超级重要的SQL优化问题(上)

SQL优化问题,一直是大家学习的难点。可能你会觉得,作为一名数据分析师,我只要知道怎么查询即可,其实不然,恰恰SQL优化问题,是面试官最容易用来为难我们的一道关卡,今天我就带大家讲述一下这方面的知识。
由于这个篇章涉及到的知识点太多,为了您们阅读的方便,我准备分为上、下两篇为大家讲述SQL优化知识。前方知识高能预警,大家做好准备哦。

本文大纲
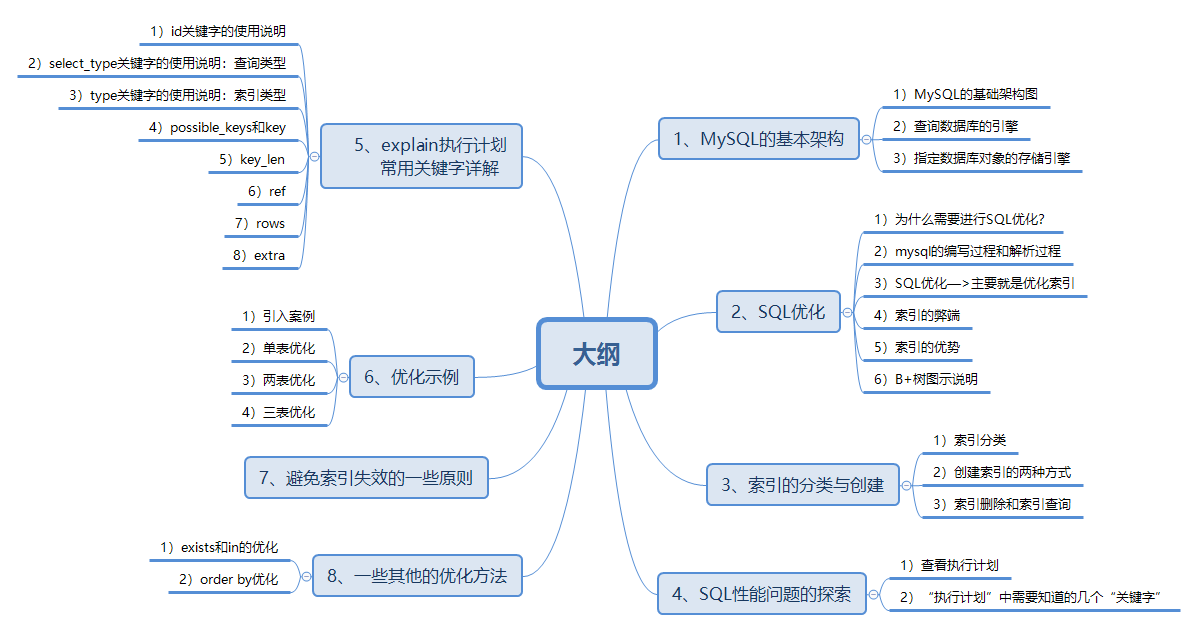
下图就是本文的大纲图,大家先大致做一个了解。今天讲述的是SQL优化问题的上篇,也就是大纲图的第1-4个部分,剩下的5-8个部分我们在明天的下篇中为大家讲述,尽情期待。
1. MySQL的基本架构
1)MySQL的基础架构图
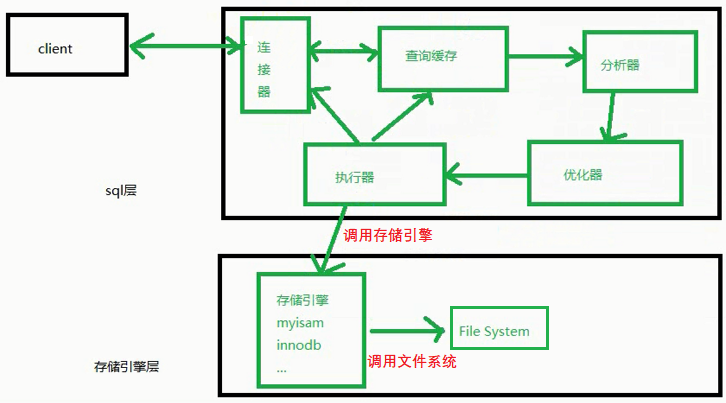
上面的client可以看成是客户端,就是我们用来链接MySQL服务器,书写SQL语句的窗口。这样的客户端其实有很多,像大家最常使用的CMD黑窗口,像安装MySQL时系统自带的WorkBench,还有大家最喜欢用的Navicat工具,它们都是一个客户端。而右边的这一大堆都可以看成是Server(MySQL的服务端),我们将Server在细分为sql层和存储引擎层。
下面我们 利用上图来说明SQL语句的整个执行过程, 这个对于我们更深层次理解SQL,确实是很有帮助 。
首先, 需要建立客户端与服务器之间的连接。这里通过一个【连接器】,我们建立的客户端与服务器之间的连接,此时,你在客户端写的SQL语句,就可以发送到MySQL的服务了。并不是连接上了MySQL服务器后,就立马给我查询出来底层的数据,这样的话效率就太低下了。
接着, 这个SQL语句将会被交到这个【查询缓存】中,如果可以查到,就直接响应回来给你;如果在查询缓存中没有查到,就需要接着往下走。
然后, 这个SQL语句将会被交到这个【分析器】中,这个分析器用于词法分析、语法分析,检查你写的SQL语句有没有单词拼写错误,语法书写错误。如果都没有错误,就需要接着往下走。
再接着, 这个SQL语句将会被交到这个【优化器】中,优化器如果觉得你的SQL写的太差了,它会帮你写一个性能高一些的等价SQL,去执行。如果优化器觉得你的SQL写的还行,就不会动你的SQL语句。这个优化器与我们下面需要讲解的“索引”有着千丝万缕的关系。
再然后, 优化器将最终确定好的SQL方案,交给了【执行器】,执行器通过执行引擎调用“存储引擎”。
最后, “存储引擎”最终调用【文件系统】,从底层去查询出数据。
当查询出数据以后,会返回给执行器。执行器一方面将结果写到查询缓存里面,当你下次再次查询的时候,就可以直接从查询缓存中获取到数据了。另一方面,直接将结果响应回客户端。
2)查询数据库的引擎
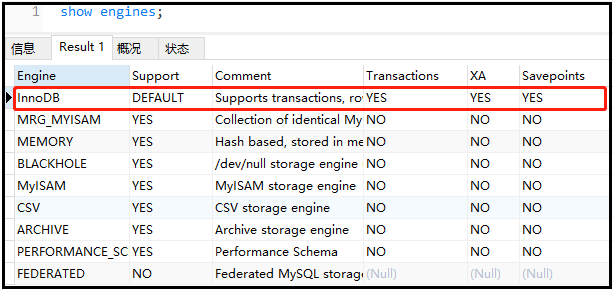
① show engines;
② show variables like “%storage_engine%”;

3)指定数据库对象的存储引擎
# 这里的engine就是指定引擎。
create table tb(
id int(4) auto_increment,
name varchar(5),
dept varchar(5),
primary key(id)
) engine=myISAM auto_increment=1 default charset=utf8;
2. SQL优化
1)为什么需要进行SQL优化?
我们在进行多表连接查询、子查询等操作的时候,由于你写出的SQL语句欠佳,导致的服务器执行时间太长,等待结果的时间会太长,基于此,我们需要学习怎么优化SQL。
