通俗易懂讲数据仓库之【缓慢变化维】

本篇博客,博主为大家带来的是关于数据仓库中一个非常重要的知识点缓慢变化维的讲解!
码字不易,先赞后看

缓慢变化维
1. 什么是缓慢变化维(SCD)
1.1 缓慢变化维简介
- 缓慢变化维,简称SCD(Slowly Changing Dimensions)
- 一些维度表的数据不是静态的,而是会随着时间而缓慢地变化(这里的缓慢是相对事实表而言,事实表数据变化的速度比维度表快)
- 这种随着时间发生变化的维度称之为缓慢变化维
- 把处理维度表数据历史变化的问题,称为缓慢变化维问题,简称SCD问题
1.2 举例说明
例如:用根据用户维度,统计不同出生年份的消费金额占比。(80后、90后、00后)。
而期间,用户可能去修改用户数据,例如:将出生日期改成了 1992年。此时,用户维度表就发生了变化。当然这个变化相对事实表的变换要慢。但这个用户维度表的变化,就是缓慢变化维。

这个用户的数据不是一直不变,而是有可能发生变化。例如:用户修改了出生日期、或者用户修改了住址。
2. SCD问题的几种解决方案
以下为解决缓慢变化维问题的几种办法:
- 保留原始值
- 改写属性值
- 增加维度新行
- 增加维度新列
- 添加历史表
SCD解决方案 - 保留原始值
- 某一个属性值绝不会变化。事实表始终按照该原始值进行分组。例如:
出生日期的数据,始终按照用户第一次填写的数据为准。
SCD解决方案 - 改写属性值
- 对其相应需要重写维度行中的旧值,以当前值替换。因此其始终反映最近的情况。
- 当一个维度值的数据源发生变化,并且不需要在维度表中保留变化历史时,通常用新数据来覆盖旧数据。这样的处理使属性所反映的中是最新的赋值。
例如:
用户维度表
修改前:

修改后:

- 这种方法有个前提,用户不关心这个数据的变化
- 这样处理,易于实现,但是没有保留历史数据,无法分析历史变化信息
SCD解决方案 - 增加维度新行
数据仓库系统的目标之一是正确地表示历史。典型代表就是拉链表。
保留历史的数据,并插入新的数据。
例如:
用户维度表
修改前:

修改后:

SCD解决方案 - 增加维度新列
用不同的字段来保存不同的值,就是在表中增加一个字段,这个字段用来保存变化后的当前值,而原来的值则被称为变化前的值。总的来说,这种方法通过添加字段来保存变化后的痕迹。
例如:
用户维度表
修改前:
修改后:

