人工智能(一)Python基础

一、 Python语言基础
先看看我呕心沥血做的这个Python基础语法的思维导图吧
不过这是全栈Python需要学习的东西,学习人工智能并不需要这么多,来跟我一起看看吧
1.1 Python介绍
现在不是一直都在吹Python吗,说什么小学都要出Python的教材了,搞得好像这年头不会个Python还不如小学生一样!
既然如此,那么?你会Python吗?
不会?不要紧!一篇文带你入门Python!一篇文带你疏通Python基础语法!
会?行吧,别急着走嘛!看看吧。毕竟,温故而知新,可以为师矣!
Python作为一门高级编程语言吗,最大的特点就是简单易学
1.2 Python安装
注意现在Python分为Python2.x和Python3.x版本,我们这里介绍的是Python3.x版本,不要下载错误
1. 普通版本
可以去官网下载——官网
下载后傻瓜式安装,不过有一步需要注意的是:「Add to path的地方需要勾一下」

不勾选的话需要手动配置环境,异常麻烦
2. Anaconda发行版
Anaconda是一个Python版本,只不过他集成了关于人工智能相关的必要库,包括numpy,matplotlib等
下载链接——点击即可下载64位windows安装包
然后就是傻瓜式安装
1.3 pycharm编辑器安装
下载pycharm专业版,怎么破解我这里就不教了,自行百度
是傻瓜式安装,让你打钩的地方全部打钩,等到安装成功后,再打开,不注册,选择跳过,会让你试用30day
然后选择New Project,点击创建一个新的项目,信息填写好,然后Create
 在这里插入图片描述
在这里插入图片描述
然后经过漫长的等待就行了,注意,真的是漫长的等待,要等好久的
1.4 基础语法
python身为一个高级语言,也是有自己的语法格式的。
1. 注释
什么叫做注释呢?注释就是对我们的代码进行解释,让别人能够看懂我们写的代码。但是计算机却会对我们的注释熟视无睹,因为他并不需要你的解释,他能看懂。
「单行注释」: # 这是单行注释
「多行注释」:""“这是多行注释”""
2. 保留字
再别的语言里也叫做关键字,是在python这门语言中另有作用的名字。
而有时,你不需要管这个单词是什么意思,只需要知道他的作用是什么,不过编程语言中讲究见名知意,所以英语好一点是有优势的。不过也不能全靠翻译意思。
python的保留字相对来说较少,有33个
3. 标识符
标识符,这个东西是我们自己命名的东西,但是呢,我们又不能随意的命名,因为不知定格规范的话,有的人写这种,有的人写那种,计算机又会看不懂了。
「标识符的规范」:可以包含数字,字母,下划线,但是又不能以数字开头,并且标识符对大小写敏感。
而现在,我们学的python3,有个「中国人的福音」:那就是,*我们可以使用中文作为我们的标识符!*是的没错,中文作为标识符。当然,同样不可以数字开头。
标识符的作用下一篇会提到。
「小练习」
❝判断以下标识符是否正确
1smly smly _smly smly_ sm_ly 判断下列标识符是否相同
❞
smly Smly smly sMly SMLy smLY smly1 Smly1
4. 缩进
缩进在python中是及其重要的,就好像我们说话时的标点符号但又不完全一样,因为在python中缩进是必须的,缩进是让计算机知道我们的代码是从哪里分段的,而如果没有缩进,计算机就不认识你的代码,就会报错。
那么什么是报错呢,就好像你朋友对你胡言乱语的一顿输出,你却听不懂,这时候你就会说,我听不懂,你说听不懂,就是报错,给你朋友看的,他知道你听不懂,就会重新组织语言,直到让你听懂。
那么计算机也是同样的道理,你不缩进的代码,计算机就不懂,就会给你报错,让你明白,他不懂,这样你就会修改你的代码,让计算机明白你的意思。
而这个过程也是我们调试我们的代码的过程。
不同的代码组合在一起,就像不同的汉字组合在一样,分隔开不同的段,就有不同的意思。
而缩进也有包含的意思,相同层次的代码缩进相同,层次靠下的缩进依次减少。(这个暂时不理解也是没事的,后面就会理解了)
「小练习」
# 1. 判断以下代码能否运行
print("Hello")
print("World")
print("!")
5. 输入
输出我们已经知道了,使用print(),那么输入呢? input()
input()
print()
运行试试:
 在这里插入图片描述
在这里插入图片描述
会提示你在这输入东西,那么我们如果想要一个提示的话,怎么办呢?
