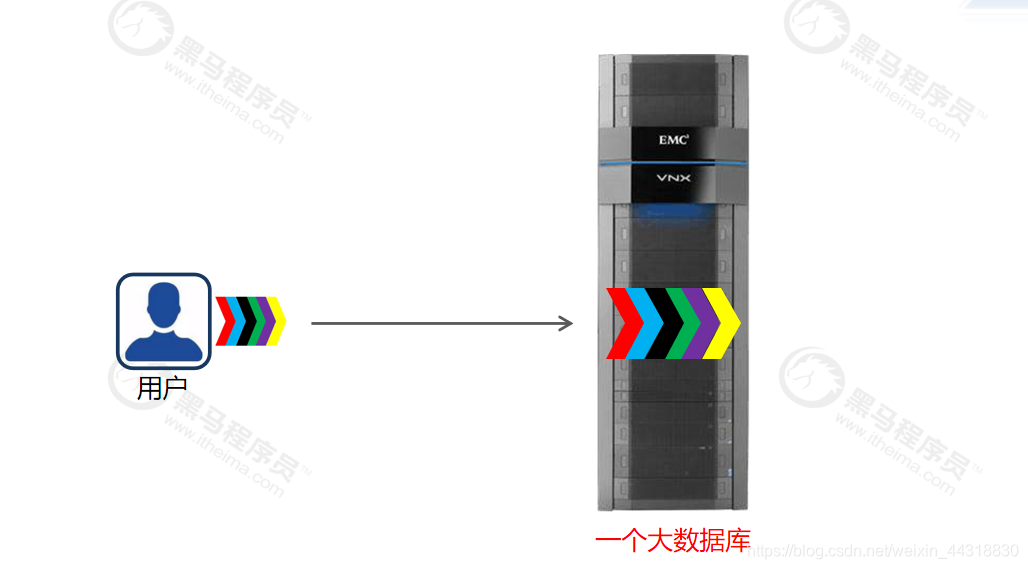
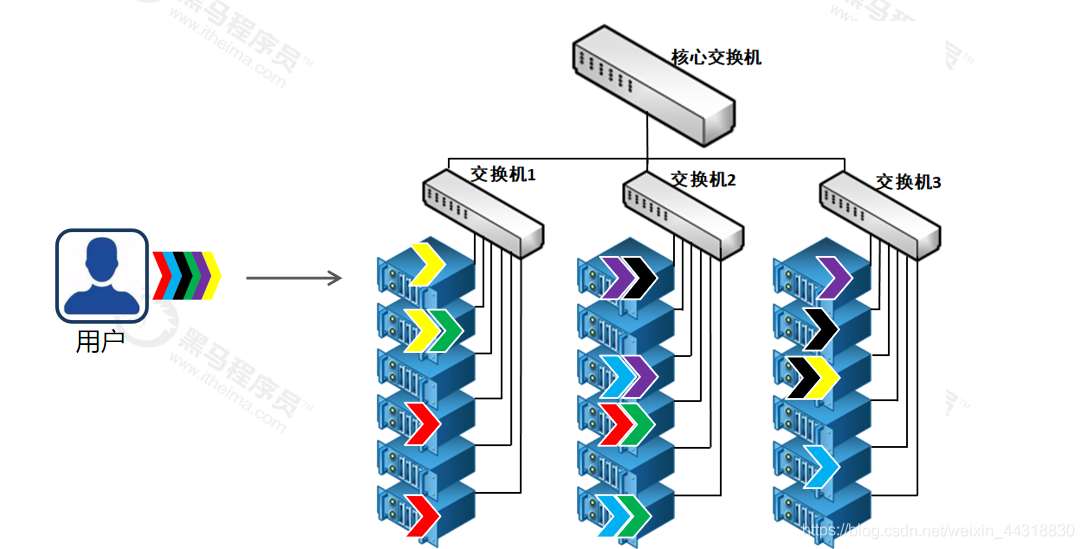
多份数据(数据复制)
模型
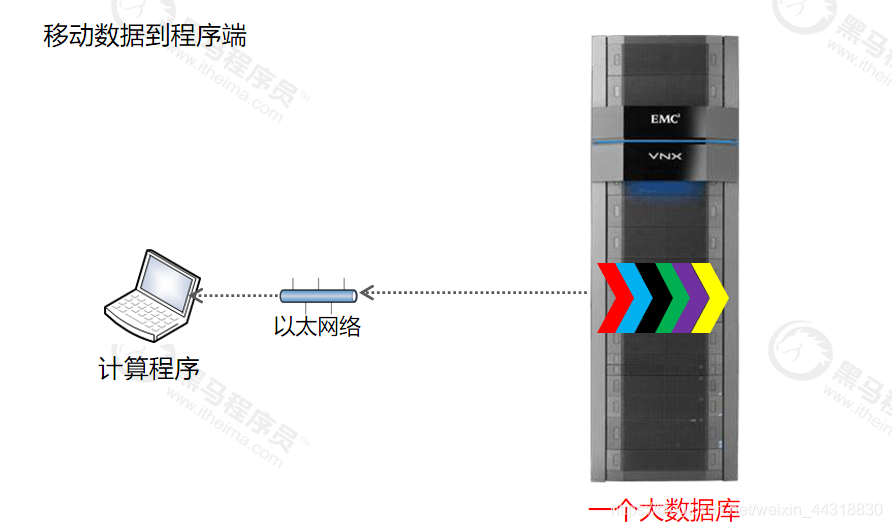
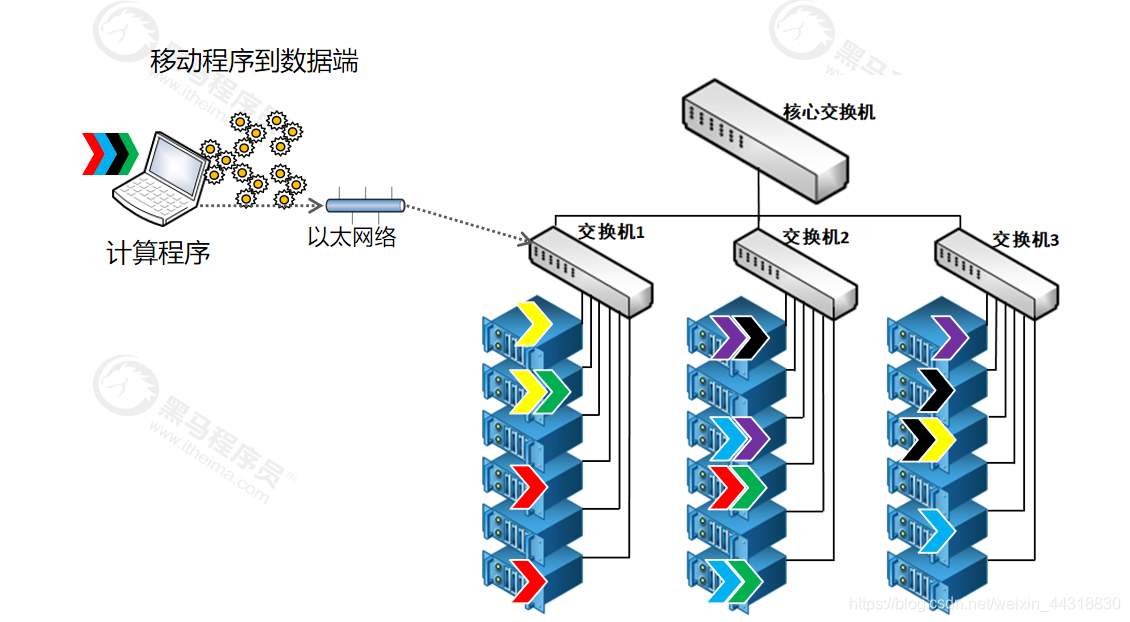
传统的计算模型是移动数据到程序端,大数据计算模型是移动程序到数据端。io 和网络的使用率都非常低,且多节点存储,多节点计算(众人拾柴火焰高)
移动数据
移动计算程序
本次的分享就到这里了,喜欢的小伙伴们不要忘了点赞加关注ヾ(๑╹◡╹)ノ"
文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/102841176

- 点赞
- 收藏
- 关注作者
评论(0)