SCD解决方案 - 使用历史表
另外建一个表来保存历史记录,这种方式就是将历史数据与当前数据完全分开来,在维度中只保存当前最新的数据。
用户维度表

用户维度历史表

这种方式的优点是可以同时分析当前及前一次变化的属性值,缺点是只保留了最后一次变化信息。
3. 数仓项目-拉链表技术介绍
数据仓库的数据模型设计过程中,经常会遇到这样的需求:
- 表中的部分字段会被update,例如:
用户的地址,产品的描述信息,品牌信息等等;
- 需要查看某一个时间点或者时间段的历史快照信息,例如:
查看某一个产品在历史某一时间点的状态
查看某一个用户在过去某一段时间内,更新过几次等等
- 变化的比例和频率不是很大,例如:
总共有1000万的会员,每天新增和发生变化的有10万左右
相信大家看到这里,可能对拉链表技术已经实现的效果可能不太清楚,下面将通过一个案例为大家进行演示实现拉链表的具体操作。
4. 商品历史快照案例
需求:
有一个商品表:
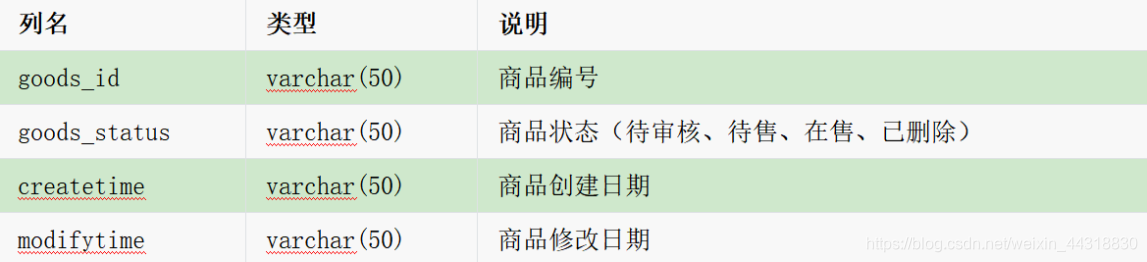
2019年12月20日的数据如下所示:
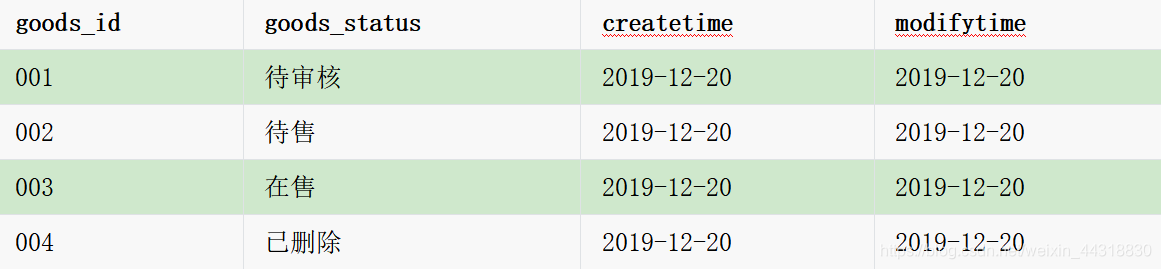
商品的状态,会随着时间推移而变化,我们需要将商品的所有变化的历史信息都保存下来。如何实现呢?
4.1 使用拉链表保存历史快照思路
- 拉链表不存储冗余的数据,只有某行的数据发生变化,才需要保存下来,相比每次全量同步会节省存储空间。
- 能够查询到历史快照
- 额外的增加了两列(dw_start_date、dw_end_date),为数据行的生命周期
12月20日商品拉链表的数据:
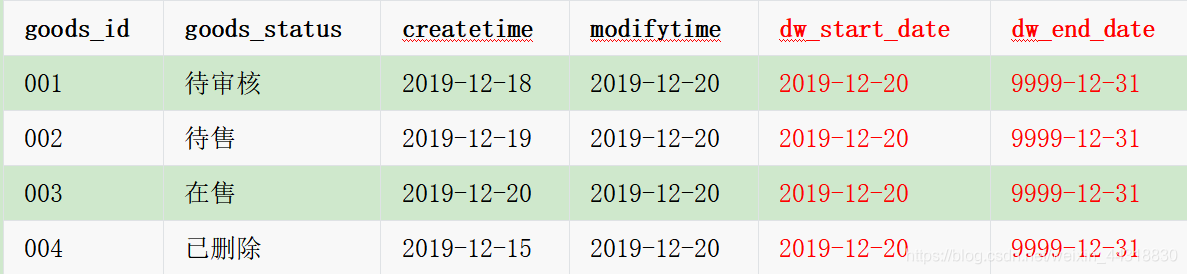
12月20日的数据是全新的数据导入到dw表
dw_start_date表示某一条数据的生命周期起始时间,即数据从该时间开始有效(即生效日期)
dw_end_date表示某一条数据的生命周期结束时间,即数据到这一天(不包含)(即失效日期)
dw_end_date为9999-12-31,表示当前这条数据是最新的数据,数据到9999-12-31才过期
12月21日商品拉链表的数据
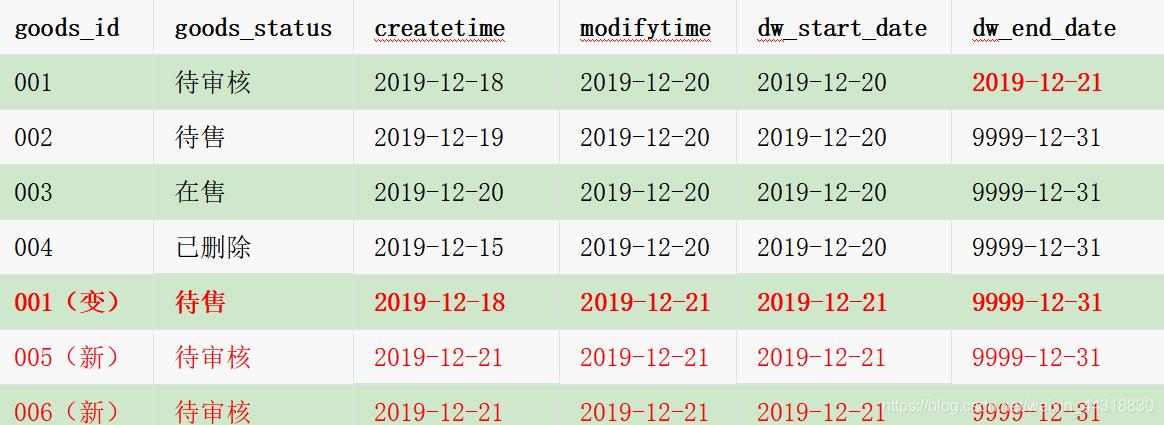
可以发现:
- 拉链表中没有存储冗余的数据,(只要数据没有变化,无需同步)
- 001编号的商品数据的状态发生了变化(从待审核 → 待售),需要将原有的dw_end_date从9999-12-31变为2019-12-21,表示待审核状态,在2019/12/20(包含) - 2019/12/21(不包含)有效
- 001编号新的状态重新保存了一条记录,dw_start_date为2019/12/21,dw_end_date为9999/12/31。新数据005、006、dw_start_date为2019/12/21,dw_end_date为9999/12/31
12月22日商品拉链表的数据
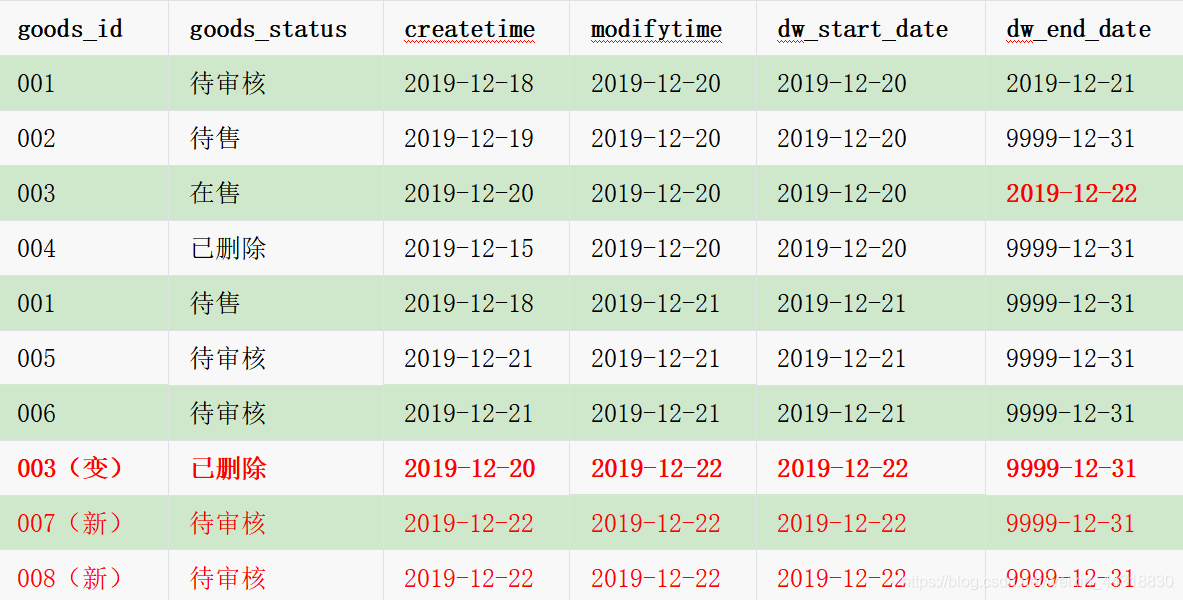
- 003编号的商品数据的状态发生了变化(从在售→已删除),需要将原有的dw_end_date从9999-12-31变为2019-12-22,表示在售状态,在2019/12/20(包含) - 2019/12/22(不包含)有效
- 003编号新的状态重新保存了一条记录,dw_start_date为2019/12/22,dw_end_date为9999/12/31。新数据007、008、dw_start_date为2019/12/22,dw_end_date为9999/12/31
