简单介绍 HDFS,MapReduce,Yarn 的 架构思想和原理

大家好,我是 梦想家Alex 。之前实际上我也写了不少关于大数据技术组件的文章,例如:
…
但感觉基本上都是在描述一些理论层面的内容,缺少一些架构的思想精髓 。而且大数据技术其实是分布式技术在数据处理领域的创新型应用,其本质就是利用更多的计算机组成一个集群,提供更多的计算资源,从而满足更大的计算压力要求。说的通俗易懂一些,就是大数据技术的诞生解决的就是数据存储和计算的问题。正好最近在刷李智慧老师的书和极客专栏,想输出一些干货。那本篇文章,我想先通过一个引子,为大家带来 Hadoop 三大组件,例如 HDFS,MapReduce,Yarn 的架构分析和梳理,希望对大家学习成长有所帮助 。

引子
大数据就是将各种数据统一收集起来进行计算,发掘其中的价值。这些数据,既包括数据库的数据,也包括日志数据,还包括专门采集的用户行为数据;既包括企业内部自己产生的数据,也包括从第三方采购的数据,还包括使用网络爬虫获取的各种互联网公开数据 …
面对如此庞大的数据,如何存储、如何有效利用大规模的服务器集群处理计算才是大数据技术的核心。
HDFS 分布式文件存储架构
我们知道,Google 大数据“三驾马车”的第一驾是 GFS(Google 文件系统),而 Hadoop 的第一个产品是 HDFS,可以说分布式文件存储是分布式计算的基础,也可见分布式文件存储的重要性。如果我们将大数据计算比作烹饪,那么数据就是食材,而 Hadoop 分布式文件系统 HDFS 就是烧菜的那口大锅。
厨师来来往往,食材进进出出,各种菜肴层出不穷,而不变的则是那口大锅。大数据也是如此,这些年来,各种计算框架、各种算法、各种应用场景不断推陈出新,让人眼花缭乱,但是大数据存储的王者依然是 HDFS。
