ESPNet介绍

ESPNet是一套基于E2E的开源工具包,可进行语音识别等任务。从另一个角度来说,ESPNet和HTK、Kaldi是一个性质的东西,都是开源的NLP工具;
引用论文作者的话:ESPnet是基于一个基于Attention的编码器-解码器网络,另包含部分CTC组件;
个人理解:在ESPNet出现之前,已经出现了CTC、Transformer等端到端ASR模型,ESPNet以这两种模型为核心,将这两个模型串了起来,利用二者优点,并外加了Kaldi等数据准备、特征提取的工具,最终封装成一个ASR的工具包,命名为ESPNet。
1、ESPNet 架构
ESPNet中使用了ATT+CTC的架构,其可分为两大部分:
1、Shared encoder(共享编码器):包括了VGG卷积网络和BLSTM(双向长短时记忆网络)层,来完成语音到向量的转化。
2、Joint Decoder(联合解码器):联合解码器实现向量到最终文本结果的输出;
联合解码器包括CTC(负责标签和序列的自动对齐)、Attention(为不同序列赋予不同权重)和RNN-LM(语言模型,生成最优字词句);
其中CTC和Attention二者共同使用一个Loss来使模型收敛,最终的损失函数LossMTL为CTC损失函数和Attention损失函数的加权求和;
联合解码中,使用one-pass beam search(剪枝搜索)方法来消除不规则的序列与标签的对齐。
2、ESPNet 实现ASR的具体流程
ESPNet实现ASR包含以下流程:
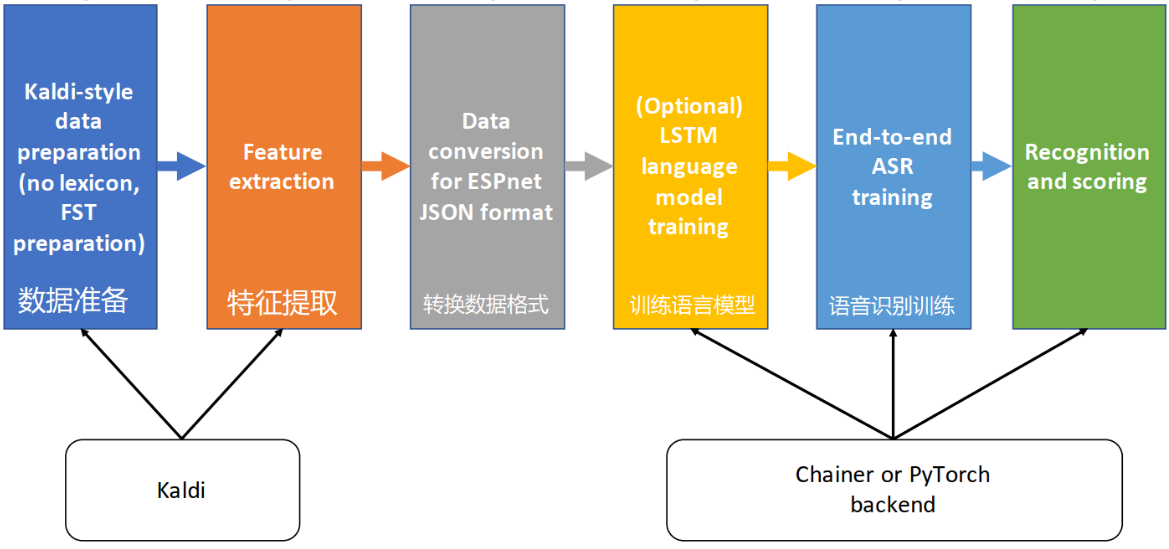
数据准备:下载数据与解压缩数据;
特征提取:使用Kaldi(Kaldi也是个开源ASR工具)来提取语音特征,输出为80维的FBank特征,加上3维的pitch特征,总共83维。然后进行均值归一化,让网络更容易对语音特征进行学习;
转换数据格式:将中间数据转化为JSON格式;
语言模型的训练:语言模型使用的RNN-LM模型,其中RNN-LM训练有无字的字符序列水平知识。尽管注意解码器暗含像等式中一样包含语言模型。 RNN-LM概率用于与解码器网络一起预测输出标签。基于注意力的解码器会先学会使用LM。此外,RNN-LM可以与编码器一起训练解码器网络
声学模型的训练:使用字典、训练集和测试集,基于CTC模型、Attention的架构和Transformer的解码器进行声学部分的训练;
识别与打分:联合Transformer模型、CTC模型和RNN语言模型进行打分: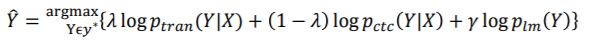

- 点赞
- 收藏
- 关注作者
评论(0)