4.2 拉链表存储历史快照代码实现
操作步骤:
- 在原有dw层表上,添加额外的两列
生效日期(dw_start_date)
失效日期(dw_end_date)
- 只同步当天修改的数据到ods层
- 拉链表算法实现
编写SQL处理当天最新的数据(新添加的数据和修改过的数据)
编写SQL处理dw层历史数据,重新计算之前的dw_end_date
- 拉链表的数据为:当天最新的数据 UNION ALL 历史数据
4.3 具体实现
MySQL创建商品表
-- 创建数据库
create database if not exists demo;
-- 创建商品表
create table if not exists `demo`.`t_product_2`(
goods_id varchar(50), -- 商品编号
goods_status varchar(50), -- 商品状态
createtime varchar(50), -- 商品创建时间
modifytime varchar(50) -- 商品修改时间
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Hive ODS层建表
-- 创建表
create database if not exists `demo`;
-- 创建ods层表
create table if not exists `demo`.`ods_product_2`(
goods_id string, -- 商品编号
goods_status string, -- 商品状态
createtime string, -- 商品创建时间
modifytime string -- 商品修改时间
)
partitioned by (dt string)
row format delimited fields terminated by ',' stored as TEXTFILE;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Hive dw层创建拉链表
-- 创建拉链表
create table if not exists `demo`.`dw_product_2`(
goods_id string, -- 商品编号
goods_status string, -- 商品状态
createtime string, -- 商品创建时间
modifytime string, -- 商品修改时间
dw_start_date string, -- 生效日期
dw_end_date string -- 失效日期
)
row format delimited fields terminated by ',' stored as TEXTFILE;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
全量导入2019年12月20日数据
1、MySQL数据库导入12月20日数据(4条数据)
insert into `demo`.`t_product_2`(goods_id, goods_status, createtime, modifytime) values
('001', '待审核', '2019-12-18', '2019-12-20'),
('002', '待售', '2019-12-19', '2019-12-20'),
('003', '在售', '2019-12-20', '2019-12-20'),
('004', '已删除', '2019-12-15', '2019-12-20');