为什么 HDFS 的地位如此稳固呢?在整个大数据体系里面,最宝贵、最难以代替的资产就是数据,大数据所有的一切都要围绕数据展开。HDFS 作为最早的大数据存储系统,存储着宝贵的数据资产,各种新的算法、框架要想得到人们的广泛使用,必须支持 HDFS 才能获取已经存储在里面的数据。所以大数据技术越发展,新技术越多,HDFS 得到的支持越多,我们越离不开 HDFS。HDFS 也许不是最好的大数据存储技术,但依然最重要的大数据存储技术。
之前在 前方高能 | HDFS 的架构,你吃透了吗?这篇文章中,我们就已经谈到了 HDFS 的架构 ,如下图所示:
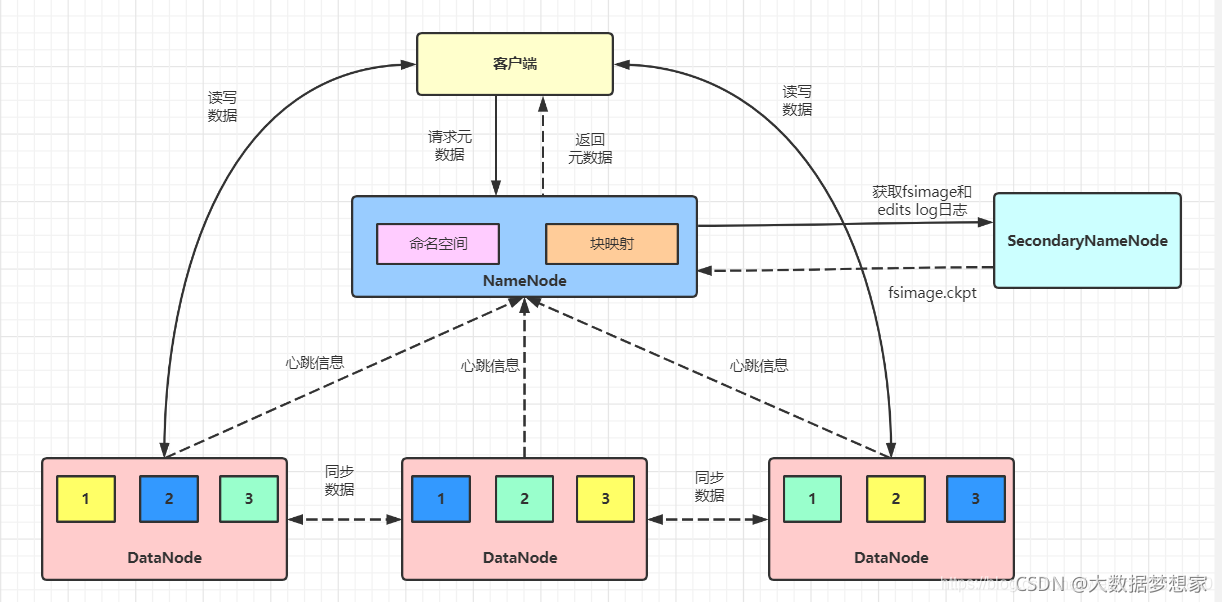
HDFS 可以将数千台服务器组成一个统一的文件存储系统,其中 NameNode 服务器充当文件控制块的角色,进行文件元数据管理,即记录文件名、访问权限、数据存储地址等信息,而真正的文件数据则存储在 DataNode 服务器上。
DataNode 以块为单位存储数据,所有的块信息,比如 块 ID、块所在的服务器 IP 地址等,都记录在 NameNode 服务器上,而具体的块数据存储在 DataNode 服务器上。理论上,NameNode 可以将所有 DataNode 服务器上的所有数据块都分配给一个文件,也就是说,一个文件可以使用所有服务器的硬盘存储空间 。
此外,HDFS 为了保证不会因为磁盘或者服务器损坏而导致文件损坏,还会对数据块进行复制,每个数据块都会存储在多台服务器上,甚至多个机架上。
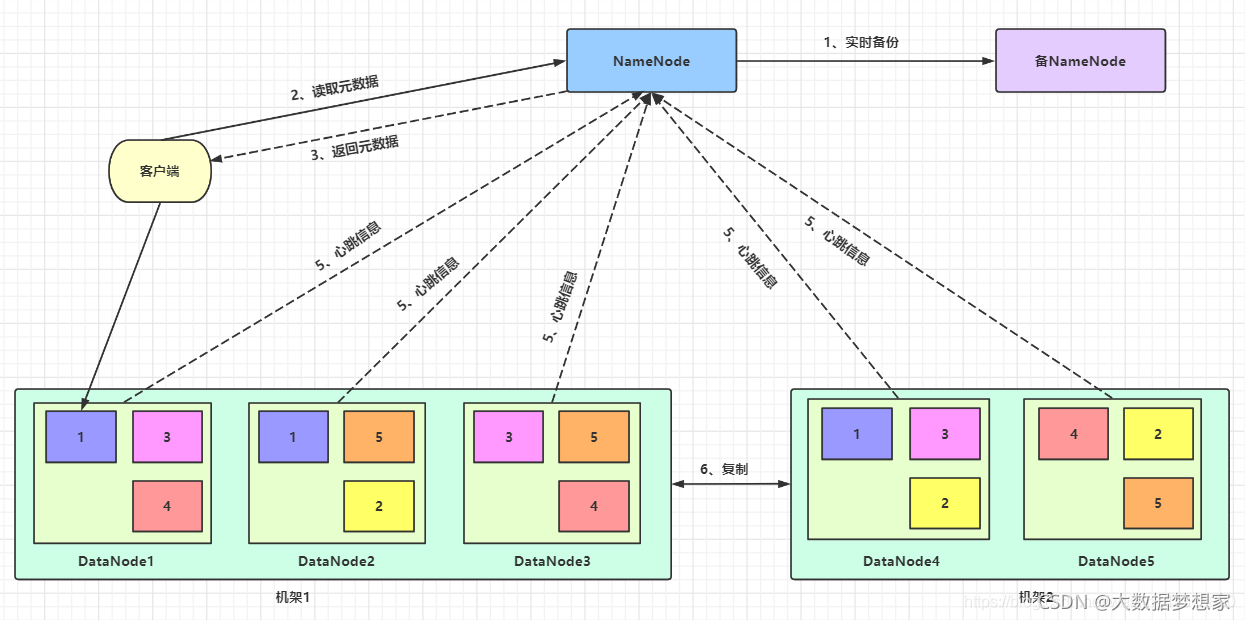
关于 HDFS是怎么做文件管理和容错,可以看下这篇文章:干货 | HDFS是怎么做文件管理和容错的?
