大数据实战【千亿级数仓】阶段五

本篇博客,为大家带来的是关于大数据实战【千亿级数仓】阶段五的内容。

该阶段中我们需要达成的目标有:
- 学习、掌握kylin的使用,使用kylin,为数据仓库内的数据进行预计算
关于Kylin的入门及使用安装,具体的内容可以参考博主写的kylin专栏的内容:
👉Kylin
所以本篇博客,为大家带来的则是如何将Kylin与我们的数仓项目进行结合,即使用Kylin,为数据仓库内的ads层结果数据进行预计算处理。
基于Kylin开发Ads层
项目需求介绍
因为业务需要,公司运营部门,希望随时能够自己编写SQL语句,快速获取到不同维度数据的指标,故基于Kylin OLAP分析平台,搭建快速OLAP分析平台。
业务开发
开发步骤:
- 创建 itcast_shop 项目
- 导入dw层宽表数据
- 创建数据模型
- 创建Cube立方体
- 构建立方体
- 执行查询
具体操作步骤:
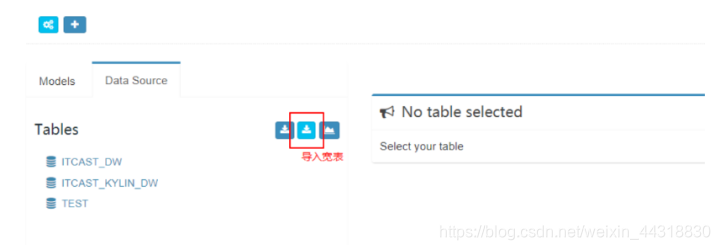
在kylin中导入数据源

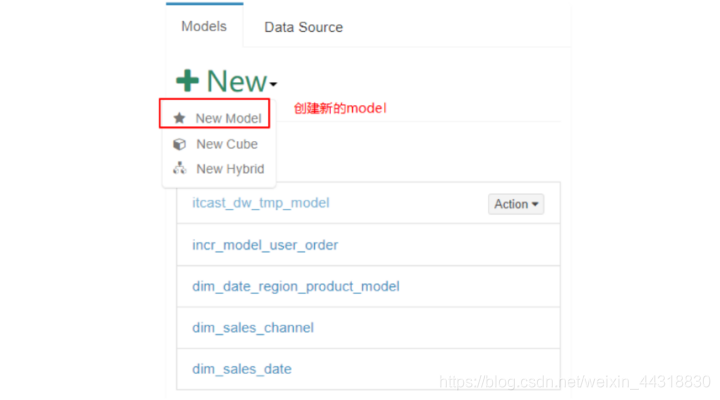
创建model
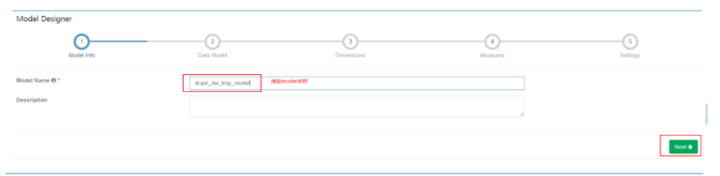
指定model名称:
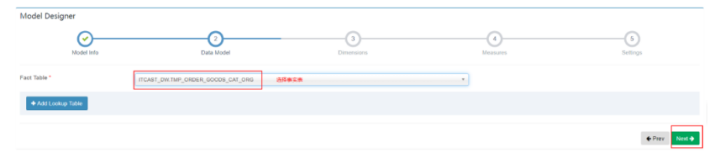
选择事实表:
创建完了Model,接着我们需要创建Cube,创建Cube就需要根据我们根据业务需求中所书写的SQL语句进行操作。
这里举一个在前面阶段我们所求得的SQL指标的例子。
全国、无商品分类维度的交易信息
需求:
- 获取全国、无商品分类维度的分交易类型数据
- 获取全国、无商品分类维度的不分交易类型的数据
对应的SQL
-- 获取全国、无商品分类维度的分交易类型数据
select
paytype,
count(distinct orderid) total_cnt,
sum(goodsprice) total_money
from
itcast_dw.TMP_ORDER_GOODS_CAT_ORG
group by paytype;
-- 获取全国、无商品分类维度的不分交易类型的数据
select
'9' as paytype,
count(distinct orderid) total_cnt,
sum(goodsprice) total_money
from
itcast_dw.TMP_ORDER_GOODS_CAT_ORG;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
全国、一级商品分类维度交易信息
需求:
- 获取全国、一级商品分类维度的分交易类型数据
- 获取全国、一级商品分类维度的不分交易类型数据
对应的SQL
-- 1、获取全国、一级商品分类维度的分交易类型数据
select
firstcat,
paytype,
count(distinct orderid) total_cnt,
sum(goodsprice) total_money
from
itcast_dw.TMP_ORDER_GOODS_CAT_ORG
group by firstcat, paytype;
-- 2、获取全国、一级商品分类维度的不分交易类型数据
select
firstcat,
count(distinct orderid) total_cnt,
sum(goodsprice) total_money
from
itcast_dw.TMP_ORDER_GOODS_CAT_ORG
group by firstcat;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
获取到SQL指标之后,我们就可以创建Cube立方体,并build构建立方体,最后再根据SQL语句,在线进行查询即可。
因为这里面所涉及到的Kylin基本的流程操作。而博主在之前的博客kylin入门实操已经为大家较为详细地介绍了kylin的操作流程,所以这里就不再做过多的赘述。
大家在领悟了Kylin的基本流程之后,根据已有的SQL,利用Kylin进行加速查询还是比较容易的。
小结
大数据实战【千亿级数仓】阶段五的内容到这里就结束了。大家需要在了解Kylin基本操作的基础上,对我们数仓项目ads数据层的数据进行预处理,加速查询!!!
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波🙏

文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/106245790

- 点赞
- 收藏
- 关注作者
评论(0)