2)mysql的编写过程和解析过程
① 编写过程
select dinstinct ..from ..join ..on ..where ..group by ..having ..order by ..limit ..
② 解析过程
from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..
提供一个网站,详细说明了mysql解析过程:https://www.cnblogs.com/annsshadow/p/5037667.html
3)SQL优化—>主要就是优化索引
优化SQL,最重要的就是优化SQL索引。
索引相当于字典的目录。利用SQL索引查找某条记录的过程,就相当于利用字典目录查找汉字的过程。有了索引,就可以很方便快捷的定位某条记录。
① 什么是索引?
索引是帮助MySQL高效获取数据的一种【数据结构】。索引是一种树结构,MySQL中一般用的是【B+树】。
② 索引图示说明(这里用二叉树来帮助我们理解索引)
树形结构的特点:子元素比父元素小的,放在左侧;子元素比父元素大的,放在右侧。- 下图只是为了帮我们简单理解索引的,真实的关于【B+树】的说明,我们会在下面进行说明。
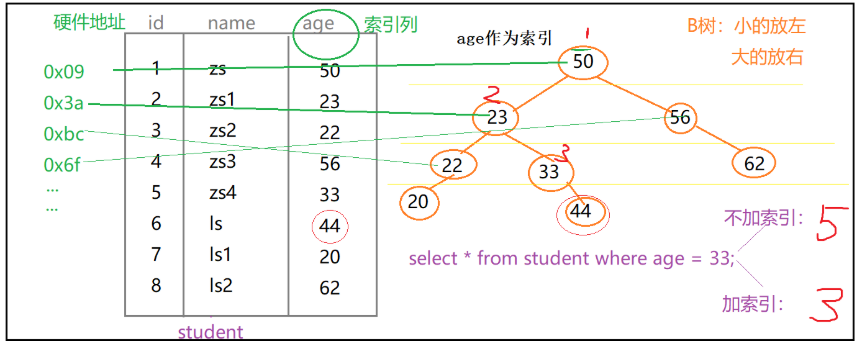
利用索引怎么查找数据呢?用两个字来说,就是【指向】。上图中,我们为age字段设置了索引,即类似于右侧的这种树形结构。mysql表中的每一行记录都有一个硬件地址,例如索引中的age=50,指向的就是源表中该行的标识符(“硬件地址”)。也就是说,树形索引建立了与源表中每行记录的硬件地址的映射关系,当你指定了某个索引,这种映射关系也就建成了,这就是为什么我们可以通过索引快速定位源表中记录的原因。
接下来我们以【select * from student where age=33】查询语句为例,说明一下利用索引是怎么查询数据的。
当我们不加索引的时候,会从上到下扫描源表,当扫描到第5行的时候,找到了我们想要找到了元素,一共是查询了5次。
当添加了索引以后,就直接在树形结构中进行查找,33比50小,就从左侧查询到了23,33大于23,就又查询到了右侧,这下找到了33,整个索引结束,一共进行了3次查找。是不是很方便,假如我们此时需要查找age=62,你再想想“添加索引”前后,查找次数的变化情况。
4)索引的弊端
- ① 当数据量很大的时候,索引也会很大(当然相比于源表来说,还是相当小的),也需要存放在内存 / 硬盘中(通常存放在硬盘中),占据一定的内存空间 / 物理空间。
- ②
索引并不适用于所有情况:a.少量数据;b.频繁进行改动的字段,不适合做索引;c.很少使用的字段,不需要加索引。 - ③
索引会提高数据查询效率,但是会降低“增、删、改”的效率。当不使用索引的时候,我们进行数据的增删改,只需要操作源表即可,但是当我们添加索引后,不仅需要修改源表,也需要再次修改索引,很麻烦。尽管是这样,添加索引还是很划算的,因为我们大多数使用的就是查询,“查询”对于程序的性能影响是很大的。
5)索引的优势
- ①
提高查询效率(降低了IO使用率)。当创建了索引后,查询次数减少了。 - ②
降低CPU使用率。比如说【…order by age desc】这样一个操作,当不加索引,会把源表加载到内存中做一个排序操作,极大的消耗了资源。但是使用了索引以后,第一索引本身就小一些,第二索引本身就是排好序的,左边数据最小,右边数据最大。
6)B+树图示说明
MySQL中索引使用的就是B+树结构,我们现在就利用下图来讲述一下这种树结构。