MapReduce 大数据计算架构
大数据计算的核心思路是移动计算比移动数据更划算。既然计算方法跟传统计算方法不一样,移动计算而不是移动数据,那么用传统的编程模型进行大数据计算就会遇到很多困难,因此 Hadoop 大数据计算使用了一种叫作 MapReduce 的编程模型。
其实 MapReduce 编程模型并不是 Hadoop 原创,甚至也不是 Google 原创,但是 Google 和 Hadoop 创造性地将 MapReduce 编程模型用到大数据计算上,立刻产生了神奇的效果,看似复杂的各种各样的机器学习、数据挖掘、SQL 处理等大数据计算变得简单清晰起来。
就好比数据存储在 HDFS 上的最终目的还是为了计算,通过数据分析或者机器学习获得有益的结果。但是如果像传统的应用程序那样,把 HDFS 当做普通文件,从文件中读取数据后进行计算,那么对于需要一次计算数百 TB 数据的大数据计算场景,就不知道要算到什么时候了。
大数据处理的经典计算框架是 MapReduce 。MapReduce 的核心思想是对数据进行分片计算。既然数据是以块为单位分布存储在很多服务器组成的集群上,那么能不能就在这些服务器上针对每个数据块进行分布式计算呢 ?
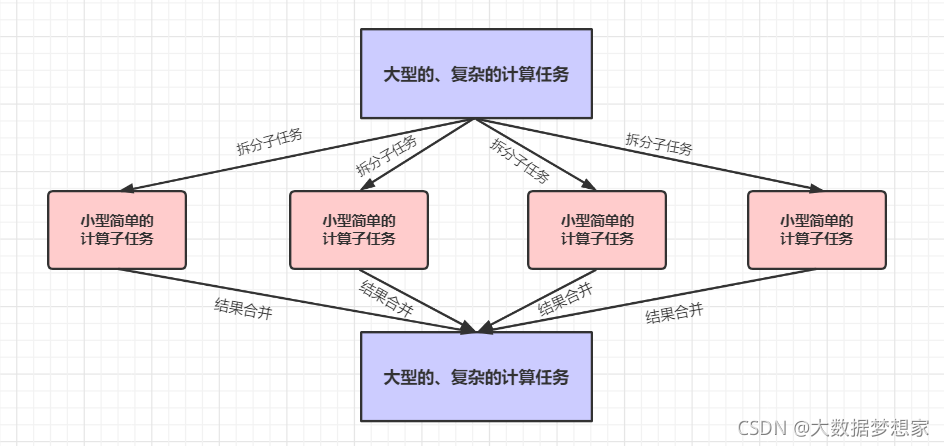
事实上,MapReduce 可以在分布式集群的多台服务器上启动同一个计算程序,每个服务器上的程序进程都可以读取本服务器上要处理的数据块进行计算,因此,大量的数据就可以同时进行计算了。但是这样一来,每个数据块的数据都是独立的,如果这些数据块需要进行关联计算怎么办?