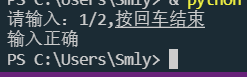
input("请输入:1/2,按回车结束")
print("输入正确")
结果:
 在这里插入图片描述
在这里插入图片描述
6. 输出
print()是个输出函数(暂时先不去管什么是函数,后面会讲解的),可以把括号里面的内容输出到控制台显示 当然,括号里面是你想显示的内容是需要加双引号,单引号(这里一定要注意单双引号都是英文符号,也就是切换到英文输入的单双引号) 比如说你要显示你好呀,就应该这么写
print ('你好呀')
这就是print ()函数输出字符串 什么是字符串呢?字符串就是这里面英文单双引号里面的内容 就像
"Hello World"
"你好呀"
"你好,初学者"
这些都是字符串 计算机里面的字符串就相当于我们人和人之间平时说的话,字符串是计算机与计算机之间,或者是会编程语言的人与计算机之间交流的东西
7. 变量
什么是变量。顾名思义,就是可变的量。
而之前所学的字符串,就是不可变的,这个不可变的意思是,保存在内存里面的不会改变,并不是内容。
因为你可以对字符串进行各种操作,但是,其在内存中的地址确实不变的,你所修改,只是将原来的copy一份,再修改。
就相当于我说了一句话,你可以拿去用,自己修改修改,但是那已经不是我所说过的话了,已经被你复制了过去。
那么变量有什么用呢?变量可以接收我们的数据,进行连续,重复的调用,比如我们的"Hello World!"这个字符串很长,我们如果想在很多地方都使用的话,就需要重复写这么多,那样是不是很麻烦,所以就有了变量,定义一个变量去接收这个字符串,以后再使用,可以直接通过这个变量名去调用。
而这个变量名,就是我们上节所学到的标识符。
简单使用:
a = "Hello World"
print(a)
1.5 数据类型
数据类型,就是我们存储数据的东西。什么是数据类型?就是数据的类型!没别的意思。
那么为什么需要数据类型呢?
如果我们需要进行数学运算,比如说1+1,1乘1,1除以1,等等等
我们就需要用到数字,而数字有小数,整数,复数(暂时不知道没关系,用的不多)对吧
数据类型分为基本数据类型和高级数据类型。
基本数据类型包括:整型(int),浮点型(float),复数(complex),布尔型
高级数据类型包括:字符串(str),列表(list),集合(set),字典(dict),元组(tuple)
那么高级数据类型为什么冠以高级之称呢?因为他们还有别的额外的操作。
比如增删改查之类的操作。
1. 数类型
整数在python中叫做整型 用int 表示,小数在python中叫做浮点型,用 float 表示
比如:
int类型 1,10,100,1000,10000 float类型 1.1 1.11 1.1111
看看这个代码
print(100+0.555)
输出的结果是100.555
这个100就是整型int,0.555就是浮点型float
2. 布尔型
布尔型呢,只有两个值
一个是True表示正确,一个是False表示错误
就像我告诉你 1>2 你就会反驳我,这是错的一样
计算机也会思考,你看这两行代码
print (1>2)
print (1<2)
运行结果:
 在这里插入图片描述
在这里插入图片描述
3. 字符串
❝字符串就类似于我们平时说的话,就是字符串在一起,叫做字符串,字符就是一个一个的
❞
首先呢,字符串可以遍历取值,也就是可以利用我们的循环来将其中的所有元素,一个一个的展现出来,拿出来,可以进行各种操作
当然别的高级数据类型也都可以遍历,只不过字典会有所区别
代码展示:
str_ = "Hello World!"
