利用SQL “窗口函数” 分析高(三)班学生考试成绩和生活消费!

一、背景介绍
今天,野鸡大学高(三)班的月考成绩出来了,这里先给大家公布一下各位同学的考试成绩。
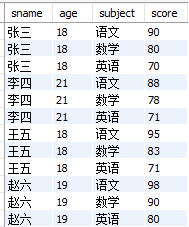
接着,在给大家公布一下各位同学的生活消费情况。
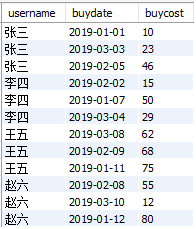
下面我们利用上述考试成绩和生活消费记录,利用mysql做一个简单的分析。
当然,从本文标题就可以看出来。本文就是要结合这份数据,为大家讲述SQL “窗口函数” 应该怎么用?

从上面这张图,应该知道这个知识点的重要性了。包括你以后学习hive或者oracle数据库,或者说数据分析面试,这都将是一个很重要的知识点。
二、建表语句和插入数据
创建表格
create table exam_score(
sname varchar(20),
age int,
subject varchar(20),
score varchar(20)
)charset=utf8;
# ----------------------- #
create table cost_fee(
sname varchar(20),
buydate varchar(20),
buycost int
)charset=utf8;
插入数据
insert into exam_score values
('张三' , 18, '语文' , 90),
('张三' , 18, '数学' , 80),
('张三' , 18, '英语' , 70),
('李四' , 21, '语文' , 88),
('李四' , 21, '数学' , 78),
('李四' , 21, '英语' , 71),
('王五' , 18, '语文' , 95),
('王五' , 18, '数学' , 83),
('王五' , 18, '英语' , 71),
('赵六' , 19, '语文' , 98),
('赵六' , 19, '数学' , 90),
('赵六' , 19, '英语' , 80);
# ----------------------- #
insert into cost_fee values
('张三','2019-01-01',10),
('张三','2019-03-03',23),
('张三','2019-02-05',46),
('李四','2019-02-02',15),
('李四','2019-01-07',50),
('李四','2019-03-04',29),
('王五','2019-03-08',62),
('王五','2019-02-09',68),
('王五','2019-01-11',75),
('赵六','2019-02-08',55),
('赵六','2019-03-10',12),
('赵六','2019-01-12',80);
三、窗口函数分类介绍
在正式讲述 “窗口函数” 应用之前,我这里先带着大家梳理一遍 “窗口函数” 的基础。我们可以将窗口函数分为如下几类:
- 聚合函数 + over()搭配;
- 排序函数 + over()搭配;
- ntile()函数 + over()搭配;
- 偏移函数 + over()搭配;
具体每一类,有哪些函数呢?观察下面的思维导图。
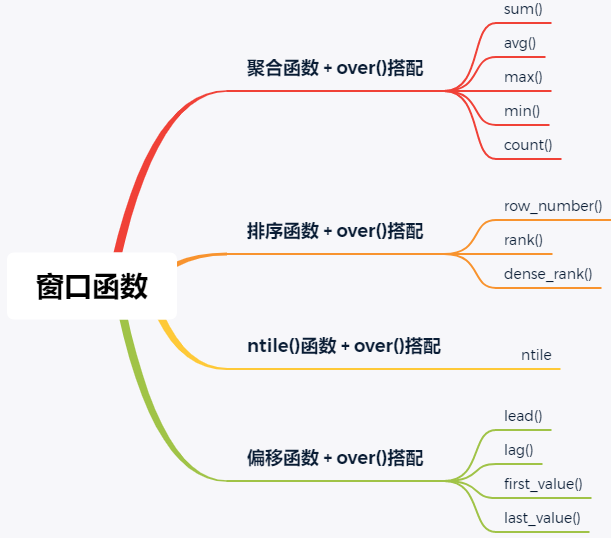
对于over()里面,这里还有两个常用的关键字,必须要讲述。如下:
- partition by + 字段:你可以想象成group by关键字,就是用于 “分组” 的关键字;
- order by + 字段:这个更容易理解,就是用于 “排序” 的关键字;
四、窗口函数应用
上面给大家介绍了若干常用的 “窗口函数”,这里利用文首创建的数据,讲讲 “窗口函数” 的应用。
希望大家通过每个案例,来总结一下每个函数的含义,这里就不详细写了。
1. 聚合函数 + over()搭配
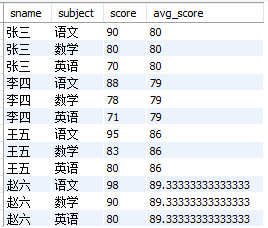
① 计算每位同学的得分与平均值的情况
select
sname
,subject
,score
,avg(score) over(partition by sname) as avg_score
from
exam_score
结果如下:
② 计算每位同学1-3月消费情况和消费总额
select
sname
,buydate
,buycost
,sum(buycost) over(partition by sname) as sum_cost
from
cost_fee
结果如下:
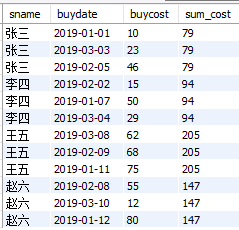
③ 计算每位同学1-3月消费情况和累计消费总额
select
sname
,buydate
,buycost
,sum(buycost) over(partition by sname order by buydate) as sum_cost
from
cost_fee
结果如下:
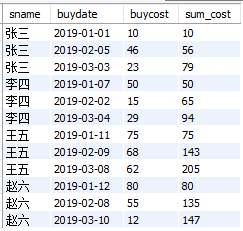