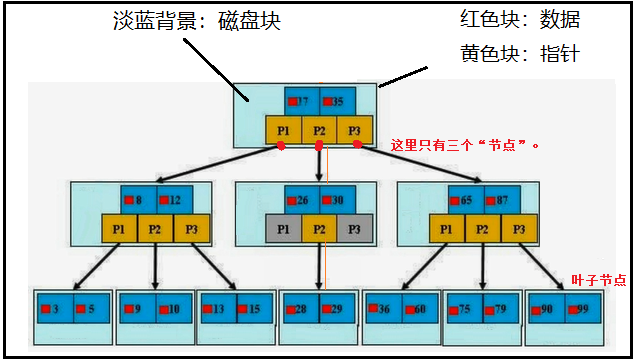
首先, Btree一般指的都是【B+树】,数据全部存放在叶子节点中。对于上图来说,最下面的第3层,属于叶子节点,真实数据部份都是存放在叶子节点当中的。那么对于第1、2层中的数据又是干嘛的呢?答:用于分割指针块儿的,比如说小于26的找P1,介于26-30之间的找P2,大于30的找P3。
其次, 三层【B+树】可以存放上百万条数据。这么多数据怎么放的呢?增加“节点数”。图中我们只有三个节点。
最后, 【B+树】中查询任意数据的次数,都是n次,n表示的是【B+树】的高度。
3. 索引的分类与创建
1)索引分类
- 单值索引
- 唯一索引
- 复合索引
① 单值索引
- 利用表中的某一个字段创建单值索引。一张表中往往有多个字段,也就是说每一列其实都可以创建一个索引,这个根据我们实际需求来进行创建。还需要注意的一点就是,一张表可以创建多个“单值索引”。
- 如果某一张表既有age字段,又有name字段,我们可以分别对age、name创建一个单值索引,这样一张表就有了两个单值索引。
② 唯一索引
- 也是利用表中的某一个字段创建单值索引,
与单值索引不同的是:创建唯一索引的字段中的数据,不能有重复值。 - 像age肯定有很多人的年龄相同,像name肯定有些人是重名的,因此都不适合创建“唯一索引”。像编号id、学号sid,对于每个人都不一样,因此可以用于创建唯一索引。
③ 复合索引
- 多个列共同构成的索引。比如说我们创建这样一个“复合索引”(name,age),先利用name进行索引查询,当name相同的时候,我们利用age再进行一次筛选。
注意:复合索引的字段并不是非要都用完,当我们利用name字段索引出我们想要的结果以后,就不需要再使用age进行再次筛选了。
2)创建索引
① 语法
- 语法:create 索引类型 索引名 on 表(字段);
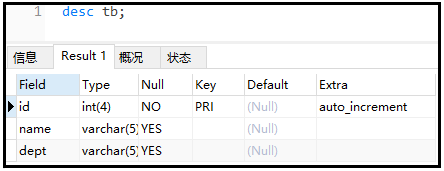
- 利用如下建表语句,完成创建索引的演示。
create table tb(
id int(4) auto_increment,
name varchar(5),
dept varchar(5),
primary key(id)
) engine=myISAM auto_increment=1 default charset=utf8;
- 查询表结构

② 创建索引的第一种方式
Ⅰ 创建单值索引
create index dept_index on tb(dept);
Ⅱ 创建唯一索引:这里我们假定name字段中的值都是唯一的
create unique index name_index on tb(name);
Ⅲ 创建复合索引
create index dept_name_index on tb(dept,name);
③ 创建索引的第二种方式
- 先删除之前创建的索引以后,再进行这种创建索引方式的测试。
- 语法:alter table 表名 add 索引类型 索引名(字段);
Ⅰ 创建单值索引
alter table tb add index dept_index(dept);
Ⅱ 创建唯一索引:这里我们假定name字段中的值都是唯一的
alter table tb add unique index name_index(name);
Ⅲ 创建复合索引
alter table tb add index dept_name_index(dept,name);
④ 补充说明
- 如果某个字段是primary key,那么该字段默认就是主键索引。