for i in str_:
print(i)
运行结果:
 在这里插入图片描述
在这里插入图片描述
可以看到,循环将我们的字符串拆开一个一个的拿了出来,并且输出
然后呢就是字符串格式化
什么是格式化字符串?就是可以让我们的代码更加简单
以问题理解
怎么输出一句话,包含变量
例子:给出一个变量a = 1 怎么让输出的结果为:"a的值为:1"
-
第一个方法:print("a的值为:", a) -
第二个方法:print("a的值为:{}".format(a)) -
第三个方法:print("a的值为:%d"%a) -
第四个方法:print(f"a的值为:{a}")
其实就是让我们的字符串中可以添加变量,而第一种的方法在处理一个字符串中的多个变量时是较为麻烦的,这时候就需要用到下面三个,比较简单,我最喜欢的是第四个方法。因为写出来简单
原生字符串就是只含字符串,和格式化不同,原生字符串引号里面的所有都是字符串,不会被机器认识成别的
比如我们的转义符\
\t 表示我们的tab \n表示换行
那么怎么定义呢?只需要在字符串前面的括号前加上r就可以了
我们来看看这个代码,结果会是如何
print(r"你好\t世界")
print(r"你好\n世界")
运行结果:
 在这里插入图片描述
在这里插入图片描述
可以看到,我们的转义符并没有什么作用,他被原原本本的表现了出来,这就是我们的原生字符串的作用
关于转义符,我就不多说了,像了解的可以去搜索一下
关于字符串呢,还有更多的操作,比如什么判断是否是数字,判断大小写,转大小写什么的,想了解可以去搜索一下字符串的所有操作,本篇作为入门篇,就不多说那么多了。
4. 列表
「基础理解」
list 列表
列表是用中括号括起来的以一组数据 比如说这个 [1, 2, 3, 4, 5,] 就是一个列表
这个就是储存了1-5 五个整型数据的 一个列表
用变量接受一个列表:li = []
作为高级数据类型,列表可以增删改查。
至于遍历,就不说了和字符串是一样的
你也不需要深刻理解,你只需要知道,列表是个袋子,他可以帮助我们存储更多的东西。
而我们也可以通过这个袋子去操作里面的东西,比如上述的增删改查,不就是往袋子里放东西,把袋子里的东西拿出来,把袋子里的东西拿出来换个东西,看看袋子里的东西
「增加数据:」
往列表增加元素:li.append()
举例:
li = [1, 2, 3, 4]
li.append(5)
print(li)
结果:[1, 2, 3, 4, 5]
而作为高级数据类型,你可以往列表里面添加一切数据类型
「删除数据:」
删除列表指定元素:li.remove()
举例:
li = [1, 2, 3, 4]
li.remove(1)
print(li)
结果为:[2, 3, 4]
就是把袋子里的1拿了出来,至于放在哪,那肯定是扔了啊。
「查找元素:」
查找元素:
列表支持查找元素,不过是利用下标查找,python下标从0开始,当然,字符串也支持下标取值
举例:
li = [1, 2, 3, 4]
print(li[0])
结果为:1
既然说到了下表取值,那就说一下切片与步长吧
切片:可以限制取哪些下标范围的数据
步长:几个元素几个元素的取
列表[下标:下表:步长] 1表示正值一个一个取,-1表示倒着取,不写默认为1,2表示隔一个取一次
比如我们只取1,3(不包含3,这里指得也是下标)的元素
a = [1, 2, 3, 4, 5, 6]
print(a[1:3])
# 结果为:[2, 3]
print(a[::2])
# 结果为:[1, 3, 5]
print(a[;;-1])
# 结果为:[6, 5, 4, 3, 2, 1]
「更改数据:」
同样,修改元素需要通过下标来实现
举例:
li = [1, 2, 3, 4]
li[0] = 2
print(li)
结果为: [2, 2, 3, 4]
5. 元组
元组与别的不同,他是不可变的,意思就是无法添加,无法修改,无法删除
元组使用小括号定义 tu = (1, 2, 3, 4)
元素之间和列表,集合,字典一样,每组元素之间通过英文逗号,分隔开
可以参考列表,只不过元组和集合一样无法修改,但是并不是因为无序性,元组可以通过下标取值
虽然元组是不可变的,但是我们可以直接把整个元组删除
tu = (1, 2, 3, 4, 5)
del tu
print(tu)
结果为:()
6. 字典
为什么把字典返回在最后?因为字典是键值对的形式。
格式:dic = {"key": value}
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
在字典中,通过访问key以得到value
「添加元素:」
我们可以定义一个空字典,也可以定义一个有元素的
我们会分别举例
空字典:
di = {}
di["name"] = "Tom"
di["age"] = 18
print(di)
结果:{"name": "Tom", "age": 18}
有元素的字典:
di = {"name": "Tom"}
di["age"] = 18
print(di)
结果为:{"name": "Tom", "age": 18}
之所以能用这样的方法,是因为我们的键是唯一的,所以可以通过这种方法添加元素
「删除元素:」