注意: 结合②③,大家可以发现partition by结合order by,与不结合order by,得到的完全是不同的结果。一个是分组求总和(不加order by);一个是分组求累计和(加order by)。
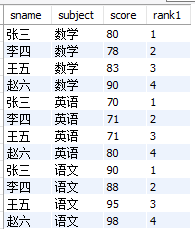
2. 排序函数 + over()搭配
① 计算每个科目的排名,相同的分数排名不同,顺序依次增加
select
sname
,subject
,score
,row_number() over(partition by subject order by score) rank1
from
exam_score
结果如下:
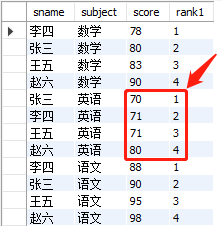
② 计算每个科目的排名,相同的分数排名相同,余下排名跳跃增加
select
sname
,subject
,score
,rank() over(partition by subject order by score) rank1
from
exam_score
结果如下:
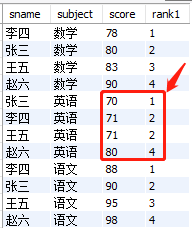
③ 计算每个科目的排名,相同的分数排名相同,余下排名顺序增加
select
sname
,subject
,score
,dense_rank() over(partition by subject order by score) rank1
from
exam_score
结果如下:
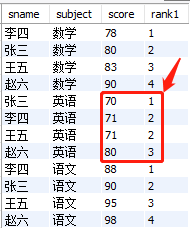
3. ntile()函数 + over()搭配
ntile()函数有点乱入的感觉,你不知道给它分哪一类。该函数主要用 “数据切分”。如果说这个函数还有点用的话,就是他也可以对数据进行排序,类似于上面提到的row_number()函数。
① 对exam_score表,进行整张表切分
select
sname
,subject
,score
,ntile(4) over() rank1
from
exam_score
结果如下:
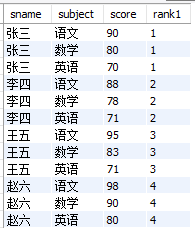
不信你下去试一下,ntile()里面不管写哪个数字,好像都可以。
② 对exam_score表,按照subject分组切分
select
sname
,subject
,score
,ntile(4) over(partition by subject) rank1
from
exam_score
结果如下:
即使是分组切分,你也会发现,这样毫无意义,因为score并没有排序。
② 对exam_score表,对score排序后,按照subject分组切分(最有用)
select
sname
,subject
,score
,ntile(4) over(partition by subject order by score) rank1
from
exam_score
结果如下:
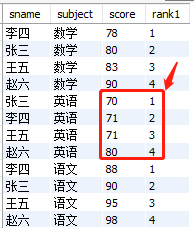
注意: 仔细观察这种用法,基本可以等效row_number()函数,效果是一样的。
4. 偏移函数 + over()搭配
① 展示各位同学的“上次购买时间”和“下次购买时间”
注:对于第一天,显示 “first buy”;对于最后一天,显示 “last buy”;
select
sname
,buydate
,lag(buydate,1,'first day') over(partition by sname order by buydate) as 上次购买时间
,lead(buydate,1,'last day') over(partition by sname order by buydate) as 下次购买时间
from
cost_fee
结果如下:
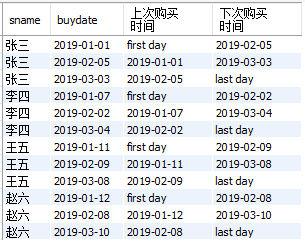
② 截止到当前日期,每位同学的“首次购买时间”和“最后一次购买时间”
select
sname
,buydate
,first_value(buydate) over(partition by sname order by buydate) as 首次购买时间
,last_value(buydate) over(partition by sname order by buydate) as 最后一次购买时间
from
cost_fee
结果如下:
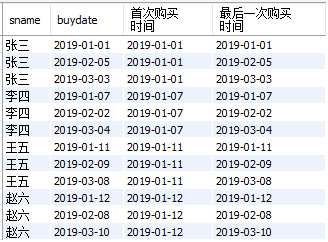
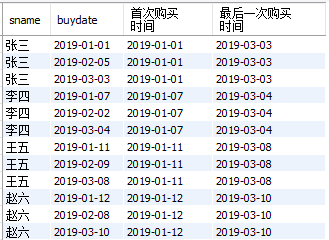
③ 展示每位同学的“首次购买时间”和“最后一次购买时间”
注意: 这里并没有说 “截止到当前日期”,请注意②③之间的区别呀。需求不同,结果就不同。
select
sname
,buydate
,first_value(buydate) over(partition by sname order by buydate) as 首次购买时间
,last_value(buydate) over(partition by sname ) as 最后一次购买时间
from
cost_fee
结果如下:

- 点赞
- 收藏
- 关注作者
评论(0)