Linux系列:磁盘分区知识补充!

1、系统分区,也叫“磁盘分区”;
磁盘分区是使用分区编辑器在磁盘上划分几个逻辑部分。碟片一旦划分成数个分区,不同类的目录与文件可以存储进不同的分区。
通俗的说:就是把大硬盘,按照我的需求,分成几个小的硬盘。
2、用一个形象的例子说明“磁盘分区”
第一步:
我家有一面墙(如图1所示)很大,空着嫌浪费,于是按照墙的大小,做了一面柜子。只是设计之初,我很粗心,忘记给这个大柜子【添加隔断】,分成一个个的小柜子。
然后呢,我把家中【爸爸、妈妈、我】三个人的所有衣物,全部塞到这个大柜子中去。
突然有一天,我想找一个袜子,可以找的到吗?肯定是可以的。本来很简单的一件事,我只需要打开装袜子的柜子,取出袜子即可。但是现在正是因为没有隔断,就变成了对这个大柜子中所有衣物的大扫除,我需要遍历这个大柜子去找我的一双袜子,这样做相当耗费时间。
柜子是这样,硬盘其实也是这样,同时我们存入硬盘中的东西远远多于家里的衣服。假如没有对这个硬盘进行合理的规划,那么硬盘的读取和写入的效率会及其低下。那么,正确的做法是如何的呢,我们接着朝下看。
图1如下所示:

第二步:
假如我家有三口人,按照我们的需要把大柜子,合理的分成3个小柜子(如图2所示),左边是爸爸的衣服,中间是妈妈的衣服,右边是我的衣服。硬盘也是这样,可以按照我们的需求,把一个大硬盘,按照我们的需求分成几个分区,各自有各自的功能需求,那么进行数据读取和写入的效率会大大提升。
图2如下所示:
先来看看分区类型:
1)主分区:最多只能有4个。
2)扩展分区:
>>>最多只能有1个。
>>>主分区加扩展分区最多有4个。
>>>不能写入数据,只能包含逻辑分区。
3)逻辑分区
第三步:
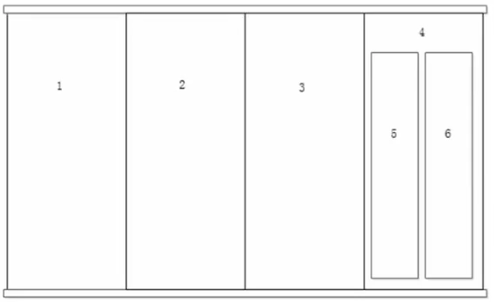
假如有一天,我爷爷、奶奶搬进来和我们一起住了,这个时候5个人,使用3个柜子肯定是不够的,好说呀,重新再做两个隔断,分成5部分,存储5个人的衣物就够了。
但是,硬盘就不可以这样了,按照硬盘的限制,我最多只能有4个分区。为了解决这个矛盾,我只能使用如图3所示的做法,把1、2、3作为“主分区”,它们可以分别放入数据,但是第4块属于“扩展分区”,它里面不能写入数据,也不能格式化,它唯一的作用就是,在这个“扩展分区”中添加其它的“逻辑分区”,逻辑分区可以正常的格式化和写入数据。
注意:这种限制,不是linux的限制,而是硬盘的限制,只要硬盘的结构不发生变化,这种限制依然都会存在。
图3如下所示:
第四步:
硬盘正确进行分区后,就可以写入数据了吗?当然不是。硬盘必须经过格式化后,才可以写入数据。
格式化(高级格式化)又称逻辑格式化,它是指根据用户选定的文件系统,如FAT16、FAT32、NTFS、EXT2、EXT3、EXT4等,在磁盘的特定区域写入特定数据,在分区中划出一片用于存放文件分配表、目录表等用于文件管理的磁盘空间。
通俗的说:格式化就是在硬盘中写入文件系统。
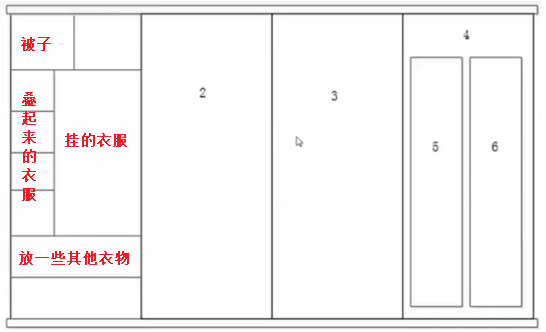
这样说,可能还是很难理解,我们看下面的图4。
有了柜子,就直接放入衣服了吗?大家想一下,其实也不是这样的,我们的柜子还要打一些隔断,不同的隔断–有条理的放入–指定的东西,格式化就可以理解为在柜子中打入隔断。只不过硬盘的格式化必须遵守一定的规则,也就是说,在linux中,默认的文件系EXT4,它进入格式化的时候,需要把每个柜子,变成一个一个等大小的数据块儿,每个数据块默认的大小是4KB,即:每4KB空间放一个小隔断。
假如有一个10KB的数据,它会被存入到任意的三个小数据块儿中,其中一个数据块儿虽然只存了2KB,但是也不会再存入其他的数据。在windows中有一个磁盘碎片整理工具,它可以尽量把这些保存同一个文件的不同数据块,尽量的放到一块儿去,方便数据的读取(了解一下)。
这里再解释一下格式化的意思:硬盘格式化就是将文件系统写入硬盘,写入文件系统【第1个主要的工作】就是,按照文件系统的规则,把硬盘分割成等大小的数据块,我们把这个数据块取名叫做“block”。
写入文件系统到硬盘,进行格式化后,就结束了吗?不是,这里还有一个规则。
再看看上面那个10KB的例子,我们数据存储在几个不同的数据块中,当我们想要读取数据的时候,我怎么知道这个文件,存储在哪些数据块中呢?
这就需要利用“文件分区表”,这个“文件分区表”就相当于在柜门上面贴上一个纸条,标明每件衣服、裤子、袜子放入了哪一个隔断。当我需要找某一件衣物的时候,只需要拿着“纸条上面的编号”对应着去找我的衣物。“文件分区表”上记录着每个文件存储的编号,通过这个编号,就可以知道这个文件存储在哪写数据块中了。这个编号,我们称之为“i节点号”,也叫做“inode号”。
通过以上的叙述,最后再说一下硬盘格式化的含义:硬盘格式化就是将文件系统写入硬盘,一共做了两件事,第1就是进行分区,把硬盘分成一个个一个个等大小的数据块,但是还不能直接使用;第2就是建立一个“inode列表”,当我们查找数据的时候,是通过“i节点号”来找到这个文件的条款,从而通过条款知道这个文件保存在哪几个数据块儿当中,从而打开数据块,拿出这些数据,拼凑成我们的完整文件。
图4如下所示:
第五步:
这一步都是系统所做的,我们只需要认识这些设备文件名就行。
假如是Windows系统,我们对硬盘进行了分区,进行了格式化,这个时候只要给这个硬盘分配盘符就可以直接使用了。但是Linux不行,我们进行分区进行格式化后,要想给它分配盘符之前,必须给每一个分区取一个设备文件名(硬件文件名)。
要注意linux中一个重要的概念:在linux中,所有的硬件设备都是文件,系统先要认识并识别这些文件,就必须给他们起一个设备文件名。这个设备文件名是固定的,系统自动检测的,我们要做的就是能够看懂就行了。分区的设备文件名也是固定的,系统自动检测的,我们要做的就是能够看懂就行了。
硬件设备的文件名:
硬件 设备文件名
IDE硬盘 /dev/hd[a-d]
SCSI/SATA/USB硬盘 /dev/sd[a-p]
光驱 /dev/cdrom或/dev/sr0
软盘 /dev/fd[0-1]
打印机(25针 ) /dev/1p[0-2]
打印机(USB) /dev/usb/1p[0-15]
鼠标 /dev/mouse
// 注:现在的电脑和服务器现在基本都是SATA硬盘接口,因此,在linux中识别
// 出来的都是sda,假如你电脑有两张硬盘,第二个识别出来的就是sdb,假如
// 再有一张硬盘,显示的就是sdc...
分区的设备文件名:
设备文件名
/dev/hdal(IDE硬盘接口)
/dev/sdal(SCSI硬盘接口、SATA硬盘接口)
// 注:应为目前电脑基本都是SATA硬盘接口,因此在linux中识别出来的是sda,
// 因此,该硬盘下面对应的分区应该就是sda1、sda2、sda3...
第六步:
给分区分配盘符,这个是windows中的说法,在linux中把这个盘符叫做挂载点,windows中所说的盘符是C盘、D盘、E盘、F盘,而linux的挂载点是一个任意的空目录(只有少数目录不可以做为挂载点),即可。
1)必须分区
/(根分区)
swap分区(交换分区,内存2倍,不超过2GB)
# 注:没有上述两个分区,linux不能正常安装。
2)推荐分区
/boot(启动分区,200MB)
# boot分区,专门保存系统用于启动的数据。避免根分区写满了,造成的linux无
# 法正常启动的情况发生。
3、文件系统结构
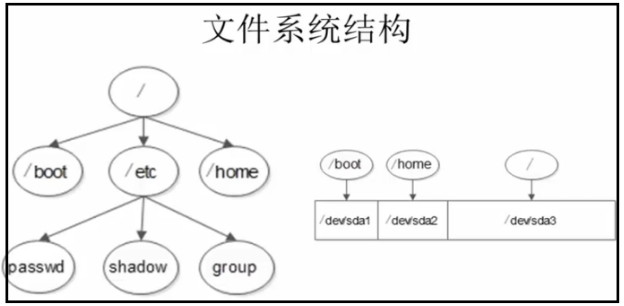
上图的解释:
记住,/boot分区属于存放系统启动程序的数据,肯定是占据第一位的分区,不管你怎么设置磁盘分区,/boot分区都会是sda1,/home分区存放的是普通用户进行各种操作时的一些数据,/根分区中存储的的是,对其余目录进行操作时所产生的数据。
假如,我们没有/boot分区,没有/home分区,我们进行操作时的各种数据都是存放在/根分区下,这样就会造成对根分区的压力很大,从根分区中读取数据效率也很低效(范围越大,找东西肯定就越困难)。假如有了/boot分区,我里面只记录系统启动时的数据信息,不写入其余信息,这样对于系统正常启动也是很好的。假如有了/home分区,我们创建了普通用户后,对普通用户的操作数据,也都是放在这个目录下的,这样对于我们找寻普通用户相关文件信息,也只需要系统在这个/home分区下进行搜索,这样效率会很高,同时对于/根分区来说,也分担了一部分压力。
总结系统分区的整个过程:
- 1)分区:把大硬盘分为小的逻辑分区; // 把大柜子打成一个个的小柜子;
- 2)格式化:写入文件系统; // 打隔断,同时生成一张inode列表;
- 3)分区设备文件名:给每个分区定义设备文件名;
- 4)挂载:给每个分区分配挂载点;

- 点赞
- 收藏
- 关注作者
评论(0)