还是通过唯一的键来确定,然后删除
di = {"name": "Tom", "age": 18}
del di["age"]
print(di)
结果为:{"name": "Tom"}
「修改元素:」
通过键来重新赋值以修改元素,我就不多做解释和示范了
「查找元素:」
查找元素就不能通过下标了,需要通过键来获取
di = {"name": "Tom", "age": 18}
print(di["name"])
结果为:"Tom"
7. 集合
集合:set 集合具有无序性,和不可重复性 无序性:没有顺序
当然集合也可以创建一个空集合,但是不能这样创建s = {}
因为这样是定义一个空字典的,我们应该这样set(s)
格式(长什么样):
s = {1, 2, 3, 4, 5}
「添加元素:」
往集合添加元素s.add()ands.update()
s = {1, 2, 3, 4, 5}
s.add(6)
s.upadte(7)
print(s)
结果为: {1, 2, 3, 4, 5, 6, 7}
「删除数据:」
s = {1, 2, 3, 4, 5}
s.remove(1)
print(s)
结果为:{2, 3, 4, 5, 6}
全部删除:s.clear()
「修改元素:」
没这个功能,因为元素是无序的,没法通过下标查找和修改
也没事,因为你在程序中,用列表和字典比较多
8. 类型转换
何为类型转换?就是字面意思,数据的类型发生了改变。
类型转换分为自动类型转换和强制类型转换。
我们上面的例子,100+0.555
一个是整型,一个是浮点型,他们的结果就是浮点型,这时候就发生了类型转化。
有时候,我们会需要进行类型转换的操作,因为有的时候某些数据类型无法满足我们的需求,这时候,我们就需要进行类型转换。
Python对类型转换提供了函数(与print()函数一样)支持强制类型转换
函数名就是数据类型的名字,只不过是多了一双半角括号,将需要转类型的数据放在括号里,就可以了
比如:我们要将别的数据转为字符串(基本上所有数据都可以转为字符串)
# 类型转换
a = 1
b = 1.1
c = 1+1j
d = "ss"
print(str(a))
print(str(b))
print(str(c))
print(str(d))
运行结果:
 在这里插入图片描述
在这里插入图片描述
1.6 运算符
当我们使用Python的时候,也需要进行运算,所以就引入了运算符
1. 算术运算符
和数学中的基本相同
| 符号 | 作用 | 符号 | 作用 |
|---|---|---|---|
| + | 相加 | - | 相减 |
| * | 相乘 | / | 相除 |
| % | 取余 | ** | 乘方 |
举例
print(1+1-2*5/2%5**2)
不要感觉麻烦,就按照数学中来计算
注意运算顺序
答案是:
-3.0
2. 赋值运算符
想想刚刚说的变量,就用到了辅助运算符=
而与之对应的还有 += *= /= ....
a += 1就等价于a = a+1
别的类比就可以了
3. 位运算符
位运算符,按位运算
位运算符主要针对的是「二进制数据」,并只适用于int ,short ,byte,long,char五种类型。 位运算符有,&、|、<<、>>、<<<、^、~
-
& 如果相对应位都是1,则结果为1,否则为0 -
| 如果相对应位都是 0,则结果为 0,否则为 1 -
^ 如果相对应位值相同,则结果为0,否则为1 -
〜 按位取反运算符翻转操作数的每一位,即0变成1,1变成0 -
<< 按位左移运算符。左操作数按位左移右操作数指定的位数 -
>> 按位右移运算符。左操作数按位右移右操作数指定的位数 -
>>> 按位右移补零操作符。左操作数的值按右操作数指定的位数右移,移动得到的空位以零填充 这个计算是要有二进制来使用,我是没怎么用过。。所以理解的不够深入,尽请谅解
4. 比较运算符
顾名思义,就是计算你们两个的关系的,关系运算符有:== 、!=、>、<、<=、>= 「这里的都是英文符号」,需要注意的是,关系运算符都是二目运算符,返回的都是布尔类型的数据true/false
-
==和数学中的=一样用法,比如,你看到别人这样写:1 = 2,你就下意识的知道,这是错的,同理,你在Java中写出1 == 2,计算机也是知道这是错的,他会告诉你:false -
!= 不等于,和数学中的是一样的,比如你看到1 2,你会说,这是对的,同样的,你给电脑看1!=2,电脑也会告诉你,这是对的,true。 -
下面的大于小于,大于等于,小于等于,都和数学中的一样,想必上过小学的人,都不会理解不了吧——笑
| 符号 | 作用 |
|---|---|
| == | 等于 - 比较对象是否相等 |
| != | 不等于 - 比较两个对象是否不相等 |
| > | 大于 - 返回x是否大于y |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写。 |
| >= | 大于等于 - 返回x是否大于等于y。 |
| <= | 小于等于 - 返回x是否小于等于y。 |
输出结果为布尔型数据,即要么是True要么是Flase
5. 逻辑运算符
既然有运算符,那么怎么能没有与或非呢,三种运算符:and、or、 !