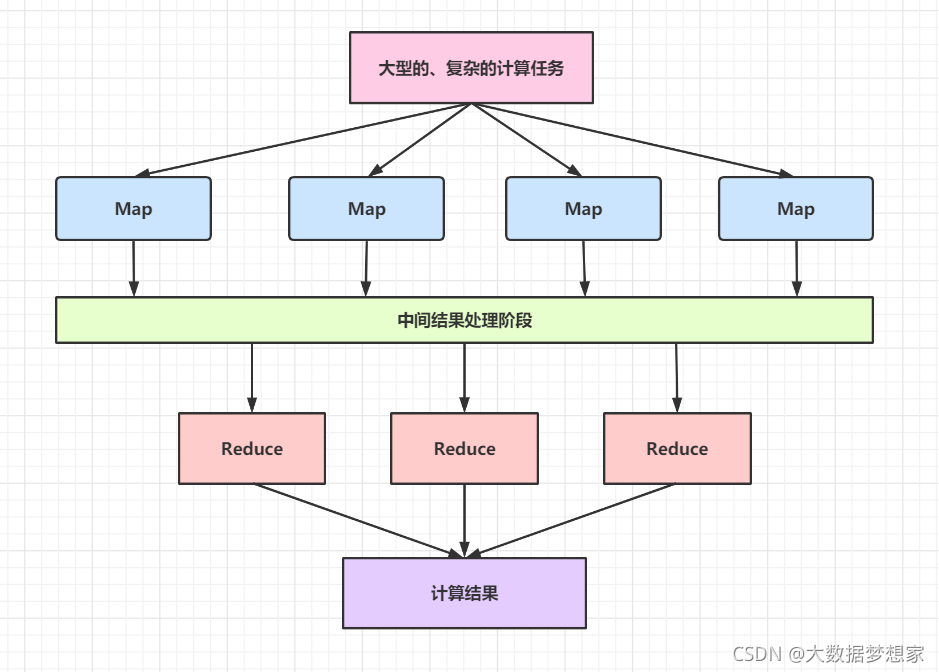
MapReduce 将计算过程分成了两个部分:一部分是 map 过程,每个服务器上会启动多个 map 进程,map 优先读取本地数据进行计算,计算后输出一个 <key,value> 集合;另一部分是 reduce 部分,MapReduce 在每个服务器上都会启动多个 reduce 进程,然后对所有 map 输出的 <key,value> 集合进行 shuffle 操作。所谓的 shuffle 就是将相同的 key 发送到同一个 reduce 进程中,在 reduce 中完成数据关联计算 。
为了更直观的展示这个过程,下面以经典的 WordCount ,即统计所有数据中相同单词的词频数据为例,来认识 map 和 reduce 的处理过程 。
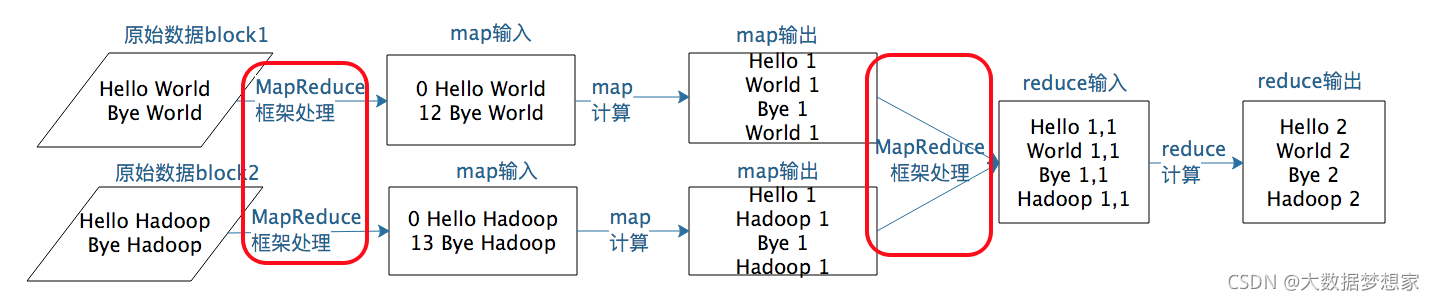
假设原始数据有两个数据块,MapReduce 框架启动了两个 map 进程进行处理,它们分别读入数据 。 map 函数会对输入数据进行分词处理,然后针对每个单词输出 < 单词,1 > 这样的 < key,value > 结果 。 然后 MapReduce 框架进行 shuffle 操作,相同的 key 发送给同一个 reduce 进程,reduce 的输入就是 < key ,value 的列表>这样的结构,即相同 key 的 value 合并成了一个列表。
