Spark之【RDD编程】详细讲解(No1)——《编程模型的理解与RDD的创建》

上一篇博客《什么是RDD?带你快速了解Spark中RDD的概念!》为大家带来了RDD的概述之后。本篇博客,博主将继续前进,为大家带来RDD编程系列。
该系列第一篇,为大家带来的是编程模型的理解与RDD的创建!
该系列内容十分丰富,高能预警,先赞后看!

RDD编程
1.编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
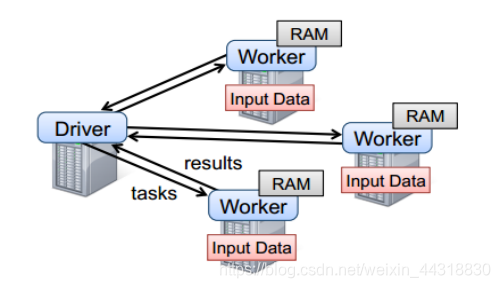
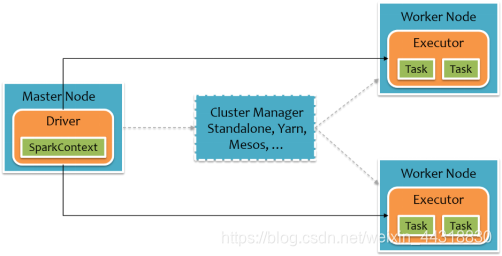
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
2. RDD的创建
在Spark中创建RDD的创建方式可以分为三种:从集合中创建RDD;从外部存储创建RDD;从其他RDD创建。
2.1 从集合中创建
从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD
1) 使用parallelize()从集合创建
scala> val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
- 1
- 2
2) 使用makeRDD()从集合创建
scala> val rdd1 = sc.makeRDD(Array(1,2,3,4,5,6,7,8))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:24
- 1
- 2
2.2 由外部存储系统的数据集创建
包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等,我们会在后面的博客中详细介绍。
scala> val rdd2= sc.textFile("hdfs://hadoop102:9000/RELEASE")
rdd2: org.apache.spark.rdd.RDD[String] = hdfs:// hadoop102:9000/RELEASE MapPartitionsRDD[4] at textFile at <console>:24
- 1
- 2
2.3 从其他RDD创建
第三种方式是通过对现有RDD的转换来创建RDD,因为所涉及到的篇幅比较长,知识点也比较多,故在下一篇博客(No2)中,我们将详细讨论转换。
好了,本次的分享就到这里,受益的小伙伴或对大数据技术感兴趣的朋友可以点个赞哟~

文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/104495259

- 点赞
- 收藏
- 关注作者
评论(0)