-
and,这个就是与,也就是和逻辑,两个都必须满足,举个例子:我有女朋友和你有女朋友,那么,皆大欢喜。只要我没有女朋友或者你没有女朋友,就不说皆大欢喜,如果我俩都有,那就是皆大欢喜 -
or,这个是或,通用上面的例子,不过这次是只要我们俩其中一个有女朋友就是皆大欢喜 -
!,这个是非,通用上面的例子,这次是我们俩都没有女朋友,就皆大欢喜(?怎么哪里怪怪的)
1.7 分支控制语句
那么什么叫做分支控制语句呢?相信你们都知道数学中的流程图吧。
什么?没见过?没关系,我就让你们见识见识!
 在这里插入图片描述
在这里插入图片描述
数学中的流程图就长这个样子
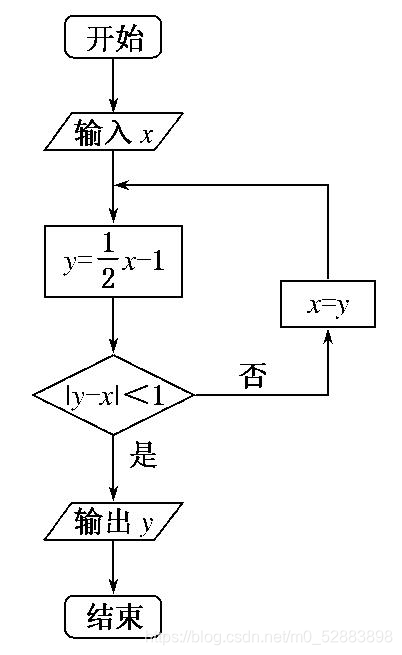 在这里插入图片描述
在这里插入图片描述
那么我们的分支控制语句和这玩意有什么关系呢?
其实差不多就是一个东西。
分支控制语句分为条件控制语句和循环控制语句。
从字面了解,一个是能用没几次的,一个是能用好多次的。
如果你还有所疑惑,那么是肯定的,因为,你现在脑子里面只是有了一个概念,却很模糊。
那么就跟着我来带你详细了解了解!
❝条件控制语句,就是通过判断条件来执行我们的代码,就像数学流程图里的是和否。
❞
1. 单支if语句
我们先来看看格式:
if 条件:
代码
这个翻译成汉语就是
如果 条件是真的:
执行代码
结束
如果 条件是假的
结束
流程就是这样的
2. 简单使用
那么我们来看一个小小的例子吧
a = int(input("请输入一个整数"))
b = int(input("请输入一个整数"))
c = a+b
if c<10:
print("两数之和小于10")
来看看运行起来是什么样子的吧
 在这里插入图片描述
在这里插入图片描述
懂了没?是不是很简单?没错,条件控制语句就是做这个的,不过这只是最简单的条件控制语句,下面我们来看看稍微复杂一点的。
3. 多支判断
「格式:」
if 条件:
代码
elif 条件:
代码
else:
代码
「使用:」
继续使用上面的例子
a = int(input("请输入一个整数"))
b = int(input("请输入一个整数"))
c = a+b
if c<10:
print("两数之和小于10")
elif c==10:
print("两数之和等于10")
else:
print("两数之和大于10")
好的,好的,我们的程序能做的事更多了
这次就输入一个5一个6吧
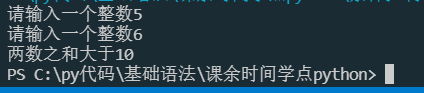 在这里插入图片描述
在这里插入图片描述
欧克,完美的实现了我们的功能
1.8 循环控制语句
循环,循环,何为循环,就是一直进行,不会停止
那么怎么停止呢?那也得我们自己设置条件
循环控制语句有两种,一种是for循环,一种是while循环。
1. for循环
「格式:」
一般来说,for循环使用较多
for 临时变量 in 循环的条件:
代码
我们的for循环需要一个临时变量,不需要提前定义一个变量去接收循环里面的值
这样对于内存也是一种释放,提前定义变量的话,就是一个全局变量,会一直占用内存,而这个for循环的临时变量就在循环结束后销毁,释放内存。
用白话文讲就是,临时变量只能在循环开始-循环结束前活着,循环结束的时候就是临时变量寿终正寝的时候,有点类似于卸磨杀驴(手动狗头)
而且我们的for并不需要我们手动更新变量
「使用:」
还记不记得上一篇的变量最后面,我们使用了10个print()函数输出了10次Hello World!