在这个示例中,这个 value 列表就是由很多个 1 组成的列表。reduce 对这些 1 进行求和操作,就得到了每个单词的词频结果了。
示例代码如下:
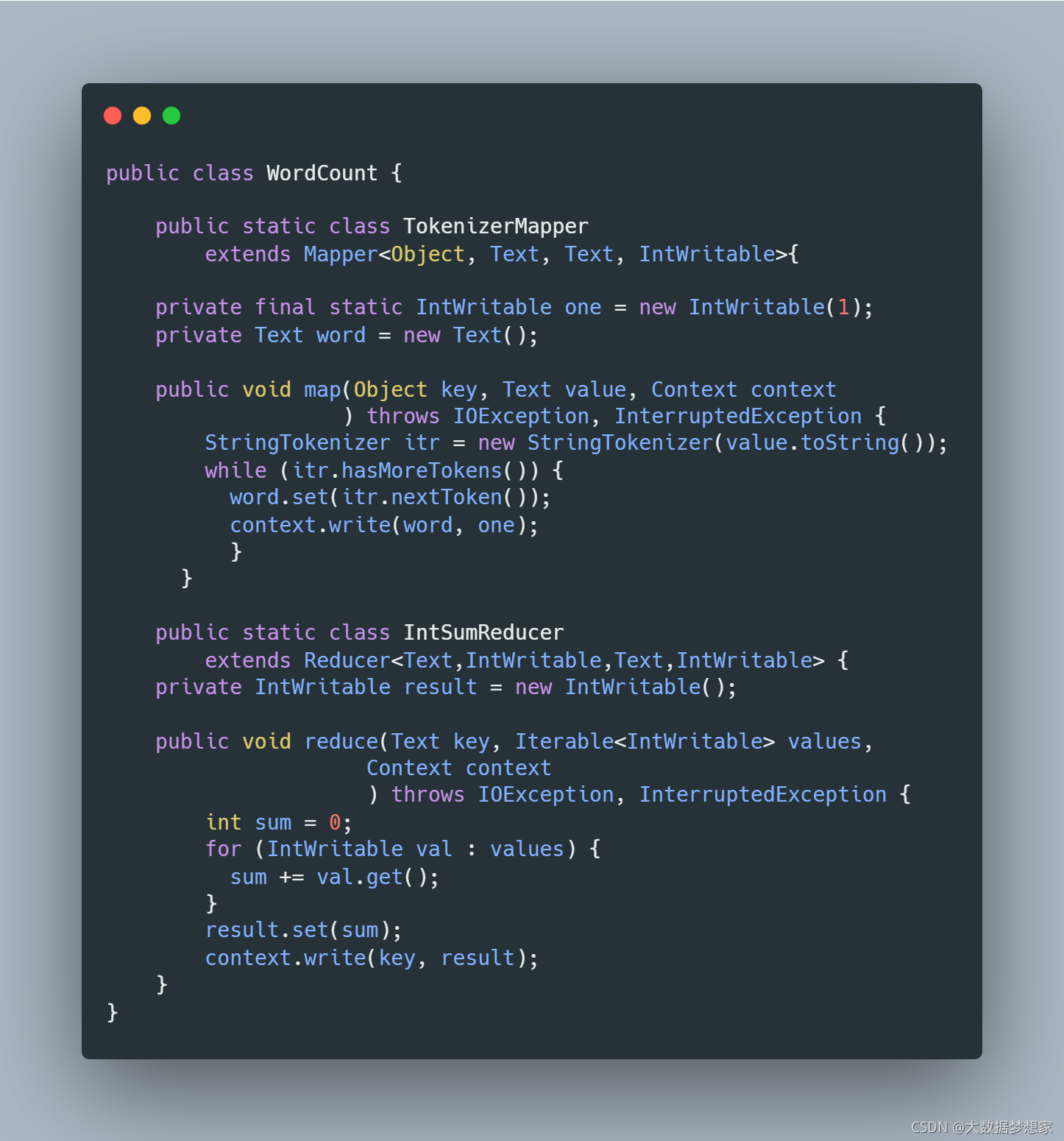
上面的源代码描述的是 map 和 reduce 进程合作完成数据处理的过程,那么这些进程是如何在分布式的服务器集群上启动的呢?数据是如何流动并最终完成计算的呢?
我们以 Hadoop 1 为例,带领大家一起看下这个过程。
MapReduce1 主要有 JobTracker 和 TaskTracker 这两种角色,JobTracker 在 MapReduce 的集群只有一个,而 TaskTracker 则和 DataNode 一起启动在集群的所有服务器上。
MapReduce 应用程序 JobClient 启动后,会向 JobTracker 提交作业,JobTracker 根据作业中输入的文件路径分析需要在哪些服务器上启动 map 进程,然后就在这些服务器上的 TaskTracker 发送任务命令。
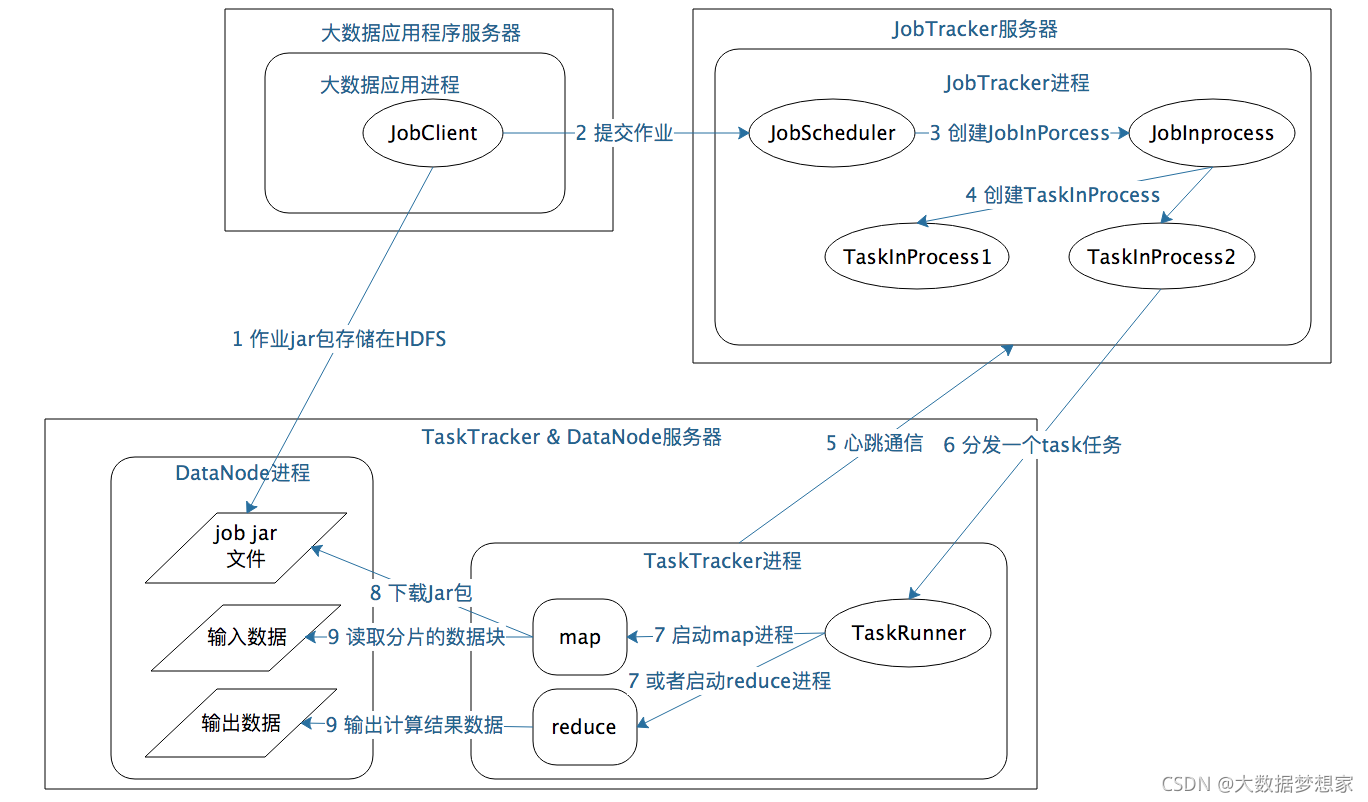
TaskTracker 收到任务后,启动一个TaskRunner 进程下载任务对应的程序,然后反射加载程序中的 map 函数,读取任务中分配的数据块,并进行map计算。map计算结束后,TaskTracker会对 map 输出进行shuffle 操作,然后 TaskRunner 加载 reduce 函数进行后续计算 。