- 1
- 2
- 3
- 4
- 5
2、使用Kettle进行全量同步MySQL数据到Hive ods层表
关于如何使用Kettle同步数据的操作博主已经在上面一篇博客大数据实战【千亿级数仓】阶段二详细说明了,感兴趣的朋友可以去看看。
创建Hive分区
-- 创建分区
alter table `demo`.`ods_product_2` add if not exists partition (dt='${dt}');
- 1
- 2
表输入
SELECT
*
FROM t_product_2
where modifytime <= '${dt}'
- 1
- 2
- 3
- 4
3、编写SQL从ods导入dw当天最新的数据
-- 从ods层导入dw当天最新数据
insert overwrite table `demo`.`dw_product_2`
select
goods_id, -- 商品编号
goods_status, -- 商品状态
createtime, -- 商品创建时间
modifytime, -- 商品修改时间
modifytime as dw_start_date, -- 生效日期
'9999-12-31' as dw_end_date -- 失效日期
from
`demo`.`ods_product_2`
where
dt = '2019-12-20';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
增量导入2019年12月21日数据
1、MySQL数据库导入12月21日数据(6条数据)
UPDATE `demo`.`t_product_2` SET goods_status = '待售', modifytime = '2019-12-21' WHERE goods_id = '001';
INSERT INTO `demo`.`t_product_2`(goods_id, goods_status, createtime, modifytime) VALUES
('005', '待审核', '2019-12-21', '2019-12-21'),
('006', '待审核', '2019-12-21', '2019-12-21');
- 1
- 2
- 3
- 4
2、使用Kettle开发增量同步MySQL数据到Hive ods层表
Hive创建分区
-- 创建分区
alter table `demo`.`ods_product_2` add if not exists partition (dt='${dt}');
- 1
- 2
表输入读取MySQL数据
SELECT
*
FROM t_product_2
where modifytime = '${dt}'
- 1
- 2
- 3
- 4
3、编写SQL处理dw层历史数据,重新计算之前的dw_end_date
-- 重新计算dw层拉链表中的失效时间
select
t1.goods_id, -- 商品编号
t1.goods_status, -- 商品状态
t1.createtime, -- 商品创建时间
t1.modifytime, -- 商品修改时间
t1.dw_start_date, -- 生效日期(生效日期无需重新计算)
case when (t2.goods_id is not null and t1.dw_end_date > '2019-12-21')
then '2019-12-21'
else t1.dw_end_date -- 小的是以前修改的,不用修改,只修改9999-12-31的数据
