MapReduce的逻辑切分split与合并combiner

在之前的博客《MapReduce中shuffle阶段概述及计算任务流程》,小菌为大家分享了MapReduce的整体计算任务流程以及shuffle阶段主要的作用。本篇博客小菌将针对MapReduce流程中的第2步——split逻辑切分与第7步——合并做一个知识面的拓展。
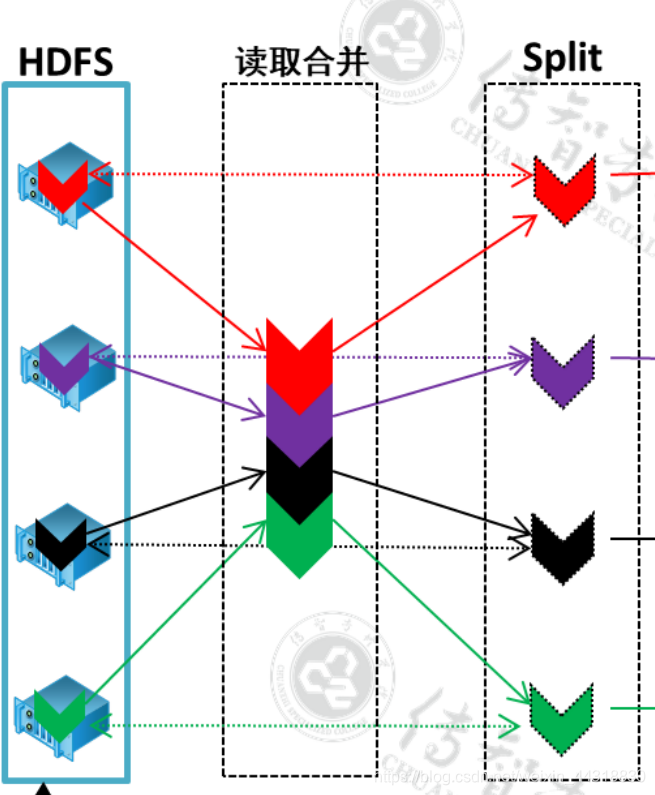
Split的逻辑切分
在MapReduce任务流程中第一步获取到数据后,split对数据进行逻辑切分,切分的大小是128M。这里的128 与 HDFS 数据块的128 没有任何关系。
HDFS 128 是存储层面的数据,split 128 是计算层面的 128, 只不过数据恰好相等。
两个128 相同的原因是,一个集成程序能够正好计算一个数据块!
MapReduce的combiner
每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对map 端的输出先做一次合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络IO 性能,是 MapReduce 的一种优化手段之一。
combiner 是 MR 程序中 Mapper 和 Reducer 之外的一种组件,组件的父类就是 Reducer。
combiner 和 reducer 的区别在于运行的位置:
Combiner 是在每一个 maptask 所在的节点运行
Reducer 是接收全局所有 Mapper 的输出结果;
combiner 的意义就是对每一个 maptask 的输出进行局部汇总,以减小网络传输量
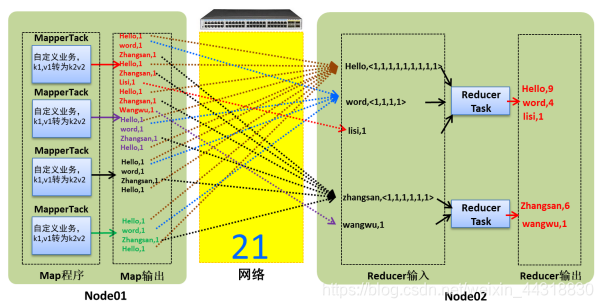
让我们通过两张图来看下未使用combiner和使用combiner的网络开销的大致情况!
未使用combiner的网络开销
使用combiner的网络开销
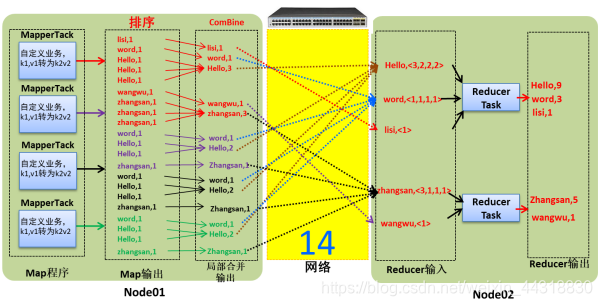
可以很明显的看出在combiner阶段,通过合并同一个区中相同key的value值,减小了后续的数据传输,从而提高了网络的io!
但在MapReduce中,combiner是默认不开启的。为什么呢?是因为数据合并并不适用所有的业务需求,如果是计算个数,求和combiner还能发挥它的优势!但如果是求平均数,combiner必不可免的会影响到最终的结果,使结果变得不可靠!所以当我们需要到combiner时,需要手动开启。
具体实现步骤:
1、自定义一个 combiner 继承 Reducer,重写 reduce 方法
2、在 job 中设置: job.setCombinerClass(CustomCombiner.class)
combiner 能够应用的前提是不能影响最终的业务逻辑。而且,combiner 的输出 kv 应该跟 reducer 的输入 kv 类型要对应起来。
本次的分享就到这里了,大家有什么疑惑或者好的建议可以在评论区积极留言。受益的小伙伴们不要忘了点赞关注小菌哟~~

文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/103078466

- 点赞
- 收藏
- 关注作者
评论(0)