那么我们也可以用我们的循环,用更少的代码,实现这个效果
a = "Hello World!"
for i in range(10):
print(a)
代码中的i是从0开始的,而这个range()函数里面的值,就是从i到10(不含10),因此,会循环10次
来运行看看吧
 在这里插入图片描述
在这里插入图片描述
完美,达到了我们的目的
2. while循环
「格式:」
while 条件:
代码
「使用:」
还是上面的,输出10次Hello World!
a = "Hello World!"
i = 0
while i<10:
print(a)
i+=1
while循环不仅需要定义全局变量,而且还需要我们自己手动更新变量的值(i)
如果不更新的话,i的值就不会改变,条件就会一直成立,循环就不会停止,因此,使用while的时候,一定不要忘了更新变量
3. 主动循环结束
三种语句:break return continue都可以使循环停止
不过return一般都是用到函数里面的,都是使用break
而continue 不是用来终止循环的,具体作用看下面代码示例
「break:」
看汉语也有个大概思想:打破
它的作用是打破循环,使循环碰到它后终止
break的作用是打破结构体,使程序退出当前代码块
下面看这个例子,我们要实现的功能是循环获取用户从键盘输入的数据,直到输入q来推出程序
while True:
a = input()
if a == "q":
break
else:
print(a + " 输入成功,输入 'q' 退出程序")
运行结果:
 在这里插入图片描述
在这里插入图片描述
此时我们发现,输入q推出了,但是我们看着并不舒服,我们还可以加个提示,或者让他再输入一次“确认”来确认是否要推出
while True:
a = input()
if a == "q":
print("确定要推退出,确定的话,请输入确定退出来确定")
if input() == "确定退出":
print("已退出,程序结束")
break
else:
print(a + " 输入成功,输入 'q' 退出程序")
运行结果:
 在这里插入图片描述
在这里插入图片描述
这样就完美了,我这可不是谁字数啊,我这是强迫症(认真脸)!
「continue:」
continue是跳出当前循环,执行下一循环,也就是说,他并没有令循环终止的能力,他只能令循环少循环一些次数
我们先把上面的代码里面的break换成continue试试
while True:
a = input()
if a == "q":
print("确定要推退出,确定的话,请输入确定退出来确定")
if input() == "确定退出":
print("已退出,程序结束")
else:
print(a + " 输入成功,输入 'q' 退出程序")
行不通
 在这里插入图片描述
在这里插入图片描述
退出不了!
果然吧,那么continue有啥用呢?
我先不说,你先看:
for i in range(10):
if i % 5 == 0:
continue
else:
print(i)
运行结果:
 在这里插入图片描述
在这里插入图片描述
「return:」
return意为返回,是用在函数中的返回值的,至于函数是什么,我们会在本专栏中陆续讲述,你先看效果就可以了
我们计算当i的值循环到5时,让a+b,然后计算完终止
当i为5时,不管循环是否进行完,都会强行终止
def sum(a, b):
for i in range(10):
if i<a:
pass
else:
a+=b
return a
print(sum(5, 2))
pass的意思就相当于什么都不做
运行结果为:7
那么如果我们把return的位置换一下呢?
def sum(a, b):
for i in range(10):
if i<a:
pass
else:
a+=b
return a
print(sum(5, 2))
我们的循环会在第一次就终止,因为第一次i的值为0,满足判断条件,执行return语句,结束循环
那么如果我们再换一下呢?我们这次放在循环外面,那么肯定是循环执行完才会结束了,会把a+=b执行一次,还是7
def sum(a, b):
for i in range(10):
if i<a:
pass
else:
a+=b
return a
print(sum(5, 2))
1.9 函数式编程
「注意不要和数学中的函数搞混了」
那么到底什么是函数呢?
函数其实就是当我们在程序中需要大量重复的代码块,我们将其封装成一个代码块,用一个名字来表示,而这个名字是标识符。需要遵循标识符的规则。
函数的优点就是避免了代码重复率,提高开发效率。
举个例子:我们需要让电脑给我们表白(骚话),输出一段情话,就比如这一段
"我爱你"
"我要给你生猴子"
"啊啊啊,好喜欢你"
按照之前所学,一个一个的print()就行了嘛
但是我需要你什么时候都能给我来一段表白(骚话)呢?
