把本地的文件数据导入到Hive分区表--系列①Java代码

【摘要】
本篇博客,小菌为大家带来关于如何将本地的多个文件导入到Hive分区表中对应的分区上的方法。一共有四种方法,本...
本篇博客,小菌为大家带来关于如何将本地的多个文件导入到Hive分区表中对应的分区上的方法。一共有四种方法,本篇将介绍第一种—Java代码。
首先编写代码,通过MapReduce将处理好的数据写入到HDFS的目录下。下面提供一种参考!
Map
public class Mapper01 extends Mapper<LongWritable, Text,Text,Text> {
/**
*
* @param key 行首偏移量
* @param value 一整行的数据
* @param context 上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//思路:
//获取一行数据,使用\t进行分割。若分割后形成的数组大于11(角标为11的字段为日期格式数据),并且角标为14的字段不等于空。
String[] splits = value.toString().trim().split("\t");
if(splits.length> 15 && !"" .equals(splits[14])){
//截取出数据中的日期数据(含时间格式为yyyy-MM-dd HH:mm:ss)
String dataTime = splits[14];
//若数据中包含空格
if (dataTime.contains(" ")){
//截取出数据中的日期(格式为:yyyy-MM-dd)
String data = dataTime.substring(0, dataTime.indexOf(" "));
//分别获取年份,月份,日期
String[] split = data.split("-");
String year = split[0];
String month = split[1];
String day = split[2];
//只有年份大于2000年以后并且月份和日数为两位数的才为有效数据
if (Integer.parseInt(year)>=2000 && Integer.parseInt(year)<=2019 && month.length()==2 && day.length()==2){
// 进一步获取时分秒
int i = dataTime.indexOf(" ");
String time = dataTime.substring(i).trim();
//按照 : 进行切分
String[] split1 = time.split(":");
//如果切分的长度等于3才继续做判断
if (split1.length==3){
//获取到时分秒
String hour = split1[0];
String min = split1[1];
String sec = split1[2];
if (hour.length()==2&&min.length()==2&&sec.length()==2){
//符合上述的所有条件之后就可以输出了
context.write(new Text(data),value);
}
}
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
Reduce
public class Reducer01 extends Reducer<Text,Text, NullWritable,NullWritable> {
private static FileSystem hdfs;
static {
try {
hdfs = FileSystem.get(new URI("hdfs://node01:8020/"), new Configuration(),"root");
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
*
* @param key
* @param values yyyy
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 在输入key值中切分字符串
if (key.toString().contains("-")){
StringBuilder stringBuilder = new StringBuilder();
for (Text value : values) {
stringBuilder.append(value.toString()).append("\r\n");
}
//创建一个目录
FSDataOutputStream outputStream = hdfs.create(new Path("/cells_info/results/"+key+".txt"));
//写入数据
outputStream.writeBytes(stringBuilder.toString());
//关闭资源
outputStream.close();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
Runner01
public class Runner01 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//新建一个配置文件对象
Configuration conf = new Configuration();
//实例化job对象
Job job = new Job(conf);
//设置本地下载
//job.setJarByClass(Runner01.class);
//设置map输出类型
job.setMapperClass(Mapper01.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置reduce类型
job.setReducerClass(Reducer01.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(NullWritable.class);
//设置输入和输出
job.setInputFormatClass(TextInputFormat.class);
//TextInputFormat.addInputPath(job,new Path("hdfs://192.168.100.100:8020/cells_info/cell_strength_data.sql"));
TextInputFormat.addInputPath(job,new Path("hdfs://192.168.100.100:8020/cells_info/cell_strength_data.sql"));
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://192.168.100.100:8020/cells_info/all_sort"));
// 设置reduceTask的数量
// 等待执行
boolean result = job.waitForCompletion(true);
System.out.println("status:"+result);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
执行到这里我们已经成功将数据清洗后写入到HDFS的目录下了。

接下来我们需要做的,就是把HDFS上的多个文件通过Java写入到Hive的分区表。
自定义一个类书写数据导入类LoadData
LoadData
public class LoadData{
public static void main(String[] args) throws Exception {
//设置链接的服务器
ConnBean connBean=new ConnBean("node01", "root","123456" );
//链接服务器
SSHExec sshExec =SSHExec.getInstance(connBean);
sshExec.connect();
FileSystem hdfs = FileSystem.get(new URI("hdfs://node01:8020/"), new Configuration(), "root");
//获取某一目录下的所有文件
FileStatus[] status = hdfs.listStatus(new Path("/cells_info/result/"));
//遍历输出
for (FileStatus fileStatus : status) {
// 获取文件名
String string = fileStatus.getPath().getName();
String[] split1 = string.split("-");
// 获取年份
String year = split1[0];
// 获取月份
String month = split1[1];
String days = split1[2];
// 获取天数
String day = days.substring(0,days.indexOf(".txt"));
// 设置命令,执行之后相当于在Linux上执行
//
// ExecCommand add = new ExecCommand("hive -e \"LOAD DATA INPATH '"+fileStatus.getPath()+"' OVERWRITE INTO TABLE telecom.cell_strength_2 PARTITION (DS='local',year='"+year+"',month = '"+month+"' , day = '"+day+"'); \"");
ExecCommand execCommand2 = new ExecCommand("hive -e \"LOAD DATA INPATH '"+fileStatus.getPath()+"' OVERWRITE INTO TABLE telecom.cell_strength PARTITION (YEAR='"+year+"',MONTH = '"+month+"' , DAY = '"+day+"'); \"");
//执行命令
Result exec2 = sshExec.exec(execCommand2);
}
//关闭连接
sshExec.disconnect();
hdfs.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
通过在LoadData 类中设置命令之后,然后执行Java程序执行命令,就可以做到用Java代码实现在linux中从外部文件导入分区表的操作!
导入成功后的在HDFS,可以通过目录结构查看分区后的详细情况!
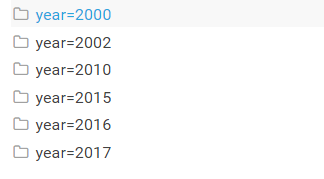
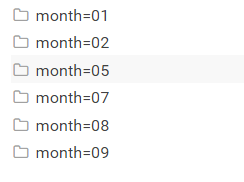
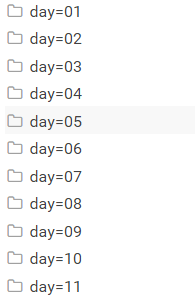
到这里我们就实现了通过Java代码把本地的文件数据导入到Hive的分区表中的操作!
下一篇博客,将介绍的是通过Linux脚本的方式批量导入数据至不同的分区,敬请期待!

文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/103705580

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)