Java——Stream数据流(Properties子类、Collection接口加强、MapReduce操作)

目录
1、Properties子类
Properties是专门存储属性信息操作的类,其为Hashtable的子类,Hashtable能保存各种类型数据,但Properties类只能进行字符串数据的保存,因为其主要用于资源文件操作的。

在使用时,使用的是子类中定义的方法
- 构造方法:public Properties();
- 设置属性:public Object setProperties(String key,String value); 若内容不存在,返回null
- 取得属性:public Object getProperties(String key);若内容不存在,返回默认值
在Properties中有两个重要的操作方法:
1)将属性输出到指定输出流中
-
Properties pro = new Properties();
-
pro.setProperty("SH","上海");
-
pro.setProperty("NJ","南京");
-
try {
-
pro.store(new FileOutputStream(new File("D:"+File.separator+"test.properties")),"test");
-
} catch (IOException e) {
-
e.printStackTrace();
-
}
其中打开保存的文档,可见中文为UNICODE编码
2)从输入流读取属性信息
-
try {
-
pro.load(new FileInputStream(new File("D:"+File.separator+"test.properties")));
-
} catch (IOException e) {
-
e.printStackTrace();
-
}
-
System.out.println(pro.getProperty("NJ"));
读出后可发现,资源文件中不能有中文,中文是要经过编码转换的。
当Properties与国际化结合会非常好用,其中不要忽略ResourceBundle类的使用。
2、Collection接口加强
JDK1.8开始,由于接口上可以使用default、static定义方法,那么一些已有接口发生了本质的改变。Iterator接口中提供有一个:
default void forEach(Consumer<?super T>action)
-
List<String> list =new ArrayList<>();
-
list.add("A");
-
list.add("B");
-
list.forEach(System.out ::println); //方法引用
list.forEach(System.out ::println); 直接输出数据,但Collection接口的最重要的改变不是这里,而是在Collection接口的一个方法上:
获取数据流对象:default java.util.stream.Stream<E>stream().
-
List<String> list =new ArrayList<>();
-
list.add("A");
-
list.add("A");
-
list.add("B");
-
Stream<String> stream = list.stream().distinct();//排除重复元素
-
System.out.println(stream.count()); //输出结构为2
3、数据流基本操作
为什么要用Stream?取得数据流,主要 的目的是为了进行数据处理使用。在Sream类中有以下几个方法较为典型:
1)过滤:public Stream<T> filter(Predicate<? super T> var1)。--需要满足某些条件才可以过滤
【举例】:简单过滤
-
List<String> list =new ArrayList<>();
-
list.add("ANV");
-
list.add("AVVC");
-
list.add("BXX");
-
-
Stream<String> stream = list.stream().filter((x) -> x.contains("A")); //过滤出包含A的
-
System.out.println(stream.count()); //输出结果为2
以上只是简单过滤,类似统计操作,没什么意思,若想把符合条件的数据筛选出来,可以使用收集器:
2)public<R,A> R collect(Collector<?super T,A,R> collector)
需要使用Collector接口,该接口可通过java.util.stream.Collectors进行实例化,以List集合收集:
public static<T> Collector<T,?,List<T>>toList().
【举例】:收集操作
-
List<String> list =new ArrayList<>();
-
list.add("ANV");
-
list.add("AVVC");
-
list.add("BXX");
-
-
List<String> list1 = list.stream().filter((x) -> x.contains("A")).collect(Collectors.toList()); //过滤出包含A的
-
System.out.println(list1);
![]()
以上filter方法是区分大小写的,若把数据都换为小写,则无法收集,可以使用转换方法:
3)转换<R> Stream<R> map(Function<? super T, ? extends R> var1);
【举例】:使用map()方法处理
-
List<String> list =new ArrayList<>();
-
list.add("anv");
-
list.add("avvc");
-
list.add("BXX");
-
-
List<String> list1 = list.stream().map((x)-> x.toUpperCase()).filter((x) -> x.contains("A")).collect(Collectors.toList()); //过滤出包含A的
-
System.out.println(list1);
![]()
4)但是,在大数据范围中是允许有分页的,所以可以直接在数据流上进行分页处理操作:
- 跳过的数据行数:Stream<T> skip(long var1);
- 取得的行数:Stream<T> limit(long var1);
【举例】:实现分页
-
List<String> list =new ArrayList<>();
-
list.add("ANV");
-
list.add("AVVC");
-
list.add("BXX");
-
list.add("BACX");
-
list.add("ACX");
-
-
List<String> list1 = list.stream().map((x)-> x.toUpperCase()).filter((x) -> x.contains("A"))
-
.skip(2)
-
.limit(1)
-
.collect(Collectors.toList()); //过滤出包含A的
-
System.out.println(list1);
实现分页前后对比结果:

4、MapReduce操作(重要)
大数据定义范畴中,MapReduce属于两个层次的概念:
- Map处理:针对每行数据进行处理操作;
- Reduce处理:分析统计。
【举例】:做一个订单处理
-
List<Order> all = new ArrayList<>();
-
all.add(new Order("电子",1,1));
-
all.add(new Order("蔬菜",1,10));
-
all.add(new Order("日用品",1,100));
-
double allPrice = all.stream().map((x)-> x.getPrice()*x.getAmount()).reduce((sum,m)-> sum+m).get();
-
System.out.println(allPrice);
![]()
一般处理需要涉及5种数据:种类、平均值、最高值、最低值、总值,在整个处理的数据类型一定是double,此时需要进行一些额外的处理:
- 以Double处理:DoubleStream mapToDouble(ToDoubleFunction<? super T> var1);
取得DoubleStream后,进一步对数据进行处理,处理使用:
- 处理操作:DoubleSummaryStatistics summaryStatistics();
-
List<Order> all = new ArrayList<>();
-
all.add(new Order("电子",1,1));
-
all.add(new Order("蔬菜",1,10));
-
all.add(new Order("日用品",1,100));
-
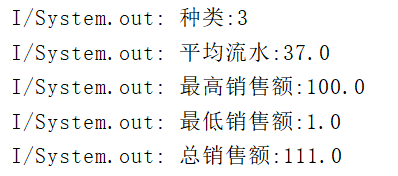
DoubleSummaryStatistics dss = all.stream().mapToDouble((x)-> x.getPrice()*x.getAmount()).summaryStatistics();
-
System.out.println("种类:"+ dss.getCount());
-
System.out.println("平均流水:"+ dss.getAverage());
-
System.out.println("最高销售额:"+ dss.getMax());
-
System.out.println("最低销售额:"+ dss.getMin());
-
System.out.println("总销售额:"+ dss.getSum());
5、总结
1)JDK1.8对类集提供了更多的处理支持;
2)MapReduce:Map处理数据,Reduce统计数据。
作于202003172030,已归档
———————————————————————————————————
本文为博主原创文章,转载请注明出处!
若本文对您有帮助,轻抬您发财的小手,关注/评论/点赞/收藏,就是对我最大的支持!
祝君升职加薪,鹏程万里!
文章来源: winter.blog.csdn.net,作者:Winter_world,版权归原作者所有,如需转载,请联系作者。
原文链接:winter.blog.csdn.net/article/details/104862364

- 点赞
- 收藏
- 关注作者
评论(0)