完美解决Hadoop集群无法正常关闭的问题!

相信对于大部分的大数据初学者来说,一定遇见过hadoop集群无法正常关闭的情况。有时候当我们更改了hadoop内组件的配置文件后,必须要通过重启集群来使配置文件生效。
但往往一stop-all.sh,集群下方总会出现下面的提示:
[root@master ~]# stop-dfs.sh
Stopping namenodes on [master]
master: no namenode to stop
slave2: no datanode to stop
slave1: no datanode to stop
…
最开始的时候,我也是看了一个头两个大,这都是啥么情况???
但问题都出来了,只有迎面解决了~
我们都知道在Hadoop中控制脚本启动和停止hadoop后台程序的是哪个脚本。
没错,就是hadoop-daemon.sh
先让我们利用find命令找到它的位置
find / -name hadoop-daemon.sh

通过vim /export/servers/hadoop-2.6.0-cdh5.14.0/sbin/hadoop-daemon.sh
在文件的最后几行,我们终于找到了答案:
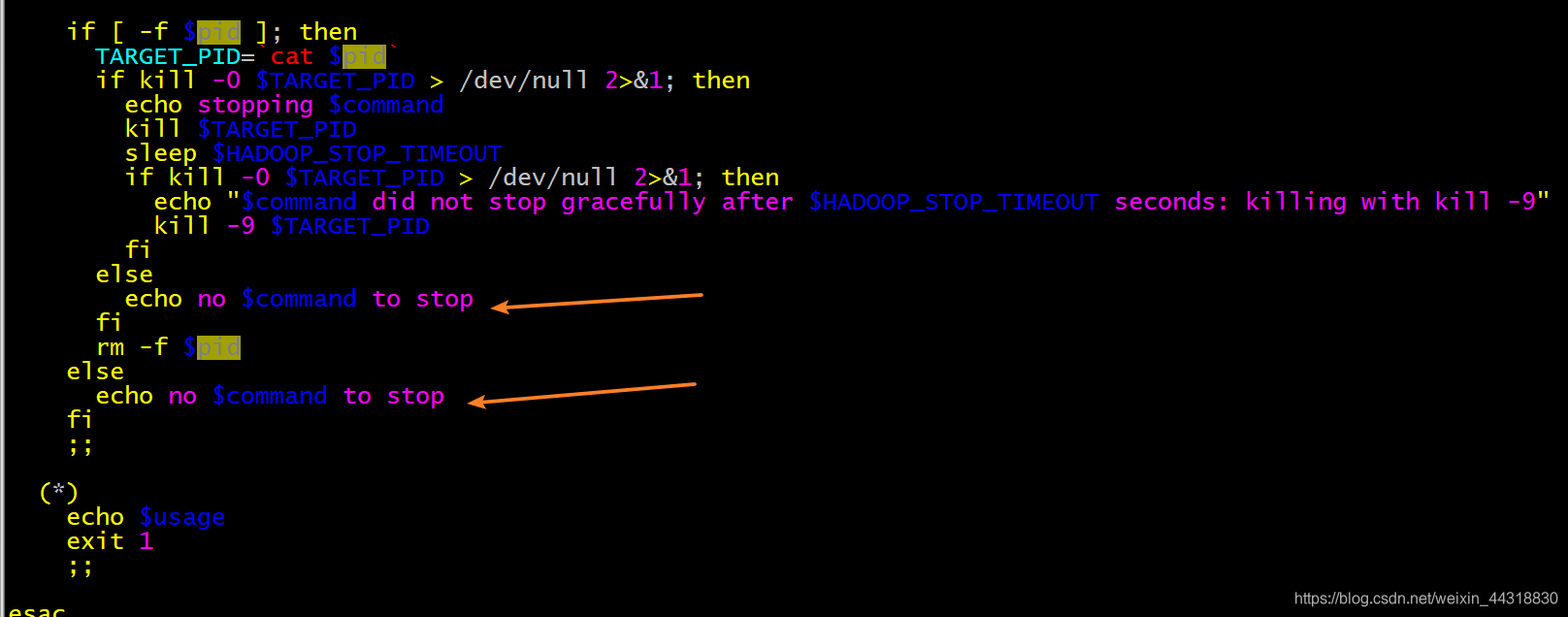
初步分析,如果pid文件不存在就会打印:no xxx to stop
那我们上述出现的情况无非就是hadoop集群关闭的时候,Namenode或者DataNode的pid文件找不着。
通过配置文件最初的描述,我们大概知道pid文件默认是保存在tmp目录下
# HADOOP_PID_DIR The pid files are stored. /tmp by default.
那这个pid文件是啥?根据查阅资料,方知Hadoop启动后,会把进程的PID号存储在一个文件中,这样执行stop-dfs脚本时就可以按照进程PID去关闭进程了。
现在问题原因很明确了,就是/tmp目录下的hadoop-*.pid的文件找不到了。
我们知道/tmp是临时目录,系统会定时清理该目录中的文件。显然把pid文件放在这里是不靠谱的,pid文件长时间不被访问,早被清理了!
所以我们只需要在配置文件中更改默认的pid存放位置即可。但注意,需要先通过kill等方法把进程杀死,等集群关闭之后再更改!!!

同样的道理,你还需要修改yarn-daemon.sh配置文件

好了,从此再也不用担心出现no xxx to stop的警告了!

文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/104339471

- 点赞
- 收藏
- 关注作者
评论(0)