这个时候恐怕用循环就不妥了吧,就用我们的函数了
当然,python自带的有很多内置函数,而我们自己定义的函数叫做自定义函数。
1. 无参函数:
无参函数是最基本的函数,基本上很少用到,都是拿来练习理解函数的。
def 函数名字():
代码
「使用:」
# 定义
def Qinghua():
print("我爱你")
print("我要给你生猴子")
print("啊啊啊,好喜欢你")
# 调用
Qinghua()
运行结果:
 在这里插入图片描述
在这里插入图片描述
好像,并没有多大作用吗!
其实不然,看这个
# 定义
def Qinghua():
print("我爱你")
print("我要给你生猴子")
print("啊啊啊,好喜欢你")
# 调用
Qinghua()
for i in range(10):
print("经过了{}秒".format(i))
Qinghua()
他可以在你任何想使用的时候,都可以通过调用的形式使用,而不需要你再打了。
就像变量一样,不过函数要比普通的变量复杂一些
2. 有参函数
函数是可以传递参数的,而参数分为形参和实参
❝形参就是形式上的参数,就像一家公司有员工,清洁工,董事长等职位,但是有些职位却空着,这些空着的职位,就相当于形参,需要有人去做这个职位,才能发挥作用,而这个能发挥职位作用的人,就叫做实参(实际参数)。
❞
而我们定义有参函数的时候,需要定义形参来表示我们的函数,有这些东西,你想让我们的函数去发挥作用的话,就需要给我们传递实际参数。
有参有参,在哪里体现的有参呢?
在我们定义的时候,我们需要在括号里面定义形参,用于接收参数
而在我们调用的时候,也是通过函数名后面的括号传递实参的
「使用:」
我们会定义一个有参函数来使两个参数拼接在一起,并遍历
def PinJie(a, b):
str_ = str(a)+str(b)
print(str_)
for i in str_:
print(i)
PinJie("sasa", 4564)
#也可以这么写
"""
PinJie(a="sasa",b=4564)
这样写的好处是
就算你的位置写错了
参数传递的也还是对的
也就是说,参数传递的位置不固定
就像这样
PinJie (b=4564, a='sasa')
是完全一样的
"""
运行:
 在这里插入图片描述
在这里插入图片描述
3. return的作用
之前说过,return一般是使用在函数中的,那么他的作用是什么呢?
先根据见名知意的规律来解读:返回
❝确实,他的作用就是返回,返回值
❞
通过return xxx来达到返回值得目的,这里是返回了xxx这个东西,至于xxx 是什么。。众所周知,xxx可以什么都是!
那么返回的值到了哪里呢?到了函数的调用那里,这个函数名字(参数)就是返回的值
「使用:」
看上面的那个函数,他显示拼接后的结果,使用了print()函数(内置函数)
那么我们使用return试试
def PinJie(a, b):
str_ = str(a)+str(b)
return str_
for i in str_:
print(i)
PinJie("sasa", 4564)
那么会怎么样呢?
答案是,什么都不会显示!
 在这里插入图片描述
在这里插入图片描述
为什么呢?因为我们没有使用print()函数(瞎说,那不是有!)
为什么这么说呢?因为上次讲过,return用于结束一段代码,而我们在中间return,下面的训话也就不会被执行,就直接结束了。
怎么显示循环呢?把「return放在函数最下面」,我就不展示了,自己去试试,不然优点水字数!(狗头保命!)
那么上面说了返回的值被 **函数名()**接收了,那么他现在就是一个值了,想要让它显示,那么只能用print()了啊!
def PinJie(a, b):
str_ = str(a)+str(b)
return str_
for i in str_:
print(i)
p = PinJie("sasa", 4564)
print(p)
结果:
 在这里插入图片描述
在这里插入图片描述
他就显示了返回值,也就是函数拼接的结果
1.10 面向对象编程
1. 理解
编程语言有面向对象(Java,Python)和面向过程(C语言)之分,面向对象需要一些抽象的思维才行。
面向过程和面向对象有什么区别呢?