Yarn 资源调度框架
在 MapReduce 应用程序的启动过程中,最重要的就是要把 MapReduce 程序分发到大数据集群的服务器上,在上文介绍的 Hadoop 1 中,这个过程主要是通过 TaskTracker 和 JobTracker 通信来完成。
但是这种架构方案有什么缺点呢?
服务器集群资源调度管理和 MapReduce 执行过程耦合在一起,如果想在当前集群中运行其他计算任务,比如 Spark 或者 Storm,就无法统一使用集群中的资源了。
在 Hadoop 早期的时候,大数据技术就只有 Hadoop 一家,这个缺点并不明显。但随着大数据技术的发展,各种新的计算框架不断出现,我们不可能为每一种计算框架部署一个服务器集群,而且就算能部署新集群,数据还是在原来集群的 HDFS 上。所以我们需要把 MapReduce 的资源管理和计算框架分开,这也是 Hadoop 2 最主要的变化,就是将 Yarn 从 MapReduce 中分离出来,成为一个独立的资源调度框架。
Yarn 的设计思路也非常有趣
首先,为了避免功能的高度耦合,你得将原 JobTracker 的功能进行拆分
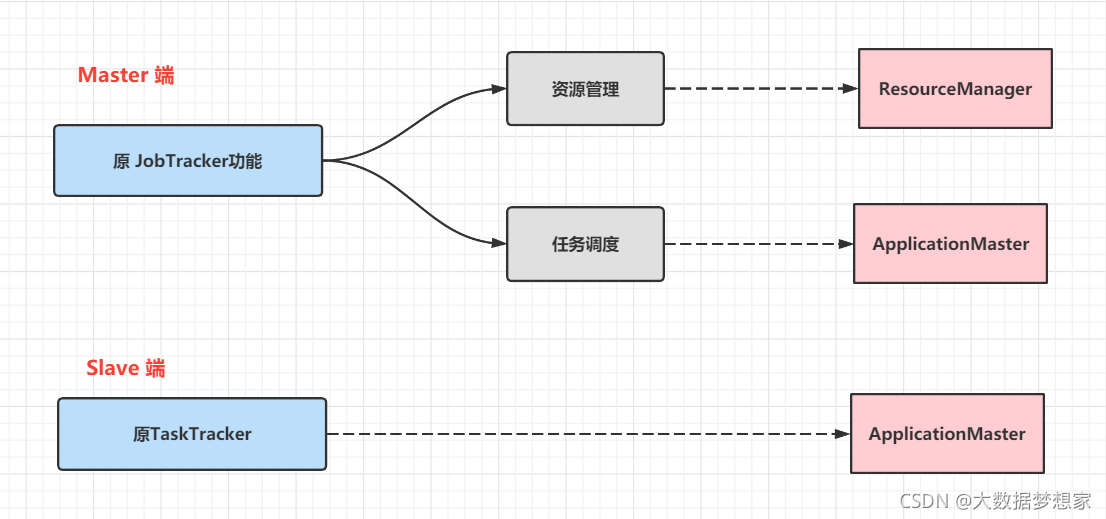
其次,一个集群多个框架,即在一个集群上部署一个统一的资源调度框架YARN,在YARN之上可以部署各种计算框架。