end as dw_end_date -- 更新生效日期(需要重新计算)
from
`demo`.`dw_product_2` t1
left join
(select * from `demo`.`ods_product_2` where dt='2019-12-21') t2
on t1.goods_id = t2.goods_id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4、合并当天最新的数据和历史数据到dw层
insert overwrite table `demo`.`dw_product_2`
select
t1.goods_id, -- 商品编号
t1.goods_status, -- 商品状态
t1.createtime, -- 商品创建时间
t1.modifytime, -- 商品修改时间
t1.dw_start_date, -- 生效日期(生效日期无需重新计算)
case when (t2.goods_id is not null and t1.dw_end_date > '2019-12-21')
then '2019-12-21'
else t1.dw_end_date
end as dw_end_date -- 更新生效日期(需要重新计算)
from
`demo`.`dw_product_2` t1
left join
(select * from `demo`.`ods_product_2` where dt='2019-12-21') t2
on t1.goods_id = t2.goods_id
union all
select
goods_id, -- 商品编号
goods_status, -- 商品状态
createtime, -- 商品创建时间
modifytime, -- 商品修改时间
modifytime as dw_start_date, -- 生效日期
'9999-12-31' as dw_end_date -- 失效日期
from
`demo`.`ods_product_2` where dt='2019-12-21' -- 只有新增和修改的数据
order by dw_start_date, goods_id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
到这里,我们的拉链表的操作就完了,接下来让我们来进行一些查询来验证效果。
查询拉链表
1、获取2019-12-20日的历史快照数据
select * from demo.dw_product_2 where dw_start_date <= '2019-12-20' and dw_end_date > '2019-12-20' order by goods_id;
- 1

2、获取最新的商品快照数据
select * from demo.dw_product_2 where dw_end_date = '9999-12-31' order by goods_id;
- 1

感谢看到这里的朋友,为你们的学习精神点赞👍
小结
本篇博客为大家详细介绍了大数据数据仓库中一个非常重要的概念——缓慢变化维,以及讲述了一个简单的入门案例。
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波🙏

文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/105961276

- 点赞
- 收藏
- 关注作者
评论(0)