面向过程注重亲力亲为,意思也就是自己去干这件事;而面向对象更倾向于找个人给自己做事。
就拿那个老生常谈的例子来说吧——洗衣服:
「面向过程:」
面向过程的洗衣服是:
❝❞
把衣服拿到洗衣机旁边 放进去 等待 捞出来
等下一次洗衣服,你还得重复这些操作
而这就是函数式编程
「面向对象:」
而面向对象则是:
❝❞
创造一个机器人
教他如何洗衣服
把衣服拿到洗衣机旁边 放进去 等待 捞出来 让他去干活
等下一次需要洗衣服,就让机器人去干就行了
而面向对象绕不开的就是类和对象了,接着往下看吧
2. 类
类是个抽象的东西,比如说人类,动物类,植物类,类是具有某些相同特征的事物的集合
那么如何定义一个属于我们的类呢?有三种方法,推荐使用第三种
# 定义一个Xxx类
class Xxx:
代码块
class Xxx():
代码块
class Xxx(object):
代码
这就成了
而类需要有属性,行为(方法)等东西
而属性就是在类里面的局部变量
而行为就是定义在类里面的函数
「构造方法:」
而每个类都有一些默认的行为(方法),比如这个构造方法__init__
每个类都默认有这个构造方法,而 构造方法里面的内容是会在实例化的时候就运行的,也就是,你实例化的时候,就会调用这个__init__构造方法。
而对象是什么呢?
3. 对象
对象是类的实例化,拿人类来说,人是一个类,而我们每个人都是人这个类的实例化对象。
看代码:
# 定义一个人类
class Person(object):
pass
# 实例化对象
xiaoming = Person()
很明显,xiaoming是Person这个类的实例化对象,换句话说,xiaoming是个Person,在这句话里,xiaoming就是「对象」,Person就是「类」
4. 代码实现洗衣机
代码:
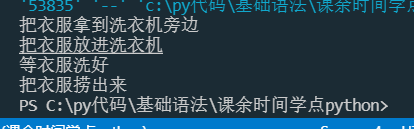
class Robot(object):
def __init__(self):
print("把衣服拿到洗衣机旁边")
print("把衣服放进洗衣机")
print("等衣服洗好")
print("把衣服捞出来")
xiaoming = Robot()
运行结果:
5. 封装
可以将构造方法的参数,进行封装,让其在每个方法中都可以调用
想着这样的代码就是错的
class Person(object):
def __init__(self, name, age):
pass
def speak(self):
print(f"{age}岁的{name}会说话")
Menger = Person("布小禅", 20)
name = Menger.name
age = Menger.age
person.speak()
print("姓名:{} \n年龄:{}".format(name, age))
因为speak方法里面的name和age,计算机不知道是谁,计算机不认识他们两个,而刚刚那两行self.name = name和self.age = age就是相当于告诉计算机name和age是类的参数
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def speak(self):
print(f"{age}岁的{name}会说话")
Menger = Person("布小禅", 20)
name = Menger.name
age = Menger.age
Menger.speak()
print("姓名:{} \n年龄:{}".format(name, age))
这样就对了,输出为:
❝姓名:布小禅
年龄:20
❞
6. 继承
Python的面向对象是可以继承的,就像你继承了你爸爸和你妈妈的部分特征,Python中的子类,继承父类,说起继承,其实你们也都见过了,就我上一篇说的三种定义类的方法的第三种:
class ClassNmae(object):
代码块
那个ClassNmae后面的括号里的object就是父类,而ClassName是子类
子类继承父类的所有东西
7. 私有化
上篇说过封装,既将我们不想让别人看到代码的内容,但是又需要用到的内容,通过类内部调用来实现调用。
说到这里却不得不提一下上篇的:
class Person(object):
def __init__(self, name, age):
self.xxx = name
self.xxxx = age
这里面self后面的名字,是可以自己随意命名的,上一篇和后面一样只是为了好记忆罢了
只要你记得住,便是颠倒也是无事
「属性私有化:」
何为属性私有?
举个例子便是:你的私房钱,你的手机电脑里面的小秘密等等这些不想被别人知道的东西
那么上面就说了,封装的目的是什么,不就是隐藏那些不想让别人知道的代码吗
所以有个属性私有化,可以让你的类属性变成私有的,这可和上篇的封装不一样,封装了还能通过实例化对象调用;这个属性一旦变成私有的,你在类外部是无法调用的
那我想用了怎么办?在类内部调用嘛!
好,叭叭了这么多,想必你们也得烦了,上代码
使用格式:
class Xxx(object):
age = 20
_name = "Xxx"
这种前面带着一个下划线的就是私有属性,无法通过类外部实例化对象的方法进行调用
具体应用:
"""
定义一个挺人类
含有姓名,年龄,体重,身高
将体重设置私有化
通过类内部调用使得能够在类外部看到你的体重
"""
class Person(object):
_weight = 70
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
def weightPrint(self):
print("我的体重是:", self._weight)
person = Person("布小禅", 20, 180)
person.weightPrint()
这个体重就无法通过person.weight、person._weight这样调用,因为这个属性是私有的
**方法私

- 点赞
- 收藏
- 关注作者
评论(0)