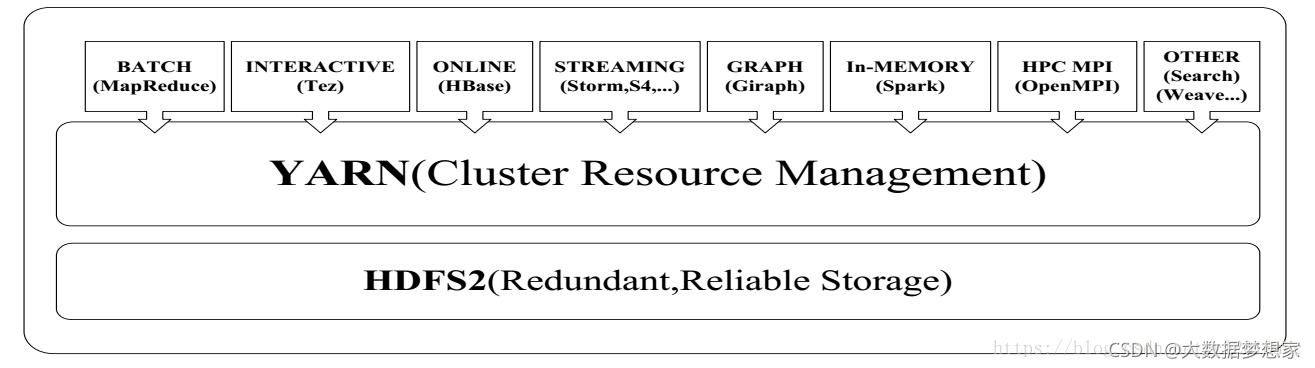
最终形成 Yarn 的整体架构如下所示:
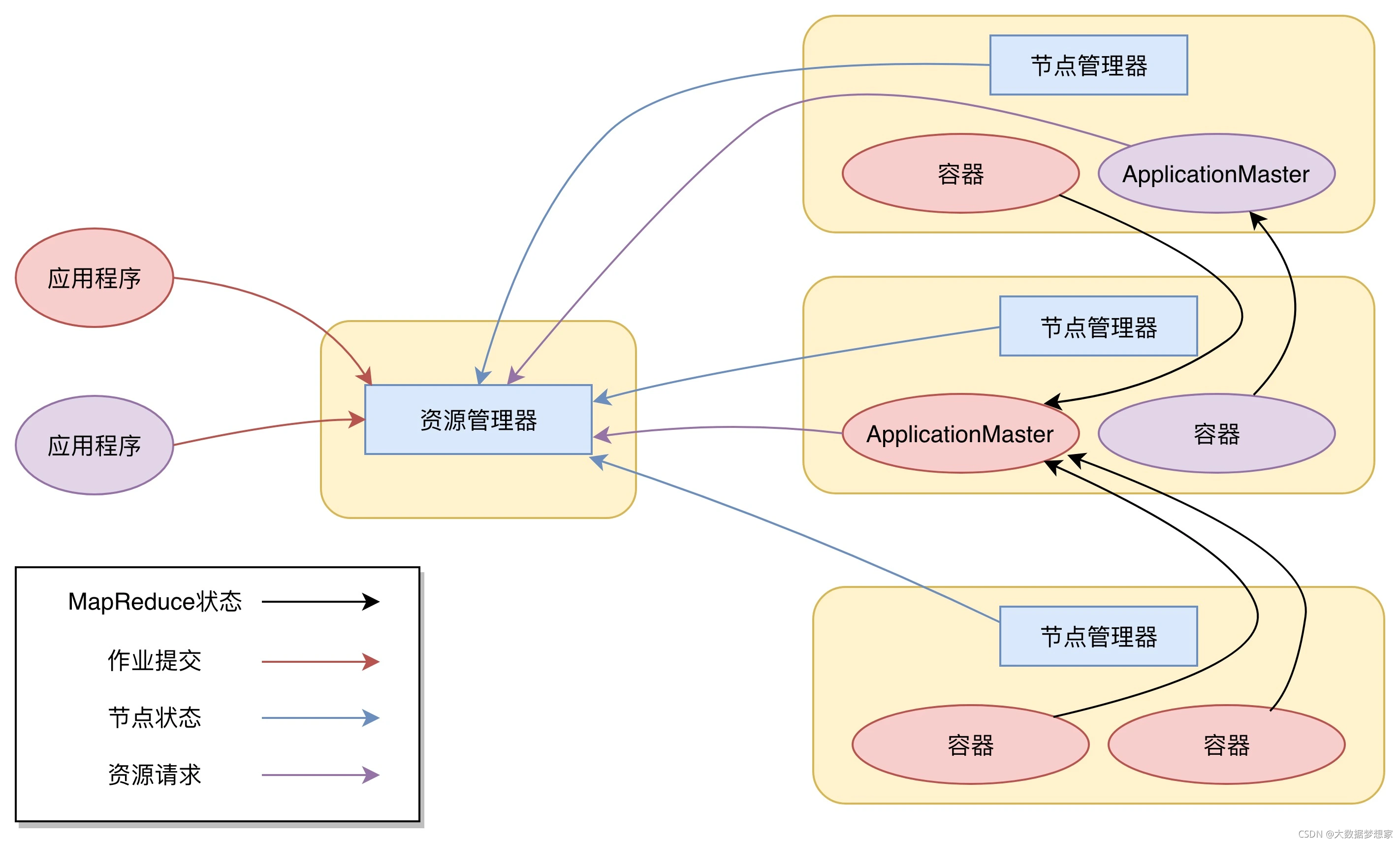
从图上看,Yarn 包括两个部分:一个是资源管理器(Resource Manager),一个是节点管理器(Node Manager)。这也是 Yarn 的两种主要进程:ResourceManager 进程负责整个集群的资源调度管理,通常部署在独立的服务器上;NodeManager 进程负责具体服务器上的资源和任务管理,在集群的每一台计算服务器上都会启动,基本上跟 HDFS 的 DataNode 进程一起出现。
具体说来,资源管理器又包括两个主要组件:调度器和应用程序管理器。调度器其实就是一个资源分配算法,根据应用程序(Client)提交的资源申请和当前服务器集群的资源状况进行资源分配。
Yarn 内置了几种资源调度算法,包括 Fair Scheduler、Capacity Scheduler 等,你也可以开发自己的资源调度算法供 Yarn 调用。Yarn 进行资源分配的单位是容器(Container),每个容器包含了一定量的内存、CPU 等计算资源,默认配置下,每个容器包含一个 CPU 核心。容器由 NodeManager 进程启动和管理,NodeManger 进程会监控本节点上容器的运行状况并向 ResourceManger 进程汇报。
