HBase的读写流程

本篇博客小菌为大家带来的是关于HBase的读写路程的介绍。
读请求流程
在介绍之前先为大家科普几个前提!
- 什么是meta表?
meta 表时hbase系统自带的一个表。里面存储了hbase用户表的原信息。 - 什么是元信息?
meta表内记录一行数据是用户表一个region的start key 到endkey的范围。 - meta表存在什么地方?
meta表存储在regionserver里。 具体存储在哪个regionserver里?zookeeper知道。
好了,清楚了上面的概念之后,理解起来就会简单很多了。
meta,region之间的关系如下(在HBase0.96版本中已经取消了root表)
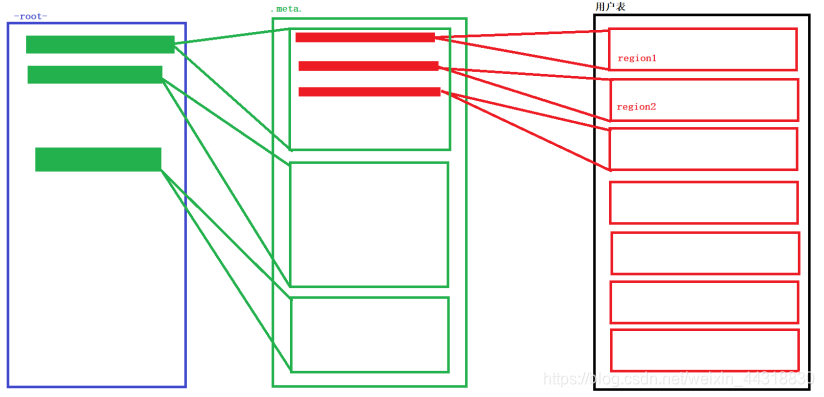
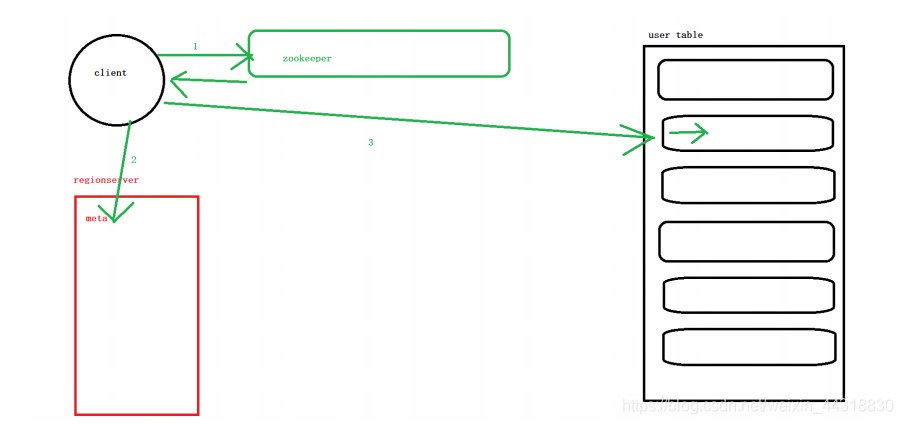
具体的流程如下:
1.到zookeeper询问meta表在哪
2.到meta所在的节点(regionserver)读取meta表的数据
3.找到region 获取region和regionserver的对应关系,直接到regionserver读取region数据
写请求过程
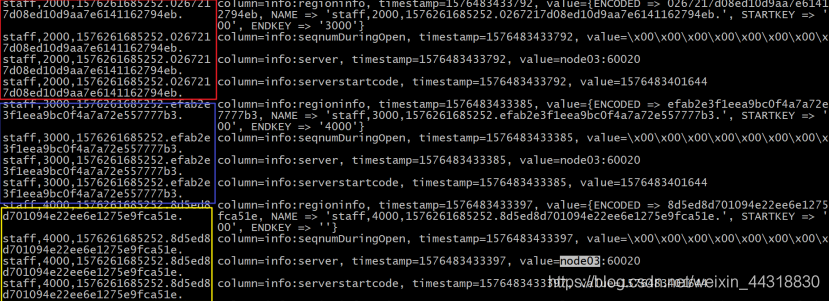
写入的流程与读的流程稍复杂一些
1、Client先访问zookeeper,找到Meta表,并获取Meta表元数据。确定当前将要写入的数据所对应的HRegion和HRegionServer服务器。
2、Client向该HRegionServer服务器发起写入数据请求。
- Client先把数据写入到HLog,以防止数据丢失。
- 然后将数据写入到Memstore。
3、Memstore达到阈值,会把Memstore中的数据flush到Storefile中 4、当Storefile越来越多,达到一定数量时,会触发Compact合并操作,将多个小文件合并成一个大文件。
5、Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,变成两个文件。
说明:hbasez 支持数据修改(伪修改),实际上是相同rowkey数据的添加。hbase只显示最后一次的添加。
好了,本次的分享就到这里了,受益的小伙伴或对大数据技术感兴趣的朋友记得关注小菌哟(^U^)ノ~YO

文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/103656305

- 点赞
- 收藏
- 关注作者
评论(0)