- 主键索引和唯一索引非常相似。
相同点:该列中的数据都不能有相同值;不同点:主键索引不能有null值,但是唯一索引可以有null值。
3)索引删除和索引查询
① 索引删除
- 语法:drop index 索引名 on 表名;
drop index name_index on tb;
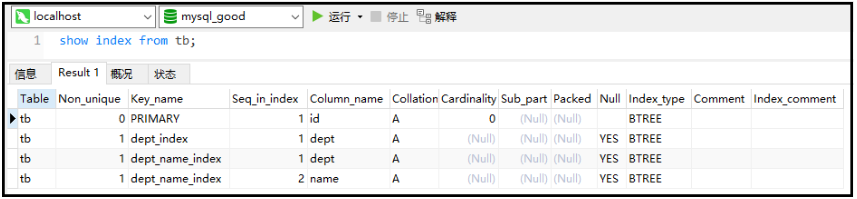
② 索引查询
- 语法:show index from 表名;
show index from tb;
结果如下:
4. SQL性能问题的探索
人为优化:需要我们使用explain分析SQL的执行计划。该执行计划可以模拟SQL优化器执行SQL语句,可以帮助我们了解到自己编写SQL的好坏。SQL优化器自动优化:最开始讲述MySQL执行原理的时候,我们已经知道MySQL有一个优化器,当你写了一个SQL语句的时候,SQL优化器如果认为你写的SQL语句不够好,就会自动写一个好一些的等价SQL去执行。SQL优化器自动优化功能【会干扰】我们的人为优化功能。当我们查看了SQL执行计划以后,如果写的不好,我们会去优化自己的SQL。当我们以为自己优化的很好的时候,最终的执行计划,并不是按照我们优化好的SQL语句来执行的,而是有时候将我们优化好的SQL改变了,去执行。SQL优化是一种概率问题,有时候系统会按照我们优化好的SQL去执行结果(优化器觉得你写的差不多,就不会动你的SQL)。有时候优化器仍然会修改我们优化好的SQL,然后再去执行。
1)查看执行计划
- 语法:explain + SQL语句
- eg:explain select * from tb;
2)“执行计划”中需要知道的几个“关键字”
- id :编号
- select_type :查询类型
- table :表
- type :类型
- possible_keys :预测用到的索引
- key :实际使用的索引
- key_len :实际使用索引的长度
- ref :表之间的引用
- rows :通过索引查询到的数据量
- Extra :额外的信息
建表语句和插入数据:
# 建表语句
create table course
(
cid int(3),
cname varchar(20),
tid int(3)
);
create table teacher
(
tid int(3),
tname varchar(20),
tcid int(3)
);
create table teacherCard
(
tcid int(3),
tcdesc varchar(200)
);
# 插入数据
insert into course values(1,'java',1);
insert into course values(2,'html',1);
insert into course values(3,'sql',2);
insert into course values(4,'web',3);
insert into teacher values(1,'tz',1);
insert into teacher values(2,'tw',2);
insert into teacher values(3,'tl',3);
insert into teacherCard values(1,'tzdesc') ;
insert into teacherCard values(2,'twdesc') ;
insert into teacherCard values(3,'tldesc') ;

- 点赞
- 收藏
- 关注作者
评论(0)