应用程序管理器负责应用程序的提交、监控应用程序运行状态等。应用程序启动后需要在集群中运行一个 ApplicationMaster,ApplicationMaster 也需要运行在容器里面。每个应用程序启动后都会先启动自己的 ApplicationMaster,由 ApplicationMaster 根据应用程序的资源需求进一步向 ResourceManager 进程申请容器资源,得到容器以后就会分发自己的应用程序代码到容器上启动,进而开始分布式计算。
巨人的肩膀
1、《从零开始学大数据》
2、《架构师的自我修炼》
3、 https://www.cnblogs.com/yszd/p/10885222.htm
4、 http://hadoop.apache.org/
小结
本期内容简单为大家介绍了 Hadoop 三大组件的架构思想和原理,对于一些非重点的内容并未详细展开介绍,大家可以自行了解或者添加我的 wx:zwj_bigdataer 找我交流学习。如果本期内容对你有点帮助,记得来发三连支持一下 ~
更多精彩内容关注 👇「大数据梦想家」🔥:
一枚喜欢阅读,输出,复盘的大数据爱好者。热衷于分享大数据基础原理,技术实战,架构设计与原型实现之外,还喜欢输出一些有趣实用的编程干货内容,与阅读心得 …
文章来源: alice.blog.csdn.net,作者:大数据梦想家,版权归原作者所有,如需转载,请联系作者。
原文链接:alice.blog.csdn.net/article/details/120414894

- 点赞
- 收藏
- 关注作者
评论(0)